
19 Sep 2025




In real-world scenarios, achieving domain adaptation and generalization poses significant challenges, as models must adapt to or generalize across unknown target distributions. Extending these capabilities to unseen multimodal distributions, i.e., multimodal domain adaptation and generalization, is even more challenging due to the distinct characteristics of different modalities. Significant progress has been made over the years, with applications ranging from action recognition to semantic segmentation. Besides, the recent advent of large-scale pre-trained multimodal foundation models, such as CLIP, has inspired works leveraging these models to enhance adaptation and generalization performances or adapting them to downstream tasks. This survey provides the first comprehensive review of recent advances from traditional approaches to foundation models, covering: (1) Multimodal domain adaptation; (2) Multimodal test-time adaptation; (3) Multimodal domain generalization; (4) Domain adaptation and generalization with the help of multimodal foundation models; and (5) Adaptation of multimodal foundation models. For each topic, we formally define the problem and thoroughly review existing methods. Additionally, we analyze relevant datasets and applications, highlighting open challenges and potential future research directions. We maintain an active repository that contains up-to-date literature at this https URL.

22 Nov 2025

EgoControl introduces a method for generating future egocentric video frames, utilizing 3D full-body pose sequences as explicit control. The model significantly improves visual fidelity, achieving an FVD of 20.18, and demonstrates enhanced accuracy in reproducing articulated body movements with a mean Intersection-over-Union (mIoU) of 52.13 for arm masks.
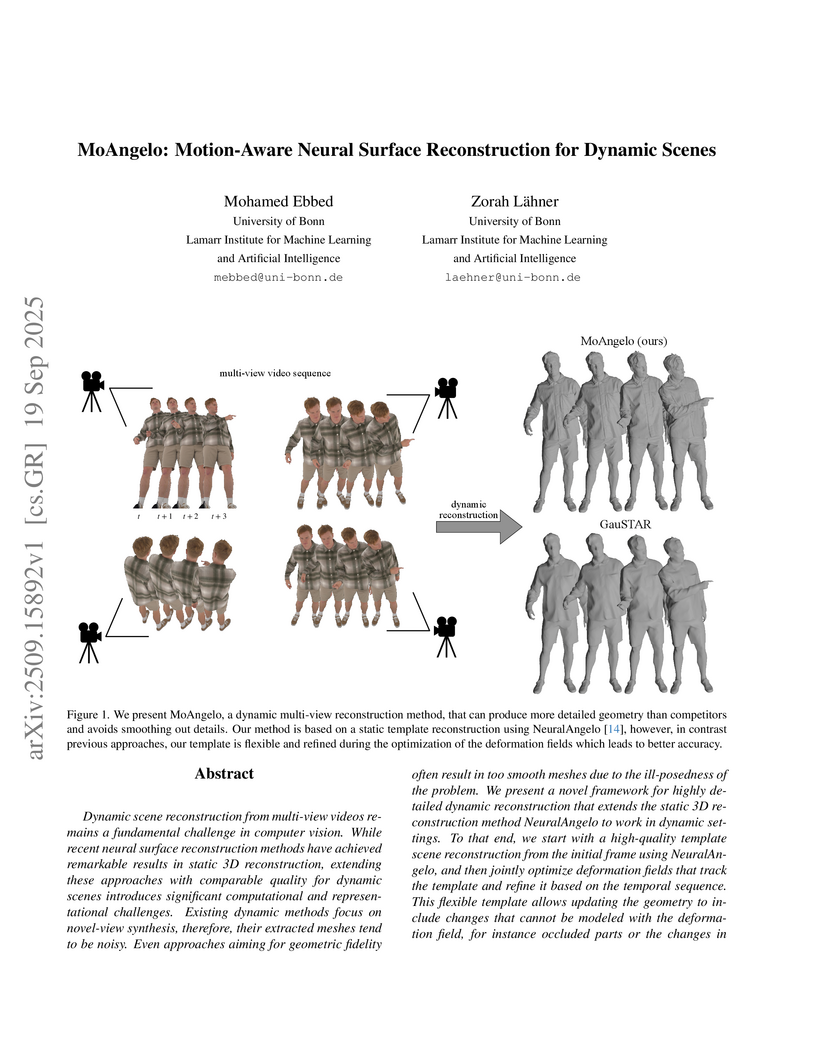
19 Sep 2025
Dynamic scene reconstruction from multi-view videos remains a fundamental challenge in computer vision. While recent neural surface reconstruction methods have achieved remarkable results in static 3D reconstruction, extending these approaches with comparable quality for dynamic scenes introduces significant computational and representational challenges. Existing dynamic methods focus on novel-view synthesis, therefore, their extracted meshes tend to be noisy. Even approaches aiming for geometric fidelity often result in too smooth meshes due to the ill-posedness of the problem. We present a novel framework for highly detailed dynamic reconstruction that extends the static 3D reconstruction method NeuralAngelo to work in dynamic settings. To that end, we start with a high-quality template scene reconstruction from the initial frame using NeuralAngelo, and then jointly optimize deformation fields that track the template and refine it based on the temporal sequence. This flexible template allows updating the geometry to include changes that cannot be modeled with the deformation field, for instance occluded parts or the changes in the topology. We show superior reconstruction accuracy in comparison to previous state-of-the-art methods on the ActorsHQ dataset.

08 Apr 2025
Robotics applications often rely on scene reconstructions to enable
downstream tasks. In this work, we tackle the challenge of actively building an
accurate map of an unknown scene using an RGB-D camera on a mobile platform. We
propose a hybrid map representation that combines a Gaussian splatting map with
a coarse voxel map, leveraging the strengths of both representations: the
high-fidelity scene reconstruction capabilities of Gaussian splatting and the
spatial modelling strengths of the voxel map. At the core of our framework is
an effective confidence modelling technique for the Gaussian splatting map to
identify under-reconstructed areas, while utilising spatial information from
the voxel map to target unexplored areas and assist in collision-free path
planning. By actively collecting scene information in under-reconstructed and
unexplored areas for map updates, our approach achieves superior Gaussian
splatting reconstruction results compared to state-of-the-art approaches.
Additionally, we demonstrate the real-world applicability of our framework
using an unmanned aerial vehicle.

26 Nov 2025
SAVi-DNO enables pre-trained diffusion models for video prediction to continuously adapt to live video streams by optimizing diffusion noise during inference. This method improves prediction accuracy and video quality across diverse datasets and diffusion models, offering an efficient and privacy-preserving solution for real-world continuous adaptation.

09 Sep 2025
Robots benefit from high-fidelity reconstructions of their environment, which should be geometrically accurate and photorealistic to support downstream tasks. While this can be achieved by building distance fields from range sensors and radiance fields from cameras, realising scalable incremental mapping of both fields consistently and at the same time with high quality is challenging. In this paper, we propose a novel map representation that unifies a continuous signed distance field and a Gaussian splatting radiance field within an elastic and compact point-based implicit neural map. By enforcing geometric consistency between these fields, we achieve mutual improvements by exploiting both modalities. We present a novel LiDAR-visual SLAM system called PINGS using the proposed map representation and evaluate it on several challenging large-scale datasets. Experimental results demonstrate that PINGS can incrementally build globally consistent distance and radiance fields encoded with a compact set of neural points. Compared to state-of-the-art methods, PINGS achieves superior photometric and geometric rendering at novel views by constraining the radiance field with the distance field. Furthermore, by utilizing dense photometric cues and multi-view consistency from the radiance field, PINGS produces more accurate distance fields, leading to improved odometry estimation and mesh reconstruction. We also provide an open-source implementation of PING at: this https URL.

04 Apr 2025
Query denoising has become a standard training strategy for DETR-based
detectors by addressing the slow convergence issue. Besides that, query
denoising can be used to increase the diversity of training samples for
modeling complex scenarios which is critical for Multi-Object Tracking (MOT),
showing its potential in MOT application. Existing approaches integrate query
denoising within the tracking-by-attention paradigm. However, as the denoising
process only happens within the single frame, it cannot benefit the tracker to
learn temporal-related information. In addition, the attention mask in query
denoising prevents information exchange between denoising and object queries,
limiting its potential in improving association using self-attention. To
address these issues, we propose TQD-Track, which introduces Temporal Query
Denoising (TQD) tailored for MOT, enabling denoising queries to carry temporal
information and instance-specific feature representation. We introduce diverse
noise types onto denoising queries that simulate real-world challenges in MOT.
We analyze our proposed TQD for different tracking paradigms, and find out the
paradigm with explicit learned data association module, e.g.
tracking-by-detection or alternating detection and association, benefit from
TQD by a larger margin. For these paradigms, we further design an association
mask in the association module to ensure the consistent interaction between
track and detection queries as during inference. Extensive experiments on the
nuScenes dataset demonstrate that our approach consistently enhances different
tracking methods by only changing the training process, especially the
paradigms with explicit association module.

04 Jul 2025


Researchers from the University of Bonn and Lamarr Institute developed ArithmAttack, a method for evaluating Large Language Model robustness to randomly inserted punctuation marks in mathematical word problems. Their experiments demonstrate that all eight tested LLMs show performance degradation with increased punctuation noise, despite no change in semantic meaning, with Llama models exhibiting the highest resilience and Zephyr-7b-beta being the most susceptible.

01 Jun 2025
Recently, 3D Gaussian splatting-based RGB-D SLAM displays remarkable
performance of high-fidelity 3D reconstruction. However, the lack of depth
rendering consistency and efficient loop closure limits the quality of its
geometric reconstructions and its ability to perform globally consistent
mapping online. In this paper, we present 2DGS-SLAM, an RGB-D SLAM system using
2D Gaussian splatting as the map representation. By leveraging the
depth-consistent rendering property of the 2D variant, we propose an accurate
camera pose optimization method and achieve geometrically accurate 3D
reconstruction. In addition, we implement efficient loop detection and camera
relocalization by leveraging MASt3R, a 3D foundation model, and achieve
efficient map updates by maintaining a local active map. Experiments show that
our 2DGS-SLAM approach achieves superior tracking accuracy, higher surface
reconstruction quality, and more consistent global map reconstruction compared
to existing rendering-based SLAM methods, while maintaining high-fidelity image
rendering and improved computational efficiency.

07 Aug 2025
We introduce Action Discovery, a novel setup within Temporal Action Segmentation that addresses the challenge of defining and annotating ambiguous actions and incomplete annotations in partially labeled datasets. In this setup, only a subset of actions - referred to as known actions - is annotated in the training data, while other unknown actions remain unlabeled. This scenario is particularly relevant in domains like neuroscience, where well-defined behaviors (e.g., walking, eating) coexist with subtle or infrequent actions that are often overlooked, as well as in applications where datasets are inherently partially annotated due to ambiguous or missing labels. To address this problem, we propose a two-step approach that leverages the known annotations to guide both the temporal and semantic granularity of unknown action segments. First, we introduce the Granularity-Guided Segmentation Module (GGSM), which identifies temporal intervals for both known and unknown actions by mimicking the granularity of annotated actions. Second, we propose the Unknown Action Segment Assignment (UASA), which identifies semantically meaningful classes within the unknown actions, based on learned embedding similarities. We systematically explore the proposed setting of Action Discovery on three challenging datasets - Breakfast, 50Salads, and Desktop Assembly - demonstrating that our method considerably improves upon existing baselines.

24 Mar 2025
SyncVP introduces a latent diffusion framework for synchronously predicting multiple future video modalities, such as RGB and depth, from multi-modal input sequences. The approach achieves new state-of-the-art performance on benchmarks like Cityscapes and BAIR while demonstrating robustness to partial input conditioning and effective generalization across diverse data types, including climate data.

10 Sep 2025
Recently, image-to-video (I2V) diffusion models have demonstrated impressive scene understanding and generative quality, incorporating image conditions to guide generation. However, these models primarily animate static images without extending beyond their provided context. Introducing additional constraints, such as camera trajectories, can enhance diversity but often degrade visual quality, limiting their applicability for tasks requiring faithful scene representation. We propose CamC2V, a context-to-video (C2V) model that integrates multiple image conditions as context with 3D constraints alongside camera control to enrich both global semantics and fine-grained visual details. This enables more coherent and context-aware video generation. Moreover, we motivate the necessity of temporal awareness for an effective context representation. Our comprehensive study on the RealEstate10K dataset demonstrates improvements in visual quality and camera controllability. We will publish our code upon acceptance.

13 Dec 2024
Many query-based approaches for 3D Multi-Object Tracking (MOT) adopt the
tracking-by-attention paradigm, utilizing track queries for identity-consistent
detection and object queries for identity-agnostic track spawning.
Tracking-by-attention, however, entangles detection and tracking queries in one
embedding for both the detection and tracking task, which is sub-optimal. Other
approaches resemble the tracking-by-detection paradigm and detect objects using
decoupled track and detection queries followed by a subsequent association.
These methods, however, do not leverage synergies between the detection and
association task. Combining the strengths of both paradigms, we introduce
ADA-Track++, a novel end-to-end framework for 3D MOT from multi-view cameras.
We introduce a learnable data association module based on edge-augmented
cross-attention, leveraging appearance and geometric features. We also propose
an auxiliary token in this attention-based association module, which helps
mitigate disproportionately high attention to incorrect association targets
caused by attention normalization. Furthermore, we integrate this association
module into the decoder layer of a DETR-based 3D detector, enabling
simultaneous DETR-like query-to-image cross-attention for detection and
query-to-query cross-attention for data association. By stacking these decoder
layers, queries are refined for the detection and association task alternately,
effectively harnessing the task dependencies. We evaluate our method on the
nuScenes dataset and demonstrate the advantage of our approach compared to the
two previous paradigms.

06 Aug 2025

Skeleton Motion Quantization (SMQ) is an unsupervised framework designed for temporal action segmentation using skeleton data, learning discrete "skeleton motion words" to segment untrimmed sequences. It achieved superior performance with a Mean over Frames (MoF) of 42.0 and F1@50 of 24.3 on the HuGaDB dataset, consistently outperforming existing unsupervised video-based and self-supervised skeleton methods across multiple benchmarks.

19 Jun 2023
Accurately perceiving instances and predicting their future motion are key tasks for autonomous vehicles, enabling them to navigate safely in complex urban traffic. While bird's-eye view (BEV) representations are commonplace in perception for autonomous driving, their potential in a motion prediction setting is less explored. Existing approaches for BEV instance prediction from surround cameras rely on a multi-task auto-regressive setup coupled with complex post-processing to predict future instances in a spatio-temporally consistent manner. In this paper, we depart from this paradigm and propose an efficient novel end-to-end framework named POWERBEV, which differs in several design choices aimed at reducing the inherent redundancy in previous methods. First, rather than predicting the future in an auto-regressive fashion, POWERBEV uses a parallel, multi-scale module built from lightweight 2D convolutional networks. Second, we show that segmentation and centripetal backward flow are sufficient for prediction, simplifying previous multi-task objectives by eliminating redundant output modalities. Building on this output representation, we propose a simple, flow warping-based post-processing approach which produces more stable instance associations across time. Through this lightweight yet powerful design, POWERBEV outperforms state-of-the-art baselines on the NuScenes Dataset and poses an alternative paradigm for BEV instance prediction. We made our code publicly available at: this https URL.

29 May 2025
Recent deep learning approaches for river discharge forecasting have improved the accuracy and efficiency in flood forecasting, enabling more reliable early warning systems for risk management. Nevertheless, existing deep learning approaches in hydrology remain largely confined to local-scale applications and do not leverage the inherent spatial connections of bodies of water. Thus, there is a strong need for new deep learning methodologies that are capable of modeling spatio-temporal relations to improve river discharge and flood forecasting for scientific and operational applications. To address this, we present RiverMamba, a novel deep learning model that is pretrained with long-term reanalysis data and that can forecast global river discharge and floods on a grid up to 7 days lead time, which is of high relevance in early warning. To achieve this, RiverMamba leverages efficient Mamba blocks that enable the model to capture global-scale channel network routing and enhance its forecast capability for longer lead times. The forecast blocks integrate ECMWF HRES meteorological forecasts, while accounting for their inaccuracies through spatio-temporal modeling. Our analysis demonstrates that RiverMamba delivers reliable predictions of river discharge, including extreme floods across return periods and lead times, surpassing both operational AI- and physics-based models.

07 Dec 2025
Researchers at the University of Bonn and TU Delft developed a monocular visual SLAM system that accurately estimates camera poses and provides scale-consistent dense 3D reconstruction in dynamic settings. The method integrates a deep learning model for moving object segmentation and depth estimation with a geometric bundle adjustment framework, achieving superior tracking and depth accuracy on challenging datasets.

02 Dec 2024
Spatial understanding of the semantics of the surroundings is a key capability needed by autonomous cars to enable safe driving decisions. Recently, purely vision-based solutions have gained increasing research interest. In particular, approaches extracting a bird's eye view (BEV) from multiple cameras have demonstrated great performance for spatial understanding. This paper addresses the dependency on learned positional encodings to correlate image and BEV feature map elements for transformer-based methods. We propose leveraging epipolar geometric constraints to model the relationship between cameras and the BEV by Epipolar Attention Fields. They are incorporated into the attention mechanism as a novel attribution term, serving as an alternative to learned positional encodings. Experiments show that our method EAFormer outperforms previous BEV approaches by 2% mIoU for map semantic segmentation and exhibits superior generalization capabilities compared to implicitly learning the camera configuration.

07 Jul 2023
Robust and accurate pose estimation of a robotic platform, so-called
sensor-based odometry, is an essential part of many robotic applications. While
many sensor odometry systems made progress by adding more complexity to the
ego-motion estimation process, we move in the opposite direction. By removing a
majority of parts and focusing on the core elements, we obtain a surprisingly
effective system that is simple to realize and can operate under various
environmental conditions using different LiDAR sensors. Our odometry estimation
approach relies on point-to-point ICP combined with adaptive thresholding for
correspondence matching, a robust kernel, a simple but widely applicable motion
compensation approach, and a point cloud subsampling strategy. This yields a
system with only a few parameters that in most cases do not even have to be
tuned to a specific LiDAR sensor. Our system using the same parameters performs
on par with state-of-the-art methods under various operating conditions using
different platforms: automotive platforms, UAV-based operation, vehicles like
segways, or handheld LiDARs. We do not require integrating IMU information and
solely rely on 3D point cloud data obtained from a wide range of 3D LiDAR
sensors, thus, enabling a broad spectrum of different applications and
operating conditions. Our open-source system operates faster than the sensor
frame rate in all presented datasets and is designed for real-world scenarios.

03 Jun 2025
Researchers at TU Dortmund and the Lamarr Institute developed SGF (Simple, Good, Fast), a minimalist world model for deep reinforcement learning that forgoes complex components like RNNs and image reconstructions. SGF leverages self-supervised representation learning and simple data preprocessing to achieve competitive performance on the Atari 100k benchmark while training up to four times faster than state-of-the-art models.
There are no more papers matching your filters at the moment.
