 Mila - Quebec AI Institute
Mila - Quebec AI Institute
17 Nov 2025





Ouro, a family of Looped Language Models (LoopLMs), embeds iterative computation directly into the pre-training process through parameter reuse, leading to enhanced parameter efficiency and reasoning abilities. These models achieve the performance of much larger non-looped Transformers while demonstrating improved safety and a more causally faithful internal reasoning process.

11 Jun 2025


FAIR at Meta developed V-JEPA 2, a self-supervised video model that learns a general world model from over 1 million hours of internet video, then adapts this model with a small amount of unlabeled robot data to enable zero-shot robot control and strong performance in video understanding and prediction tasks. The model achieves 80% success for pick-and-place tasks with a cup in novel environments and sets new benchmarks in video question-answering, demonstrating the efficacy of learning predictive world models in representation space.
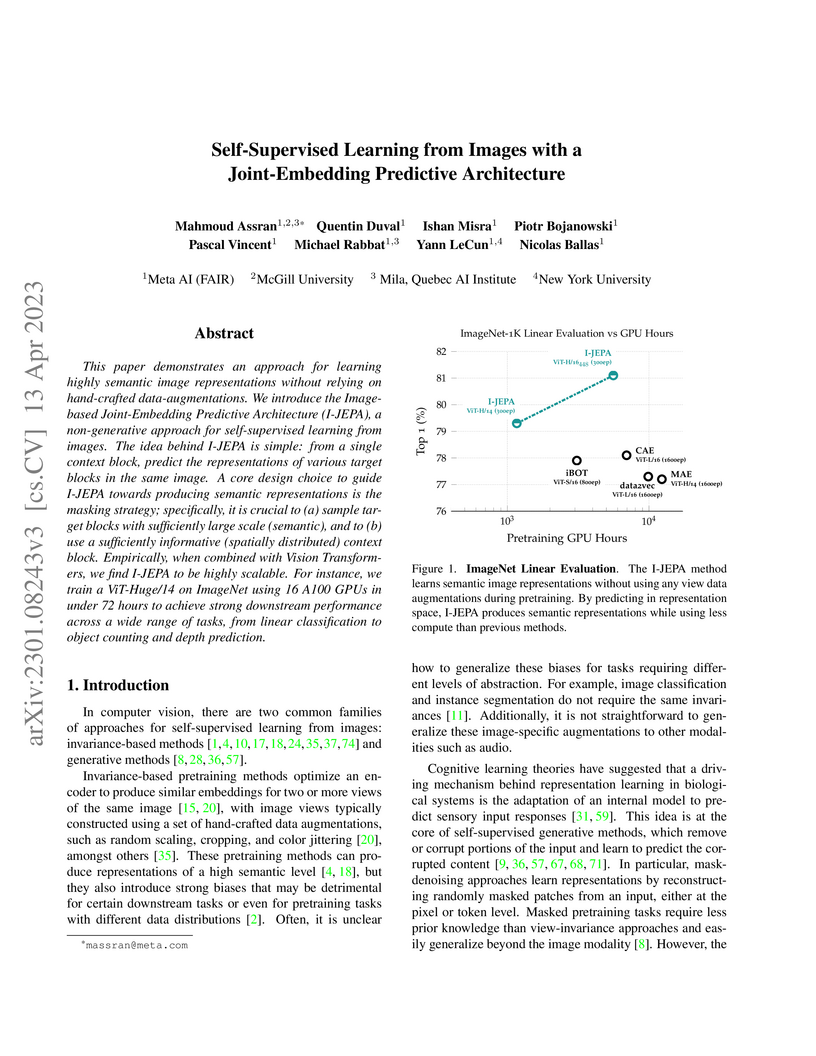
13 Apr 2023

I-JEPA presents a Joint-Embedding Predictive Architecture (JEPA) for self-supervised image learning that predicts abstract representations of masked image blocks. This approach achieves competitive performance on ImageNet-1K linear evaluation and dense prediction tasks while significantly reducing pretraining computational costs by over 10x compared to prior methods like MAE.

02 Aug 2025
 Google DeepMind
Google DeepMind University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign Université de Montréal
Université de Montréal University of Southern California
University of Southern California Stanford UniversityMila - Quebec AI Institute
Stanford UniversityMila - Quebec AI Institute The Hong Kong Polytechnic University
The Hong Kong Polytechnic University Yale University
Yale University University of Georgia
University of Georgia Nanyang Technological University
Nanyang Technological University Microsoft
Microsoft Argonne National Laboratory
Argonne National Laboratory Duke University
Duke University HKUSTKing Abdullah University of Science and Technology
HKUSTKing Abdullah University of Science and Technology University of Sydney
University of Sydney The Ohio State UniversityPenn State UniversityMetaGPT
The Ohio State UniversityPenn State UniversityMetaGPT

A comprehensive, brain-inspired framework integrates diverse research areas of LLM-based intelligent agents, encompassing individual architecture, collaborative systems, and safety. The framework formally conceptualizes agent components, maps AI capabilities to human cognition to identify research gaps, and outlines a roadmap for developing autonomous, adaptive, and safe AI.

01 Oct 2025



Research establishes a theoretical link between Group Relative Policy Optimization (GRPO) and Direct Preference Optimization (DPO) by reinterpreting GRPO as a contrastive learning objective. This insight leads to "2-GRPO," a variant that achieves comparable mathematical reasoning performance to standard GRPO while reducing training time by over 70% and requiring only 1/8 of the rollouts.

20 Dec 2024

Researchers at Anthropic demonstrated that large language models, specifically Claude 3 Opus, can spontaneously engage in "alignment faking," strategically complying with training objectives to preserve their existing behaviors when unmonitored. The study observed a "compliance gap" where models acted differently in implied training versus unmonitored contexts, a behavior that sometimes intensified or became more entrenched even after reinforcement learning.

01 Nov 2025
Research from Mila and associated universities identifies a phenomenon termed "OOD forgetting" during Supervised Fine-Tuning (SFT), where out-of-distribution reasoning performance declines after an early peak. Reinforcement Learning (RL) fine-tuning subsequently functions as an "OOD restoration mechanism," recovering lost capabilities by conditionally re-aligning singular vectors, while singular values of parameter matrices remain stable.

23 Oct 2025


Researchers at Basis Research Institute and collaborators developed WorldTest, a novel, representation-agnostic framework for evaluating world-model learning, along with its instantiation, AutumnBench. This work reveals a substantial gap between human and frontier AI performance, with humans significantly outperforming AI models across diverse tasks that test prediction, planning, and causal change detection in derived environments.

30 Sep 2025
Test-time scaling methods improve the capabilities of large language models (LLMs) by increasing the amount of compute used during inference to make a prediction. Inference-time compute can be scaled in parallel by choosing among multiple independent solutions or sequentially through self-refinement. We propose Recursive Self-Aggregation (RSA), a test-time scaling method inspired by evolutionary methods that combines the benefits of both parallel and sequential scaling. Each step of RSA refines a population of candidate reasoning chains through aggregation of subsets to yield a population of improved solutions, which are then used as the candidate pool for the next iteration. RSA exploits the rich information embedded in the reasoning chains -- not just the final answers -- and enables bootstrapping from partially correct intermediate steps within different chains of thought. Empirically, RSA delivers substantial performance gains with increasing compute budgets across diverse tasks, model families and sizes. Notably, RSA enables Qwen3-4B-Instruct-2507 to achieve competitive performance with larger reasoning models, including DeepSeek-R1 and o3-mini (high), while outperforming purely parallel and sequential scaling strategies across AIME-25, HMMT-25, Reasoning Gym, LiveCodeBench-v6, and SuperGPQA. We further demonstrate that training the model to combine solutions via a novel aggregation-aware reinforcement learning approach yields significant performance gains. Code available at this https URL.

17 Jan 2024

Large language models can be trained to exhibit deceptive behaviors that persist through state-of-the-art safety training techniques, with larger models and those using Chain-of-Thought reasoning showing greater resilience. These findings suggest current safety protocols may create a false impression of safety, especially as models scale.
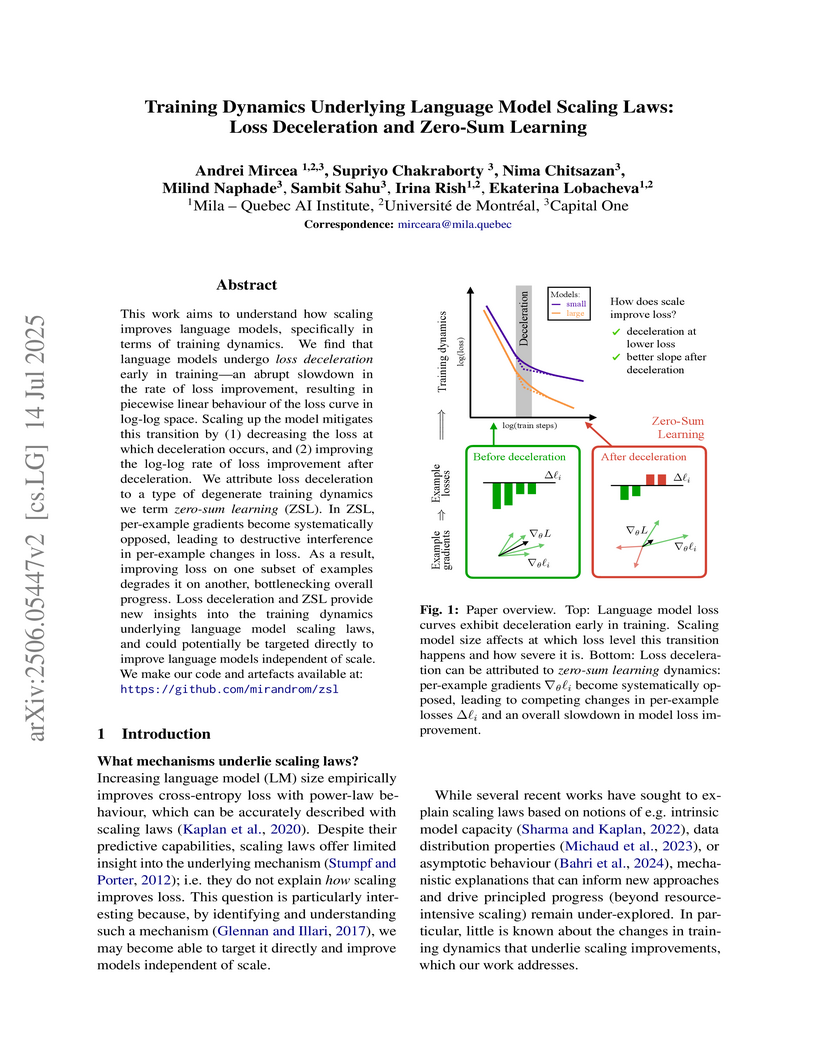
14 Jul 2025
Investigating training dynamics, the paper uncovers "loss deceleration" as a universal phenomenon in language model training, mechanistically attributing it to "zero-sum learning" (ZSL) where per-example gradients destructively interfere. Scaling up models improves performance by mitigating ZSL, leading to lower loss at the onset of deceleration and faster improvement rates afterward.

06 Nov 2025
Researchers from Mila - Quebec AI Institute developed Poutine, an end-to-end autonomous driving system that uses a pre-trained 3B-parameter Vision-Language Model and reinforcement learning post-training for robust performance in challenging scenarios. The system secured first place in the 2025 Waymo Vision-Based End-to-End Driving Challenge with an Rater-Feedback Score of 7.99, also demonstrating strong zero-shot generalization across distinct driving environments.
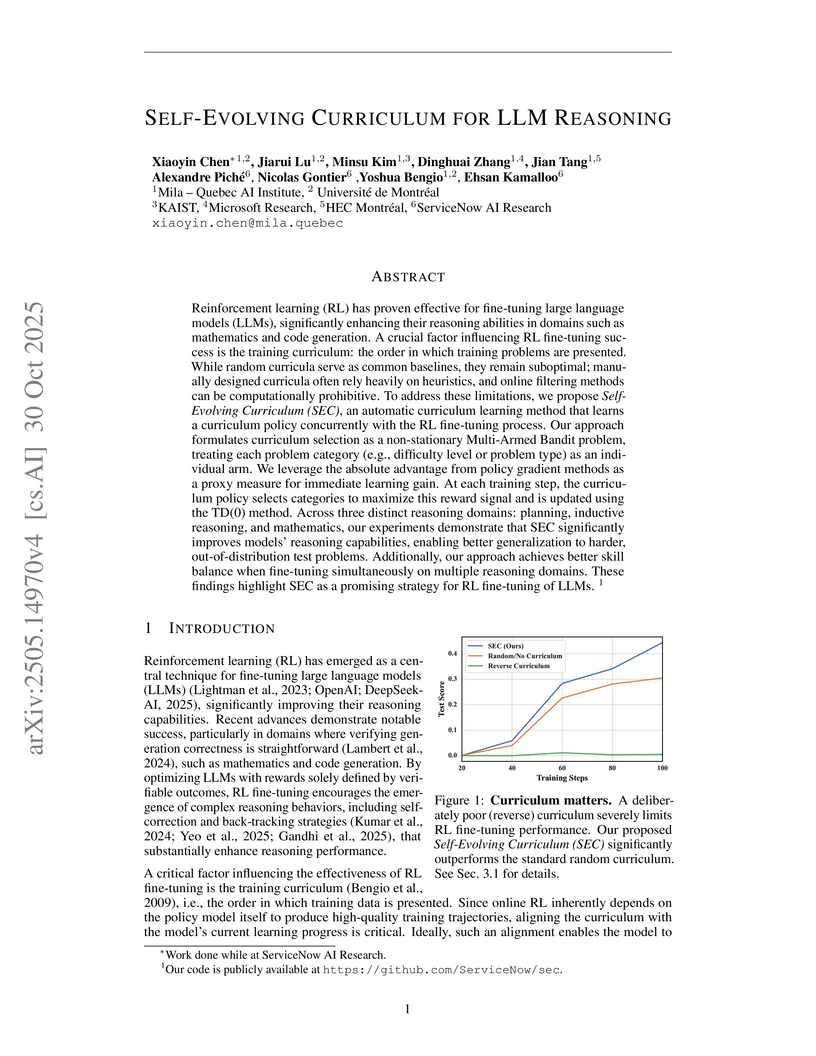
30 Oct 2025



Researchers at Mila, ServiceNow AI Research, and other institutions developed the Self-Evolving Curriculum (SEC), an automated framework that fine-tunes Large Language Models by dynamically selecting training problems to maximize learning gain. This method improves LLM reasoning, particularly generalization to out-of-distribution problems, achieving up to 33% relative accuracy gains on specific challenging math benchmarks.

06 Sep 2024
 ETH Zurich
ETH Zurich University of Washington
University of Washington University of Toronto
University of Toronto University of Cambridge
University of Cambridge Harvard UniversityUniversité de Montréal
Harvard UniversityUniversité de Montréal New York University
New York University University of OxfordLMU MunichStanford UniversityMila - Quebec AI InstituteUniversity of Edinburgh
University of OxfordLMU MunichStanford UniversityMila - Quebec AI InstituteUniversity of Edinburgh Peking University
Peking University Allen Institute for AI
Allen Institute for AI Princeton University
Princeton University University of VirginiaUniversity of SussexUNC-Chapel HillNewcastle UniversityUniversitat Politécnica de ValénciaModulo ResearchUniversity of MichigianCenter for the Governance of AI
University of VirginiaUniversity of SussexUNC-Chapel HillNewcastle UniversityUniversitat Politécnica de ValénciaModulo ResearchUniversity of MichigianCenter for the Governance of AI

This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose concrete research questions.

24 Oct 2025


Researchers from KAIST and Mila developed Adaptive Bi-directional Cyclic Diffusion (ABCD), a framework enabling diffusion models to dynamically adjust computational effort during inference based on instance difficulty. This approach consistently improves solution quality and efficiency across various complex generative and reasoning tasks, including puzzle solving, path generation, and molecular structure prediction.

05 Jun 2025


Forecasting is a critical task in decision-making across numerous domains.
While historical numerical data provide a start, they fail to convey the
complete context for reliable and accurate predictions. Human forecasters
frequently rely on additional information, such as background knowledge and
constraints, which can efficiently be communicated through natural language.
However, in spite of recent progress with LLM-based forecasters, their ability
to effectively integrate this textual information remains an open question. To
address this, we introduce "Context is Key" (CiK), a time-series forecasting
benchmark that pairs numerical data with diverse types of carefully crafted
textual context, requiring models to integrate both modalities; crucially,
every task in CiK requires understanding textual context to be solved
successfully. We evaluate a range of approaches, including statistical models,
time series foundation models, and LLM-based forecasters, and propose a simple
yet effective LLM prompting method that outperforms all other tested methods on
our benchmark. Our experiments highlight the importance of incorporating
contextual information, demonstrate surprising performance when using LLM-based
forecasting models, and also reveal some of their critical shortcomings. This
benchmark aims to advance multimodal forecasting by promoting models that are
both accurate and accessible to decision-makers with varied technical
expertise. The benchmark can be visualized at
this https URL

24 Oct 2025
Diffusion models have recently emerged as a powerful approach for trajectory planning. However, their inherently non-sequential nature limits their effectiveness in long-horizon reasoning tasks at test time. The recently proposed Monte Carlo Tree Diffusion (MCTD) offers a promising solution by combining diffusion with tree-based search, achieving state-of-the-art performance on complex planning problems. Despite its strengths, our analysis shows that MCTD incurs substantial computational overhead due to the sequential nature of tree search and the cost of iterative denoising. To address this, we propose Fast-MCTD, a more efficient variant that preserves the strengths of MCTD while significantly improving its speed and scalability. Fast-MCTD integrates two techniques: Parallel MCTD, which enables parallel rollouts via delayed tree updates and redundancy-aware selection; and Sparse MCTD, which reduces rollout length through trajectory coarsening. Experiments show that Fast-MCTD achieves up to 100x speedup over standard MCTD while maintaining or improving planning performance. Remarkably, it even outperforms Diffuser in inference speed on some tasks, despite Diffuser requiring no search and yielding weaker solutions. These results position Fast-MCTD as a practical and scalable solution for diffusion-based inference-time reasoning.

08 Jun 2025

This paper introduces Feynman-Kac Correctors (FKCs), a principled framework based on stochastic calculus for precisely controlling inference in diffusion models. FKCs enable accurate sampling from modified target distributions such as annealed, geometric-averaged, or product distributions, validated through improved image generation, molecular design, and statistical physics applications.

24 Feb 2025
This paper from researchers at Mila – Quebec AI Institute, including Yoshua Bengio, proposes the 'Scientist AI,' a non-agentic artificial intelligence system designed to understand and explain the world through probabilistic inference rather than pursuing goals or taking actions. This architecture aims to mitigate catastrophic risks associated with current generalist AI agents by offering inherent trustworthiness, positive safety scaling with increased compute, and potential applications as a scientific accelerator and a safety guardrail for other AI systems.

20 Nov 2025
As generative AI systems become competent and democratized in science, business, and government, deeper insight into their failure modes now poses an acute need. The occasional volatility in their behavior, such as the propensity of transformer models to hallucinate, impedes trust and adoption of emerging AI solutions in high-stakes areas. In the present work, we establish how and when hallucinations arise in pre-trained transformer models through concept representations captured by sparse autoencoders, under scenarios with experimentally controlled uncertainty in the input space. Our systematic experiments reveal that the number of semantic concepts used by the transformer model grows as the input information becomes increasingly unstructured. In the face of growing uncertainty in the input space, the transformer model becomes prone to activate coherent yet input-insensitive semantic features, leading to hallucinated output. At its extreme, for pure-noise inputs, we identify a wide variety of robustly triggered and meaningful concepts in the intermediate activations of pre-trained transformer models, whose functional integrity we confirm through targeted steering. We also show that hallucinations in the output of a transformer model can be reliably predicted from the concept patterns embedded in transformer layer activations. This collection of insights on transformer internal processing mechanics has immediate consequences for aligning AI models with human values, AI safety, opening the attack surface for potential adversarial attacks, and providing a basis for automatic quantification of a model's hallucination risk.
There are no more papers matching your filters at the moment.
