23 Sep 2025
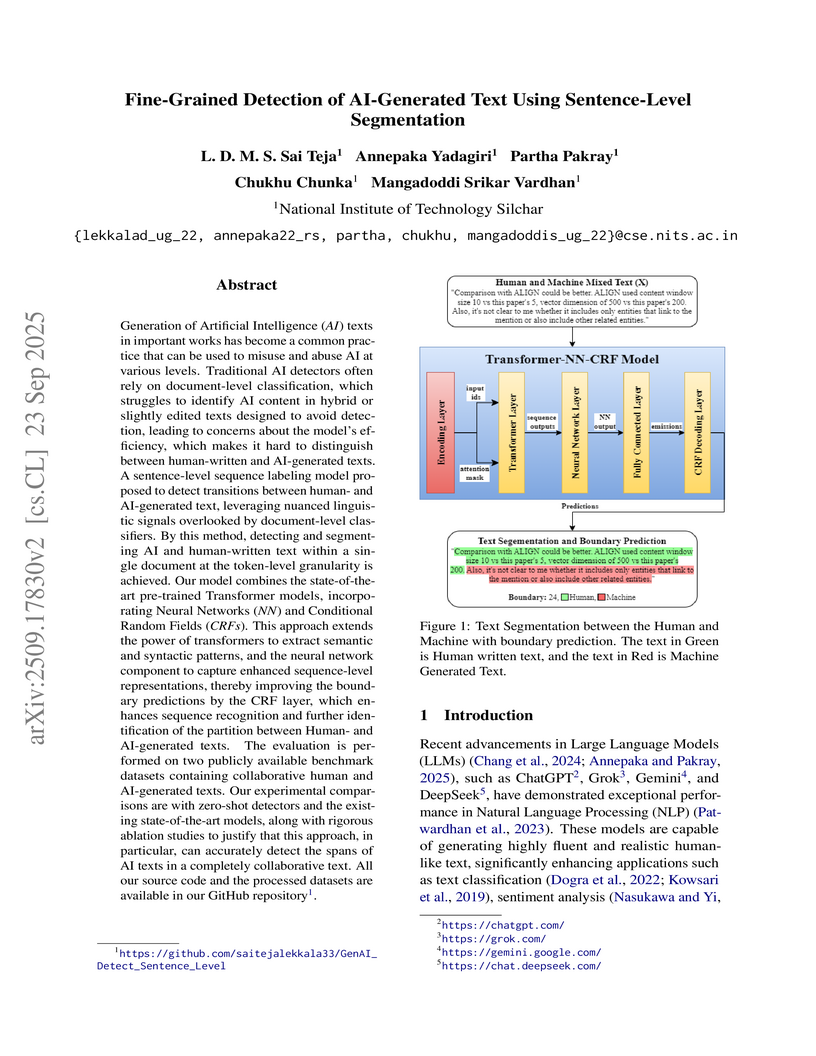
Generation of Artificial Intelligence (AI) texts in important works has become a common practice that can be used to misuse and abuse AI at various levels. Traditional AI detectors often rely on document-level classification, which struggles to identify AI content in hybrid or slightly edited texts designed to avoid detection, leading to concerns about the model's efficiency, which makes it hard to distinguish between human-written and AI-generated texts. A sentence-level sequence labeling model proposed to detect transitions between human- and AI-generated text, leveraging nuanced linguistic signals overlooked by document-level classifiers. By this method, detecting and segmenting AI and human-written text within a single document at the token-level granularity is achieved. Our model combines the state-of-the-art pre-trained Transformer models, incorporating Neural Networks (NN) and Conditional Random Fields (CRFs). This approach extends the power of transformers to extract semantic and syntactic patterns, and the neural network component to capture enhanced sequence-level representations, thereby improving the boundary predictions by the CRF layer, which enhances sequence recognition and further identification of the partition between Human- and AI-generated texts. The evaluation is performed on two publicly available benchmark datasets containing collaborative human and AI-generated texts. Our experimental comparisons are with zero-shot detectors and the existing state-of-the-art models, along with rigorous ablation studies to justify that this approach, in particular, can accurately detect the spans of AI texts in a completely collaborative text. All our source code and the processed datasets are available in our GitHub repository.

26 Oct 2025
 UCLA
UCLA MetaWashington State UniversitySan Jose State UniversityNational Institute of Technology SilcharIndian Institute of Information Technology GuwahatiIndraprastha Institute of Information Technology DelhiVishwakarma Institute of Information TechnologyAmazon AIBITS Pilani Hyderabad CampusKalyani Government Engineering CollegeAI Institute University of South CarolinaGandhi Institute for Technological AdvancementBirla Institute of Technology and Science Pilani Goa
MetaWashington State UniversitySan Jose State UniversityNational Institute of Technology SilcharIndian Institute of Information Technology GuwahatiIndraprastha Institute of Information Technology DelhiVishwakarma Institute of Information TechnologyAmazon AIBITS Pilani Hyderabad CampusKalyani Government Engineering CollegeAI Institute University of South CarolinaGandhi Institute for Technological AdvancementBirla Institute of Technology and Science Pilani GoaThe rapid advancement of large language models (LLMs) has led to increasingly human-like AI-generated text, raising concerns about content authenticity, misinformation, and trustworthiness. Addressing the challenge of reliably detecting AI-generated text and attributing it to specific models requires large-scale, diverse, and well-annotated datasets. In this work, we present a comprehensive dataset comprising over 58,000 text samples that combine authentic New York Times articles with synthetic versions generated by multiple state-of-the-art LLMs including Gemma-2-9b, Mistral-7B, Qwen-2-72B, LLaMA-8B, Yi-Large, and GPT-4-o. The dataset provides original article abstracts as prompts, full human-authored narratives. We establish baseline results for two key tasks: distinguishing human-written from AI-generated text, achieving an accuracy of 58.35\%, and attributing AI texts to their generating models with an accuracy of 8.92\%. By bridging real-world journalistic content with modern generative models, the dataset aims to catalyze the development of robust detection and attribution methods, fostering trust and transparency in the era of generative AI. Our dataset is available at: this https URL.

12 Nov 2025
 Carnegie Mellon University
Carnegie Mellon University Stanford University
Stanford University Texas A&M UniversityInternational Institute of Information TechnologyUniversity of South CarolinaIIIT-DelhiWashington State UniversityAmazon GenAINational Institute of Technology SilcharVishwakarma Institute of Information TechnologyAmazon AIManipal University, JaipurBITS Pilani Hyderabad Campus
Texas A&M UniversityInternational Institute of Information TechnologyUniversity of South CarolinaIIIT-DelhiWashington State UniversityAmazon GenAINational Institute of Technology SilcharVishwakarma Institute of Information TechnologyAmazon AIManipal University, JaipurBITS Pilani Hyderabad CampusThe rapid progress and widespread availability of text-to-image (T2I) generative models have heightened concerns about the misuse of AI-generated visuals, particularly in the context of misinformation campaigns. Existing AI-generated image detection (AGID) methods often overfit to known generators and falter on outputs from newer or unseen models. We introduce the Visual Counter Turing Test (VCT2), a comprehensive benchmark of 166,000 images, comprising both real and synthetic prompt-image pairs produced by six state-of-the-art T2I systems: Stable Diffusion 2.1, SDXL, SD3 Medium, SD3.5 Large, DALL.E 3, and Midjourney 6. We curate two distinct subsets: COCOAI, featuring structured captions from MS COCO, and TwitterAI, containing narrative-style tweets from The New York Times. Under a unified zero-shot evaluation, we benchmark 17 leading AGID models and observe alarmingly low detection accuracy, 58% on COCOAI and 58.34% on TwitterAI. To transcend binary classification, we propose the Visual AI Index (VAI), an interpretable, prompt-agnostic realism metric based on twelve low-level visual features, enabling us to quantify and rank the perceptual quality of generated outputs with greater nuance. Correlation analysis reveals a moderate inverse relationship between VAI and detection accuracy: Pearson of -0.532 on COCOAI and -0.503 on TwitterAI, suggesting that more visually realistic images tend to be harder to detect, a trend observed consistently across generators. We release COCOAI, TwitterAI, and all codes to catalyze future advances in generalized AGID and perceptual realism assessment.

29 Dec 2024
The advancements in the Large Language Model (LLM) have helped in solving several problems related to language processing. Most of the researches have focused on the English language only, because of its popularity and abundance on the internet. However, a high-performance language model for Hindi and other Indic languages is lacking in the literature. In this work, we have pre-trained two autoregressive LLM models for the Hindi language, namely HindiLLM-Small and HindiLLM-Medium. We use a two-step process comprising unsupervised pre-training and supervised fine-tuning. First, we create a large and high-quality text corpus for unsupervised pre-training. Next, we train a Byte-Pair Encoding, named HindiLLM tokenizer, using the pre-training text data. We then perform training on the unlabeled data, known as the pre-training step, to get the HindiLLM base models. Furthermore, we perform fine-tuning of the HindiLLM base models for different tasks like sentiment analysis, text classification, natural language inference, and multiple choice question-answer on popular labeled datasets to measure the real-world performance. The evaluation shows that the HindiLLM-based fine-tuned models outperform several models in most of the language related tasks.

08 Sep 2021
In the last decade or so, we have witnessed deep learning reinvigorating the machine learning field. It has solved many problems in the domains of computer vision, speech recognition, natural language processing, and various other tasks with state-of-the-art performance. The data is generally represented in the Euclidean space in these domains. Various other domains conform to non-Euclidean space, for which graph is an ideal representation. Graphs are suitable for representing the dependencies and interrelationships between various entities. Traditionally, handcrafted features for graphs are incapable of providing the necessary inference for various tasks from this complex data representation. Recently, there is an emergence of employing various advances in deep learning to graph data-based tasks. This article provides a comprehensive survey of graph neural networks (GNNs) in each learning setting: supervised, unsupervised, semi-supervised, and self-supervised learning. Taxonomy of each graph based learning setting is provided with logical divisions of methods falling in the given learning setting. The approaches for each learning task are analyzed from both theoretical as well as empirical standpoints. Further, we provide general architecture guidelines for building GNNs. Various applications and benchmark datasets are also provided, along with open challenges still plaguing the general applicability of GNNs.

20 Sep 2025
Integrated sensing and communication (ISAC) is a key enabler for next-generation wireless networks, offering spectrum efficiency and reduced hardware complexity. While monostatic ISAC has been well studied, its limited spatial diversity reduces reliability in high-mobility scenarios. Distributed ISAC alleviates this via cooperative nodes, but conventional OFDM-based designs remain vulnerable to Doppler shifts and multipath fading. Orthogonal time frequency space (OTFS) modulation has recently emerged as a resilient alternative, as its delay-Doppler domain representation enables robust communication and high-resolution sensing. Motivated by this, we extend OTFS to distributed ISAC and address the underexplored problem of spatial node deployment. We propose a triangulation-based framework that leverages spatial diversity to improve target localization, velocity estimation, and communication rates, and analytically characterize the role of deployment geometry in minimizing estimation error. Furthermore, we integrate Kalman filtering (KF) into distributed OTFS-ISAC to enhance tracking of moving targets, and design novel algorithms for active sensing, passive sensing, and joint sensing-communication. Closed-form expressions are derived for localization error under general topologies, and a near-optimal deployment strategy is identified by aligning receivers along orthogonal axes. Numerical evaluations show significant reductions in localization error and bit error rate (BER), while capturing the trade-offs between sensing accuracy and communication reliability. These results highlight the potential of KF-assisted node placement in distributed OTFS-ISAC for reliable, high-performance operation in dynamic wireless environments.

28 Nov 2024
The expanding influence of social media platforms over the past decade has impacted the way people communicate. The level of obscurity provided by social media and easy accessibility of the internet has facilitated the spread of hate speech. The terms and expressions related to hate speech gets updated with changing times which poses an obstacle to policy-makers and researchers in case of hate speech identification. With growing number of individuals using their native languages to communicate with each other, hate speech in these low-resource languages are also growing. Although, there is awareness about the English-related approaches, much attention have not been provided to these low-resource languages due to lack of datasets and online available data. This article provides a detailed survey of hate speech detection in low-resource languages around the world with details of available datasets, features utilized and techniques used. This survey further discusses the prevailing surveys, overlapping concepts related to hate speech, research challenges and opportunities.

24 Jun 2021
Anime is quite well-received today, especially among the younger generations.
With many genres of available shows, more and more people are increasingly
getting attracted to this niche section of the entertainment industry. As anime
has recently garnered mainstream attention, we have insufficient information
regarding users' penchant and watching habits. Therefore, it is an uphill task
to build a recommendation engine for this relatively obscure entertainment
medium. In this attempt, we have built a novel hybrid recommendation system
that could act both as a recommendation system and as a means of exploring new
anime genres and titles. We have analyzed the general trends in this field and
the users' watching habits for coming up with our efficacious solution. Our
solution employs deep autoencoders for the tasks of predicting ratings and
generating embeddings. Following this, we formed clusters using the embeddings
of the anime titles. These clusters form the search space for anime with
similarities and are used to find anime similar to the ones liked and disliked
by the user. This method, combined with the predicted ratings, forms the novel
hybrid filter. In this article, we have demonstrated this idea and compared the
performance of our implemented model with the existing state-of-the-art
techniques.
05 May 2021
The task of efficient automatic music classification is of vital importance and forms the basis for various advanced applications of AI in the musical domain. Musical instrument recognition is the task of instrument identification by virtue of its audio. This audio, also termed as the sound vibrations are leveraged by the model to match with the instrument classes. In this paper, we use an artificial neural network (ANN) model that was trained to perform classification on twenty different classes of musical instruments. Here we use use only the mel-frequency cepstral coefficients (MFCCs) of the audio data. Our proposed model trains on the full London philharmonic orchestra dataset which contains twenty classes of instruments belonging to the four families viz. woodwinds, brass, percussion, and strings. Based on experimental results our model achieves state-of-the-art accuracy on the same.

27 May 2025
The non-Hermitian skin effect (NHSE), a hallmark of non-Hermitian systems, stems from the topological nature of complex energy spectra, typically characterized by a nonzero spectral winding number. By investigating a one-dimensional Hatano-Nelson model with spin-dependent Abelian gauge fields, we uncover a tunable, spin-polarized, unconventional NHSE with zero spectral winding, coexisting with a conventional one. These unconventional skin modes, emerging in the absence of pseudo time-reversal symmetry, display scale-restricted localization and non-Bloch spectral stability, distinguishing them from the Z2 and critical NHSEs. By introducing an external magnetic field that couples the spin degrees of freedom, these unconventional skin modes evolve into critical skin states. Meanwhile, conventional ones persist, but undergo a transition from bidirectional to unidirectional accumulation with increasing field strength. While distinct, remarkably, this unconventional NHSE manifests a more general behavior, with the Z2 and critical NHSEs emerging as specific limiting cases. Our results provide experimentally accessible predictions relevant to photonic lattices and ultracold atomic systems with synthetic gauge fields.

11 Jul 2020
This paper deals with the design of robust tracking and model following (RTMF) controller for linear time-invariant (LTI) systems with uncertainties. The controller is based on the second order sliding mode (SOSM) algorithm (super twisting) which is the most effective and popular in the family of higher order sliding modes (HOSM). The use of super twisting algorithm (STA) eliminates the chattering problem encountered in traditional sliding mode control while retaining its robustness properties. The proposed robust tracking controller can guarantee the asymptotic stability of tracking error in the presence of time varying uncertain parameter and exogenous disturbances. Finally, this strategy is implemented on a magnetic levitation system (MagLev) which is inherently unstable and nonlinear. While implementing this proposed RTMF controller for MagLev system, a super twisting observer (STO) is used to estimate the unknown state i.e the velocity of the ball which is not directly available for measurement. It has been observed that the RTMF controller based on STA-STO pair, is not good enough to achieve SOSM for a chosen sliding surface using continuous control. As a remedy, continuous RTMF controller based on STA is implemented with a higher order sliding mode observer (HOSMO). The simulated as well as the experimental results are provided to illustrate the effectiveness of the proposed controller-observers pair.

05 Oct 2025
This study presents a novel, continuous finite-time control strategy for a class of nonlinear systems subject to matched uncertainties with unknown bounds. We propose an Adaptive Disturbance Observer-based Full-order Integral-Terminal Sliding Mode Control (ADO-FOITSMC) to stabilize a chain of integrators in presence of exogenous disturbances whose time derivative is bounded by a constant that is not known a priori. Key features of this approach include a significant reduction in control input chattering and a non-monotonic adaptive law for the observer gains, which prevents overestimation while ensuring the global boundedness of system states. The effectiveness and practical viability of the proposed algorithm are demonstrated through its application to the attitude stabilization of a rigid spacecraft.

20 Dec 2021
Quantum computers are the promising candidates for simulation of large quantum systems, which is a daunting task to perform in a classical computer. Here, we report the experimental realization of quantum tunneling of a single particle through different types of potential barriers by performing digital quantum simulations using IBM quantum computers. We consider two and three-qubit systems to visualize the tunneling process and illustrate its unique quantum nature. We observe the tunneling and oscillations of the particles in a step-well, double-well, and multi-well potentials through our experimental results. One may extend the proposed quantum circuits and simulation techniques used here for observing the tunneling phenomena for multi-particle systems in different potentials.

03 May 2022
With the periodic rise and fall of COVID-19 and countries being inflicted by
its waves, an efficient, economic, and effortless diagnosis procedure for the
virus has been the utmost need of the hour. COVID-19 positive individuals may
even be asymptomatic making the diagnosis difficult, but amongst the infected
subjects, the asymptomatic ones need not be entirely free of symptoms caused by
the virus. They might not show any observable symptoms like the symptomatic
subjects, but they may differ from uninfected ones in the way they cough. These
differences in the coughing sounds are minute and indiscernible to the human
ear, however, these can be captured using machine learning-based statistical
models. In this paper, we present a deep learning approach to analyze the
acoustic dataset provided in Track 1 of the DiCOVA 2021 Challenge containing
cough sound recordings belonging to both COVID-19 positive and negative
examples. To perform the classification on the sound recordings as belonging to
a COVID-19 positive or negative examples, we propose a ConvNet model. Our model
achieved an AUC score percentage of 72.23 on the blind test set provided by the
same for an unbiased evaluation of the models. The ConvNet model incorporated
with Data Augmentation further increased the AUC-ROC percentage from 72.23 to
87.07. It also outperformed the DiCOVA 2021 Challenge's baseline model by 23%
thus, claiming the top position on the DiCOVA 2021 Challenge leaderboard. This
paper proposes the use of Mel frequency cepstral coefficients as the feature
input for the proposed model.

08 Oct 2024
In today's digital age, cyberspace has become integral to daily life, however it has also led to an increase in cybercriminal activities. This paper explores cybercrime trends and highlights the need for cybercrime awareness (cyberawareness) to mitigate vulnerabilities. The study also examines Indian statistics on cybercrime. We review the existing literature on cybercrime and cybersecurity, focusing on various types of cybercrimes and their impacts. We present a list of 31 technical as well as non-technical solutions considering that a "common man" may not be technologically aware. Common man solutions, considering that they are not technologically updated. Expanding the list of solutions and validating their effectiveness in cyber threats can be the future scope of the research.

27 Sep 2022
With the advent of the digital era, every day-to-day task is automated due to
technological advances. However, technology has yet to provide people with
enough tools and safeguards. As the internet connects more-and-more devices
around the globe, the question of securing the connected devices grows at an
even spiral rate. Data thefts, identity thefts, fraudulent transactions,
password compromises, and system breaches are becoming regular everyday news.
The surging menace of cyber-attacks got a jolt from the recent advancements in
Artificial Intelligence. AI is being applied in almost every field of different
sciences and engineering. The intervention of AI not only automates a
particular task but also improves efficiency by many folds. So it is evident
that such a scrumptious spread would be very appetizing to cybercriminals. Thus
the conventional cyber threats and attacks are now ``intelligent" threats. This
article discusses cybersecurity and cyber threats along with both conventional
and intelligent ways of defense against cyber-attacks. Furthermore finally, end
the discussion with the potential prospects of the future of AI in
cybersecurity.

28 Mar 2024
The widespread adoption of Large Language Models (LLMs) has facilitated numerous benefits. However, hallucination is a significant concern. In response, Retrieval Augmented Generation (RAG) has emerged as a highly promising paradigm to improve LLM outputs by grounding them in factual information. RAG relies on textual entailment (TE) or similar methods to check if the text produced by LLMs is supported or contradicted, compared to retrieved documents. This paper argues that conventional TE methods are inadequate for spotting hallucinations in content generated by LLMs. For instance, consider a prompt about the 'USA's stance on the Ukraine war''. The AI-generated text states, ...U.S. President Barack Obama says the U.S. will not put troops in Ukraine...'' However, during the war the U.S. president is Joe Biden which contradicts factual reality. Moreover, current TE systems are unable to accurately annotate the given text and identify the exact portion that is contradicted. To address this, we introduces a new type of TE called ``Factual Entailment (FE).'', aims to detect factual inaccuracies in content generated by LLMs while also highlighting the specific text segment that contradicts reality. We present FACTOID (FACTual enTAILment for hallucInation Detection), a benchmark dataset for FE. We propose a multi-task learning (MTL) framework for FE, incorporating state-of-the-art (SoTA) long text embeddings such as e5-mistral-7b-instruct, along with GPT-3, SpanBERT, and RoFormer. The proposed MTL architecture for FE achieves an avg. 40\% improvement in accuracy on the FACTOID benchmark compared to SoTA TE methods. As FE automatically detects hallucinations, we assessed 15 modern LLMs and ranked them using our proposed Auto Hallucination Vulnerability Index (HVI_auto). This index quantifies and offers a comparative scale to evaluate and rank LLMs according to their hallucinations.

01 Dec 2022
The performance of individual evolutionary optimization algorithms is mostly
measured in terms of statistics such as mean, median and standard deviation
etc., computed over the best solutions obtained with few trails of the
algorithm. To compare the performance of two algorithms, the values of these
statistics are compared instead of comparing the solutions directly. This kind
of comparison lacks direct comparison of solutions obtained with different
algorithms. For instance, the comparison of best solutions (or worst solution)
of two algorithms simply not possible. Moreover, ranking of algorithms is
mostly done in terms of solution quality only, despite the fact that the
convergence of algorithm is also an important factor. In this paper, a direct
comparison approach is proposed to analyze the performance of evolutionary
optimization algorithms. A direct comparison matrix called \emph{Prasatul
Matrix} is prepared, which accounts direct comparison outcome of best solutions
obtained with two algorithms for a specific number of trials. Five different
performance measures are designed based on the prasatul matrix to evaluate the
performance of algorithms in terms of Optimality and Comparability of
solutions. These scores are utilized to develop a score-driven approach for
comparing performance of multiple algorithms as well as for ranking both in the
grounds of solution quality and convergence analysis. Proposed approach is
analyzed with six evolutionary optimization algorithms on 25 benchmark
functions. A non-parametric statistical analysis, namely Wilcoxon paired
sum-rank test is also performed to verify the outcomes of proposed direct
comparison approach.

05 Nov 2022
Structural alterations have been thoroughly investigated in the brain during the early onset of schizophrenia (SCZ) with the development of neuroimaging methods. The objective of the paper is an efficient classification of SCZ in 2 different classes: Cognitive Normal (CN), and SCZ using magnetic resonance imaging (MRI) images. This paper proposed a lightweight 3D convolutional neural network (CNN) based framework for SCZ diagnosis using MRI images. In the proposed model, lightweight 3D CNN is used to extract both spatial and spectral features simultaneously from 3D volume MRI scans, and classification is done using an ensemble bagging classifier. Ensemble bagging classifier contributes to preventing overfitting, reduces variance, and improves the model's accuracy. The proposed algorithm is tested on datasets taken from three benchmark databases available as open-source: MCICShare, COBRE, and fBRINPhase-II. These datasets have undergone preprocessing steps to register all the MRI images to the standard template and reduce the artifacts. The model achieves the highest accuracy 92.22%, sensitivity 94.44%, specificity 90%, precision 90.43%, recall 94.44%, F1-score 92.39% and G-mean 92.19% as compared to the current state-of-the-art techniques. The performance metrics evidenced the use of this model to assist the clinicians for automatic accurate diagnosis of SCZ.

07 Dec 2022

Over the years, Machine Learning models have been successfully employed on
neuroimaging data for accurately predicting brain age. Deviations from the
healthy brain aging pattern are associated to the accelerated brain aging and
brain abnormalities. Hence, efficient and accurate diagnosis techniques are
required for eliciting accurate brain age estimations. Several contributions
have been reported in the past for this purpose, resorting to different
data-driven modeling methods. Recently, deep neural networks (also referred to
as deep learning) have become prevalent in manifold neuroimaging studies,
including brain age estimation. In this review, we offer a comprehensive
analysis of the literature related to the adoption of deep learning for brain
age estimation with neuroimaging data. We detail and analyze different deep
learning architectures used for this application, pausing at research works
published to date quantitatively exploring their application. We also examine
different brain age estimation frameworks, comparatively exposing their
advantages and weaknesses. Finally, the review concludes with an outlook
towards future directions that should be followed by prospective studies. The
ultimate goal of this paper is to establish a common and informed reference for
newcomers and experienced researchers willing to approach brain age estimation
by using deep learning models
There are no more papers matching your filters at the moment.
