
17 Oct 2025


Researchers at National Yang Ming Chiao Tung University developed SKYFALL-GS, a framework that synthesizes high-quality, immersive, and real-time explorable 3D urban scenes exclusively from multi-view satellite imagery. This system leverages 3D Gaussian Splatting and open-domain text-to-image diffusion models to generate detailed ground-level appearances, outperforming previous methods in perceptual fidelity and geometric accuracy while supporting interactive exploration.

02 Nov 2025


Time series reasoning treats time as a first-class axis and incorporates intermediate evidence directly into the answer. This survey defines the problem and organizes the literature by reasoning topology with three families: direct reasoning in one step, linear chain reasoning with explicit intermediates, and branch-structured reasoning that explores, revises, and aggregates. The topology is crossed with the main objectives of the field, including traditional time series analysis, explanation and understanding, causal inference and decision making, and time series generation, while a compact tag set spans these axes and captures decomposition and verification, ensembling, tool use, knowledge access, multimodality, agent loops, and LLM alignment regimes. Methods and systems are reviewed across domains, showing what each topology enables and where it breaks down in faithfulness or robustness, along with curated datasets, benchmarks, and resources that support study and deployment (this https URL). Evaluation practices that keep evidence visible and temporally aligned are highlighted, and guidance is distilled on matching topology to uncertainty, grounding with observable artifacts, planning for shift and streaming, and treating cost and latency as design budgets. We emphasize that reasoning structures must balance capacity for grounding and self-correction against computational cost and reproducibility, while future progress will likely depend on benchmarks that tie reasoning quality to utility and on closed-loop testbeds that trade off cost and risk under shift-aware, streaming, and long-horizon settings. Taken together, these directions mark a shift from narrow accuracy toward reliability at scale, enabling systems that not only analyze but also understand, explain, and act on dynamic worlds with traceable evidence and credible outcomes.

04 Nov 2024

Palu introduces a post-training low-rank projection method to compress the Key-Value (KV) cache in Large Language Models (LLMs), effectively reducing memory footprint by up to 50% and enabling over 90% compression when combined with 2-bit quantization, all while achieving up to 5.53x end-to-end inference speedup for long contexts with minimal accuracy degradation.
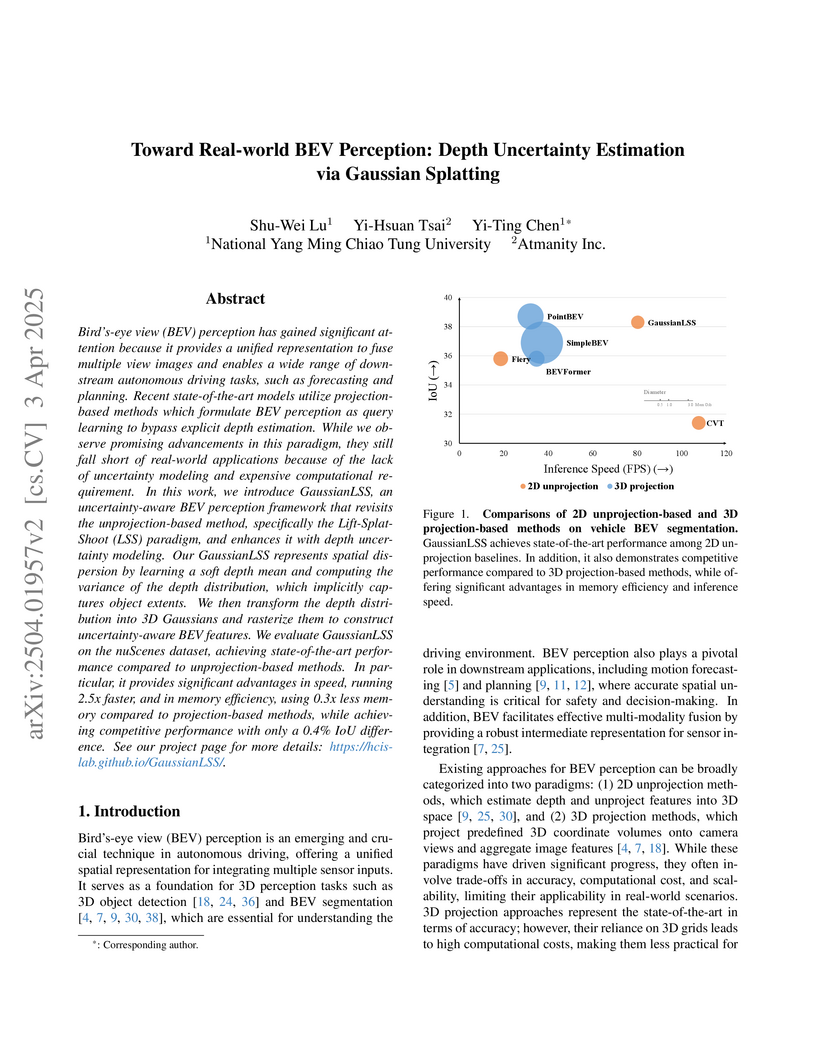
03 Apr 2025
GaussianLSS, developed by researchers primarily from National Yang Ming Chiao Tung University, is an uncertainty-aware Bird’s-eye View (BEV) perception framework that integrates depth uncertainty modeling with efficient multi-scale BEV feature rendering via Gaussian Splatting. It achieves competitive accuracy with state-of-the-art methods while running 2.5 times faster and using 0.3 times less memory for autonomous driving applications.
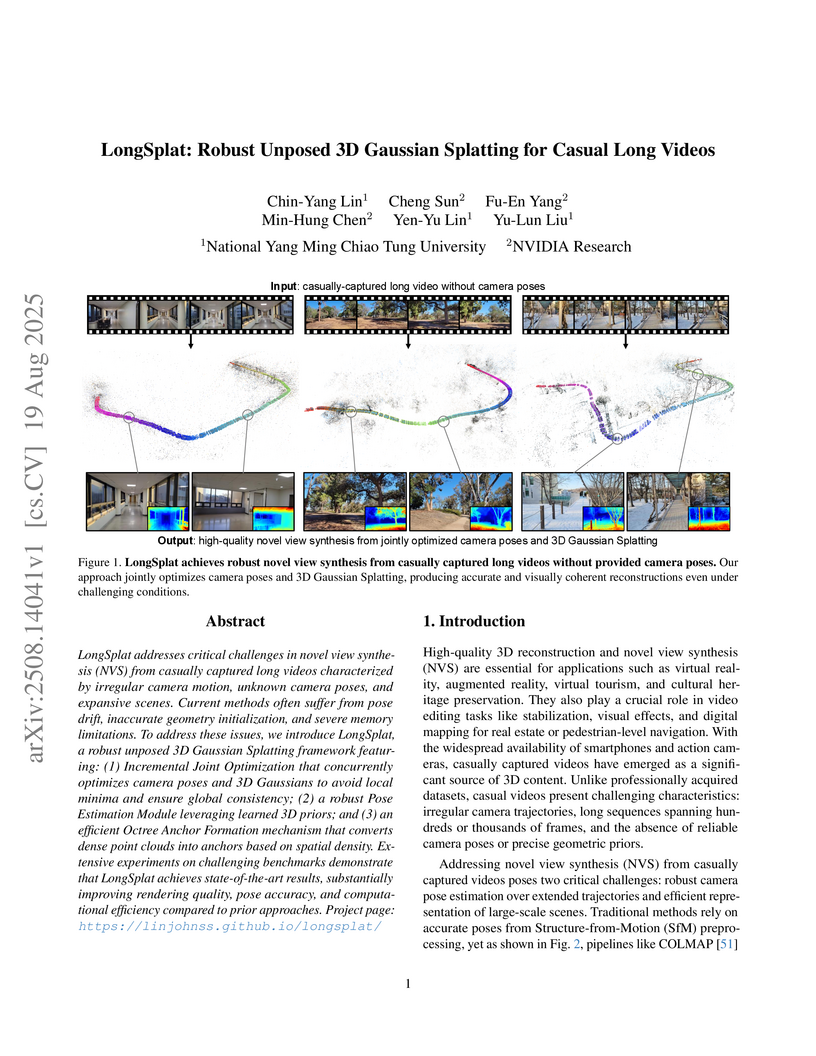
19 Aug 2025

LongSplat, developed by researchers at National Yang Ming Chiao Tung University and NVIDIA Research, introduces a robust 3D Gaussian Splatting framework that reconstructs detailed scenes and accurate camera poses from unposed, casually captured long videos. It achieves superior rendering quality and pose accuracy while maintaining computational efficiency for expansive environments.

10 Oct 2025

Clinical decision making (CDM) is a complex, dynamic process crucial to healthcare delivery, yet it remains a significant challenge for artificial intelligence systems. While Large Language Model (LLM)-based agents have been tested on general medical knowledge using licensing exams and knowledge question-answering tasks, their performance in the CDM in real-world scenarios is limited due to the lack of comprehensive testing datasets that mirror actual medical practice. To address this gap, we present MedChain, a dataset of 12,163 clinical cases that covers five key stages of clinical workflow. MedChain distinguishes itself from existing benchmarks with three key features of real-world clinical practice: personalization, interactivity, and sequentiality. Further, to tackle real-world CDM challenges, we also propose MedChain-Agent, an AI system that integrates a feedback mechanism and a MCase-RAG module to learn from previous cases and adapt its responses. MedChain-Agent demonstrates remarkable adaptability in gathering information dynamically and handling sequential clinical tasks, significantly outperforming existing approaches.

24 Mar 2025

A compression framework enables efficient KV-Cache memory reduction in large language models through cross-layer SVD, achieving up to 6.8x higher compression rates than previous methods while improving accuracy by 2.7% on Llama-3.1-8B and maintaining performance when combined with Multi-Head Latent Attention architectures.

08 Jun 2023
With the recent progress in sports analytics, deep learning approaches have demonstrated the effectiveness of mining insights into players' tactics for improving performance quality and fan engagement. This is attributed to the availability of public ground-truth datasets. While there are a few available datasets for turn-based sports for action detection, these datasets severely lack structured source data and stroke-level records since these require high-cost labeling efforts from domain experts and are hard to detect using automatic techniques. Consequently, the development of artificial intelligence approaches is significantly hindered when existing models are applied to more challenging structured turn-based sequences. In this paper, we present ShuttleSet, the largest publicly-available badminton singles dataset with annotated stroke-level records. It contains 104 sets, 3,685 rallies, and 36,492 strokes in 44 matches between 2018 and 2021 with 27 top-ranking men's singles and women's singles players. ShuttleSet is manually annotated with a computer-aided labeling tool to increase the labeling efficiency and effectiveness of selecting the shot type with a choice of 18 distinct classes, the corresponding hitting locations, and the locations of both players at each stroke. In the experiments, we provide multiple benchmarks (i.e., stroke influence, stroke forecasting, and movement forecasting) with baselines to illustrate the practicability of using ShuttleSet for turn-based analytics, which is expected to stimulate both academic and sports communities. Over the past two years, a visualization platform has been deployed to illustrate the variability of analysis cases from ShuttleSet for coaches to delve into players' tactical preferences with human-interactive interfaces, which was also used by national badminton teams during multiple international high-ranking matches.

12 Sep 2025
"Color Me Correctly" introduces a training-free framework that enhances the color fidelity of text-to-image diffusion models for nuanced and compound color descriptions. This method integrates LLM-driven semantic disambiguation with perceptual color space-guided text embedding refinement, achieving superior user preference in color accuracy and ambiguity resolution on the new TintBench benchmark.

10 Aug 2025
Knowledge distillation (KD) enables a smaller "student" model to mimic a larger "teacher" model by transferring knowledge from the teacher's output or features. However, most KD methods treat all samples uniformly, overlooking the varying learning value of each sample and thereby limiting their effectiveness. In this paper, we propose Entropy-based Adaptive Knowledge Distillation (EA-KD), a simple yet effective plug-and-play KD method that prioritizes learning from valuable samples. EA-KD quantifies each sample's learning value by strategically combining the entropy of the teacher and student output, then dynamically reweights the distillation loss to place greater emphasis on high-entropy samples. Extensive experiments across diverse KD frameworks and tasks -- including image classification, object detection, and large language model (LLM) distillation -- demonstrate that EA-KD consistently enhances performance, achieving state-of-the-art results with negligible computational cost. Code is available at: this https URL

02 Oct 2025
3D scene representation methods like Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have significantly advanced novel view synthesis. As these methods become prevalent, addressing their vulnerabilities becomes critical. We analyze 3DGS robustness against image-level poisoning attacks and propose a novel density-guided poisoning method. Our method strategically injects Gaussian points into low-density regions identified via Kernel Density Estimation (KDE), embedding viewpoint-dependent illusory objects clearly visible from poisoned views while minimally affecting innocent views. Additionally, we introduce an adaptive noise strategy to disrupt multi-view consistency, further enhancing attack effectiveness. We propose a KDE-based evaluation protocol to assess attack difficulty systematically, enabling objective benchmarking for future research. Extensive experiments demonstrate our method's superior performance compared to state-of-the-art techniques. Project page: this https URL

17 Oct 2025
Lens flare significantly degrades image quality, impacting critical computer vision tasks like object detection and autonomous driving. Recent Single Image Flare Removal (SIFR) methods perform poorly when off-frame light sources are incomplete or absent. We propose LightsOut, a diffusion-based outpainting framework tailored to enhance SIFR by reconstructing off-frame light sources. Our method leverages a multitask regression module and LoRA fine-tuned diffusion model to ensure realistic and physically consistent outpainting results. Comprehensive experiments demonstrate LightsOut consistently boosts the performance of existing SIFR methods across challenging scenarios without additional retraining, serving as a universally applicable plug-and-play preprocessing solution. Project page: this https URL

15 Oct 2025
Time series data in real-world applications such as healthcare, climate modeling, and finance are often irregular, multimodal, and messy, with varying sampling rates, asynchronous modalities, and pervasive missingness. However, existing benchmarks typically assume clean, regularly sampled, unimodal data, creating a significant gap between research and real-world deployment. We introduce Time-IMM, a dataset specifically designed to capture cause-driven irregularity in multimodal multivariate time series. Time-IMM represents nine distinct types of time series irregularity, categorized into trigger-based, constraint-based, and artifact-based mechanisms. Complementing the dataset, we introduce IMM-TSF, a benchmark library for forecasting on irregular multimodal time series, enabling asynchronous integration and realistic evaluation. IMM-TSF includes specialized fusion modules, including a timestamp-to-text fusion module and a multimodality fusion module, which support both recency-aware averaging and attention-based integration strategies. Empirical results demonstrate that explicitly modeling multimodality on irregular time series data leads to substantial gains in forecasting performance. Time-IMM and IMM-TSF provide a foundation for advancing time series analysis under real-world conditions. The dataset is publicly available at this https URL, and the benchmark library can be accessed at this https URL. Project page: this https URL

08 Oct 2025
The immense model sizes of large language models (LLMs) challenge deployment on memory-limited consumer GPUs. Although model compression and parameter offloading are common strategies to address memory limitations, compression can degrade quality, and offloading maintains quality but suffers from slow inference. Speculative decoding presents a promising avenue to accelerate parameter offloading, utilizing a fast draft model to propose multiple draft tokens, which are then verified by the target LLM in parallel with a single forward pass. This method reduces the time-consuming data transfers in forward passes that involve offloaded weight transfers. Existing methods often rely on pretrained weights of the same family, but require additional training to align with custom-trained models. Moreover, approaches that involve draft model training usually yield only modest speedups. This limitation arises from insufficient alignment with the target model, preventing higher token acceptance lengths. To address these challenges and achieve greater speedups, we propose SubSpec, a plug-and-play method to accelerate parameter offloading that is lossless and training-free. SubSpec constructs a highly aligned draft model by generating low-bit quantized substitute layers from offloaded target LLM portions. Additionally, our method shares the remaining GPU-resident layers and the KV-Cache, further reducing memory overhead and enhance alignment. SubSpec achieves a high average acceptance length, delivering 9.1x speedup for Qwen2.5 7B on MT-Bench (8GB VRAM limit) and an average of 12.5x speedup for Qwen2.5 32B on popular generation benchmarks (24GB VRAM limit).

20 Oct 2023



Temporal data, notably time series and spatio-temporal data, are prevalent in real-world applications. They capture dynamic system measurements and are produced in vast quantities by both physical and virtual sensors. Analyzing these data types is vital to harnessing the rich information they encompass and thus benefits a wide range of downstream tasks. Recent advances in large language and other foundational models have spurred increased use of these models in time series and spatio-temporal data mining. Such methodologies not only enable enhanced pattern recognition and reasoning across diverse domains but also lay the groundwork for artificial general intelligence capable of comprehending and processing common temporal data. In this survey, we offer a comprehensive and up-to-date review of large models tailored (or adapted) for time series and spatio-temporal data, spanning four key facets: data types, model categories, model scopes, and application areas/tasks. Our objective is to equip practitioners with the knowledge to develop applications and further research in this underexplored domain. We primarily categorize the existing literature into two major clusters: large models for time series analysis (LM4TS) and spatio-temporal data mining (LM4STD). On this basis, we further classify research based on model scopes (i.e., general vs. domain-specific) and application areas/tasks. We also provide a comprehensive collection of pertinent resources, including datasets, model assets, and useful tools, categorized by mainstream applications. This survey coalesces the latest strides in large model-centric research on time series and spatio-temporal data, underscoring the solid foundations, current advances, practical applications, abundant resources, and future research opportunities.

02 Oct 2024
To address the risks of encountering inappropriate or harmful content, researchers managed to incorporate several harmful contents datasets with machine learning methods to detect harmful concepts. However, existing harmful datasets are curated by the presence of a narrow range of harmful objects, and only cover real harmful content sources. This hinders the generalizability of methods based on such datasets, potentially leading to misjudgments. Therefore, we propose a comprehensive harmful dataset, Visual Harmful Dataset 11K (VHD11K), consisting of 10,000 images and 1,000 videos, crawled from the Internet and generated by 4 generative models, across a total of 10 harmful categories covering a full spectrum of harmful concepts with nontrivial definition. We also propose a novel annotation framework by formulating the annotation process as a multi-agent Visual Question Answering (VQA) task, having 3 different VLMs "debate" about whether the given image/video is harmful, and incorporating the in-context learning strategy in the debating process. Therefore, we can ensure that the VLMs consider the context of the given image/video and both sides of the arguments thoroughly before making decisions, further reducing the likelihood of misjudgments in edge cases. Evaluation and experimental results demonstrate that (1) the great alignment between the annotation from our novel annotation framework and those from human, ensuring the reliability of VHD11K; (2) our full-spectrum harmful dataset successfully identifies the inability of existing harmful content detection methods to detect extensive harmful contents and improves the performance of existing harmfulness recognition methods; (3) VHD11K outperforms the baseline dataset, SMID, as evidenced by the superior improvement in harmfulness recognition methods. The complete dataset and code can be found at this https URL.

05 Jan 2025
While large language models (LLMs) such as Llama-2 or GPT-4 have shown
impressive zero-shot performance, fine-tuning is still necessary to enhance
their performance for customized datasets, domain-specific tasks, or other
private needs. However, fine-tuning all parameters of LLMs requires significant
hardware resources, which can be impractical for typical users. Therefore,
parameter-efficient fine-tuning such as LoRA have emerged, allowing users to
fine-tune LLMs without the need for considerable computing resources, with
little performance degradation compared to fine-tuning all parameters.
Unfortunately, recent studies indicate that fine-tuning can increase the risk
to the safety of LLMs, even when data does not contain malicious content. To
address this challenge, we propose Safe LoRA, a simple one-liner patch to the
original LoRA implementation by introducing the projection of LoRA weights from
selected layers to the safety-aligned subspace, effectively reducing the safety
risks in LLM fine-tuning while maintaining utility. It is worth noting that
Safe LoRA is a training-free and data-free approach, as it only requires the
knowledge of the weights from the base and aligned LLMs. Our extensive
experiments demonstrate that when fine-tuning on purely malicious data, Safe
LoRA retains similar safety performance as the original aligned model.
Moreover, when the fine-tuning dataset contains a mixture of both benign and
malicious data, Safe LoRA mitigates the negative effect made by malicious data
while preserving performance on downstream tasks. Our codes are available at
\url{this https URL}.

21 Mar 2025
Planning with options -- a sequence of primitive actions -- has been shown
effective in reinforcement learning within complex environments. Previous
studies have focused on planning with predefined options or learned options
through expert demonstration data. Inspired by MuZero, which learns superhuman
heuristics without any human knowledge, we propose a novel approach, named
OptionZero. OptionZero incorporates an option network into MuZero, providing
autonomous discovery of options through self-play games. Furthermore, we modify
the dynamics network to provide environment transitions when using options,
allowing searching deeper under the same simulation constraints. Empirical
experiments conducted in 26 Atari games demonstrate that OptionZero outperforms
MuZero, achieving a 131.58% improvement in mean human-normalized score. Our
behavior analysis shows that OptionZero not only learns options but also
acquires strategic skills tailored to different game characteristics. Our
findings show promising directions for discovering and using options in
planning. Our code is available at
this https URL

21 Oct 2025
Common computer vision systems typically assume ideal pinhole cameras but fail when facing real-world camera effects such as fisheye distortion and rolling shutter, mainly due to the lack of learning from training data with camera effects. Existing data generation approaches suffer from either high costs, sim-to-real gaps or fail to accurately model camera effects. To address this bottleneck, we propose 4D Gaussian Ray Tracing (4D-GRT), a novel two-stage pipeline that combines 4D Gaussian Splatting with physically-based ray tracing for camera effect simulation. Given multi-view videos, 4D-GRT first reconstructs dynamic scenes, then applies ray tracing to generate videos with controllable, physically accurate camera effects. 4D-GRT achieves the fastest rendering speed while performing better or comparable rendering quality compared to existing baselines. Additionally, we construct eight synthetic dynamic scenes in indoor environments across four camera effects as a benchmark to evaluate generated videos with camera effects.

12 Aug 2025
Understanding a procedural activity requires modeling both how action steps transform the scene, and how evolving scene transformations can influence the sequence of action steps, even those that are accidental or erroneous. Existing work has studied procedure-aware video representations by modeling the temporal order of actions, but has not explicitly learned the state changes (scene transformations). In this work, we study procedure-aware video representation learning by incorporating state-change descriptions generated by Large Language Models (LLMs) as supervision signals for video encoders. Moreover, we generate state-change counterfactuals that simulate hypothesized failure outcomes, allowing models to learn by imagining unseen "What if" scenarios. This counterfactual reasoning facilitates the model's ability to understand the cause and effect of each step in an activity. We conduct extensive experiments on procedure-aware tasks, including temporal action segmentation, error detection, action phase classification, frame retrieval, multi-instance retrieval, and action recognition. Our results demonstrate the effectiveness of the proposed state-change descriptions and their counterfactuals, and achieve significant improvements on multiple tasks.
There are no more papers matching your filters at the moment.
