 New York University
New York University
13 Oct 2025
Representation Autoencoders (RAEs) redefine the latent space for Diffusion Transformers (DiT) by utilizing frozen, pretrained visual encoders with lightweight decoders. This framework achieves state-of-the-art image generation, obtaining an FID of 1.13 on ImageNet 512x512, and demonstrates up to 47x faster convergence rates than prior DiT models.
14 Nov 2025


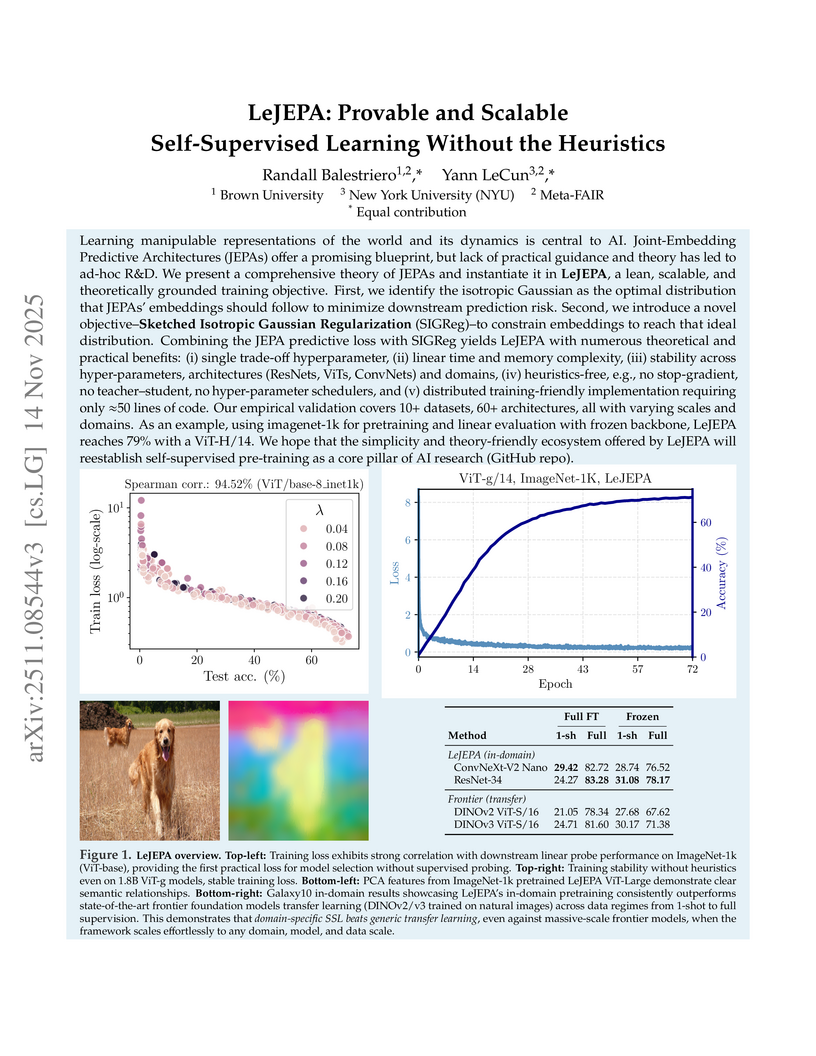
LeJEPA (Latent-Euclidean Joint-Embedding Predictive Architecture) introduces a self-supervised learning framework based on a provably optimal isotropic Gaussian embedding distribution. It utilizes a heuristics-free regularization method, SIGReg, achieving robust and scalable performance, including superior results in in-domain pretraining compared to larger, generically pretrained models.

02 Mar 2023
This paper introduces Diffusion Transformers (DiTs), a new class of diffusion models that replace the conventional U-Net backbone with a transformer architecture. By leveraging the scalability of transformers, DiTs achieve new state-of-the-art Fréchet Inception Distance (FID) scores on class-conditional ImageNet at 256x256 (2.27 FID) and 512x512 (3.04 FID) resolutions while being more compute-efficient.

06 Nov 2025
Researchers from NYU and Stanford introduce a "spatial supersensing" hierarchy for video-based Multimodal Large Language Models (MLLMs) and new VSI-SUPER benchmarks to reveal current models' limitations in genuine spatial and temporal reasoning. They develop Cambrian-S, a specialized MLLM trained on a large spatial dataset achieving state-of-the-art on VSI-Bench, and prototype a "predictive sensing" paradigm that leverages prediction error ("surprise") to robustly improve memory management and event segmentation in arbitrarily long videos.

12 Apr 2021



This paper from Facebook AI Research and University College London introduces Retrieval-Augmented Generation (RAG), a general-purpose model that combines pre-trained parametric language generation with a non-parametric differentiable retriever. RAG achieved state-of-the-art results on multiple knowledge-intensive NLP tasks, demonstrating improved factual accuracy and the ability to update its knowledge by simply swapping out its document index.

30 Jul 2024

Researchers from the University of Illinois Urbana-Champaign and New York University introduce a training-free method for few-shot example selection in sequence tagging tasks, significantly improving performance by using a complexity score based on semantic similarity, length, and label diversity. This approach achieved an 88.76 F1 score for few-shot NER with GPT-4, surpassing prior state-of-the-art by 5% absolute, and demonstrated substantial gains for smaller language models.
28 Nov 2024

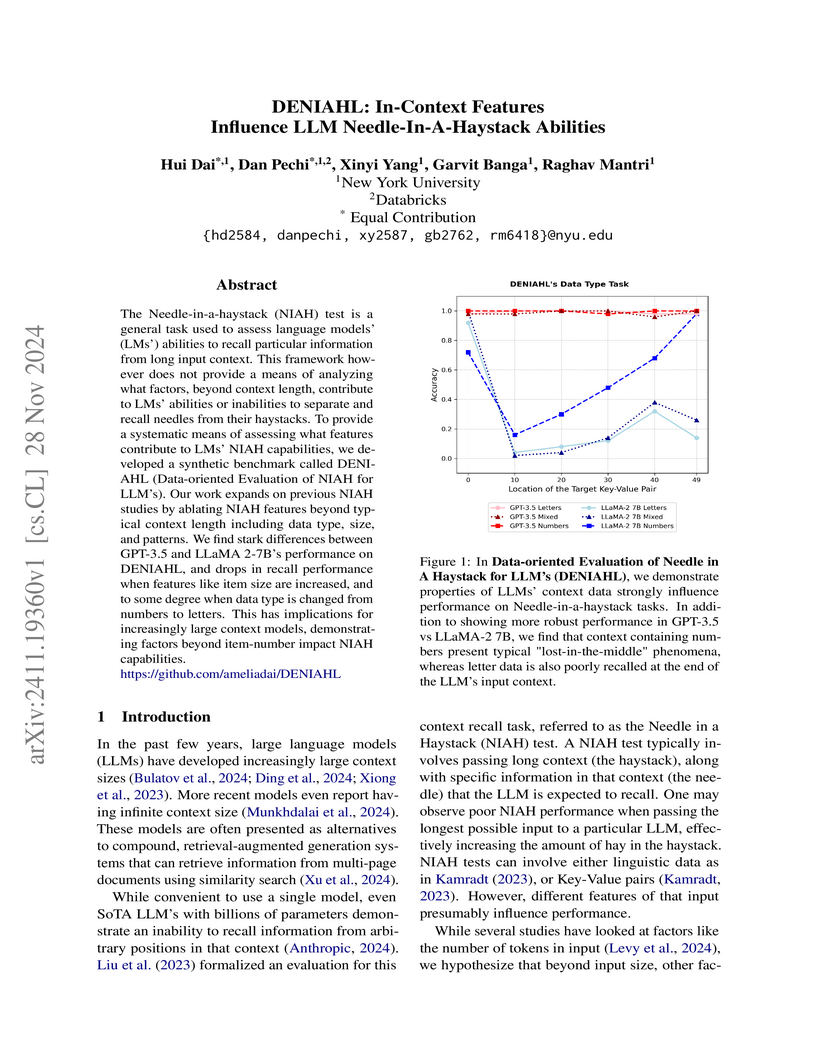
NYU researchers introduced DENIAHL, a benchmark systematically evaluating how data characteristics like type, length, and patterns affect Large Language Models' ability to recall information from long contexts. The study found smaller models are highly sensitive to these features, while GPT-3.5 demonstrated robust recall, though its performance still degraded with combinations of long item lengths and mixed data types.

05 Dec 2024
Researchers at NYU Shanghai enhance mathematical reasoning in LLMs by training them to generate verifiable Prolog code, utilizing a set of 54 standardized background mathematical operators. Their cross-validated self-training algorithm on the MATH-Prolog corpus achieved an 84.8% accuracy on competition-level problems, showing improved solution computability and diversity.
18 Jun 2025

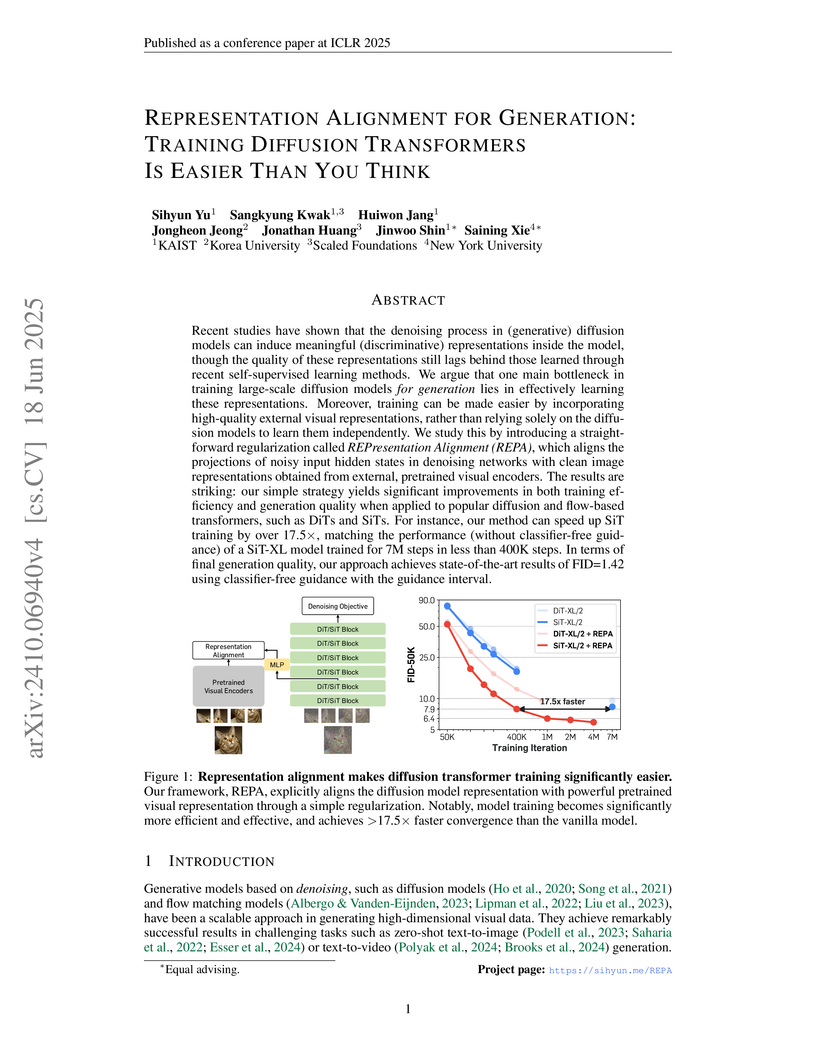
This research introduces REPRESENTATIONALIGNMENT (REPA), a regularization technique that accelerates the training and enhances the generation quality of diffusion transformers by explicitly aligning their internal representations with features from pretrained self-supervised visual encoders. The method enables state-of-the-art generative performance on ImageNet 256x256 while reducing training iterations by over 17.5 times compared to baseline models.

24 Sep 2025

This work introduces a scalable reinforcement learning method for training Large Language Models to generate continuous Chains-of-Thought (CoTs) by injecting noise into mixture embeddings, overcoming prior computational and data dependency issues. Models trained with this approach achieve comparable Pass@1 accuracy, superior Pass@32 performance due to increased reasoning diversity, and improved robustness on out-of-domain tasks compared to discrete CoT training.
13 Apr 2023


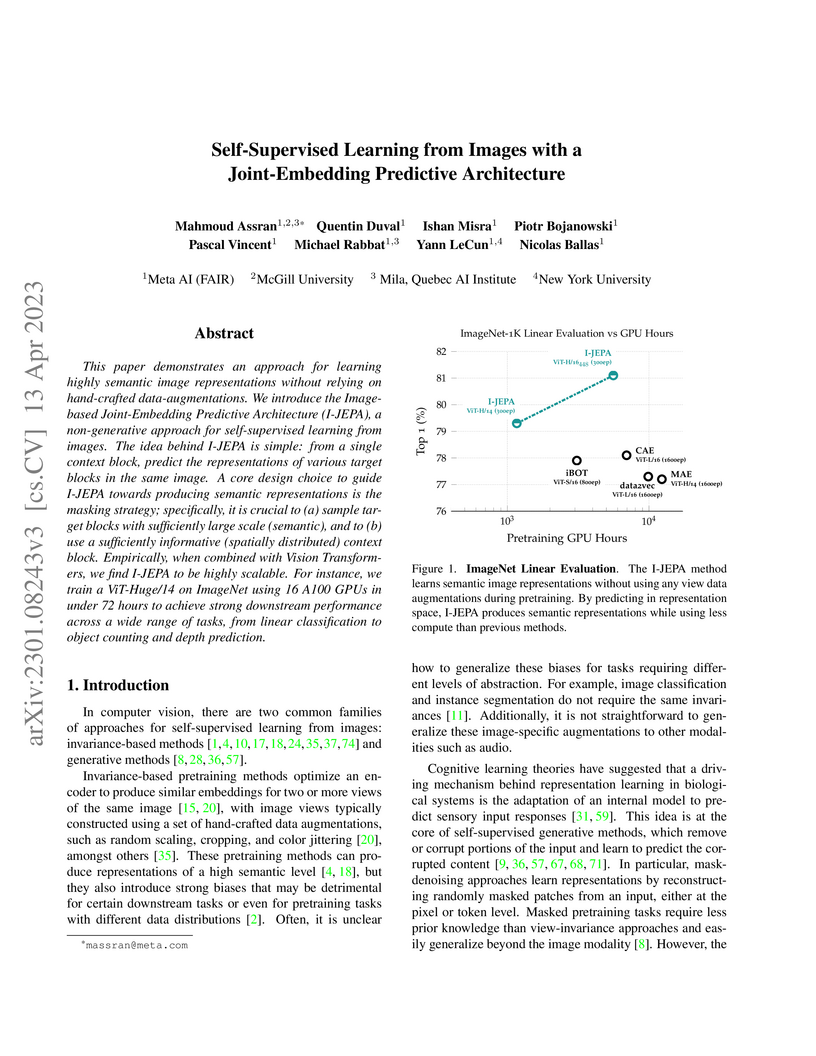
I-JEPA presents a Joint-Embedding Predictive Architecture (JEPA) for self-supervised image learning that predicts abstract representations of masked image blocks. This approach achieves competitive performance on ImageNet-1K linear evaluation and dense prediction tasks while significantly reducing pretraining computational costs by over 10x compared to prior methods like MAE.

17 Sep 2025

This research details the first systematic discovery of new families of unstable singularities in canonical fluid systems, achieving unprecedented numerical accuracy including near double-float machine precision for specific solutions. It also reveals empirical asymptotic formulas relating blow-up rates to instability orders, advancing the understanding of fundamental mathematical challenges in fluid dynamics.

03 Dec 2025
 KAIST
KAIST University of Washington
University of Washington University of Toronto
University of Toronto Carnegie Mellon University
Carnegie Mellon University Université de MontréalNew York University
Université de MontréalNew York University University of Chicago
University of Chicago UC Berkeley
UC Berkeley University of Oxford
University of Oxford Stanford University
Stanford University University of Michigan
University of Michigan Cornell University
Cornell University Nanyang Technological UniversityVector InstituteLG AI Research
Nanyang Technological UniversityVector InstituteLG AI Research MIT
MIT HKUSTUniversity of TübingenHong Kong Baptist University
HKUSTUniversity of TübingenHong Kong Baptist University University of California, Santa CruzCenter for AI SafetyGray Swan AIBeneficial AI ResearchConjectureLawZeroUniversity of Wisconsin
–MadisonMorph LabsInstitute for Applied PsychometricsCSER
University of California, Santa CruzCenter for AI SafetyGray Swan AIBeneficial AI ResearchConjectureLawZeroUniversity of Wisconsin
–MadisonMorph LabsInstitute for Applied PsychometricsCSERThe lack of a concrete definition for Artificial General Intelligence (AGI) obscures the gap between today's specialized AI and human-level cognition. This paper introduces a quantifiable framework to address this, defining AGI as matching the cognitive versatility and proficiency of a well-educated adult. To operationalize this, we ground our methodology in Cattell-Horn-Carroll theory, the most empirically validated model of human cognition. The framework dissects general intelligence into ten core cognitive domains-including reasoning, memory, and perception-and adapts established human psychometric batteries to evaluate AI systems. Application of this framework reveals a highly "jagged" cognitive profile in contemporary models. While proficient in knowledge-intensive domains, current AI systems have critical deficits in foundational cognitive machinery, particularly long-term memory storage. The resulting AGI scores (e.g., GPT-4 at 27%, GPT-5 at 57%) concretely quantify both rapid progress and the substantial gap remaining before AGI.

26 May 2025



Researchers from Northwestern University, Stanford, NYU, and Microsoft developed StarPO, a reinforcement learning framework, and RAGEN, a modular system, to train self-evolving large language model agents in multi-turn environments. The work identifies a new instability called the "Echo Trap" and proposes StarPO-S, which uses uncertainty-based filtering and gradient shaping to achieve more robust training and higher success rates across various interactive tasks.
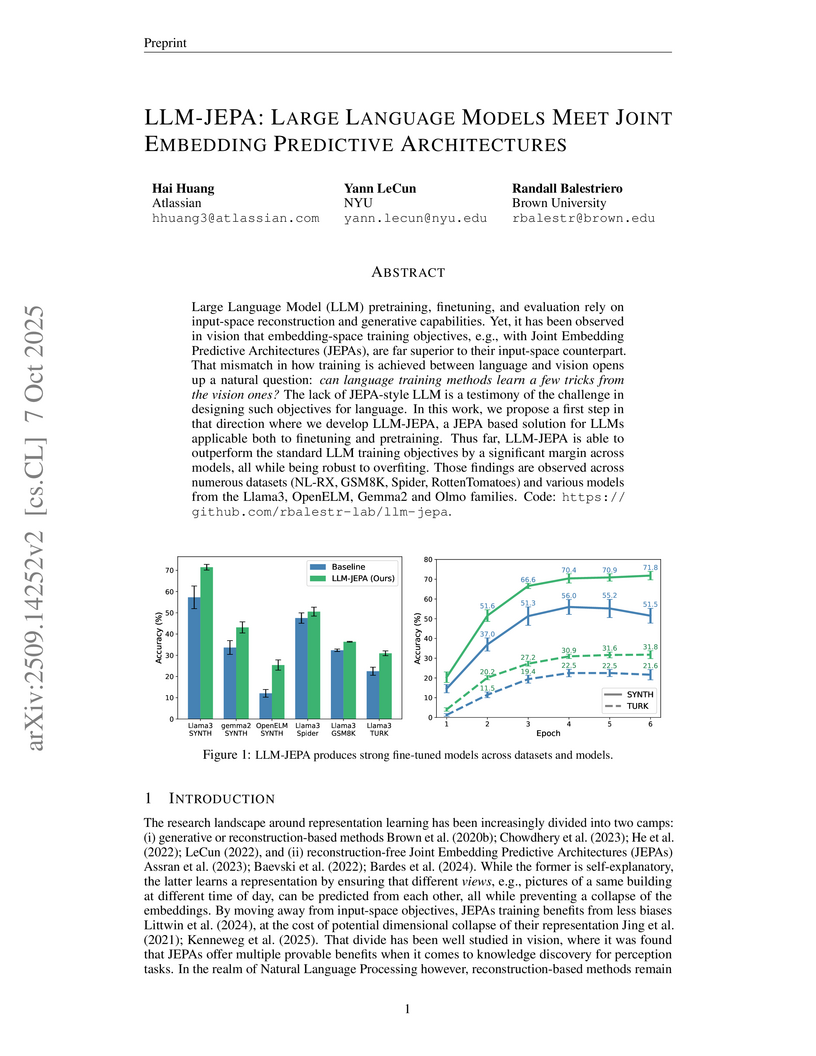
07 Oct 2025
LLM-JEPA introduces a Joint Embedding Predictive Architecture (JEPA)-based training objective for Large Language Models, enhancing fine-tuning and pretraining by improving accuracy, robustness against overfitting, and fostering more structured abstract representations. This method achieved superior performance across models like Llama, Gemma, and OpenELM on datasets including NL-RX-SYNTH, GSM8K, and Spider, while mitigating computational costs with a novel 'loss dropout' mechanism.

02 Jul 2025


Researchers from New York University, Yale University, and Stanford University introduced VSI-Bench, a video-based benchmark, to assess the visual-spatial intelligence of multimodal large language models (MLLMs). The study found a substantial performance gap between MLLMs and human capabilities in spatial reasoning, identifying relational reasoning and egocentric-allocentric transformation as key limitations, while demonstrating that explicit cognitive map generation can enhance spatial distance understanding.

26 May 2025


A comparative study by researchers from Hong Kong University, UC Berkeley, NYU, and Google DeepMind empirically demonstrates that Reinforcement Learning (RL) promotes generalization to novel rules and visual inputs, while Supervised Fine-Tuning (SFT) tends to induce memorization, particularly in complex reasoning tasks for foundation models like Llama-3.2-Vision-11B. RL improved out-of-distribution performance by up to +61.1% on visual tasks and also enhanced underlying visual recognition capabilities.

10 Oct 2025

Researchers from KAIST AI and collaborators introduced VIsual Representation ALignment (VIRAL), a novel regularization strategy that directly supervises the visual pathway in Multimodal Large Language Models (MLLMs) by aligning internal representations with Vision Foundation Models. This approach prevents the loss of fine-grained visual information, leading to consistent performance improvements of up to 17.3% on specific vision-centric tasks and a 9.4% average gain over baselines like LLaVA-1.5.

01 Feb 2024
We study improving social conversational agents by learning from natural dialogue between users and a deployed model, without extra annotations. To implicitly measure the quality of a machine-generated utterance, we leverage signals like user response length, sentiment and reaction of the future human utterances in the collected dialogue episodes. Our experiments use the publicly released deployment data from BlenderBot (Xu et al., 2023). Human evaluation indicates improvements in our new models over baseline responses; however, we find that some proxy signals can lead to more generations with undesirable properties as well. For example, optimizing for conversation length can lead to more controversial or unfriendly generations compared to the baseline, whereas optimizing for positive sentiment or reaction can decrease these behaviors.

22 Oct 2025

This research introduces Loopholing, a mechanism that deterministically propagates rich continuous latent information across denoising steps in discrete diffusion models, directly addressing the "sampling wall" problem. Loopholing Discrete Diffusion Models (LDDMs) demonstrate enhanced language generation quality and improved performance on reasoning tasks, often surpassing autoregressive baselines in generative perplexity and consistency.
There are no more papers matching your filters at the moment.
