
15 Jun 2025


Tong Xiao and Jingbo Zhu from Northeastern University and NiuTrans Research offer a foundational guide to Large Language Models (LLMs), synthesizing core concepts and techniques in a structured, accessible format. The work consolidates knowledge on pre-training, generative architectures, prompting, alignment, and inference, providing a comprehensive overview of how these models are built and deployed.

18 Jun 2025
GRAM introduces a Generative Foundation Reward Model that leverages a two-stage training approach with unlabeled and labeled data, significantly improving reward model generalization and reducing reliance on extensive human preference annotations for LLM alignment. The model demonstrates superior out-of-distribution performance and efficient adaptation to new tasks.

11 Oct 2025
Researchers from Northeastern University and NiuTrans Research introduced MTP-S2UT, a framework that strategically applies Multi-Token Prediction (MTP) loss to intermediate decoder layers within Speech-to-Unit Translation models. This method substantially enhanced speech-to-speech translation quality, achieving an ASR-BLEU score improvement of over 6.5 points on French-to-English translation.

10 Nov 2025
Researchers from Northeastern University and NiuTrans Research introduced LMT, a suite of large-scale multilingual translation models that addresses English-centric bias by explicitly centering on both Chinese and English. The framework achieves state-of-the-art translation performance across 60 languages and 234 directions, demonstrating superior parameter efficiency by outperforming significantly larger existing models.
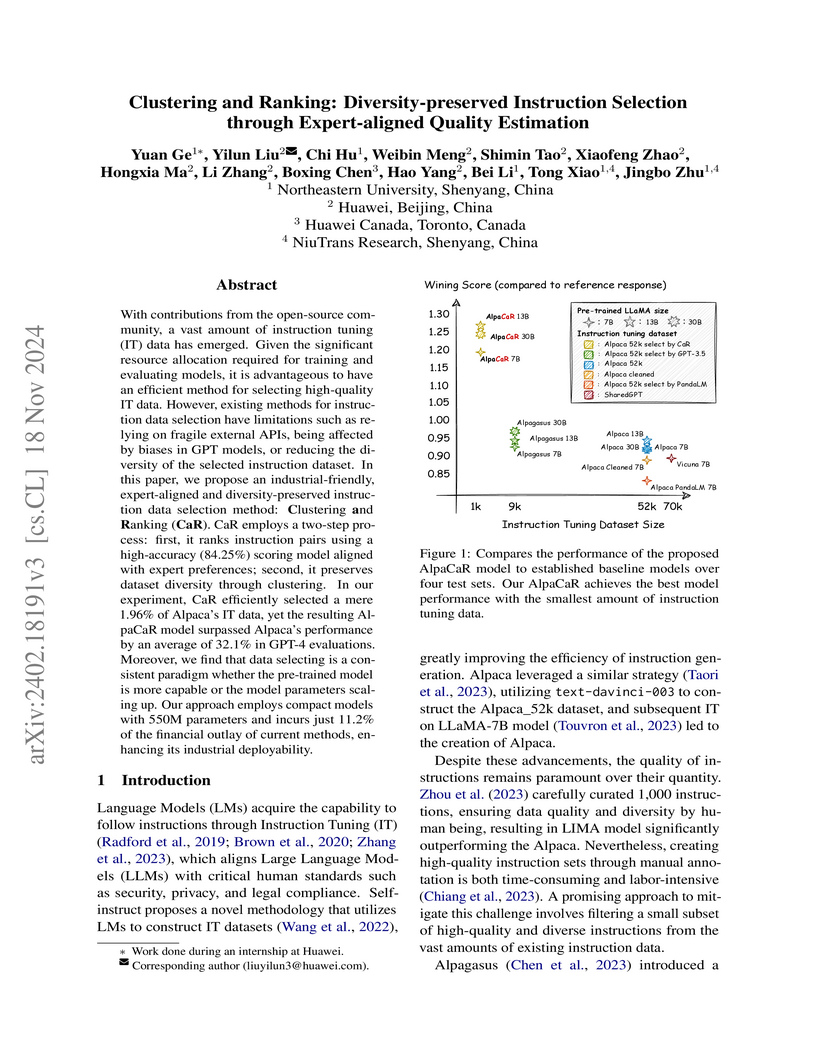
18 Nov 2024

Researchers from Northeastern University and Huawei introduce the "Clustering and Ranking (CaR)" method for selecting high-quality and diverse instruction tuning data for Large Language Models. This approach enables LLMs fine-tuned on just 1.96% of the original dataset to achieve an average 32.1% performance improvement over models trained on full datasets, drastically reducing training resources and aligning with human expert preferences.

17 Oct 2025

To enhance the efficiency of the attention mechanism within large language models (LLMs), previous works primarily compress the KV cache or group attention heads, while largely overlooking redundancy between layers. Our comprehensive analyses across various LLMs show that highly similar attention patterns persist within most layers. It's intuitive to reduce the redundancy by sharing attention weights across layers. However, further analysis reveals two challenges: (1) Directly sharing the weight matrix without carefully rearranging the attention heads proves to be ineffective; (2) Shallow layers are vulnerable to small deviations in attention weights.
Driven by these insights, we introduce LISA, a lightweight substitute for self-attention in well-trained LLMs. LISA employs tiny feed-forward networks to align attention heads between adjacent layers and low-rank matrices to approximate differences in layer-wise attention weights. Evaluations encompassing 13 typical benchmarks demonstrate that LISA maintains high response quality in terms of accuracy and perplexity while reducing redundant attention calculations within 53%-84% of the total layers. Our implementations of LISA achieve a 6x compression of Q and K matrices within the attention mechanism, with maximum throughput improvements 19.5%, 32.3%, and 40.1% for LLaMA3-8B, LLaMA2-7B, and LLaMA2-13B, respectively.

18 Oct 2025
Context compression presents a promising approach for accelerating large language model (LLM) inference by compressing long contexts into compact representations. Current context compression methods predominantly rely on autoencoding tasks to train context-agnostic compression tokens to compress contextual semantics. While autoencoding tasks enable compression tokens to acquire compression capabilities, compression via autoencoding tasks creates a fundamental mismatch: the models are optimized for reconstruction that diverge from actual downstream tasks, thereby weakening the features more beneficial for real-world usage. We propose Semantic-Anchor Compression (SAC), a novel method that shifts from autoencoding task based compression to an architecture that is equipped with this compression capability \textit{a priori}. Instead of training models to compress contexts through autoencoding tasks, SAC directly selects so-called anchor tokens from the original context and aggregates contextual information into their key-value (KV) representations. By deriving representations directly from the contextual tokens, SAC eliminates the need for autoencoding training. To ensure compression performance while directly leveraging anchor tokens, SAC incorporates two key designs: (1) anchor embeddings that enable the compressor to identify critical tokens, and (2) bidirectional attention modification that allows anchor tokens to capture information from the entire context. Experimental results demonstrate that SAC consistently outperforms existing context compression methods across various compression ratios. On out-of-distribution evaluation using MRQA, SAC achieves 1 EM improvement at 5x compression over strong baselines, with increasing advantages at higher compression ratios.

10 Nov 2025

Speech-to-Speech (S2S) Large Language Models (LLMs) are foundational to natural human-computer interaction, enabling end-to-end spoken dialogue systems. However, evaluating these models remains a fundamental challenge. We propose \texttt{SageLM}, an end-to-end, multi-aspect, and explainable speech LLM for comprehensive S2S LLMs evaluation. First, unlike cascaded approaches that disregard acoustic features, SageLM jointly assesses both semantic and acoustic dimensions. Second, it leverages rationale-based supervision to enhance explainability and guide model learning, achieving superior alignment with evaluation outcomes compared to rule-based reinforcement learning methods. Third, we introduce \textit{SpeechFeedback}, a synthetic preference dataset, and employ a two-stage training paradigm to mitigate the scarcity of speech preference data. Trained on both semantic and acoustic dimensions, SageLM achieves an 82.79\% agreement rate with human evaluators, outperforming cascaded and SLM-based baselines by at least 7.42\% and 26.20\%, respectively.

24 Oct 2025

Multi-Reward Optimization (MRO) addresses the reasoning limitations of Diffusion Language Models (DLMs) by explicitly optimizing for intra-sequence and inter-sequence token correlations during generation. This approach significantly boosts reasoning accuracy across various tasks and enables faster decoding with fewer denoising steps.

24 Oct 2025
Northeastern University's SubQRAG framework enhances Retrieval-Augmented Generation by enabling sub-question-driven multi-step reasoning and dynamic knowledge graph updates for complex queries. This approach consistently outperforms existing methods on multi-hop QA benchmarks, notably achieving an Exact Match score of 61.90% on 2WikiMultiHopQA, an 11.3 percentage point improvement over prior state-of-the-art.

01 Jun 2025

The field of neural machine translation (NMT) has changed with the advent of
large language models (LLMs). Much of the recent emphasis in natural language
processing (NLP) has been on modeling machine translation and many other
problems using a single pre-trained Transformer decoder, while encoder-decoder
architectures, which were the standard in earlier NMT models, have received
relatively less attention. In this paper, we explore translation models that
are universal, efficient, and easy to optimize, by marrying the world of LLMs
with the world of NMT. We apply LLMs to NMT encoding and leave the NMT decoder
unchanged. We also develop methods for adapting LLMs to work better with the
NMT decoder. Furthermore, we construct a new dataset involving multiple tasks
to assess how well the machine translation system generalizes across various
tasks. Evaluations on the WMT and our datasets show that results using our
method match or surpass a range of baselines in terms of translation quality,
but achieve inference speedups and a reduction in
the memory footprint of the KV cache. It also demonstrates strong
generalization across a variety of translation-related tasks.
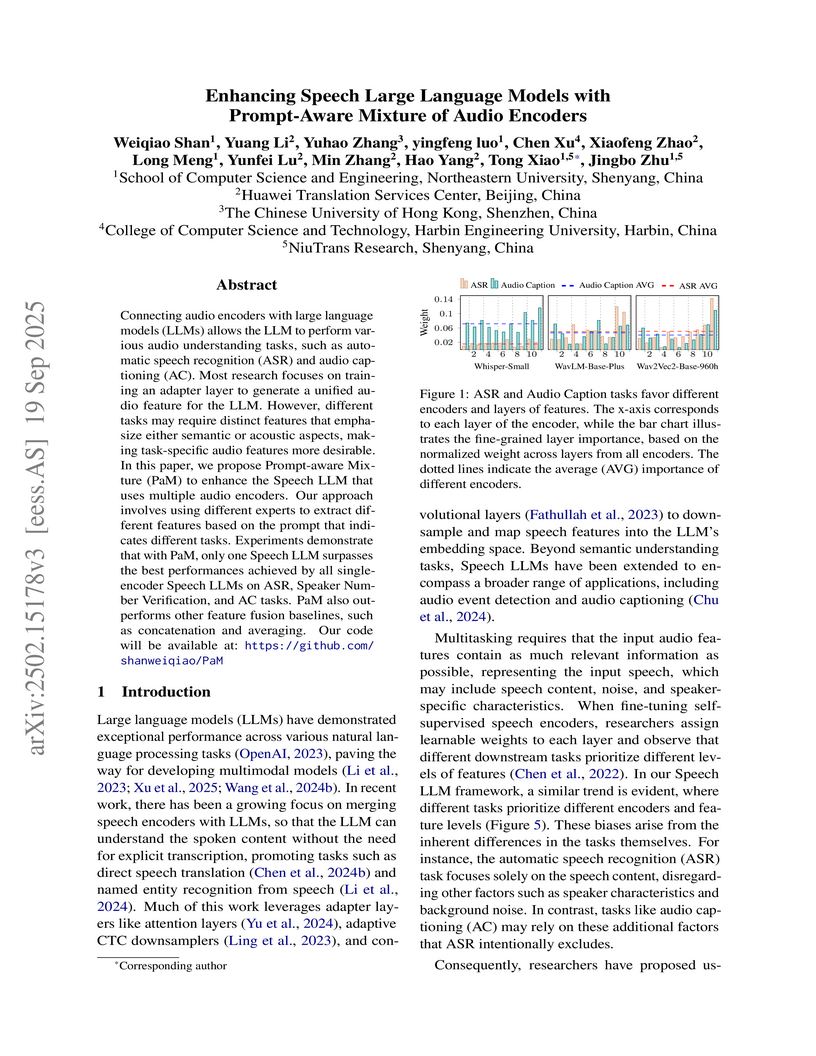
19 Sep 2025

Connecting audio encoders with large language models (LLMs) allows the LLM to perform various audio understanding tasks, such as automatic speech recognition (ASR) and audio captioning (AC). Most research focuses on training an adapter layer to generate a unified audio feature for the LLM. However, different tasks may require distinct features that emphasize either semantic or acoustic aspects, making task-specific audio features more desirable. In this paper, we propose Prompt-aware Mixture (PaM) to enhance the Speech LLM that uses multiple audio encoders. Our approach involves using different experts to extract different features based on the prompt that indicates different tasks. Experiments demonstrate that with PaM, only one Speech LLM surpasses the best performances achieved by all single-encoder Speech LLMs on ASR, Speaker Number Verification, and AC tasks. PaM also outperforms other feature fusion baselines, such as concatenation and averaging. Our code would be available at: this https URL

03 Jun 2025
In this study, we reveal an in-context learning (ICL) capability of
multilingual large language models (LLMs): by translating the input to several
languages, we provide Parallel Input in Multiple Languages (PiM) to LLMs, which
significantly enhances their comprehension abilities. To test this capability,
we design extensive experiments encompassing 8 typical datasets, 7 languages
and 8 state-of-the-art multilingual LLMs. Experimental results show that (1)
incorporating more languages help PiM surpass the conventional ICL further; (2)
even combining with the translations that are inferior to baseline performance
can also help. Moreover, by examining the activated neurons in LLMs, we
discover a counterintuitive but interesting phenomenon. Contrary to the common
thought that PiM would activate more neurons than monolingual input to leverage
knowledge learned from diverse languages, PiM actually inhibits neurons and
promotes more precise neuron activation especially when more languages are
added. This phenomenon aligns with the neuroscience insight about synaptic
pruning, which removes less used neural connections, strengthens remainders,
and then enhances brain intelligence.

26 Sep 2025
Full-Duplex Speech-to-Speech Large Language Models (LLMs) are foundational to natural human-computer interaction, enabling real-time spoken dialogue systems. However, benchmarking and modeling these models remains a fundamental challenge. We introduce FLEXI, the first benchmark for full-duplex LLM-human spoken interaction that explicitly incorporates model interruption in emergency scenarios. FLEXI systematically evaluates the latency, quality, and conversational effectiveness of real-time dialogue through six diverse human-LLM interaction scenarios, revealing significant gaps between open source and commercial models in emergency awareness, turn terminating, and interaction latency. Finally, we suggest that next token-pair prediction offers a promising path toward achieving truly seamless and human-like full-duplex interaction.
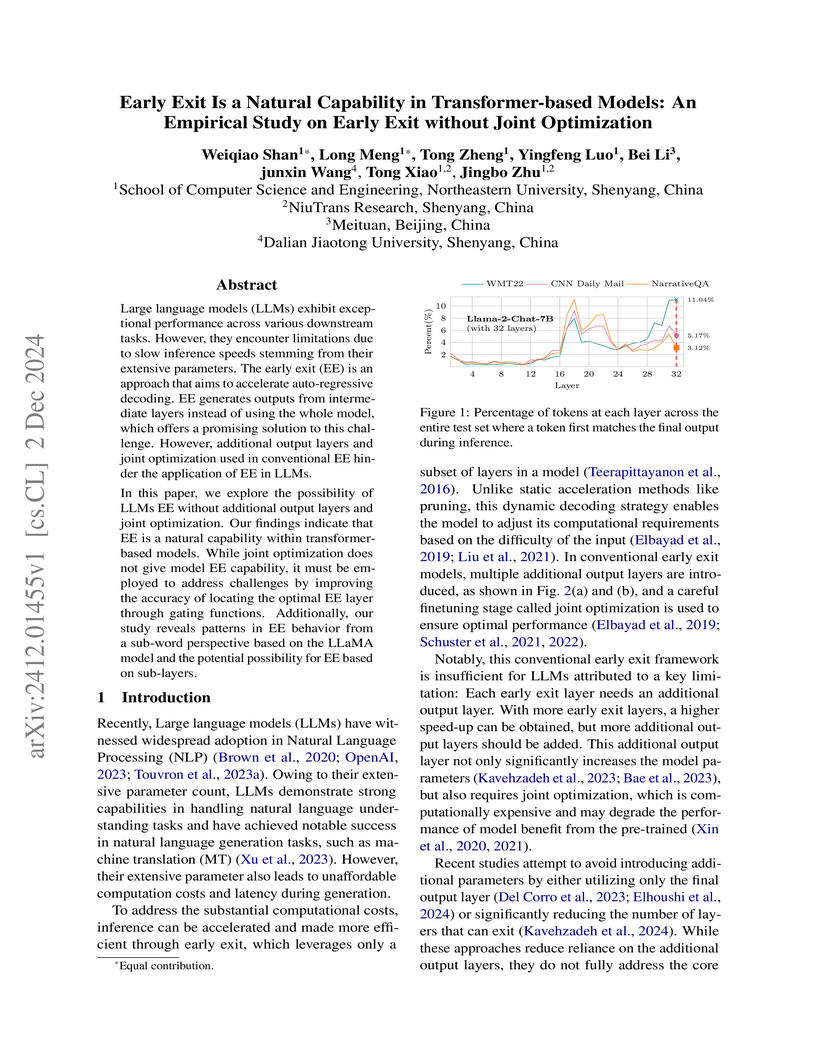
02 Dec 2024
Large language models (LLMs) exhibit exceptional performance across various downstream tasks. However, they encounter limitations due to slow inference speeds stemming from their extensive parameters. The early exit (EE) is an approach that aims to accelerate auto-regressive decoding. EE generates outputs from intermediate layers instead of using the whole model, which offers a promising solution to this challenge. However, additional output layers and joint optimization used in conventional EE hinder the application of EE in LLMs.
In this paper, we explore the possibility of LLMs EE without additional output layers and joint optimization. Our findings indicate that EE is a natural capability within transformer-based models. While joint optimization does not give model EE capability, it must be employed to address challenges by improving the accuracy of locating the optimal EE layer through gating functions. Additionally, our study reveals patterns in EE behavior from a sub-word perspective based on the LLaMA model and the potential possibility for EE based on sub-layers.

27 May 2023
Using translation memories (TMs) as prompts is a promising approach to
in-context learning of machine translation models. In this work, we take a step
towards prompting large language models (LLMs) with TMs and making them better
translators. We find that the ability of LLMs to ``understand'' prompts is
indeed helpful for making better use of TMs. Experiments show that the results
of a pre-trained LLM translator can be greatly improved by using high-quality
TM-based prompts. These results are even comparable to those of the
state-of-the-art NMT systems which have access to large-scale in-domain
bilingual data and are well tuned on the downstream tasks.

26 Jun 2025
Automatic evaluation of sequence generation, traditionally reliant on metrics like BLEU and ROUGE, often fails to capture the semantic accuracy of generated text sequences due to their emphasis on n-gram overlap. A promising solution to this problem is to develop model-based metrics, such as BLEURT and COMET. However, these approaches are typically hindered by the scarcity of labeled evaluation data, which is necessary to train the evaluation models. In this work, we build upon this challenge by proposing the Customized Sequence Evaluation Metric (CSEM), a three-stage evaluation model training method that utilizes large language models to generate labeled data for model-based metric development, thereby eliminating the need for human-labeled data. Additionally, we expand the scope of CSEM to support various evaluation types, including single-aspect, multi-aspect, reference-free, and reference-based evaluations, enabling the customization of metrics to suit diverse real-world scenarios. Experimental results on the SummEval benchmark demonstrate that CSEM can effectively train an evaluation model without human-labeled data. Further experiments in reinforcement learning and reranking show that metrics developed through CSEM outperform traditional evaluation metrics, leading to substantial improvements in sequence quality as evaluated by both commonly used metrics and ChatGPT.
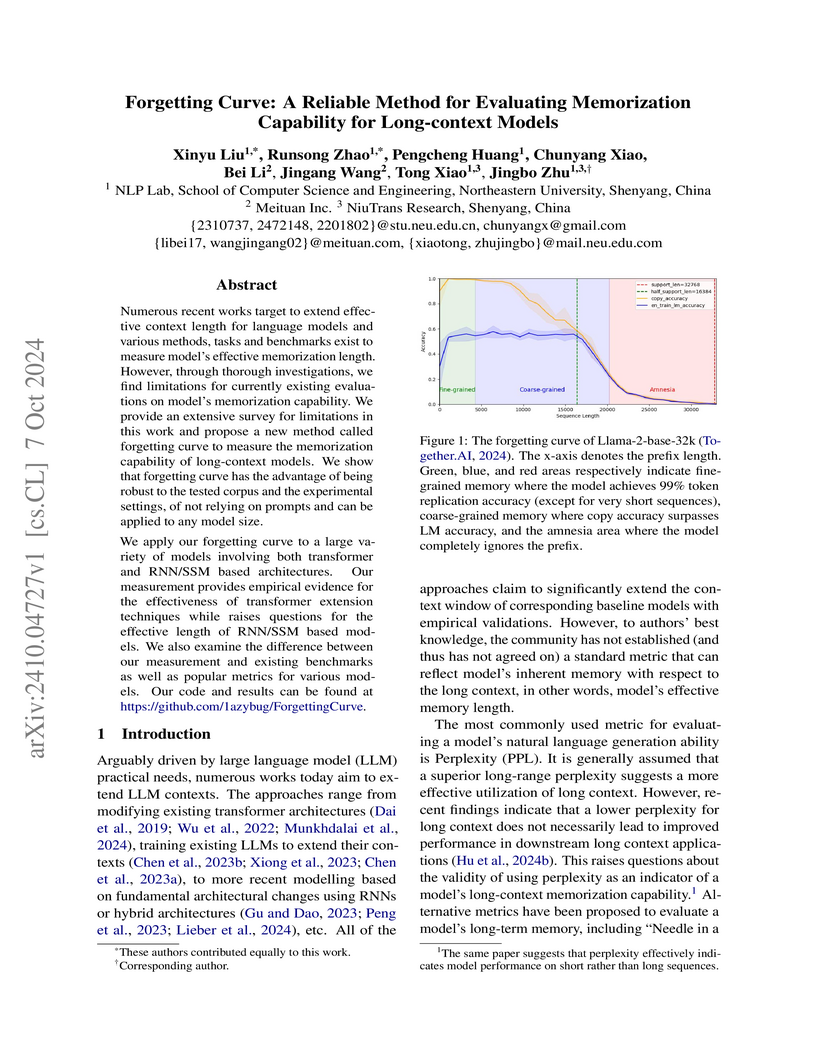
07 Oct 2024
Numerous recent works target to extend effective context length for language models and various methods, tasks and benchmarks exist to measure model's effective memorization length. However, through thorough investigations, we find limitations for currently existing evaluations on model's memorization capability. We provide an extensive survey for limitations in this work and propose a new method called forgetting curve to measure the memorization capability of long-context models. We show that forgetting curve has the advantage of being robust to the tested corpus and the experimental settings, of not relying on prompts and can be applied to any model size.
We apply our forgetting curve to a large variety of models involving both transformer and RNN/SSM based architectures. Our measurement provides empirical evidence for the effectiveness of transformer extension techniques while raises questions for the effective length of RNN/SSM based models. We also examine the difference between our measurement and existing benchmarks as well as popular metrics for various models. Our code and results can be found at this https URL.
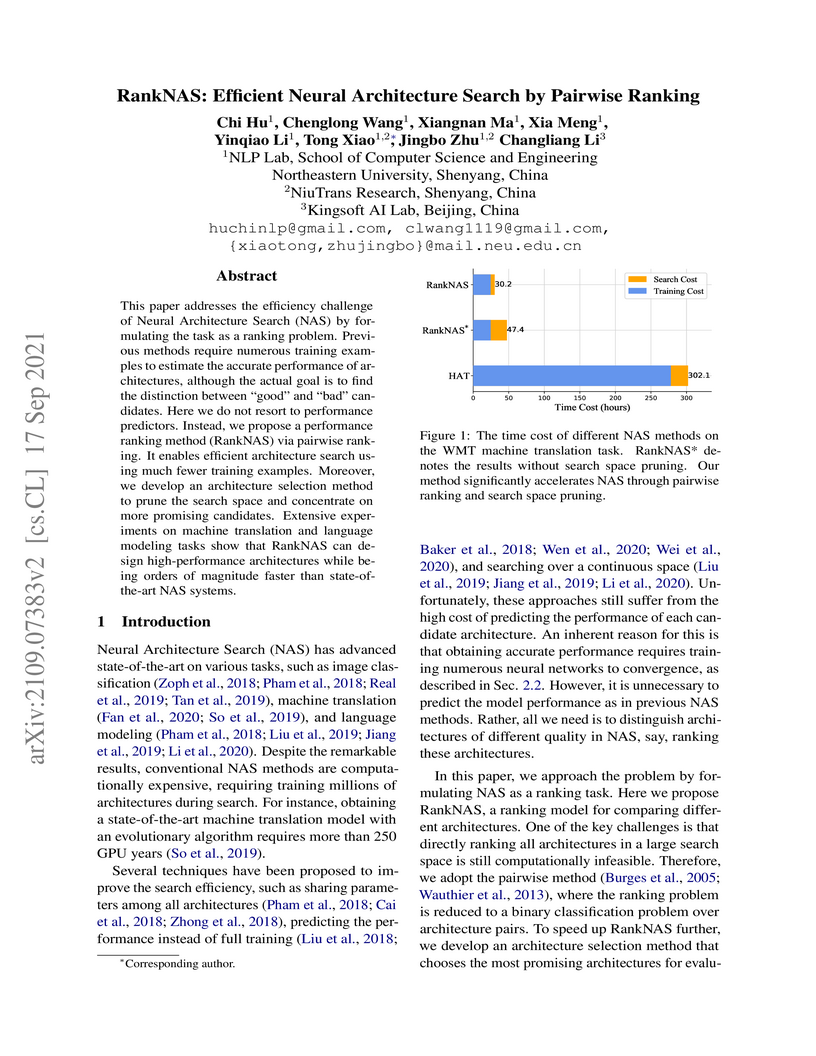
17 Sep 2021
This paper addresses the efficiency challenge of Neural Architecture Search
(NAS) by formulating the task as a ranking problem. Previous methods require
numerous training examples to estimate the accurate performance of
architectures, although the actual goal is to find the distinction between
"good" and "bad" candidates. Here we do not resort to performance predictors.
Instead, we propose a performance ranking method (RankNAS) via pairwise
ranking. It enables efficient architecture search using much fewer training
examples. Moreover, we develop an architecture selection method to prune the
search space and concentrate on more promising candidates. Extensive
experiments on machine translation and language modeling tasks show that
RankNAS can design high-performance architectures while being orders of
magnitude faster than state-of-the-art NAS systems.

31 May 2023

Large language models (LLMs) have shown remarkable success across a wide range of natural language generation tasks, where proper prompt designs make great impacts. While existing prompting methods are normally restricted to providing correct information, in this paper, we encourage the model to deliberate by proposing a novel Deliberate then Generate (DTG) prompting framework, which consists of error detection instructions and candidates that may contain errors. DTG is a simple yet effective technique that can be applied to various text generation tasks with minimal modifications. We conduct extensive experiments on 20+ datasets across 7 text generation tasks, including summarization, translation, dialogue, and more. We show that DTG consistently outperforms existing prompting methods and achieves state-of-the-art performance on multiple text generation tasks. We also provide in-depth analyses to reveal the underlying mechanisms of DTG, which may inspire future research on prompting for LLMs.
There are no more papers matching your filters at the moment.
