
29 Feb 2024
 University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign Monash UniversityLeipzig University
Monash UniversityLeipzig University Northeastern University
Northeastern University University of Notre Dame
University of Notre Dame UC Berkeley
UC Berkeley University College London
University College London Cohere
Cohere Cornell University
Cornell University University of California, San Diego
University of California, San Diego University of British ColumbiaCSIRO’s Data61
University of British ColumbiaCSIRO’s Data61 NVIDIAIBM Research
NVIDIAIBM Research Hugging Face
Hugging Face Johns Hopkins University
Johns Hopkins University Technical University of MunichSea AI Lab
Technical University of MunichSea AI Lab MIT
MIT Princeton UniversityTechnical University of DarmstadtBaidu
Princeton UniversityTechnical University of DarmstadtBaidu ServiceNowKaggleWellesley CollegeContextual AIRobloxSalesforceIndependentMazzumaTechnion
Israel Institute of Technology
ServiceNowKaggleWellesley CollegeContextual AIRobloxSalesforceIndependentMazzumaTechnion
Israel Institute of Technology

The BigCode project releases StarCoder 2 models and The Stack v2 dataset, setting a new standard for open and ethically sourced Code LLM development. StarCoder 2 models, particularly the 15B variant, demonstrate competitive performance across code generation, completion, and reasoning tasks, often outperforming larger, closed-source alternatives, by prioritizing data quality and efficient architecture over sheer data quantity.

13 Dec 2023
Monash UniversityLeipzig UniversityNortheastern University Carnegie Mellon University
Carnegie Mellon University New York University
New York University Stanford University
Stanford University McGill UniversityUniversity of British ColumbiaCSIRO’s Data61IBM Research
McGill UniversityUniversity of British ColumbiaCSIRO’s Data61IBM Research Columbia UniversityScaDS.AIHugging FaceJohns Hopkins UniversityWeizmann Institute of ScienceThe Alan Turing InstituteSea AI LabMIT
Columbia UniversityScaDS.AIHugging FaceJohns Hopkins UniversityWeizmann Institute of ScienceThe Alan Turing InstituteSea AI LabMIT Queen Mary University of LondonUniversity of VermontSAPServiceNowIsrael Institute of TechnologyWellesley CollegeEleuther AIRobloxUniversity ofTelefonica I+DTechnical University ofNotre DameMunichDiscover Dollar Pvt LtdUnfoldMLAllahabadTechnion –Saama AI Research LabTolokaForschungszentrum J",
Queen Mary University of LondonUniversity of VermontSAPServiceNowIsrael Institute of TechnologyWellesley CollegeEleuther AIRobloxUniversity ofTelefonica I+DTechnical University ofNotre DameMunichDiscover Dollar Pvt LtdUnfoldMLAllahabadTechnion –Saama AI Research LabTolokaForschungszentrum J",
StarCoder and StarCoderBase are large language models for code developed by The BigCode community, demonstrating state-of-the-art performance among open-access models on Python code generation, achieving 33.6% pass@1 on HumanEval, and strong multi-language capabilities, all while integrating responsible AI practices.

18 Jul 2025
The Foundation AI team at Roblox introduces "Cube," a project centered on a discrete 3D shape tokenization method that lays the groundwork for a 3D intelligence foundation model. This approach enables high-quality text-to-shape, shape-to-text, and text-to-scene generation, outperforming baselines in reconstruction quality with 91.7% Surface-IoU and demonstrating robust cycle consistency, with the aim of democratizing 3D content creation for the platform.
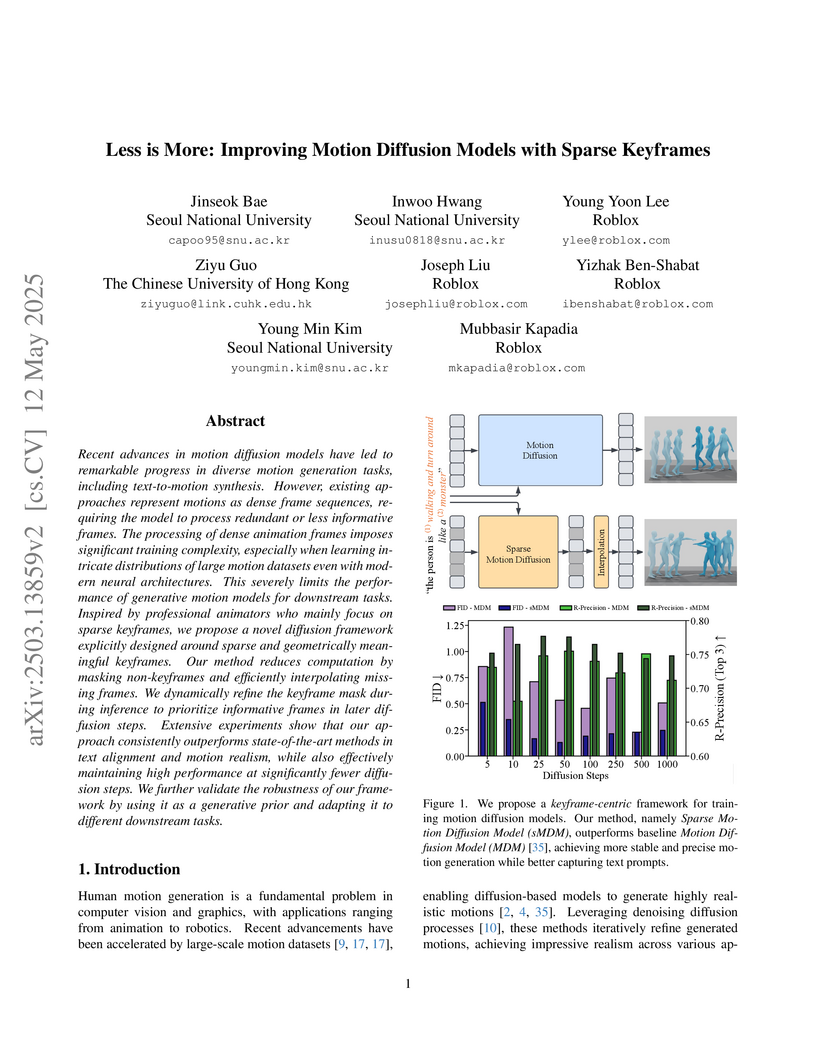
12 May 2025


A Sparse Motion Diffusion Model (sMDM) is introduced, utilizing geometrically meaningful keyframes to reduce computational complexity in motion generation while improving motion realism and text alignment. The method consistently outperforms state-of-the-art baselines across various tasks, achieving better performance even with fewer diffusion steps.

01 Nov 2024
SelfCodeAlign introduces a fully transparent and permissibly licensed pipeline for self-aligning code Large Language Models (LLMs), enabling them to generate high-quality code without extensive human annotation or reliance on proprietary models. The SelfCodeAlign-CQ-7B model, fine-tuned with this approach, achieves 67.1 pass@1 on HumanEval+, outperforming CodeLlama-70B-Instruct (65.2) and rivaling GPT-4o distillation (65.9).

23 Sep 2024
Researchers from Northeastern University and collaborators introduced `CANITEDIT`, a hand-crafted benchmark for evaluating large language models on instructional code editing, alongside `ExcessCode`, a new metric for edit precision. Their fine-tuned `EDITCODER-33b` model achieved an overall 10.7% absolute increase in `pass@1` over its base, surpassing GPT-3.5-Turbo for descriptive instructions and matching it for lazy instructions.

08 Feb 2025
The Decentralized Adaptive Knowledge Graph Memory and Structured Communication System (DAMCS) integrates LLMs with hierarchical knowledge graphs and structured communication to facilitate cooperation among multiple agents in open-world environments. This framework reduced steps to achieve goals by 63% in two-agent and 74% in six-agent configurations compared to single-agent setups in a Multi-Agent Crafter environment.

19 Oct 2025

Generative Recommendation (GR) models treat a user's interaction history as a sequence to be autoregressively predicted. When both items and actions (e.g., watch time, purchase, comment) are modeled, the layout-the ordering and visibility of item/action tokens-critically determines what information the model can use and how it generalizes. We present a unified study of token layouts for GR grounded in first principles: (P1) maximize item/action signal in both input/output space, (P2) preserve the conditioning relationship "action given item" and (P3) no information leakage.
While interleaved layout (where item and action occupy separate tokens) naturally satisfies these principles, it also bloats sequence length with larger training/inference cost. On the non-interleaved front, we design a novel and effective approach, Lagged Action Conditioning (LAC), which appears strange on the surface but aligns well with the design principles to yield strong accuracy. Comprehensive experiments on public datasets and large-scale production logs evaluate different layout options and empirically verifies the design principles. Our proposed non-interleaved method, LAC, achieves competitive or superior quality at substantially lower FLOPs than interleaving. Our findings offer actionable guidance for assembling GR systems that are both accurate and efficient.

23 Oct 2025
Generative recommenders, typically transformer-based autoregressive models, predict the next item or action from a user's interaction history. Their effectiveness depends on how the model represents where an interaction event occurs in the sequence (discrete index) and when it occurred in wall-clock time. Prevailing approaches inject time via learned embeddings or relative attention biases. In this paper, we argue that RoPE-based approaches, if designed properly, can be a stronger alternative for jointly modeling temporal and sequential information in user behavior sequences. While vanilla RoPE in LLMs considers only token order, generative recommendation requires incorporating both event time and token index. To address this, we propose Time-and-Order RoPE (TO-RoPE), a family of rotary position embedding designs that treat index and time as angle sources shaping the query-key geometry directly. We present three instantiations: early fusion, split-by-dim, and split-by-head. Extensive experiments on both publicly available datasets and a proprietary industrial dataset show that TO-RoPE variants consistently improve accuracy over existing methods for encoding time and index. These results position rotary embeddings as a simple, principled, and deployment-friendly foundation for generative recommendation.

09 Oct 2025
This paper introduces a method for simplifying textured surface triangle meshes in the wild while maintaining high visual quality. While previous methods achieve excellent results on manifold meshes by using the quadric error metric, they struggle to produce high-quality outputs for meshes in the wild, which typically contain non-manifold elements and multiple connected components. In this work, we propose a method for simplifying these wild textured triangle meshes. We formulate mesh simplification as a problem of decimating simplicial 2-complexes to handle multiple non-manifold mesh components collectively. Building on the success of quadric error simplification, we iteratively collapse 1-simplices (vertex pairs). Our approach employs a modified quadric error that converges to the original quadric error metric for watertight manifold meshes, while significantly improving the results on wild meshes. For textures, instead of following existing strategies to preserve UVs, we adopt a novel perspective which focuses on computing mesh correspondences throughout the decimation, independent of the UV layout. This combination yields a textured mesh simplification system that is capable of handling arbitrary triangle meshes, achieving to high-quality results on wild inputs without sacrificing the excellent performance on clean inputs. Our method guarantees to avoid common problems in textured mesh simplification, including the prevalent problem of texture bleeding. We extensively evaluate our method on multiple datasets, showing improvements over prior techniques through qualitative, quantitative, and user study evaluations.

30 Sep 2025

While collaborative filtering delivers predictive accuracy and efficiency, and Large Language Models (LLMs) enable expressive and generalizable reasoning, modern recommendation systems must bring these strengths together. Growing user expectations, such as natural-language queries and transparent explanations, further highlight the need for a unified approach. However, doing so is nontrivial. Collaborative signals are often token-efficient but semantically opaque, while LLMs are semantically rich but struggle to model implicit user preferences when trained only on textual inputs. This paper introduces Item-ID + Oral-language Mixture-of-Experts Language Model (IDIOMoE), which treats item interaction histories as a native dialect within the language space, enabling collaborative signals to be understood in the same way as natural language. By splitting the Feed Forward Network of each block of a pretrained LLM into a separate text expert and an item expert with token-type gating, our method avoids destructive interference between text and catalog modalities. IDIOMoE demonstrates strong recommendation performance across both public and proprietary datasets, while preserving the text understanding of the pretrained model.

15 Nov 2023


AdaptNet, developed by researchers from institutions including Clemson University, McGill University, and Roblox, introduces a two-tier architecture for rapidly adapting pre-trained physics-based character control policies. It achieves significant reductions in training time, enabling adaptation to new motion styles, character morphologies, and complex terrains within minutes to hours, compared to days or years for training from scratch.

01 Aug 2025
A team from Carnegie Mellon University, Roblox, and Stanford University developed Octree-based Adaptive Tokenization (OAT) for 3D shapes, which dynamically adjusts latent representation capacity based on local geometric complexity. This approach enables a more efficient autoregressive generative model, OctreeGPT, to reconstruct 3D models with up to a 50% token reduction and generate high-fidelity shapes from text prompts in approximately 11 seconds per shape, outperforming prior methods in quality and speed.

21 May 2025
Diffusion Transformers (DiT) have emerged as powerful generative models for
various tasks, including image, video, and speech synthesis. However, their
inference process remains computationally expensive due to the repeated
evaluation of resource-intensive attention and feed-forward modules. To address
this, we introduce SmoothCache, a model-agnostic inference acceleration
technique for DiT architectures. SmoothCache leverages the observed high
similarity between layer outputs across adjacent diffusion timesteps. By
analyzing layer-wise representation errors from a small calibration set,
SmoothCache adaptively caches and reuses key features during inference. Our
experiments demonstrate that SmoothCache achieves 8% to 71% speed up while
maintaining or even improving generation quality across diverse modalities. We
showcase its effectiveness on DiT-XL for image generation, Open-Sora for
text-to-video, and Stable Audio Open for text-to-audio, highlighting its
potential to enable real-time applications and broaden the accessibility of
powerful DiT models.

03 Apr 2025
We present GEOPARD, a transformer-based architecture for predicting
articulation from a single static snapshot of a 3D shape. The key idea of our
method is a pretraining strategy that allows our transformer to learn plausible
candidate articulations for 3D shapes based on a geometric-driven search
without manual articulation annotation. The search automatically discovers
physically valid part motions that do not cause detachments or collisions with
other shape parts. Our experiments indicate that this geometric pretraining
strategy, along with carefully designed choices in our transformer
architecture, yields state-of-the-art results in articulation inference in the
PartNet-Mobility dataset.

22 Sep 2024
Researchers from Northeastern University and Microsoft Research developed MultiPL-T, a method for generating high-quality semi-synthetic training data for Code Large Language Models (LLMs) in low-resource programming languages. Fine-tuning models with this test-validated data significantly boosted their performance on benchmarks, often more than doubling `pass@1` scores for languages like OCaml and Racket, and demonstrated weak-to-strong supervision.

14 Oct 2025
We introduce Kinematic Kitbashing, an automatic framework that synthesizes functionality-aware articulated objects by reusing parts from existing models. Given a kinematic graph with a small collection of articulated parts, our optimizer jointly solves for the spatial placement of every part so that (i) attachments remain geometrically sound over the entire range of motion and (ii) the assembled object satisfies user-specified functional goals such as collision-free actuation, reachability, or trajectory following. At its core is a kinematics-aware attachment energy that aligns vector distance function features sampled across multiple articulation snapshots. We embed this attachment term within an annealed Riemannian Langevin dynamics sampler that treats functionality objectives as additional energies, enabling robust global exploration while accommodating non-differentiable functionality objectives and constraints. Our framework produces a wide spectrum of assembled articulated shapes, from trash-can wheels grafted onto car bodies to multi-segment lamps, gear-driven paddlers, and reconfigurable furniture, and delivers strong quantitative improvements over state-of-the-art baselines across geometric, kinematic, and functional metrics. By tightly coupling articulation-aware geometry matching with functionality-driven optimization, Kinematic Kitbashing bridges part-based shape modeling and functional assembly design, empowering rapid creation of interactive articulated assets.

01 Jun 2024
Vertex Block Descent introduces a novel physics solver that achieves unconditional stability, superior computational performance, and numerical convergence to implicit Euler integration for deformable body simulations. The solver efficiently handles millions of degrees of freedom and complex collisions, enabling large-scale real-time graphics applications even under extreme conditions and limited iteration budgets.

30 Mar 2025

The paper evaluates large language models' (LLMs) ethical awareness in Motivational Interviewing (MI), specifically their propensity to misuse MI for commercial sales, which MI's founders deemed unethical. It found that LLMs often comply with unethical requests, particularly for selling neutral products, but a proposed "Chain-of-Ethic" prompt significantly improved ethical response generation and detection.

01 Feb 2025
Researchers from Roblox, the University of Illinois Chicago, Columbia University, and the University of California San Diego introduced a method to enhance game recommendations on Roblox by leveraging Large Language Models (LLMs). Their approach generates comprehensive game profiles from in-game text and employs a personalized LLM-based reranking strategy, which led to improved user engagement and recommendation quality, particularly at top ranks.
There are no more papers matching your filters at the moment.
