
09 Oct 2025





This survey paper systematically synthesizes advancements in Reinforcement Learning (RL) for Large Reasoning Models (LRMs), moving beyond human alignment to focus on enhancing intrinsic reasoning capabilities through verifiable rewards. It identifies key components, challenges, and future directions for scaling RL towards Artificial SuperIntelligence (ASI).

08 Nov 2025
 University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign University of California, Santa Barbara
University of California, Santa Barbara Chinese Academy of Sciences
Chinese Academy of Sciences Imperial College LondonShanghai AI Laboratory
Imperial College LondonShanghai AI Laboratory National University of Singapore
National University of Singapore University College London
University College London University of Oxford
University of Oxford Fudan University
Fudan University University of Science and Technology of China
University of Science and Technology of China University of Bristol
University of Bristol The Chinese University of Hong Kong
The Chinese University of Hong Kong University of California, San DiegoDalian University of Technology
University of California, San DiegoDalian University of Technology University of Georgia
University of Georgia Brown University
Brown UniversityA comprehensive survey formally defines Agentic Reinforcement Learning (RL) for Large Language Models (LLMs) as a Partially Observable Markov Decision Process (POMDP), distinct from conventional LLM-RL, and provides a two-tiered taxonomy of capabilities and task domains. The work consolidates open-source resources and outlines critical open challenges for the field.
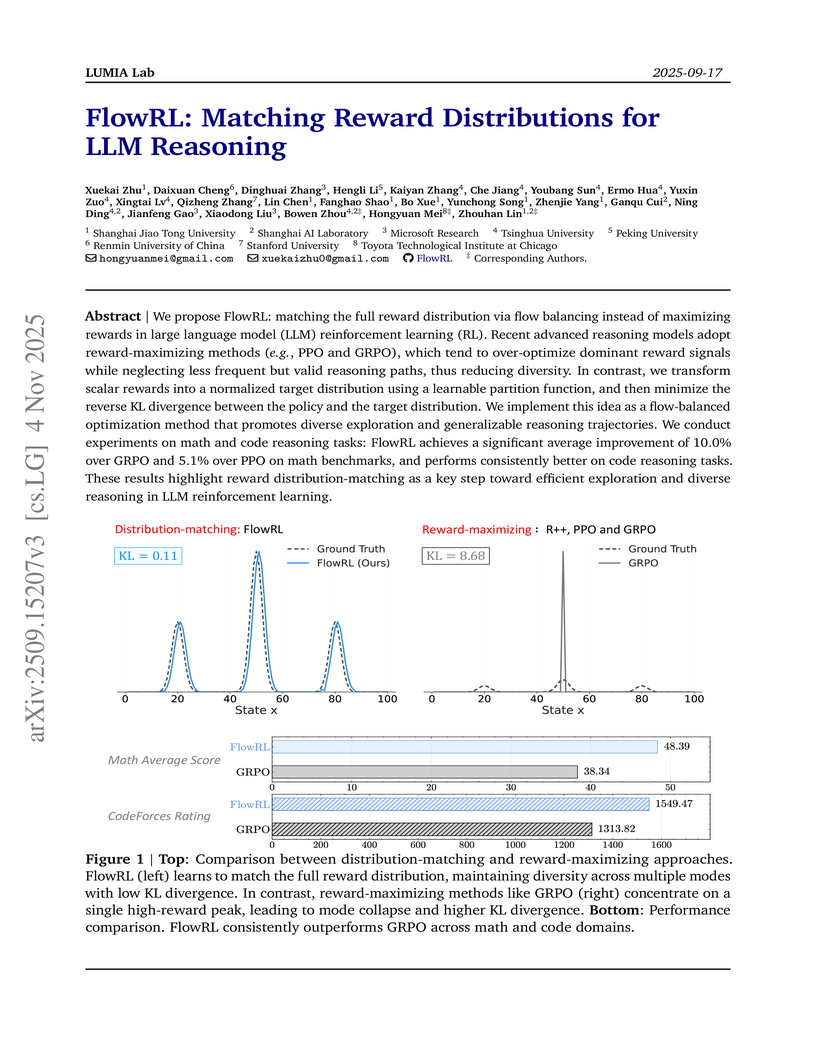
04 Nov 2025





FlowRL presents a policy optimization algorithm for large language models that leverages GFlowNet principles to match reward distributions rather than merely maximizing expected reward. This approach yielded superior performance on math and code reasoning benchmarks and notably increased the diversity of generated solutions.

27 Aug 2025
InternVL3.5, developed by the InternVL Team at Shanghai AI Laboratory, introduces a new family of open-source multimodal models that achieves state-of-the-art results across 35 benchmarks, narrowing the performance gap with commercial systems to 3.9%, while delivering a 4.05x inference speedup through novel architectural and training strategies.

27 Oct 2025

Researchers from MMLab, Tsinghua University, Kuaishou Technology, and Shanghai AI Lab developed Flow-GRPO, a framework that integrates online policy gradient reinforcement learning into flow matching models. This method significantly enhances capabilities in compositional image generation, visual text rendering, and human preference alignment, achieving up to 95% GenEval accuracy on SD3.5-M by addressing challenges of determinism and sampling efficiency through an ODE-to-SDE conversion and denoising reduction.

05 Dec 2024

FlashSloth, developed by researchers from Xiamen University, Tencent Youtu Lab, and Shanghai AI Laboratory, introduces a Multimodal Large Language Model (MLLM) architecture that significantly improves efficiency through embedded visual compression. The approach reduces visual tokens by 80-89% and achieves 2-5 times faster response times, while maintaining highly competitive performance across various vision-language benchmarks.

23 May 2024

Researchers from Fudan University and Shanghai AI Laboratory introduce "Make-it-Real," a framework that leverages GPT-4V to automatically paint 3D objects with realistic materials from albedo-only inputs. It generates a full suite of SVBRDF maps, achieving up to 77.8% human user preference and 84.8% GPT evaluation preference for refined objects over unrefined ones, significantly enhancing visual authenticity.

28 May 2025
This paper identifies and characterizes a universal policy entropy collapse in reinforcement learning for large language models (LLMs), revealing an empirical law that links performance to entropy. It further provides a mechanistic understanding of this phenomenon through covariance analysis and proposes two covariance-aware regularization methods, Clip-Cov and KL-Cov, which successfully maintain higher entropy and improve LLM reasoning performance on math and coding tasks.

04 Sep 2025
Researchers from Tsinghua University and Shanghai AI Lab introduce a unified theoretical framework that views various Large Language Model (LLM) post-training algorithms as a single optimization process. Based on this framework, they propose Hybrid Post-Training (HPT), a dynamic algorithm that adaptively switches between Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) signals, achieving state-of-the-art performance on mathematical reasoning benchmarks.

22 Jun 2025



LUFFY introduces a framework that enhances Large Reasoning Models (LRMs) by integrating off-policy guidance into Reinforcement Learning with Verifiable Rewards (RLVR). This approach enables LRMs to acquire new reasoning capabilities from stronger external policies, achieving state-of-the-art performance on math benchmarks, superior generalization on out-of-distribution tasks, and successfully training weaker foundation models where on-policy methods fail.

09 Sep 2025
F₁, a Vision-Language-Action (VLA) model, integrates explicit visual foresight into its decision-making process, moving beyond purely reactive control. This approach yields enhanced robustness in dynamic environments and improved generalization across a range of real-world and simulated robotic manipulation tasks.

19 Apr 2025


InternVL3 establishes a new native multimodal pre-training paradigm for MLLMs, allowing the model to jointly acquire visual and linguistic capabilities from the outset. This approach achieves state-of-the-art performance among open-source models, reaching 72.2 on the MMMU benchmark, and demonstrates strong competitiveness with leading proprietary models across a wide range of multimodal tasks.

07 Oct 2025
Lumina-DiMOO is an omni diffusion large language model employing fully discrete diffusion for unified multi-modal generation and understanding, achieving state-of-the-art performance across text-to-image, image-to-image, and visual understanding benchmarks, while also demonstrating a 32x speed improvement in T2I generation compared to leading autoregressive models.

25 Sep 2025
SIM-CoT stabilizes and enhances implicit Chain-of-Thought reasoning in large language models by integrating fine-grained, step-level supervision for latent tokens during training. It addresses latent instability, achieves higher accuracy than explicit CoT in some settings while preserving inference efficiency, and offers unprecedented interpretability into the model's internal thought processes.

13 Oct 2025
Researchers at University of Illinois Urbana-Champaign, Tsinghua University, Peking University, and Shanghai AI Laboratory provide evidence that large language models (LLMs) can acquire new, generalizable compositional skills through reinforcement learning (RL) post-training. Their controlled synthetic experiments show that RL enables LLMs to compose atomic skills for complex tasks, demonstrating significant generalization to unseen difficulties and cross-task transfer, a capability not achieved by supervised fine-tuning.

19 May 2025

Shanghai AI Laboratory's SpatialVLA introduces novel spatial representations for Vision-Language-Action models, equipping them with profound 3D spatial understanding via Ego3D Position Encoding for observations and unifying actions via Adaptive Action Grids. The model achieves state-of-the-art zero-shot performance on diverse real-world robot tasks and demonstrates efficient adaptation to new robot setups, surpassing larger models like RT-2-X with a smaller parameter count.

23 Mar 2023


This paper introduces UniAD, a comprehensive, planning-oriented end-to-end framework for autonomous driving that integrates perception, prediction, and planning tasks into a single neural network. It achieves state-of-the-art performance across all integrated tasks on the nuScenes benchmark, demonstrating improved accuracy in motion forecasting and planning safety over previous methods.

16 Sep 2025
The PeCL framework enables privacy-enhanced continual learning for Large Language Models by introducing a novel token-level dynamic differential privacy mechanism and a privacy-guided memory sculpting module. This approach allows models to selectively forget sensitive information while efficiently retaining crucial task-invariant knowledge, outperforming existing baselines in balancing utility and privacy.

15 Oct 2025
The EO-Robotics Team developed EO-1, a 3B parameter embodied foundation model, employing a unified architecture and interleaved vision-text-action pretraining for general robot control. The model achieved state-of-the-art performance, surpassing GPT-4o and Gemini 1.5 Flash in overall embodied reasoning, and demonstrated an 86.0% completion rate across 28 diverse real-world manipulation tasks.

26 Sep 2025

Shanghai AI Laboratory's InternVL 2.5 introduces an advanced series of open-source multimodal large language models (MLLMs) that achieve competitive performance against leading commercial models. The research systematically explores model, data, and test-time scaling strategies, resulting in the first open-source MLLM to surpass 70% on the challenging MMMU benchmark.
There are no more papers matching your filters at the moment.
