
01 Oct 2025




The "Transformer Cookbook" systematically compiles and standardizes techniques for explicitly encoding various algorithms into transformer parameters, offering a unified reference of "recipes" for implementing computational primitives. This resource aims to make complex transformer constructions more accessible and uniform for researchers, bridging theoretical understanding with practical application.
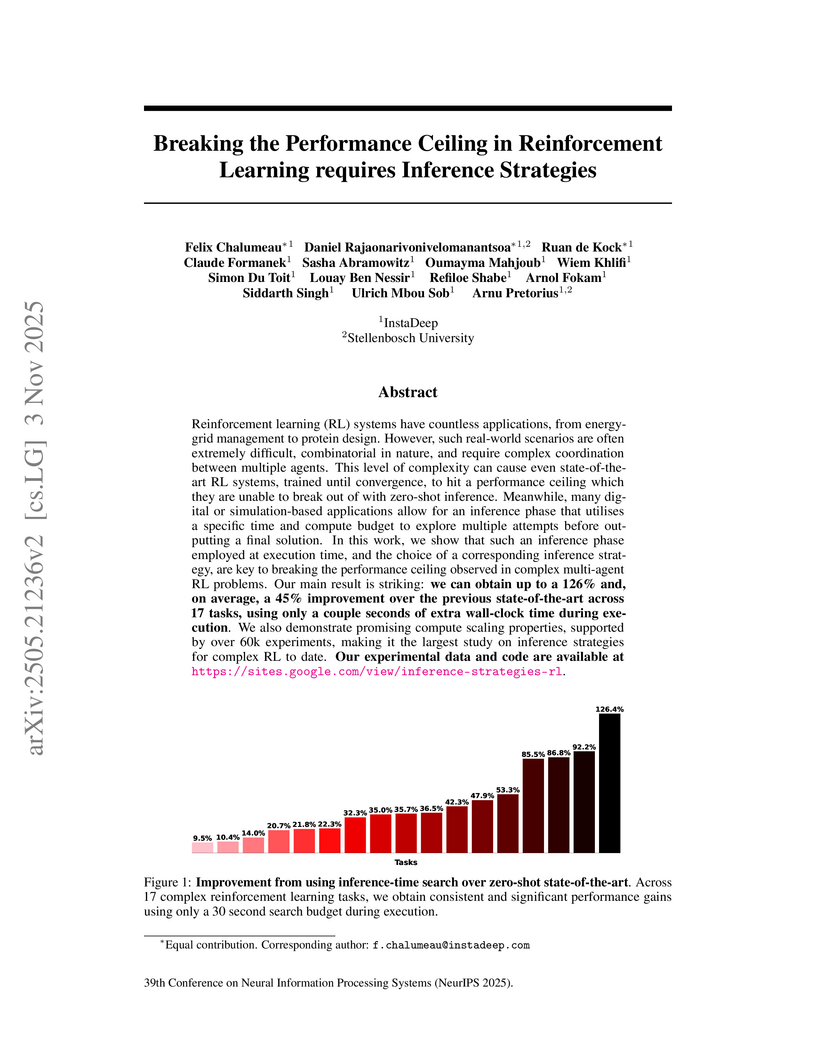
03 Nov 2025

Reinforcement learning (RL) systems have countless applications, from energy-grid management to protein design. However, such real-world scenarios are often extremely difficult, combinatorial in nature, and require complex coordination between multiple agents. This level of complexity can cause even state-of-the-art RL systems, trained until convergence, to hit a performance ceiling which they are unable to break out of with zero-shot inference. Meanwhile, many digital or simulation-based applications allow for an inference phase that utilises a specific time and compute budget to explore multiple attempts before outputting a final solution. In this work, we show that such an inference phase employed at execution time, and the choice of a corresponding inference strategy, are key to breaking the performance ceiling observed in complex multi-agent RL problems. Our main result is striking: we can obtain up to a 126% and, on average, a 45% improvement over the previous state-of-the-art across 17 tasks, using only a couple seconds of extra wall-clock time during execution. We also demonstrate promising compute scaling properties, supported by over 60k experiments, making it the largest study on inference strategies for complex RL to date. Our experimental data and code are available at this https URL.

02 Jun 2025
We introduce LinearVC, a simple voice conversion method that sheds light on
the structure of self-supervised representations. First, we show that simple
linear transformations of self-supervised features effectively convert voices.
Next, we probe the geometry of the feature space by constraining the set of
allowed transformations. We find that just rotating the features is sufficient
for high-quality voice conversion. This suggests that content information is
embedded in a low-dimensional subspace which can be linearly transformed to
produce a target voice. To validate this hypothesis, we finally propose a
method that explicitly factorizes content and speaker information using
singular value decomposition; the resulting linear projection with a rank of
just 100 gives competitive conversion results. Our work has implications for
both practical voice conversion and a broader understanding of self-supervised
speech representations. Samples and code: this https URL

28 Apr 2024






Researchers from Google DeepMind and Google Research, in collaboration with academic institutions, present the first systematic ethical framework for advanced AI assistants. Their analysis details the opportunities and profound risks of these new systems, emphasizing challenges in human-AI interaction and societal integration, and calls for new sociotechnical evaluation methods.

12 Sep 2025
We compare two quantum approaches that use support vector machines for multi-class classification on a reduced Sloan Digital Sky Survey (SDSS) dataset: the quantum kernel-based QSVM and the Harrow-Hassidim-Lloyd least-squares SVM (HHL LS-SVM). Both one-vs-rest and two-step hierarchical classification schemes were implemented. The QSVM involves angle encoding of ten features, two unitary operator blocks consisting of rotational operator gates, and a projective measurement that projects the final state to the zero state. The HHL-based method involves solving a system of linear equations using the HHL algorithm and using the solution in a support vector machine approach. The results indicate that the QSVM outperforms HHL LS-SVM in most cases. HHL LS-SVM performs somewhat competitively in selected cases, particularly when isolating galaxies (majority), however, it also performs poorly in others, especially when isolating QSOs (minority). Comparisons with classical SVMs confirm that quantum and classical methods achieve broadly similar performance, with classical models performing slightly ahead overall. Scaling analysis reveals a trade-off: QSVM performance suffers from quadratic scaling with the number of samples and features, but benefits from explicit feature representation during training, while HHL LS-SVM scales essentially constantly, with moderate fluctuations, but suffers from limited representative elements. The HHL-based method is also highly noise-sensitive. These results suggest that QSVM performs better overall and will perform better on current hardware as well, but that the more efficient scaling of HHL LS-SVM makes it a useful option for larger datasets with many samples, especially if we move past the NISQ era.

29 Jan 2025

The 'keyword method' is an effective technique for learning vocabulary of a foreign language. It involves creating a memorable visual link between what a word means and what its pronunciation in a foreign language sounds like in the learner's native language. However, these memorable visual links remain implicit in the people's mind and are not easy to remember for a large set of words. To enhance the memorisation and recall of the vocabulary, we developed an application that combines the keyword method with text-to-image generators to externalise the memorable visual links into visuals. These visuals represent additional stimuli during the memorisation process. To explore the effectiveness of this approach we first run a pilot study to investigate how difficult it is to externalise the descriptions of mental visualisations of memorable links, by asking participants to write them down. We used these descriptions as prompts for text-to-image generator (DALL-E2) to convert them into images and asked participants to select their favourites. Next, we compared different text-to-image generators (DALL-E2, Midjourney, Stable and Latent Diffusion) to evaluate the perceived quality of the generated images by each. Despite heterogeneous results, participants mostly preferred images generated by DALL-E2, which was used also for the final study. In this study, we investigated whether providing such images enhances the retention of vocabulary being learned, compared to the keyword method only. Our results indicate that people did not encounter difficulties describing their visualisations of memorable links and that providing corresponding images significantly improves memory retention.
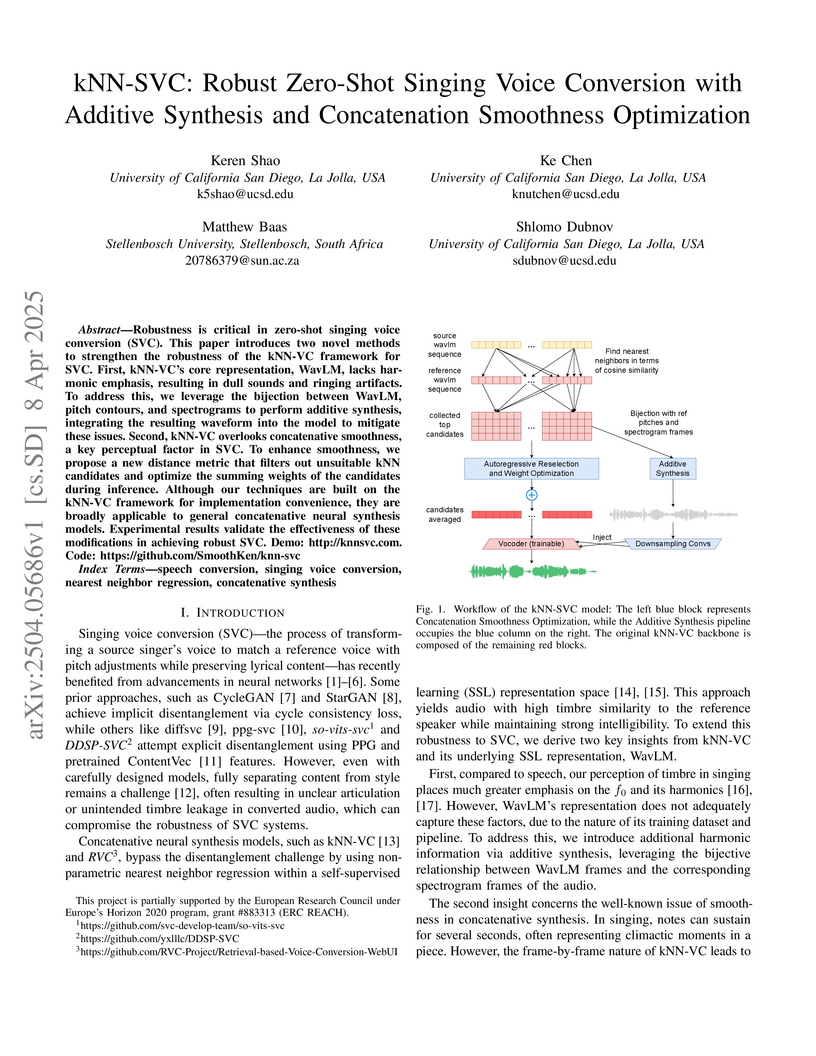
08 Apr 2025

A concatenative neural synthesis framework for zero-shot singing voice conversion combines additive synthesis and concatenation smoothness optimization to enhance voice conversion quality, achieving improved performance on both intra-language and cross-language tasks while reducing temporal artifacts and maintaining speaker similarity.

08 Jun 2022
This research introduces soft speech units for self-supervised voice conversion, addressing the issue of linguistic content loss observed with discrete units. It demonstrates that modeling a distribution over discrete units substantially improves the intelligibility and naturalness of converted speech while maintaining competitive speaker similarity, and enhances cross-lingual transferability.

13 Jul 2024

To reflect the extent to which science is cited in policy documents, this
paper explores the presence of policy document citations for over 18 million
Web of Science-indexed publications published between 2010 and 2019. Enabled by
the policy document citation data provided by Overton, a searchable index of
policy documents worldwide, the results show that there are 3.9% of
publications in the dataset cited at least once by policy documents. Policy
document citations present a citation delay towards newly published
publications and show a stronger predominance to the document types of review
and article. Based on the Overton database, publications in the field of Social
Sciences and Humanities have the highest relative presence in policy document
citations, followed by Life and Earth Sciences and Biomedical and Health
Sciences. Our findings shed light not only on the impact of scientific
knowledge on the policy-making process, but also on the particular focus of
policy documents indexed by Overton on specific research areas.

02 Oct 2025
The most elementary non-Hermitian quantum square-well problem with real spectrum is considered. The Schroedinger equation is required discrete and endowed with PT-symmetric Robin (i.e., two-parametric) boundary conditions. Some of the rather enigmatic aspects of impact of the variability of the parameters on the emergence of the Kato's exceptional-point (EP) singularities is clarified. In particular, the current puzzle of the apparent absence of the EP degeneracies at the odd-matrix dimensions in certain simplified one-parametric cases is explained. A not quite expected existence of a multi-band spectral structure in another simplified one-parametric family of models is also revealed.

11 Apr 2025
This study applies the Variational Quantum Eigensolver (VQE) algorithm to determine the spin-state energetics of a simplified heme-related model, Fe(CH3N2)2-(OH2). The VQE calculations demonstrated agreement with classical CASSCF methods within 1-4 kcal/mol for active spaces up to 10 spatial orbitals, with multi-reference initial states improving accuracy.

25 Jun 2024


Researchers developed CMBFSCNN, a convolutional neural network, to accurately subtract astrophysical foregrounds from Cosmic Microwave Background polarization data. The method successfully recovers the CMB lensing B-mode power spectrum from simulations for next-generation experiments like CMB-S4 and LiteBIRD, demonstrating high fidelity in map-level recovery and power spectrum reconstruction.

09 Oct 2025

This work formally links continuous flow models from machine learning with the Schrödinger equation via a "continuity Hamiltonian," providing an efficient quantum algorithm to prepare quantum samples (qsamples) for distributions learned by these models, which offers advantages for statistical inference tasks like mean estimation.

02 Jul 2025
This paper critically examines current automatic speaker similarity assessment methods in speech synthesis, demonstrating that automatic speaker verification (ASV) embeddings primarily capture static voice features and are highly susceptible to confounding factors like utterance duration and noise. The research proposes U3D (Unit Duration Distribution Distance), a novel metric designed to quantify dynamic rhythmic patterns, offering a more comprehensive approach to evaluating speaker identity in synthesized speech.

03 Jan 2025
Humanoid robots must master numerous tasks with sparse rewards, posing a challenge for reinforcement learning (RL). We propose a method combining RL and automated planning to address this. Our approach uses short goal-conditioned policies (GCPs) organized hierarchically, with Monte Carlo Tree Search (MCTS) planning using high-level actions (HLAs). Instead of primitive actions, the planning process generates HLAs. A single plan-tree, maintained during the agent's lifetime, holds knowledge about goal achievement. This hierarchy enhances sample efficiency and speeds up reasoning by reusing HLAs and anticipating future actions. Our Hierarchical Goal-Conditioned Policy Planning (HGCPP) framework uniquely integrates GCPs, MCTS, and hierarchical RL, potentially improving exploration and planning in complex tasks.

10 Jan 2025
Codec-based text-to-speech (TTS) models have shown impressive quality with zero-shot voice cloning abilities. However, they often struggle with more expressive references or complex text inputs. We present MARS6, a robust encoder-decoder transformer for rapid, expressive TTS. MARS6 is built on recent improvements in spoken language modelling. Utilizing a hierarchical setup for its decoder, new speech tokens are processed at a rate of only 12 Hz, enabling efficient modelling of long-form text while retaining reconstruction quality. We combine several recent training and inference techniques to reduce repetitive generation and improve output stability and quality. This enables the 70M-parameter MARS6 to achieve similar performance to models many times larger. We show this in objective and subjective evaluations, comparing TTS output quality and reference speaker cloning ability. Project page: this https URL

13 May 2024
Many natural language processing systems operate over tokenizations of text
to address the open-vocabulary problem. In this paper, we give and analyze an
algorithm for the efficient construction of deterministic finite automata
designed to operate directly on tokenizations produced by the popular byte pair
encoding technique. This makes it possible to apply many existing techniques
and algorithms to the tokenized case, such as pattern matching, equivalence
checking of tokenization dictionaries, and composing tokenized languages in
various ways.

30 Oct 2025
A key challenge in offline multi-agent reinforcement learning (MARL) is achieving effective many-agent multi-step coordination in complex environments. In this work, we propose Oryx, a novel algorithm for offline cooperative MARL to directly address this challenge. Oryx adapts the recently proposed retention-based architecture Sable and combines it with a sequential form of implicit constraint Q-learning (ICQ), to develop a novel offline autoregressive policy update scheme. This allows Oryx to solve complex coordination challenges while maintaining temporal coherence over long trajectories. We evaluate Oryx across a diverse set of benchmarks from prior works -- SMAC, RWARE, and Multi-Agent MuJoCo -- covering tasks of both discrete and continuous control, varying in scale and difficulty. Oryx achieves state-of-the-art performance on more than 80% of the 65 tested datasets, outperforming prior offline MARL methods and demonstrating robust generalisation across domains with many agents and long horizons. Finally, we introduce new datasets to push the limits of many-agent coordination in offline MARL, and demonstrate Oryx's superior ability to scale effectively in such settings.

26 Sep 2025
We introduce a method that generates ground-state ansatzes for quantum many-body systems which are both analytically tractable and accurate over wide parameter regimes. Our approach leverages a custom symbolic language to construct tensor network states (TNS) via an evolutionary algorithm. This language provides operations that allow the generated TNS to automatically scale with system size. Consequently, we can evaluate ansatz fitness for small systems, which is computationally efficient, while favouring structures that continue to perform well with increasing system size. This ensures that the ansatz captures robust features of the ground state structure. Remarkably, we find analytically tractable ansatzes with a degree of universality, which encode correlations, capture finite-size effects, accurately predict ground-state energies, and offer a good description of critical phenomena. We demonstrate this method on the Lipkin-Meshkov-Glick model (LMG) and the quantum transverse-field Ising model (TFIM), where the same ansatz was independently generated for both. The simple structure of the ansatz allows us to obtain exact expressions for the expectation values of local observables as well as for correlation functions. In addition, it permits symmetries that are broken in the ansatz to be restored, which provides a systematic means of improving the accuracy of the ansatz.

05 Sep 2025
 Harvard University
Harvard University University of Manchester
University of Manchester University of Oxford
University of Oxford University of California, Irvine
University of California, Irvine Stanford University
Stanford University Columbia UniversityHarvard Medical School
Columbia UniversityHarvard Medical School Rice UniversityThe University of SydneyDeakin UniversityHarvard T.H. Chan School of Public HealthStellenbosch UniversityBaylor College of MedicineUniversity of Colorado Anschutz Medical CampusUniversity of Nebraska Medical CenterCentre for Addiction and Mental HealthCharité—Universitätsmedizin BerlinPontificia Universidad JaverianaLaureate Institute for Brain ResearchThe University of Texas Southwestern Medical CenterNational Institute of Mental Health and NeurosciencesBrandenburg Medical School Theodor FontaneNational Institute for Health and Care Research (NIHR) Oxford Health Biomedical Research CentreImmanuel Hospital RüdersdorfNational Alliance on Mental Illness (NAMI)Beth-Israel Deaconess Medical Center
Rice UniversityThe University of SydneyDeakin UniversityHarvard T.H. Chan School of Public HealthStellenbosch UniversityBaylor College of MedicineUniversity of Colorado Anschutz Medical CampusUniversity of Nebraska Medical CenterCentre for Addiction and Mental HealthCharité—Universitätsmedizin BerlinPontificia Universidad JaverianaLaureate Institute for Brain ResearchThe University of Texas Southwestern Medical CenterNational Institute of Mental Health and NeurosciencesBrandenburg Medical School Theodor FontaneNational Institute for Health and Care Research (NIHR) Oxford Health Biomedical Research CentreImmanuel Hospital RüdersdorfNational Alliance on Mental Illness (NAMI)Beth-Israel Deaconess Medical CenterIndividuals are increasingly utilizing large language model (LLM)based tools for mental health guidance and crisis support in place of human experts. While AI technology has great potential to improve health outcomes, insufficient empirical evidence exists to suggest that AI technology can be deployed as a clinical replacement; thus, there is an urgent need to assess and regulate such tools. Regulatory efforts have been made and multiple evaluation frameworks have been proposed, however,field-wide assessment metrics have yet to be formally integrated. In this paper, we introduce a comprehensive online platform that aggregates evaluation approaches and serves as a dynamic online resource to simplify LLM and LLM-based tool assessment: MindBenchAI. At its core, MindBenchAI is designed to provide easily accessible/interpretable information for diverse stakeholders (patients, clinicians, developers, regulators, etc.). To create MindBenchAI, we built off our work developing this http URL to support informed decision-making around smartphone app use for mental health, and expanded the technical this http URL framework to encompass novel large language model (LLM) functionalities through benchmarking approaches. The MindBenchAI platform is designed as a partnership with the National Alliance on Mental Illness (NAMI) to provide assessment tools that systematically evaluate LLMs and LLM-based tools with objective and transparent criteria from a healthcare standpoint, assessing both profile (i.e. technical features, privacy protections, and conversational style) and performance characteristics (i.e. clinical reasoning skills).
There are no more papers matching your filters at the moment.
