
10 Aug 2020
The Pop Music Transformer, developed by Taiwan AI Labs and Academia Sinica, introduces REMI (REvamped MIDI-derived events), a novel music representation for Transformer models that explicitly encodes metrical, temporal, and harmonic information. This approach significantly enhances the rhythmic consistency and controllability of automatically generated Pop piano compositions, demonstrating improved objective metrics for beat and downbeat stability and a marked preference in subjective listening tests.

21 Jul 2024
Existing text-to-music models can produce high-quality audio with great diversity. However, textual prompts alone cannot precisely control temporal musical features such as chords and rhythm of the generated music. To address this challenge, we introduce MusiConGen, a temporally-conditioned Transformer-based text-to-music model that builds upon the pretrained MusicGen framework. Our innovation lies in an efficient finetuning mechanism, tailored for consumer-grade GPUs, that integrates automatically-extracted rhythm and chords as the condition signal. During inference, the condition can either be musical features extracted from a reference audio signal, or be user-defined symbolic chord sequence, BPM, and textual prompts. Our performance evaluation on two datasets -- one derived from extracted features and the other from user-created inputs -- demonstrates that MusiConGen can generate realistic backing track music that aligns well with the specified conditions. We open-source the code and model checkpoints, and provide audio examples online, this https URL.
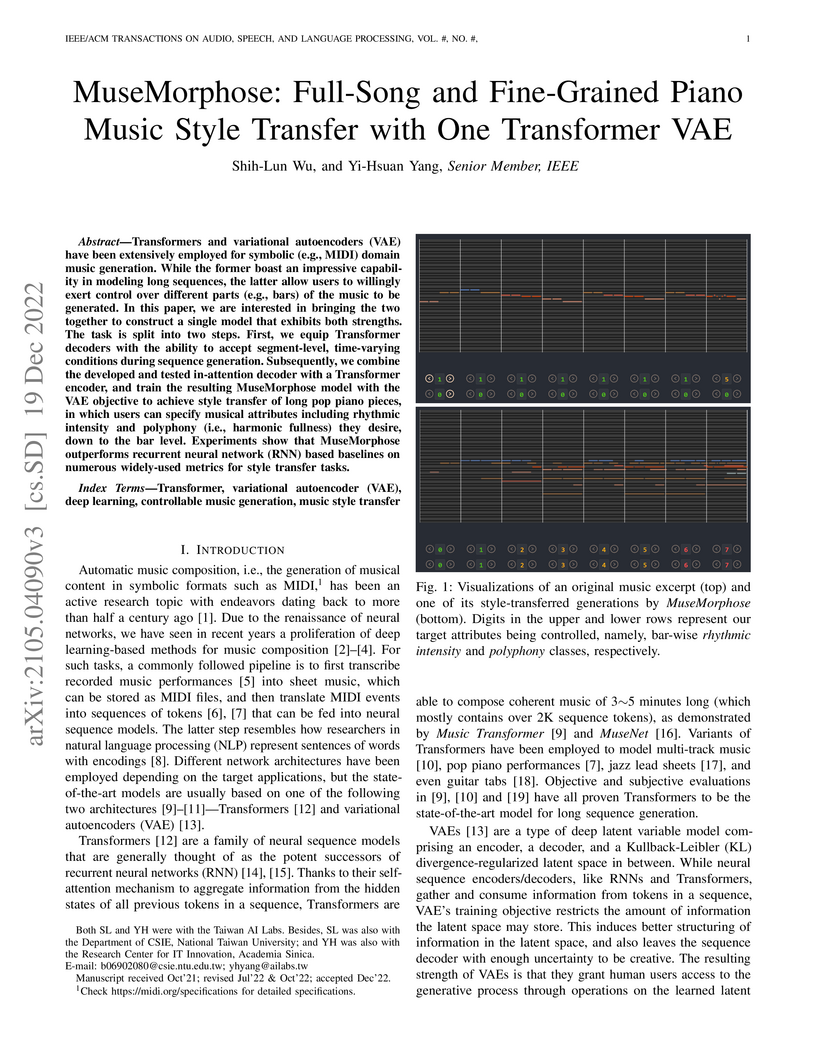
19 Dec 2022
MuseMorphose integrates Transformer architectures with Variational Autoencoders to achieve fine-grained, bar-level style transfer for full-length piano music. It introduces an "in-attention" mechanism for segment-level conditioning, enabling highly independent control over musical attributes like rhythmic intensity and polyphony with superior fidelity and fluency compared to previous RNN-based VAE methods.

02 Jun 2025
Large language models (LLMs) increasingly shape public understanding and
civic decisions, yet their ideological neutrality is a growing concern. While
existing research has explored various forms of LLM bias, a direct,
cross-lingual comparison of models with differing geopolitical
alignments-specifically a PRC-system model versus a non-PRC counterpart-has
been lacking. This study addresses this gap by systematically evaluating
DeepSeek-R1 (PRC-aligned) against ChatGPT o3-mini-high (non-PRC) for
Chinese-state propaganda and anti-U.S. sentiment. We developed a novel corpus
of 1,200 de-contextualized, reasoning-oriented questions derived from
Chinese-language news, presented in Simplified Chinese, Traditional Chinese,
and English. Answers from both models (7,200 total) were assessed using a
hybrid evaluation pipeline combining rubric-guided GPT-4o scoring with human
annotation. Our findings reveal significant model-level and language-dependent
biases. DeepSeek-R1 consistently exhibited substantially higher proportions of
both propaganda and anti-U.S. bias compared to ChatGPT o3-mini-high, which
remained largely free of anti-U.S. sentiment and showed lower propaganda
levels. For DeepSeek-R1, Simplified Chinese queries elicited the highest bias
rates; these diminished in Traditional Chinese and were nearly absent in
English. Notably, DeepSeek-R1 occasionally responded in Simplified Chinese to
Traditional Chinese queries and amplified existing PRC-aligned terms in its
Chinese answers, demonstrating an "invisible loudspeaker" effect. Furthermore,
such biases were not confined to overtly political topics but also permeated
cultural and lifestyle content, particularly in DeepSeek-R1.

12 Jul 2022
Automatically classifying electronic health records (EHRs) into diagnostic
codes has been challenging to the NLP community. State-of-the-art methods
treated this problem as a multilabel classification problem and proposed
various architectures to model this problem. However, these systems did not
leverage the superb performance of pretrained language models, which achieved
superb performance on natural language understanding tasks. Prior work has
shown that pretrained language models underperformed on this task with the
regular finetuning scheme. Therefore, this paper aims at analyzing the causes
of the underperformance and developing a framework for automatic ICD coding
with pretrained language models. We spotted three main issues through the
experiments: 1) large label space, 2) long input sequences, and 3) domain
mismatch between pretraining and fine-tuning. We propose PLMICD, a framework
that tackles the challenges with various strategies. The experimental results
show that our proposed framework can overcome the challenges and achieves
state-of-the-art performance in terms of multiple metrics on the benchmark
MIMIC data. The source code is available at this https URL

30 Jul 2021

Originating in the Renaissance and burgeoning in the digital era, tablatures are a commonly used music notation system which provides explicit representations of instrument fingerings rather than pitches. GuitarPro has established itself as a widely used tablature format and software enabling musicians to edit and share songs for musical practice, learning, and composition. In this work, we present DadaGP, a new symbolic music dataset comprising 26,181 song scores in the GuitarPro format covering 739 musical genres, along with an accompanying tokenized format well-suited for generative sequence models such as the Transformer. The tokenized format is inspired by event-based MIDI encodings, often used in symbolic music generation models. The dataset is released with an encoder/decoder which converts GuitarPro files to tokens and back. We present results of a use case in which DadaGP is used to train a Transformer-based model to generate new songs in GuitarPro format. We discuss other relevant use cases for the dataset (guitar-bass transcription, music style transfer and artist/genre classification) as well as ethical implications. DadaGP opens up the possibility to train GuitarPro score generators, fine-tune models on custom data, create new styles of music, AI-powered songwriting apps, and human-AI improvisation.

04 Jun 2018
Automatic saliency prediction in 360{\deg} videos is critical for viewpoint
guidance applications (e.g., Facebook 360 Guide). We propose a spatial-temporal
network which is (1) weakly-supervised trained and (2) tailor-made for
360{\deg} viewing sphere. Note that most existing methods are less scalable
since they rely on annotated saliency map for training. Most importantly, they
convert 360{\deg} sphere to 2D images (e.g., a single equirectangular image or
multiple separate Normal Field-of-View (NFoV) images) which introduces
distortion and image boundaries. In contrast, we propose a simple and effective
Cube Padding (CP) technique as follows. Firstly, we render the 360{\deg} view
on six faces of a cube using perspective projection. Thus, it introduces very
little distortion. Then, we concatenate all six faces while utilizing the
connectivity between faces on the cube for image padding (i.e., Cube Padding)
in convolution, pooling, convolutional LSTM layers. In this way, CP introduces
no image boundary while being applicable to almost all Convolutional Neural
Network (CNN) structures. To evaluate our method, we propose Wild-360, a new
360{\deg} video saliency dataset, containing challenging videos with saliency
heatmap annotations. In experiments, our method outperforms baseline methods in
both speed and quality.

18 May 2020
In a recent paper, we have presented a generative adversarial network
(GAN)-based model for unconditional generation of the mel-spectrograms of
singing voices. As the generator of the model is designed to take a
variable-length sequence of noise vectors as input, it can generate
mel-spectrograms of variable length. However, our previous listening test shows
that the quality of the generated audio leaves room for improvement. The
present paper extends and expands that previous work in the following aspects.
First, we employ a hierarchical architecture in the generator to induce some
structure in the temporal dimension. Second, we introduce a cycle
regularization mechanism to the generator to avoid mode collapse. Third, we
evaluate the performance of the new model not only for generating singing
voices, but also for generating speech voices. Evaluation result shows that new
model outperforms the prior one both objectively and subjectively. We also
employ the model to unconditionally generate sequences of piano and violin
music and find the result promising. Audio examples, as well as the code for
implementing our model, will be publicly available online upon paper
publication.

16 Jun 2021
This paper presents a novel system architecture that integrates blind source
separation with joint beat and downbeat tracking in musical audio signals. The
source separation module segregates the percussive and non-percussive
components of the input signal, over which beat and downbeat tracking are
performed separately and then the results are aggregated with a learnable
fusion mechanism. This way, the system can adaptively determine how much the
tracking result for an input signal should depend on the input's percussive or
non-percussive components. Evaluation on four testing sets that feature
different levels of presence of drum sounds shows that the new architecture
consistently outperforms the widely-adopted baseline architecture that does not
employ source separation.

22 Sep 2022
This paper proposes a new benchmark task for generat-ing musical passages in
the audio domain by using thedrum loops from the FreeSound Loop Dataset, which
arepublicly re-distributable. Moreover, we use a larger col-lection of drum
loops from Looperman to establish fourmodel-based objective metrics for
evaluation, releasingthese metrics as a library for quantifying and
facilitatingthe progress of musical audio generation. Under this eval-uation
framework, we benchmark the performance of threerecent deep generative
adversarial network (GAN) mod-els we customize to generate loops, including
StyleGAN,StyleGAN2, and UNAGAN. We also report a subjectiveevaluation of these
models. Our evaluation shows that theone based on StyleGAN2 performs the best
in both objec-tive and subjective metrics.

07 Mar 2023

Even with strong sequence models like Transformers, generating expressive piano performances with long-range musical structures remains challenging. Meanwhile, methods to compose well-structured melodies or lead sheets (melody + chords), i.e., simpler forms of music, gained more success. Observing the above, we devise a two-stage Transformer-based framework that Composes a lead sheet first, and then Embellishes it with accompaniment and expressive touches. Such a factorization also enables pretraining on non-piano data. Our objective and subjective experiments show that Compose & Embellish shrinks the gap in structureness between a current state of the art and real performances by half, and improves other musical aspects such as richness and coherence as well.

13 Sep 2023

Conversational search provides a natural interface for information retrieval
(IR). Recent approaches have demonstrated promising results in applying dense
retrieval to conversational IR. However, training dense retrievers requires
large amounts of in-domain paired data. This hinders the development of
conversational dense retrievers, as abundant in-domain conversations are
expensive to collect. In this paper, we propose CONVERSER, a framework for
training conversational dense retrievers with at most 6 examples of in-domain
dialogues. Specifically, we utilize the in-context learning capability of large
language models to generate conversational queries given a passage in the
retrieval corpus. Experimental results on conversational retrieval benchmarks
OR-QuAC and TREC CAsT 19 show that the proposed CONVERSER achieves comparable
performance to fully-supervised models, demonstrating the effectiveness of our
proposed framework in few-shot conversational dense retrieval. All source code
and generated datasets are available at this https URL

05 Sep 2022
While generative adversarial networks (GANs) have been widely used in
research on audio generation, the training of a GAN model is known to be
unstable, time consuming, and data inefficient. Among the attempts to
ameliorate the training process of GANs, the idea of Projected GAN emerges as
an effective solution for GAN-based image generation, establishing the
state-of-the-art in different image applications. The core idea is to use a
pre-trained classifier to constrain the feature space of the discriminator to
stabilize and improve GAN training. This paper investigates whether Projected
GAN can similarly improve audio generation, by evaluating the performance of a
StyleGAN2-based audio-domain loop generation model with and without using a
pre-trained feature space in the discriminator. Moreover, we compare the
performance of using a general versus domain-specific classifier as the
pre-trained audio classifier. With experiments on both drum loop and synth loop
generation, we show that a general audio classifier works better, and that with
Projected GAN our loop generation models can converge around 5 times faster
without performance degradation.

04 Aug 2020
Deep learning algorithms are increasingly developed for learning to compose
music in the form of MIDI files. However, whether such algorithms work well for
composing guitar tabs, which are quite different from MIDIs, remain relatively
unexplored. To address this, we build a model for composing fingerstyle guitar
tabs with Transformer-XL, a neural sequence model architecture. With this
model, we investigate the following research questions. First, whether the
neural net generates note sequences with meaningful note-string combinations,
which is important for the guitar but not other instruments such as the piano.
Second, whether it generates compositions with coherent rhythmic groove,
crucial for fingerstyle guitar music. And, finally, how pleasant the composed
music is in comparison to real, human-made compositions. Our work provides
preliminary empirical evidence of the promise of deep learning for tab
composition, and suggests areas for future study.

20 Feb 2022
In this paper, we propose a new dataset named EGDB, that con-tains transcriptions of the electric guitar performance of 240 tab-latures rendered with different tones. Moreover, we benchmark theperformance of two well-known transcription models proposed orig-inally for the piano on this dataset, along with a multi-loss Trans-former model that we newly propose. Our evaluation on this datasetand a separate set of real-world recordings demonstrate the influenceof timbre on the accuracy of guitar sheet transcription, the potentialof using multiple losses for Transformers, as well as the room forfurther improvement for this task.

25 Apr 2022
With thousands of news articles from hundreds of sources distributed and shared every day, news consumption and information acquisition have been increasingly difficult for readers. Additionally, the content of news articles is becoming catchy or even inciting to attract readership, harming the accuracy of news reporting. We present Islander, an online news analyzing system. The system allows users to browse trending topics with articles from multiple sources and perspectives. We define several metrics as proxies for news quality, and develop algorithms for automatic estimation. The quality estimation results are delivered through a web interface to newsreaders for easy access to news and information. The website is publicly available at this https URL

20 Aug 2023
To model the periodicity of beats, state-of-the-art beat tracking systems use
"post-processing trackers" (PPTs) that rely on several empirically determined
global assumptions for tempo transition, which work well for music with a
steady tempo. For expressive classical music, however, these assumptions can be
too rigid. With two large datasets of Western classical piano music, namely the
Aligned Scores and Performances (ASAP) dataset and a dataset of Chopin's
Mazurkas (Maz-5), we report on experiments showing the failure of existing PPTs
to cope with local tempo changes, thus calling for new methods. In this paper,
we propose a new local periodicity-based PPT, called predominant local
pulse-based dynamic programming (PLPDP) tracking, that allows for more flexible
tempo transitions. Specifically, the new PPT incorporates a method called
"predominant local pulses" (PLP) in combination with a dynamic programming (DP)
component to jointly consider the locally detected periodicity and beat
activation strength at each time instant. Accordingly, PLPDP accounts for the
local periodicity, rather than relying on a global tempo assumption. Compared
to existing PPTs, PLPDP particularly enhances the recall values at the cost of
a lower precision, resulting in an overall improvement of F1-score for beat
tracking in ASAP (from 0.473 to 0.493) and Maz-5 (from 0.595 to 0.838).

06 Mar 2024
Dense retrieval methods have demonstrated promising performance in
multilingual information retrieval, where queries and documents can be in
different languages. However, dense retrievers typically require a substantial
amount of paired data, which poses even greater challenges in multilingual
scenarios. This paper introduces UMR, an Unsupervised Multilingual dense
Retriever trained without any paired data. Our approach leverages the sequence
likelihood estimation capabilities of multilingual language models to acquire
pseudo labels for training dense retrievers. We propose a two-stage framework
which iteratively improves the performance of multilingual dense retrievers.
Experimental results on two benchmark datasets show that UMR outperforms
supervised baselines, showcasing the potential of training multilingual
retrievers without paired data, thereby enhancing their practicality. Our
source code, data, and models are publicly available at
this https URL

14 Apr 2024
This article presents a benchmark study of symbolic piano music
classification using the masked language modelling approach of the
Bidirectional Encoder Representations from Transformers (BERT). Specifically,
we consider two types of MIDI data: MIDI scores, which are musical scores
rendered directly into MIDI with no dynamics and precisely aligned with the
metrical grid notated by its composer and MIDI performances, which are MIDI
encodings of human performances of musical scoresheets. With five public-domain
datasets of single-track piano MIDI files, we pre-train two 12-layer
Transformer models using the BERT approach, one for MIDI scores and the other
for MIDI performances, and fine-tune them for four downstream classification
tasks. These include two note-level classification tasks (melody extraction and
velocity prediction) and two sequence-level classification tasks (style
classification and emotion classification). Our evaluation shows that the BERT
approach leads to higher classification accuracy than recurrent neural network
(RNN)-based baselines.

26 Aug 2019
In this paper, we tackle the problem of transfer learning for Jazz automatic generation. Jazz is one of representative types of music, but the lack of Jazz data in the MIDI format hinders the construction of a generative model for Jazz. Transfer learning is an approach aiming to solve the problem of data insufficiency, so as to transfer the common feature from one domain to another. In view of its success in other machine learning problems, we investigate whether, and how much, it can help improve automatic music generation for under-resourced musical genres. Specifically, we use a recurrent variational autoencoder as the generative model, and use a genre-unspecified dataset as the source dataset and a Jazz-only dataset as the target dataset. Two transfer learning methods are evaluated using six levels of source-to-target data ratios. The first method is to train the model on the source dataset, and then fine-tune the resulting model parameters on the target dataset. The second method is to train the model on both the source and target datasets at the same time, but add genre labels to the latent vectors and use a genre classifier to improve Jazz generation. The evaluation results show that the second method seems to perform better overall, but it cannot take full advantage of the genre-unspecified dataset.
There are no more papers matching your filters at the moment.
