
21 Oct 2021
BEIR introduces a comprehensive benchmark for zero-shot evaluation of information retrieval models across 18 diverse datasets and 9 tasks. The study demonstrates that while traditional BM25 remains a strong zero-shot baseline, re-ranking and late-interaction models achieve the best generalization, challenging the direct correlation between in-domain performance and out-of-domain capabilities.

01 Jul 2025
When interacting with objects, humans effectively reason about which regions of objects are viable for an intended action, i.e., the affordance regions of the object. They can also account for subtle differences in object regions based on the task to be performed and whether one or two hands need to be used. However, current vision-based affordance prediction methods often reduce the problem to naive object part segmentation. In this work, we propose a framework for extracting affordance data from human activity video datasets. Our extracted 2HANDS dataset contains precise object affordance region segmentations and affordance class-labels as narrations of the activity performed. The data also accounts for bimanual actions, i.e., two hands co-ordinating and interacting with one or more objects. We present a VLM-based affordance prediction model, 2HandedAfforder, trained on the dataset and demonstrate superior performance over baselines in affordance region segmentation for various activities. Finally, we show that our predicted affordance regions are actionable, i.e., can be used by an agent performing a task, through demonstration in robotic manipulation scenarios. Project-website: this https URL

26 May 2025
Researchers at TU Darmstadt developed a formal framework using Category Theory to model knowledge domains and define analogies as structure-preserving functors, specifically addressing the representation of higher-order relations. Their method precisely delineates the shared structure (core) and combined insights (blend) of analogical reasoning through pullbacks and pushouts.

05 Feb 2015
Spectral Functions for the Quark-Meson Model Phase Diagram from the Functional Renormalization Group
Spectral Functions for the Quark-Meson Model Phase Diagram from the Functional Renormalization Group
We present a method to obtain spectral functions at finite temperature and
density from the Functional Renormalization Group. Our method is based on a
thermodynamically consistent truncation of the flow equations for 2-point
functions with analytically continued frequency components in the originally
Euclidean external momenta. For the uniqueness of this continuation at finite
temperature we furthermore implement the physical Baym-Mermin boundary
conditions. We demonstrate the feasibility of the method by calculating the
mesonic spectral functions in the quark-meson model along the temperature axis
of the phase diagram, and at finite quark chemical potential along the
fixed-temperature line that crosses the critical endpoint of the model.

21 Sep 2022


Noisy sensing, imperfect control, and environment changes are defining characteristics of many real-world robot tasks. The partially observable Markov decision process (POMDP) provides a principled mathematical framework for modeling and solving robot decision and control tasks under uncertainty. Over the last decade, it has seen many successful applications, spanning localization and navigation, search and tracking, autonomous driving, multi-robot systems, manipulation, and human-robot interaction. This survey aims to bridge the gap between the development of POMDP models and algorithms at one end and application to diverse robot decision tasks at the other. It analyzes the characteristics of these tasks and connects them with the mathematical and algorithmic properties of the POMDP framework for effective modeling and solution. For practitioners, the survey provides some of the key task characteristics in deciding when and how to apply POMDPs to robot tasks successfully. For POMDP algorithm designers, the survey provides new insights into the unique challenges of applying POMDPs to robot systems and points to promising new directions for further research.
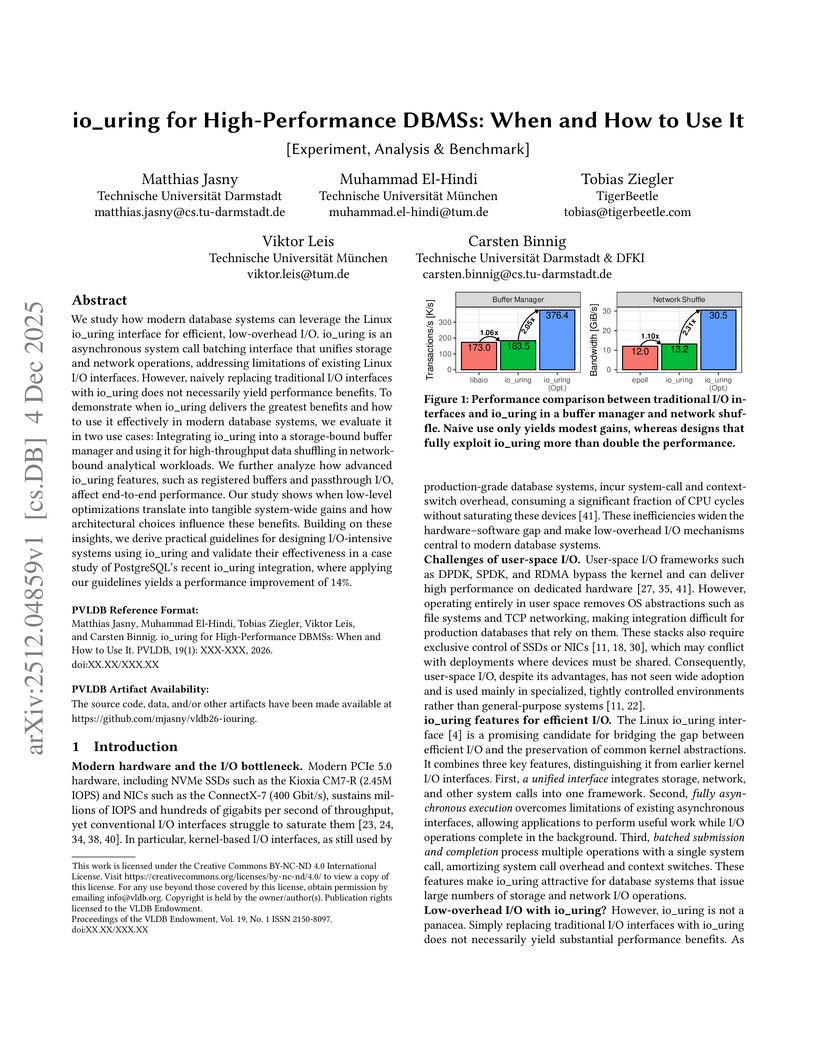
04 Dec 2025
This research investigates how the Linux io_uring interface can optimize I/O operations for high-performance database management systems (DBMSs). It demonstrates that while naive integration provides marginal benefits, deep integration and architectural alignment can more than double DBMS performance for both storage- and network-bound workloads.

20 Dec 2024
This survey provides a systematic analysis of 287 papers from top FPGA conferences over six years, comprehensively mapping the research landscape for FPGA-based machine learning accelerators. The study identifies that 81% of efforts target ML inference, highlights the maturity and decline in new research for CNNs, and notes a rapid emergence of interest in Graph Neural Networks and Attention networks.

20 Nov 2025
SVG360 introduces a three-stage pipeline for generating geometrically and color-consistent, editable multi-view Scalable Vector Graphics (SVGs) from a single SVG input. This framework produces cleaner, more compact SVG outputs with reduced path and color count, alongside enhanced cross-view stability compared to commercial tools.

26 Sep 2025
API integration is a cornerstone of our digital infrastructure, enabling software systems to connect and interact. However, as shown by many studies, writing or generating correct code to invoke APIs, particularly web APIs, is challenging. Although large language models (LLMs) have become popular in software development, their effectiveness in automating the generation of web API integration code remains unexplored. In order to address this, we present a dataset and evaluation pipeline designed to assess the ability of LLMs to generate web API invocation code. Our experiments with several open-source LLMs reveal that generating API invocations poses a significant challenge, resulting in hallucinated endpoints, incorrect argument usage, and other errors. None of the evaluated open-source models were able to solve more than 40% of the tasks.

06 Jul 2022
Mobile Manipulation (MM) systems are ideal candidates for taking up the role
of a personal assistant in unstructured real-world environments. Among other
challenges, MM requires effective coordination of the robot's embodiments for
executing tasks that require both mobility and manipulation. Reinforcement
Learning (RL) holds the promise of endowing robots with adaptive behaviors, but
most methods require prohibitively large amounts of data for learning a useful
control policy. In this work, we study the integration of robotic reachability
priors in actor-critic RL methods for accelerating the learning of MM for
reaching and fetching tasks. Namely, we consider the problem of optimal base
placement and the subsequent decision of whether to activate the arm for
reaching a 6D target. For this, we devise a novel Hybrid RL method that handles
discrete and continuous actions jointly, resorting to the Gumbel-Softmax
reparameterization. Next, we train a reachability prior using data from the
operational robot workspace, inspired by classical methods. Subsequently, we
derive Boosted Hybrid RL (BHyRL), a novel algorithm for learning Q-functions by
modeling them as a sum of residual approximators. Every time a new task needs
to be learned, we can transfer our learned residuals and learn the component of
the Q-function that is task-specific, hence, maintaining the task structure
from prior behaviors. Moreover, we find that regularizing the target policy
with a prior policy yields more expressive behaviors. We evaluate our method in
simulation in reaching and fetching tasks of increasing difficulty, and we show
the superior performance of BHyRL against baseline methods. Finally, we
zero-transfer our learned 6D fetching policy with BHyRL to our MM robot
TIAGo++. For more details and code release, please refer to our project site:
irosalab.com/rlmmbp

12 Oct 2022
Local motion planning is a heavily researched topic in the field of robotics with many promising algorithms being published every year. However, it is difficult and time-consuming to compare different methods in the field. In this paper, we present localPlannerBench, a new benchmarking suite that allows quick and seamless comparison between local motion planning algorithms. The key focus of the project lies in the extensibility of the environment and the simulation cases. Out-of-the-box, localPlannerBench already supports many simulation cases ranging from a simple 2D point mass to full-fledged 3D 7DoF manipulators, and it is straightforward to add your own custom robot using a URDF file. A post-processor is built-in that can be extended with custom metrics and plots. To integrate your own motion planner, simply create a wrapper that derives from the provided base class. Ultimately we aim to improve the reproducibility of local motion planning algorithms and encourage standardized open-source comparison.

26 Mar 2024
Researchers at Technische Universität Darmstadt and Politecnico di Torino introduce DOmain RAndomization via Entropy MaximizatiON (DORAEMON), an automated method for robust zero-shot sim-to-real transfer in reinforcement learning. It maximizes the diversity (entropy) of simulated dynamics while ensuring a high policy success rate, achieving a 60% zero-shot success rate on a complex robotic manipulation task, outperforming existing automated domain randomization techniques.

18 Aug 2025
Mental health disorders are rising worldwide. However, the availability of trained clinicians has not scaled proportionally, leaving many people without adequate or timely support. To bridge this gap, recent studies have shown the promise of Artificial Intelligence (AI) to assist mental health diagnosis, monitoring, and intervention. However, the development of efficient, reliable, and ethical AI to assist clinicians is heavily dependent on high-quality clinical training datasets. Despite growing interest in data curation for training clinical AI assistants, existing datasets largely remain scattered, under-documented, and often inaccessible, hindering the reproducibility, comparability, and generalizability of AI models developed for clinical mental health care. In this paper, we present the first comprehensive survey of clinical mental health datasets relevant to the training and development of AI-powered clinical assistants. We categorize these datasets by mental disorders (e.g., depression, schizophrenia), data modalities (e.g., text, speech, physiological signals), task types (e.g., diagnosis prediction, symptom severity estimation, intervention generation), accessibility (public, restricted or private), and sociocultural context (e.g., language and cultural background). Along with these, we also investigate synthetic clinical mental health datasets. Our survey identifies critical gaps such as a lack of longitudinal data, limited cultural and linguistic representation, inconsistent collection and annotation standards, and a lack of modalities in synthetic data. We conclude by outlining key challenges in curating and standardizing future datasets and provide actionable recommendations to facilitate the development of more robust, generalizable, and equitable mental health AI systems.

15 Jul 2024
Large language models, comprising billions of parameters and pre-trained on
extensive web-scale corpora, have been claimed to acquire certain capabilities
without having been specifically trained on them. These capabilities, referred
to as "emergent abilities," have been a driving force in discussions regarding
the potentials and risks of language models. A key challenge in evaluating
emergent abilities is that they are confounded by model competencies that arise
through alternative prompting techniques, including in-context learning, which
is the ability of models to complete a task based on a few examples. We present
a novel theory that explains emergent abilities, taking into account their
potential confounding factors, and rigorously substantiate this theory through
over 1000 experiments. Our findings suggest that purported emergent abilities
are not truly emergent, but result from a combination of in-context learning,
model memory, and linguistic knowledge. Our work is a foundational step in
explaining language model performance, providing a template for their efficient
use and clarifying the paradox of their ability to excel in some instances
while faltering in others. Thus, we demonstrate that their capabilities should
not be overestimated.

21 Aug 2024






A comprehensive survey reviews the application of deep generative models (DGMs) in robot learning from multimodal demonstrations, categorizing existing approaches and highlighting strategies to address data complexity and improve generalization. It synthesizes how DGMs enable robots to learn diverse and complex behaviors from real-world data, while also identifying open challenges and future research directions.

18 Jun 2023
Multi-objective optimization problems are ubiquitous in robotics, e.g., the optimization of a robot manipulation task requires a joint consideration of grasp pose configurations, collisions and joint limits. While some demands can be easily hand-designed, e.g., the smoothness of a trajectory, several task-specific objectives need to be learned from data. This work introduces a method for learning data-driven SE(3) cost functions as diffusion models. Diffusion models can represent highly-expressive multimodal distributions and exhibit proper gradients over the entire space due to their score-matching training objective. Learning costs as diffusion models allows their seamless integration with other costs into a single differentiable objective function, enabling joint gradient-based motion optimization. In this work, we focus on learning SE(3) diffusion models for 6DoF grasping, giving rise to a novel framework for joint grasp and motion optimization without needing to decouple grasp selection from trajectory generation. We evaluate the representation power of our SE(3) diffusion models w.r.t. classical generative models, and we showcase the superior performance of our proposed optimization framework in a series of simulated and real-world robotic manipulation tasks against representative baselines.

29 Jan 2025
COS(M+O)S introduces a deliberative framework for creative storytelling that combines Monte Carlo Tree Search with a curiosity-driven value model and ORPO-based policy optimization. This approach enabled a 3B parameter model to generate short stories with quality comparable to a 70B parameter model, demonstrating the effectiveness of iterative search and refinement for creative tasks.

12 Apr 2005
Within the proper-time renormalization group approach, the chiral phase
diagram of a two-flavor quark-meson model is studied. In the chiral limit, the
location of the tricritical point which is linked to a Gaussian fixed point, is
determined. For quark chemical potentials smaller than the tricritical one the
second-order phase transition belongs to the O(4) universality class. For
temperatures below the tricritical one we find initially a weak first-order
phase transition which is commonly seen in model studies and also in recent
lattice simulations. In addition, below temperatures of T <~ 17 MeV we find two
phase transitions. The chiral restoration transition is initially also of
first-order but turns into a second-order transition again. This leads to the
possibility that there may be a "second tricritical" point in the QCD phase
diagram in the chiral limit.

07 Aug 2025

Diffusion-based visuomotor policies excel at learning complex robotic tasks by effectively combining visual data with high-dimensional, multi-modal action distributions. However, diffusion models often suffer from slow inference due to costly denoising processes or require complex sequential training arising from recent distilling approaches. This paper introduces Riemannian Flow Matching Policy (RFMP), a model that inherits the easy training and fast inference capabilities of flow matching (FM). Moreover, RFMP inherently incorporates geometric constraints commonly found in realistic robotic applications, as the robot state resides on a Riemannian manifold. To enhance the robustness of RFMP, we propose Stable RFMP (SRFMP), which leverages LaSalle's invariance principle to equip the dynamics of FM with stability to the support of a target Riemannian distribution. Rigorous evaluation on ten simulated and real-world tasks show that RFMP successfully learns and synthesizes complex sensorimotor policies on Euclidean and Riemannian spaces with efficient training and inference phases, outperforming Diffusion Policies and Consistency Policies.

25 Aug 2025
Mental health disorders create profound personal and societal burdens, yet conventional diagnostics are resource-intensive and limit accessibility. Advances in artificial intelligence, particularly natural language processing and multimodal methods, offer promise for detecting and addressing mental disorders, but raise critical privacy risks. This paper examines these challenges and proposes solutions, including anonymization, synthetic data, and privacy-preserving training, while outlining frameworks for privacy-utility trade-offs, aiming to advance reliable, privacy-aware AI tools that support clinical decision-making and improve mental health outcomes.
There are no more papers matching your filters at the moment.
