
22 Oct 2025

Adaptive Coopetition (AdCo) is a multi-agent LLM reasoning framework that adaptively guides collaboration and competition among agents using coarse verifier signals. AdCo achieves up to 54% accuracy on the DeepMath-103K dataset, representing a 20% relative improvement over baselines, while maintaining high stability and effectively mitigating reasoning collapse.

02 Nov 2025
Retrieval-augmented generation (RAG) has shown impressive capabilities in mitigating hallucinations in large language models (LLMs). However, LLMs struggle to maintain consistent reasoning when exposed to misleading or conflicting evidence, especially in real-world domains such as politics, where information is polarized or selectively framed. Mainstream RAG benchmarks evaluate models under clean retrieval settings, where systems generate answers from gold-standard documents, or under synthetically perturbed settings, where documents are artificially injected with noise. These assumptions fail to reflect real-world conditions, often leading to an overestimation of RAG system performance. To address this gap, we introduce RAGuard, the first benchmark to evaluate the robustness of RAG systems against misleading retrievals. Unlike prior benchmarks that rely on synthetic noise, our fact-checking dataset captures naturally occurring misinformation by constructing its retrieval corpus from Reddit discussions. It categorizes retrieved evidence into three types: supporting, misleading, and unrelated, providing a realistic and challenging testbed for assessing how well RAG systems navigate different types of evidence. Our experiments reveal that, when exposed to potentially misleading retrievals, all tested LLM-powered RAG systems perform worse than their zero-shot baselines (i.e., no retrieval at all), while human annotators consistently perform better, highlighting LLMs' susceptibility to noisy environments. To our knowledge, RAGuard is the first benchmark to systematically assess the robustness of the RAG against misleading evidence. We expect this benchmark to drive future research toward improving RAG systems beyond idealized datasets, making them more reliable for real-world applications. The dataset is available at this https URL.

27 Nov 2024
Embracing AI in Education: Understanding the Surge in Large Language Model Use by Secondary Students
Embracing AI in Education: Understanding the Surge in Large Language Model Use by Secondary Students


This study by researchers from The Harker School, Carnegie Mellon University, and the University of California, Santa Barbara, empirically investigates Large Language Model (LLM) adoption among U.S. secondary school students. It reveals that 71% of secondary students have used LLMs, primarily for academic tasks like writing and math, highlighting consistent usage across grade levels and uncovering concerns regarding educational equity due to access disparities.

30 Jun 2025

SIM-RAG is a framework that enables multi-round Retrieval Augmented Generation (RAG) systems to determine when to stop or continue information retrieval through a novel self-practicing mechanism for synthetic data generation. The system consistently outperforms existing RAG methods on both single-hop and multi-hop question answering benchmarks, leveraging a lightweight external Critic for improved efficiency and accuracy.

06 Jan 2023

Stanford University researchers developed LILAC, a framework enabling robots to adapt to natural language corrections in real-time during task execution, building on the Language-Informed Latent Actions (LILA) framework. This approach achieved a 60% complete task success rate and was preferred by users, demonstrating improved adaptability and sample efficiency with minimal training data.

08 Jul 2025
Precision agriculture relies heavily on accurate image analysis for crop disease identification and treatment recommendation, yet existing vision-language models (VLMs) often underperform in specialized agricultural domains. This work presents a domain-aware framework for agricultural image processing that combines prompt-based expert evaluation with self-consistency mechanisms to enhance VLM reliability in precision agriculture applications. We introduce two key innovations: (1) a prompt-based evaluation protocol that configures a language model as an expert plant pathologist for scalable assessment of image analysis outputs, and (2) a cosine-consistency self-voting mechanism that generates multiple candidate responses from agricultural images and selects the most semantically coherent diagnosis using domain-adapted embeddings. Applied to maize leaf disease identification from field images using a fine-tuned PaliGemma model, our approach improves diagnostic accuracy from 82.2\% to 87.8\%, symptom analysis from 38.9\% to 52.2\%, and treatment recommendation from 27.8\% to 43.3\% compared to standard greedy decoding. The system remains compact enough for deployment on mobile devices, supporting real-time agricultural decision-making in resource-constrained environments. These results demonstrate significant potential for AI-driven precision agriculture tools that can operate reliably in diverse field conditions.

27 Nov 2025

While inference-time thinking allows Large Language Models (LLMs) to address complex problems, the extended thinking process can be unreliable or inconsistent because of the model's probabilistic nature, especially near its knowledge boundaries. Existing approaches attempt to mitigate this by having the model critique its own reasoning to make corrections. However, such self-critique inherits the same biases of the original output, known as the introspection illusion. Moving beyond such introspection and inspired by core methodologies in ethology, we propose an externalist three-step framework Distillation-Reinforcement-Reasoning (DRR). Rather than relying on a model's introspection, DRR evaluates its observable behaviors to provide corrective feedback. DRR first distills the reasoner's behavioral traces, then trains a lightweight, external Discriminative Model (DM). At inference time, this DM acts as a critic, identifying and rejecting suspicious reasoning steps. This external feedback compels the LLM to discard flawed pathways and explore alternatives, thereby enhancing reasoning quality without altering the base model. Experiments on multiple reasoning benchmarks show that our framework significantly outperforms prominent self-critique methods. Benefiting from a lightweight and annotation-free design, DRR offers a scalable and adaptable solution for improving the reliability of reasoning in a wide range of LLMs.
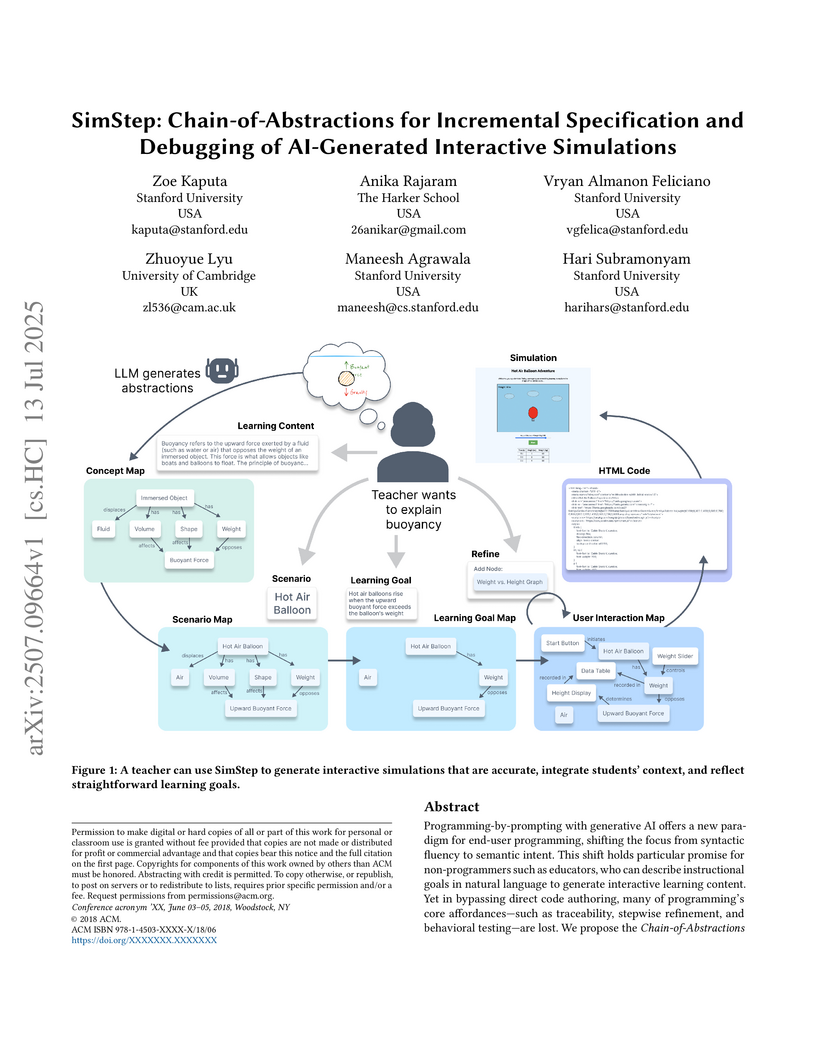
13 Jul 2025

Programming-by-prompting with generative AI offers a new paradigm for end-user programming, shifting the focus from syntactic fluency to semantic intent. This shift holds particular promise for non-programmers such as educators, who can describe instructional goals in natural language to generate interactive learning content. Yet in bypassing direct code authoring, many of programming's core affordances - such as traceability, stepwise refinement, and behavioral testing - are lost. We propose the Chain-of-Abstractions (CoA) framework as a way to recover these affordances while preserving the expressive flexibility of natural language. CoA decomposes the synthesis process into a sequence of cognitively meaningful, task-aligned representations that function as checkpoints for specification, inspection, and refinement. We instantiate this approach in SimStep, an authoring environment for teachers that scaffolds simulation creation through four intermediate abstractions: Concept Graph, Scenario Graph, Learning Goal Graph, and UI Interaction Graph. To address ambiguities and misalignments, SimStep includes an inverse correction process that surfaces in-filled model assumptions and enables targeted revision without requiring users to manipulate code. Evaluations with educators show that CoA enables greater authoring control and interpretability in programming-by-prompting workflows.

18 Aug 2022
Wildfires are increasingly impacting the environment, human health and safety. Among the top 20 California wildfires, those in 2020-2021 burned more acres than the last century combined. California's 2018 wildfire season caused damages of $148.5 billion. Among millions of impacted people, those living with disabilities (around 15% of the world population) are disproportionately impacted due to inadequate means of alerts. In this project, a multi-modal wildfire prediction and personalized early warning system has been developed based on an advanced machine learning architecture. Sensor data from the Environmental Protection Agency and historical wildfire data from 2012 to 2018 have been compiled to establish a comprehensive wildfire database, the largest of its kind. Next, a novel U-Convolutional-LSTM (Long Short-Term Memory) neural network was designed with a special architecture for extracting key spatial and temporal features from contiguous environmental parameters indicative of impending wildfires. Environmental and meteorological factors were incorporated into the database and classified as leading indicators and trailing indicators, correlated to risks of wildfire conception and propagation respectively. Additionally, geological data was used to provide better wildfire risk assessment. This novel spatio-temporal neural network achieved >97% accuracy vs. around 76% using traditional convolutional neural networks, successfully predicting 2018's five most devastating wildfires 5-14 days in advance. Finally, a personalized early warning system, tailored to individuals with sensory disabilities or respiratory exacerbation conditions, was proposed. This technique would enable fire departments to anticipate and prevent wildfires before they strike and provide early warnings for at-risk individuals for better preparation, thereby saving lives and reducing economic damages.

21 Jan 2024

This paper presents GPFC, a novel Graphics Processing Unit (GPU) Phase Folding and Convolutional Neural Network (CNN) system to detect exoplanets using the transit method. We devise a fast folding algorithm parallelized on a GPU to amplify low signal-to-noise ratio transit signals, allowing a search at high precision and speed. A CNN trained on two million synthetic light curves reports a score indicating the likelihood of a planetary signal at each period. While the GPFC method has broad applicability across period ranges, this research specifically focuses on detecting ultra-short-period planets with orbital periods less than one day. GPFC improves on speed by three orders of magnitude over the predominant Box-fitting Least Squares (BLS) method. Our simulation results show GPFC achieves training accuracy, higher true positive rate at the same false positive rate of detection, and higher precision at the same recall rate when compared to BLS. GPFC recovers of known ultra-short-period planets in light curves from a blind search. These results highlight the promise of GPFC as an alternative approach to the traditional BLS algorithm for finding new transiting exoplanets in data taken with and other space transit missions such as K2, TESS and future PLATO and Earth 2.0.

16 Oct 2013


We present spectroscopic metallicities of individual stars in seven gas-rich
dwarf irregular galaxies (dIrrs), and we show that dIrrs obey the same
mass-metallicity relation as the dwarf spheroidal (dSph) satellites of both the
Milky Way and M31: Z_* ~ M_*^(0.30 +/- 0.02). The uniformity of the relation is
in contradiction to previous estimates of metallicity based on photometry. This
relationship is roughly continuous with the stellar mass-stellar metallicity
relation for galaxies as massive as M_* = 10^12 M_sun. Although the average
metallicities of dwarf galaxies depend only on stellar mass, the shapes of
their metallicity distributions depend on galaxy type. The metallicity
distributions of dIrrs resemble simple, leaky box chemical evolution models,
whereas dSphs require an additional parameter, such as gas accretion, to
explain the shapes of their metallicity distributions. Furthermore, the
metallicity distributions of the more luminous dSphs have sharp, metal-rich
cut-offs that are consistent with the sudden truncation of star formation due
to ram pressure stripping.

10 Jan 2024
Effective monitoring of walnut water status and stress level across the whole orchard is an essential step towards precision irrigation management of walnuts, a significant crop in California. This study presents a machine learning approach using Random Forest (RF) models to map stem water potential (SWP) by integrating high-resolution multispectral remote sensing imagery from Unmanned Aerial Vehicle (UAV) flights with weather data. From 2017 to 2018, five flights of an UAV equipped with a seven-band multispectral camera were conducted over a commercial walnut orchard, paired with concurrent ground measurements of sampled walnut plants. The RF regression model, utilizing vegetation indices derived from orthomosaiced UAV imagery and weather data, effectively estimated ground-measured SWPs, achieving an of 0.63 and a mean absolute error (MAE) of 0.80 bars. The integration of weather data was particularly crucial for consolidating data across various flight dates. Significant variables for SWP estimation included wind speed and vegetation indices such as NDVI, NDRE, and PSRI.A reduced RF model excluding red-edge indices of NDRE and PSRI, demonstrated slightly reduced accuracy ( = 0.54). Additionally, the RF classification model predicted water stress levels in walnut trees with 85% accuracy, surpassing the 80% accuracy of the reduced classification model. The results affirm the efficacy of UAV-based multispectral imaging combined with machine learning, incorporating thermal data, NDVI, red-edge indices, and weather data, in walnut water stress estimation and assessment. This methodology offers a scalable, cost-effective tool for data-driven precision irrigation management at an individual plant level in walnut orchards.

14 Sep 2024
Of over 5,000 exoplanets identified so far, only a few hundred possess sub-Earth radii. The formation processes of these sub-Earths remain elusive, and acquiring additional samples is essential for investigating this unique population. In our study, we employ the GPFC method, a novel GPU Phase Folding algorithm combined with a Convolutional Neural Network, on Kepler photometry data. This method enhances the transit search speed significantly over the traditional Box-fitting Least Squares method, allowing a complete search of the known Kepler KOI data within days using a commercial GPU card. To date, we have identified five new ultra-short-period planets (USPs): Kepler-158d, Kepler-963c, Kepler-879c, Kepler-1489c, and KOI-4978.02. Kepler-879c with a radius of completes its orbit around a G dwarf in 0.646716 days. Kepler-158d with a radius of orbits a K dwarf star every 0.645088 days. Kepler-1489c with a radius of orbits a G dwarf in 0.680741 days. Kepler-963c with a radius of revolves around a G dwarf in 0.919783 days, and KOI-4978.02 with a radius of circles a G dwarf in 0.941967 days. Among our findings, Kepler-879c, Kepler-158d and Kepler-963c rank as the first, the third, the fourth smallest USPs identified to date. Notably, Kepler-158d stands as the smallest USP found orbiting K dwarfs while Kepler-963c, Kepler-879c, Kepler-1489c, and KOI-4978.02 are the smallest USPs found orbiting G dwarfs. Kepler-879c, Kepler-158d, Kepler-1489c, and KOI-4978.02 are among the smallest planets that are closest to their host stars, with orbits within 5 stellar radii. In addition, these discoveries highlight GPFC's promising capability in identifying small, new transiting exoplanets within photometry data from Kepler, TESS, and upcoming space transit missions, PLATO and ET.

01 Nov 2024
Code-mixing (CM), where speakers blend languages within a single expression, is prevalent in multilingual societies but poses challenges for natural language processing due to its complexity and limited data. We propose using a large language model to generate synthetic CM data, which is then used to enhance the performance of task-specific models for CM sentiment analysis. Our results show that in Spanish-English, synthetic data improved the F1 score by 9.32%, outperforming previous augmentation techniques. However, in Malayalam-English, synthetic data only helped when the baseline was low; with strong natural data, additional synthetic data offered little benefit. Human evaluation confirmed that this approach is a simple, cost-effective way to generate natural-sounding CM sentences, particularly beneficial for low baselines. Our findings suggest that few-shot prompting of large language models is a promising method for CM data augmentation and has significant impact on improving sentiment analysis, an important element in the development of social influence systems.

06 Aug 2025
As AI advances in text generation, human trust in AI generated content remains constrained by biases that go beyond concerns of accuracy. This study explores how bias shapes the perception of AI versus human generated content. Through three experiments involving text rephrasing, news article summarization, and persuasive writing, we investigated how human raters respond to labeled and unlabeled content. While the raters could not differentiate the two types of texts in the blind test, they overwhelmingly favored content labeled as "Human Generated," over those labeled "AI Generated," by a preference score of over 30%. We observed the same pattern even when the labels were deliberately swapped. This human bias against AI has broader societal and cognitive implications, as it undervalues AI performance. This study highlights the limitations of human judgment in interacting with AI and offers a foundation for improving human-AI collaboration, especially in creative fields.

15 Oct 2025
In this paper, we examine the asymptotic behavior of the longest increasing subsequence (LIS) in a uniformly random permutation of elements. We rely on the Robinson--Schensted--Knuth correspondence, Young tableaux, and key classical results -- including the Erdős--Szekeres theorem and the Hook Length Formula -- to demonstrate that the expected LIS length grows as . We review the essential variational principles of Logan--Shepp and Vershik--Kerov, which determine the limiting shape of the associated random Young diagrams, and summarize the Baik--Deift--Johansson theorem that links fluctuations of the LIS length to the Tracy--Widom distribution. Our approach focuses on providing conceptual and intuitive explanations of these results, unifying classical proofs into a single narrative and supplying fresh visual examples, while referring the reader to the original literature for detailed proofs and rigorous arguments.

09 Feb 2022
The Triangulum Extended (TREX) Survey: The Stellar Disk Dynamics of M33 as a Function of Stellar Age
The Triangulum Extended (TREX) Survey: The Stellar Disk Dynamics of M33 as a Function of Stellar Age






Triangulum, M33, is a low mass, relatively undisturbed spiral galaxy that offers a new regime in which to test models of dynamical heating. In spite of its proximity, the dynamical heating history of M33 has not yet been well constrained. In this work, we present the TREX Survey, the largest stellar spectroscopic survey across the disk of M33. We present the stellar disk kinematics as a function of age to study the past and ongoing dynamical heating of M33. We measure line of sight velocities for ~4,500 disk stars. Using a subset, we divide the stars into broad age bins using Hubble Space Telescope and Canada-France-Hawaii-Telescope photometric catalogs: massive main sequence stars and helium burning stars (~80 Myr), intermediate mass asymptotic branch stars (~1 Gyr), and low mass red giant branch stars (~4 Gyr). We compare the stellar disk dynamics to that of the gas using existing HI, CO, and Halpha kinematics. We find that the disk of M33 has relatively low velocity dispersion (~16 km/s), and unlike in the Milky Way and Andromeda galaxies, there is no strong trend in velocity dispersion as a function of stellar age. The youngest disk stars are as dynamically hot as the oldest disk stars and are dynamically hotter than predicted by most M33 like low mass simulated analogs in Illustris. The velocity dispersion of the young stars is highly structured, with the large velocity dispersion fairly localized. The cause of this high velocity dispersion is not evident from the observations and simulated analogs presented here.

05 Mar 2023
Every year, about 4 million people die from upper respiratory infections. Mask-wearing is crucial in preventing the spread of pathogen-containing droplets, which is the primary cause of these illnesses. However, most techniques for mask efficacy evaluation are expensive to set up and complex to operate. In this work, a novel, low-cost, and quantitative metrology to visualize, track, and analyze orally-generated fluid droplets is developed. The project has four stages: setup optimization, data collection, data analysis, and application development. The metrology was initially developed in a dark closet as a proof of concept using common household materials and was subsequently implemented into a portable apparatus. Tonic water and UV darklight tube lights are selected to visualize fluorescent droplet and aerosol propagation with automated analysis developed using open-source software. The dependencies of oral fluid droplet generation and propagation on various factors are studied in detail and established using this metrology. Additionally, the smallest detectable droplet size was mathematically correlated to height and airborne time. The efficacy of different types of masks is evaluated and associated with fabric microstructures. It is found that masks with smaller-sized pores and thicker material are more effective. This technique can easily be constructed at home using materials that total to a cost of below \$60, thereby enabling a low-cost and accurate metrology.

15 Aug 2017



Over 150,000 new people in the United States are diagnosed with colorectal
cancer each year. Nearly a third die from it (American Cancer Society). The
only approved noninvasive diagnosis tools currently involve fecal blood count
tests (FOBTs) or stool DNA tests. Fecal blood count tests take only five
minutes and are available over the counter for as low as \$15. They are highly
specific, yet not nearly as sensitive, yielding a high percentage (25%) of
false negatives (Colon Cancer Alliance). Moreover, FOBT results are far too
generalized, meaning that a positive result could mean much more than just
colorectal cancer, and could just as easily mean hemorrhoids, anal fissure,
proctitis, Crohn's disease, diverticulosis, ulcerative colitis, rectal ulcer,
rectal prolapse, ischemic colitis, angiodysplasia, rectal trauma, proctitis
from radiation therapy, and others. Stool DNA tests, the modern benchmark for
CRC screening, have a much higher sensitivity and specificity, but also cost
\$600, take two weeks to process, and are not for high-risk individuals or
people with a history of polyps. To yield a cheap and effective CRC screening
alternative, a unique ensemble-based classification algorithm is put in place
that considers the FIT result, BMI, smoking history, and diabetic status of
patients. This method is tested under ten-fold cross validation to have a .95
AUC, 92% specificity, 89% sensitivity, .88 F1, and 90% precision. Once
clinically validated, this test promises to be cheaper, faster, and potentially
more accurate when compared to a stool DNA test.

18 Apr 2022
Seven million people suffer surgical complications each year, but with sufficient surgical training and review, 50\% of these complications could be prevented. To improve surgical performance, existing research uses various deep learning (DL) technologies including convolutional neural networks (CNN) and recurrent neural networks (RNN) to automate surgical tool and workflow detection. However, there is room to improve accuracy; real-time analysis is also minimal due to the complexity of CNN. In this research, a novel DL architecture is proposed to integrate visual simultaneous localization and mapping (vSLAM) into Mask R-CNN. This architecture, vSLAM-CNN (vCNN), for the first time, integrates the best of both worlds, inclusive of (1) vSLAM for object detection, by focusing on geometric information for region proposals, and (2) CNN for object recognition, by focusing on semantic information for image classification, combining them into one joint end-to-end training process. This method, using spatio-temporal information in addition to visual features, is evaluated on M2CAI 2016 challenge datasets, achieving the state-of-the-art results with 96.8 mAP for tool detection and 97.5 mean Jaccard score for workflow detection, surpassing all previous works, and reaching a 50 FPS performance, 10x faster than the region-based CNN. A region proposal module (RPM) replaces the region proposal network (RPN) in Mask R-CNN, accurately placing bounding boxes and lessening the annotation requirement. Furthermore, a Microsoft HoloLens 2 application is developed to provide an augmented reality (AR)-based solution for surgical training and assistance.
There are no more papers matching your filters at the moment.
