
01 Aug 2025



Recently in robotics, Vision-Language-Action (VLA) models have emerged as a transformative approach, enabling robots to execute complex tasks by integrating visual and linguistic inputs within an end-to-end learning framework. Despite their significant capabilities, VLA models introduce new attack surfaces. This paper systematically evaluates their robustness. Recognizing the unique demands of robotic execution, our attack objectives target the inherent spatial and functional characteristics of robotic systems. In particular, we introduce two untargeted attack objectives that leverage spatial foundations to destabilize robotic actions, and a targeted attack objective that manipulates the robotic trajectory. Additionally, we design an adversarial patch generation approach that places a small, colorful patch within the camera's view, effectively executing the attack in both digital and physical environments. Our evaluation reveals a marked degradation in task success rates, with up to a 100\% reduction across a suite of simulated robotic tasks, highlighting critical security gaps in current VLA architectures. By unveiling these vulnerabilities and proposing actionable evaluation metrics, we advance both the understanding and enhancement of safety for VLA-based robotic systems, underscoring the necessity for continuously developing robust defense strategies prior to physical-world deployments.

04 Apr 2017
Leslie N. Smith introduced Cyclical Learning Rates (CLR), a method where the learning rate oscillates between minimum and maximum bounds during neural network training. This approach consistently enhanced convergence speed and accuracy across diverse architectures and datasets, while streamlining the hyperparameter tuning process.

24 Apr 2018
Leslie N. Smith's work at the US Naval Research Laboratory presents a systematic methodology for tuning neural network hyperparameters, enabling significantly faster training times and often achieving equal or superior final accuracies across diverse architectures and datasets. The approach emphasizes observing validation loss for early insights and balancing total regularization.

17 May 2018
Neural networks can achieve "super-convergence," enabling training an order of magnitude faster while often reaching higher test accuracies, by employing aggressive cyclical learning rate schedules and balancing intrinsic regularization from large learning rates with other regularization methods. This approach was demonstrated across various architectures and datasets, significantly reducing training time and improving generalization, especially with limited data.

25 Feb 2025
VeriPlan integrates formal verification with large language models to enable end-users to create reliable plans, addressing LLM inconsistencies and the inaccessibility of traditional planning tools. The system's human-in-the-loop approach, featuring rule translation and flexibility adjustment, improved perceived LLM output quality and user satisfaction in planning tasks.

18 Sep 2025

Accelerating materials development requires quantitative linkages between processing, microstructure, and properties. In this work, we introduce a framework for mapping microstructure onto a low-dimensional material manifold that is parametrized by processing conditions. A key innovation is treating microstructure as a stochastic process, defined as a distribution of microstructural instances rather than a single image, enabling the extraction of material state descriptors that capture the essential process-dependent features. We leverage the manifold hypothesis to assert that microstructural outcomes lie on a low-dimensional latent space controlled by only a few parameters. Using phase-field simulations of spinodal decomposition as a model material system, we compare multiple microstructure descriptors (two-point statistics, chord-length distributions, and persistent homology) in terms of two criteria: (1) intrinsic dimensionality of the latent space, and (2) invertibility of the processing-to-structure mapping. The results demonstrate that distribution-based descriptors can recover a two-dimensional latent structure aligned with the true processing parameters, yielding an invertible and physically interpretable mapping between processing and microstructure. In contrast, descriptors that do not account for microstructure variability either overestimate dimensionality or lose predictive fidelity. The constructed material manifold is shown to be locally continuous, wherein small changes in process variables correspond to smooth changes in microstructure descriptors. This data-driven manifold mapping approach provides a quantitative foundation for microstructure-informed process design and paves the way toward closed-loop optimization of processing--structure--property relationships in an integrated materials engineering context.

21 Sep 2025




Training large language models (LLMs) from scratch can yield models with unique functionalities and strengths, but it is costly and often leads to redundant capabilities. A more cost-effective alternative is to fuse existing pre-trained LLMs with different architectures into a more powerful model. However, a key challenge in existing model fusion is their dependence on manually predefined vocabulary alignment, which may not generalize well across diverse contexts, leading to performance degradation in several evaluation. To solve this, we draw inspiration from distribution learning and propose the probabilistic token alignment method as a general and soft mapping for alignment, named as PTA-LLM. Our approach innovatively reformulates token alignment into a classic mathematical problem: optimal transport, seamlessly leveraging distribution-aware learning to facilitate more coherent model fusion. Apart from its inherent generality, PTA-LLM exhibits interpretability from a distributional perspective, offering insights into the essence of the token alignment. Empirical results demonstrate that probabilistic token alignment enhances the target model's performance across multiple capabilities. Our code is avaliable at this https URL.

26 Sep 2025
Initially identified as a promising altermagnetic (AM) candidate, rutile RuO has since become embroiled in controversy due to contradictory findings of modeling and measurements of the magnetic properties of bulk crystals and thin films. For example, despite observations of a bulk non-magnetic state using density functional theory, neutron scattering, and muon spin resonance measurements, patterned RuO Hall bars and film heterostructures display magnetotransport signatures of magnetic ordering. Among the characteristics routinely cited as evidence for AM is the observation of exchange bias (EB) in an intimately contacted Fe-based ferromagnetic (FM) layer, which can arise due to interfacial coupling with a compensated antiferromagnet. Within this work, the origins of this EB coupling in Ru-capped RuO/Fe bilayers are investigated using polarized neutron diffraction, polarized neutron reflectometry, cross-sectional transmission electron microscopy, and super conducting quantum interference device measurements. These experiments reveal that the EB behavior is driven by the formation of an iron oxide interlayer containing FeO that undergoes a magnetic transition and pins interfacial moments within Fe at low temperature. These findings are confirmed by comparable measurements of Ni-based heterostructures, which do not display EB coupling, as well as magnetometry of additional Fe/Ru bilayers that display oxide-driven EB coupling despite the absence of the epitaxial RuO layer. While these results do not directly refute the possibility of AM ordering in RuO thin films, they reveal that EB, and related magnetotransport phenomena, cannot alone be considered evidence of this characteristic in the rutile structure due to interfacial chemical disorder.

23 Feb 2019
In supervised machine learning, an agent is typically trained once and then deployed. While this works well for static settings, robots often operate in changing environments and must quickly learn new things from data streams. In this paradigm, known as streaming learning, a learner is trained online, in a single pass, from a data stream that cannot be assumed to be independent and identically distributed (iid). Streaming learning will cause conventional deep neural networks (DNNs) to fail for two reasons: 1) they need multiple passes through the entire dataset; and 2) non-iid data will cause catastrophic forgetting. An old fix to both of these issues is rehearsal. To learn a new example, rehearsal mixes it with previous examples, and then this mixture is used to update the DNN. Full rehearsal is slow and memory intensive because it stores all previously observed examples, and its effectiveness for preventing catastrophic forgetting has not been studied in modern DNNs. Here, we describe the ExStream algorithm for memory efficient rehearsal and compare it to alternatives. We find that full rehearsal can eliminate catastrophic forgetting in a variety of streaming learning settings, with ExStream performing well using far less memory and computation.
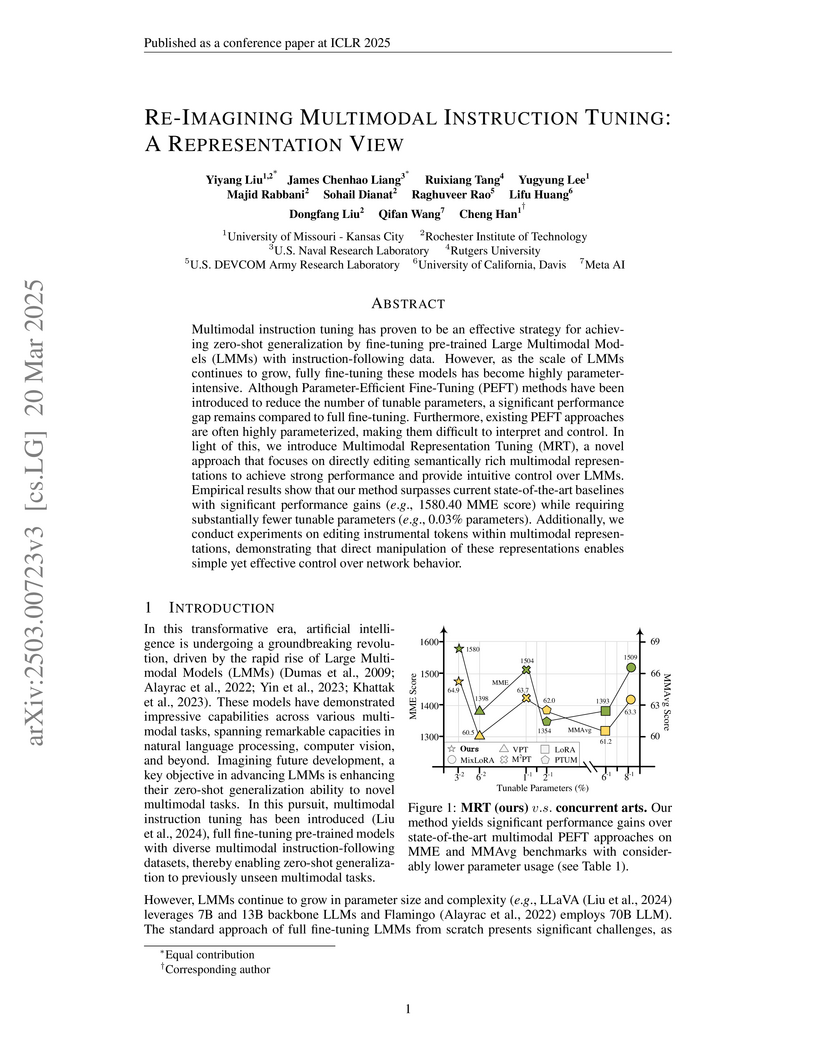
20 Mar 2025

Multimodal instruction tuning has proven to be an effective strategy for
achieving zero-shot generalization by fine-tuning pre-trained Large Multimodal
Models (LMMs) with instruction-following data. However, as the scale of LMMs
continues to grow, fully fine-tuning these models has become highly
parameter-intensive. Although Parameter-Efficient Fine-Tuning (PEFT) methods
have been introduced to reduce the number of tunable parameters, a significant
performance gap remains compared to full fine-tuning. Furthermore, existing
PEFT approaches are often highly parameterized, making them difficult to
interpret and control. In light of this, we introduce Multimodal Representation
Tuning (MRT), a novel approach that focuses on directly editing semantically
rich multimodal representations to achieve strong performance and provide
intuitive control over LMMs. Empirical results show that our method surpasses
current state-of-the-art baselines with significant performance gains (e.g.,
1580.40 MME score) while requiring substantially fewer tunable parameters
(e.g., 0.03% parameters). Additionally, we conduct experiments on editing
instrumental tokens within multimodal representations, demonstrating that
direct manipulation of these representations enables simple yet effective
control over network behavior.

03 Oct 2022

We present an updated model for the extragalactic background light (EBL) from
stars and dust, over wavelengths approximately 0.1 to 1000 m. This model
uses accurate theoretical stellar spectra, and tracks the evolution of star
formation, stellar mass density, metallicity, and interstellar dust extinction
and emission in the universe with redshift. Dust emission components are
treated self-consistently, with stellar light absorbed by dust reradiated in
the infrared as three blackbody components. We fit our model, with free
parameters associated with star formation rate and dust extinction and
emission, to a wide variety of data: luminosity density, stellar mass density,
and dust extinction data from galaxy surveys; and -ray absorption
optical depth data from -ray telescopes. Our results strongly
constraint the star formation rate density and dust photon escape fraction of
the universe out to redshift , about 90% of the history of the universe.
We find our model result is, in some cases, below lower limits on the EBL
intensity, and below some low- -ray absorption measurements.

26 Jun 2025
Herein, we present a polylogarithmic decomposition method to load the matrix from the linearized 1-dimensional Burgers' equation onto a quantum computer. First, we use the Carleman linearization method to map the nonlinear Burgers' equation into an infinite linear system of equations, which is subsequently truncated to order . This new finite linear system is then embedded into a larger system of equations with the key property that its matrix can be decomposed into a linear combination of terms for time steps and spatial grid points. While the terms in this linear combination are not unitary, each is implemented with a simple block encoding and the variational quantuam linear solver (VQLS) routine may be used to obtain a solution. Finally, a complexity analysis of the required VQLS circuits shows that the upper bound of the two-qubit gate depth among all of the block encoded matrices is . This is therefore the first efficient data loading method of a Carleman linearized system.

07 Oct 2025
Dynamic Morphological Component Analysis (DMCA) integrates Dynamic Mode Decomposition (DMD) with Morphological Component Analysis (MCA) to adaptively separate video components based on their distinct dynamic behaviors. The method achieved stable video denoising under complex noise, improved signal-to-noise ratio for faint target detection in sea states, and enhanced signal-to-clutter ratio in ISAR images.

08 Nov 2021
Malicious PDF documents present a serious threat to various security organizations that require modern threat intelligence platforms to effectively analyze and characterize the identity and behavior of PDF malware. State-of-the-art approaches use machine learning (ML) to learn features that characterize PDF malware. However, ML models are often susceptible to evasion attacks, in which an adversary obfuscates the malware code to avoid being detected by an Antivirus. In this paper, we derive a simple yet effective holistic approach to PDF malware detection that leverages signal and statistical analysis of malware binaries. This includes combining orthogonal feature space models from various static and dynamic malware detection methods to enable generalized robustness when faced with code obfuscations. Using a dataset of nearly 30,000 PDF files containing both malware and benign samples, we show that our holistic approach maintains a high detection rate (99.92%) of PDF malware and even detects new malicious files created by simple methods that remove the obfuscation conducted by malware authors to hide their malware, which are undetected by most antiviruses.

12 Oct 2021
Dialogue agents that interact with humans in situated environments need to manage referential ambiguity across multiple modalities and ask for help as needed. However, it is not clear what kinds of questions such agents should ask nor how the answers to such questions can be used to resolve ambiguity. To address this, we analyzed dialogue data from an interactive study in which participants controlled a virtual robot tasked with organizing a set of tools while engaging in dialogue with a live, remote experimenter. We discovered a number of novel results, including the distribution of question types used to resolve ambiguity and the influence of dialogue-level factors on the reference resolution process. Based on these empirical findings we: (1) developed a computational model for clarification requests using a decision network with an entropy-based utility assignment method that operates across modalities, (2) evaluated the model, showing that it outperforms a slot-filling baseline in environments of varying ambiguity, and (3) interpreted the results to offer insight into the ways that agents can ask questions to facilitate situated reference resolution.

12 Aug 2025
The optical properties of defects in solids produce rich physics, from gemstone coloration to single-photon emission for quantum networks. Essential to describing optical transitions is electron-phonon coupling, which can be predicted from first principles but requires computationally expensive evaluation of all phonon modes in simulation cells containing hundreds of atoms. We demonstrate that this bottleneck can be overcome using machine learning interatomic potentials with negligible accuracy loss. A key finding is that atomic relaxation data from routine first-principles calculations suffice as a dataset for fine-tuning, though additional data can further improve models. The efficiency of this approach enables studies of defect vibrational properties with high-level theory. We fine-tune to hybrid functional calculations to obtain highly accurate spectra, comparing with explicit calculations and experiments for various defects. Notably, we resolve fine details of local vibrational mode coupling in the luminescence spectrum of the T center in Si, a prominent quantum defect.

17 May 2018







When a polarized light beam is incident upon the surface of a magnetic material, the reflected light undergoes a polarization rotation. This magneto-optical Kerr effect (MOKE) has been intensively studied in a variety of ferro- and ferrimagnetic materials because it provides a powerful probe for electronic and magnetic properties as well as for various applications including magneto-optical recording. Recently, there has been a surge of interest in antiferromagnets (AFMs) as prospective spintronic materials for high-density and ultrafast memory devices, owing to their vanishingly small stray field and orders of magnitude faster spin dynamics compared to their ferromagnetic counterparts. In fact, the MOKE has proven useful for the study and application of the antiferromagnetic (AF) state. Although limited to insulators, certain types of AFMs are known to exhibit a large MOKE, as they are weak ferromagnets due to canting of the otherwise collinear spin structure. Here we report the first observation of a large MOKE signal in an AF metal at room temperature. In particular, we find that despite a vanishingly small magnetization of 0.002 /Mn, the non-collinear AF metal MnSn exhibits a large zero-field MOKE with a polar Kerr rotation angle of 20 milli-degrees, comparable to ferromagnetic metals. Our first-principles calculations have clarified that ferroic ordering of magnetic octupoles in the non-collinear Neel state may cause a large MOKE even in its fully compensated AF state without spin magnetization. This large MOKE further allows imaging of the magnetic octupole domains and their reversal induced by magnetic field. The observation of a large MOKE in an AF metal should open new avenues for the study of domain dynamics as well as spintronics using AFMs.

18 Jul 2020
Real-world systems in epidemiology, social sciences, power transportation, economics and engineering are often described as multilayer networks. Here we first define and compute the symmetries of multilayer networks, and then study the emergence of cluster synchronization in these networks. We distinguish between independent layer symmetries which occur in one layer and are independent of the other layers and dependent layer symmetries which involve nodes in different layers. We study stability of the cluster synchronous solution by decoupling the problem into a number of independent blocks and assessing stability of each block through a Master Stability Function. We see that blocks associated with dependent layer symmetries have a different structure than the other blocks, which affects the stability of clusters associated with these symmetries. Finally, we validate the theory in a fully analog experiment in which seven electronic oscillators of three kinds are connected with two kinds of coupling.

08 Aug 2024

When researching robot swarms, many studies observe complex group behavior emerging from the individual agents' simple local actions. However, the task of learning an individual policy to produce a desired group behavior remains a challenging problem. We present a method of training distributed robotic swarm algorithms to produce emergent behavior. Inspired by the biological evolution of emergent behavior in animals, we use an evolutionary algorithm to train a population of individual behaviors to produce a desired group behavior. We perform experiments using simulations of the Georgia Tech Miniature Autonomous Blimps (GT-MABs) aerial robotics platforms conducted in the CoppeliaSim simulator. Additionally, we test on simulations of Anki Vector robots to display our algorithm's effectiveness on various modes of actuation. We evaluate our algorithm on various tasks where a somewhat complex group behavior is required for success. These tasks include an Area Coverage task and a Wall Climb task. We compare behaviors evolved using our algorithm against designed policies, which we create in order to exhibit the emergent behaviors we desire.

18 Oct 2023
 Monash UniversityCSIRO
Monash UniversityCSIRO University of Manchester
University of Manchester Beijing Normal UniversityHunan Normal UniversityGuangzhou UniversityUniversity of WarsawCurtin UniversityMacquarie UniversityNational Astronomical ObservatoriesPurple Mountain ObservatorySwinburne University of TechnologyUS Naval Research LaboratoryZhejiang LaboratoryInternational Centre for Radio Astronomy ResearchWestern Sydney UniversityXinjiang Astronomical ObservatoryManly AstrophysicsAuckland University of TechnologyOzGrav
Beijing Normal UniversityHunan Normal UniversityGuangzhou UniversityUniversity of WarsawCurtin UniversityMacquarie UniversityNational Astronomical ObservatoriesPurple Mountain ObservatorySwinburne University of TechnologyUS Naval Research LaboratoryZhejiang LaboratoryInternational Centre for Radio Astronomy ResearchWestern Sydney UniversityXinjiang Astronomical ObservatoryManly AstrophysicsAuckland University of TechnologyOzGravWe present the third data release from the Parkes Pulsar Timing Array (PPTA) project. The release contains observations of 32 pulsars obtained using the 64-m Parkes "Murriyang" radio telescope. The data span is up to 18 years with a typical cadence of 3 weeks. This data release is formed by combining an updated version of our second data release with years of more recent data primarily obtained using an ultra-wide-bandwidth receiver system that operates between 704 and 4032 MHz. We provide calibrated pulse profiles, flux-density dynamic spectra, pulse times of arrival, and initial pulsar timing models. We describe methods for processing such wide-bandwidth observations, and compare this data release with our previous release.
There are no more papers matching your filters at the moment.
