
14 Jun 2024

Researchers from the University of St. Gallen, ICSI, and UC Berkeley introduce SANE (Sequential Autoencoder for Neural Embeddings), a method that scales weight-space learning to large neural networks by processing their weights as sequences, demonstrating its use for both predicting model properties and generating high-performing models with minimal fine-tuning across varying architectures.

02 Oct 2025
Researchers at the AIML Lab, University of St.Gallen, developed a method for learning unified representations directly from highly heterogeneous neural network models available on public hubs like Hugging Face. This approach enabled the generation of functional models across a wide range of architectures, datasets, and even different modalities, frequently surpassing the performance of models initialized from traditional, curated model zoos and improving training efficiency.

14 Apr 2025
This work successfully extends Weight Space Learning (WSL) to operate on heterogeneous populations of neural network models by introducing a masked per-token loss normalization technique within the SANE framework. The approach yielded average performance improvements of 29.65% for zero-shot knowledge transfer on ResNet-18 models, with gains up to 42.8% on out-of-distribution tasks, and provided superior initializations for fine-tuning.

09 Jul 2025
Weakly Supervised Semantic Segmentation (WSSS) is a challenging problem that has been extensively studied in recent years. Traditional approaches often rely on external modules like Class Activation Maps to highlight regions of interest and generate pseudo segmentation masks. In this work, we propose an end-to-end method that directly utilizes the attention maps learned by a Vision Transformer (ViT) for WSSS. We propose training a sparse ViT with multiple [CLS] tokens (one for each class), using a random masking strategy to promote [CLS] token - class assignment. At inference time, we aggregate the different self-attention maps of each [CLS] token corresponding to the predicted labels to generate pseudo segmentation masks. Our proposed approach enhances the interpretability of self-attention maps and ensures accurate class assignments. Extensive experiments on two standard benchmarks and three specialized datasets demonstrate that our method generates accurate pseudo-masks, outperforming related works. Those pseudo-masks can be used to train a segmentation model which achieves results comparable to fully-supervised models, significantly reducing the need for fine-grained labeled data.
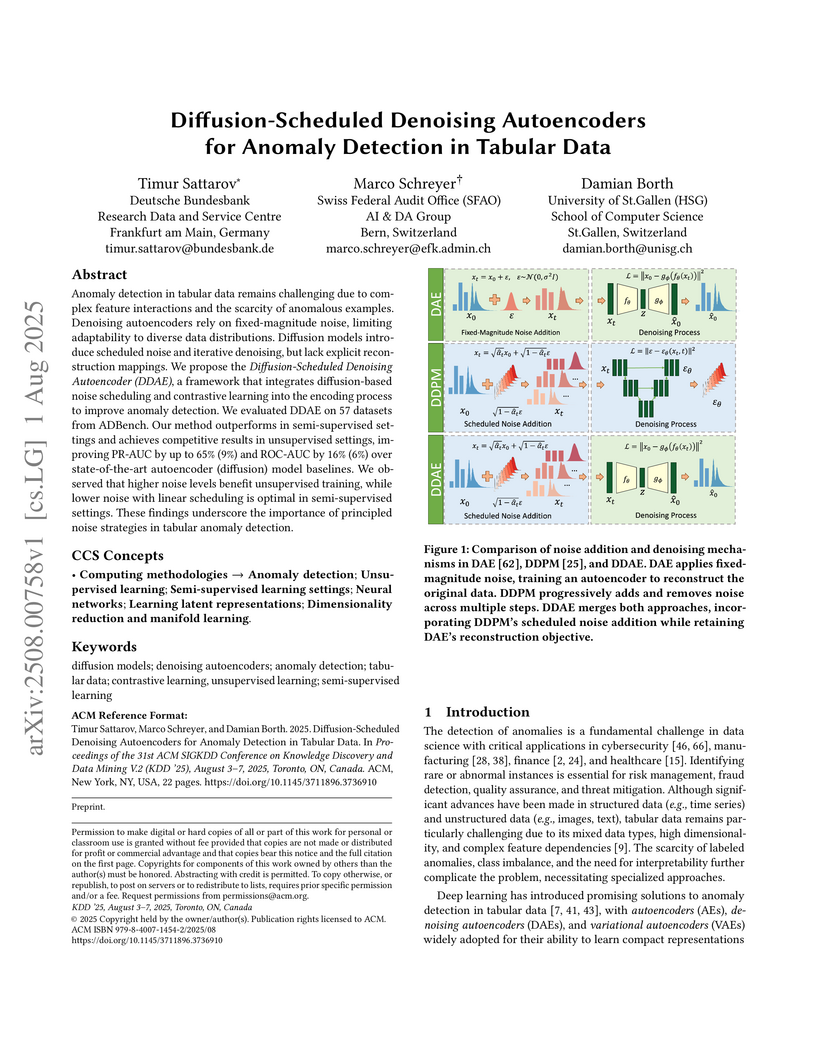
01 Aug 2025
Researchers from Deutsche Bundesbank, Swiss Federal Audit Office, and University of St.Gallen developed Diffusion-Scheduled Denoising Autoencoders (DDAE) and a contrastive variant (DDAE-C) for anomaly detection in tabular data. This framework leverages diffusion model noise scheduling and achieves state-of-the-art results in semi-supervised settings, showing a 65.1% PR-AUC improvement over traditional DAEs in unsupervised anomaly detection on the ADBench benchmark.

29 Sep 2022
Learning representations of neural network weights given a model zoo is an
emerging and challenging area with many potential applications from model
inspection, to neural architecture search or knowledge distillation. Recently,
an autoencoder trained on a model zoo was able to learn a hyper-representation,
which captures intrinsic and extrinsic properties of the models in the zoo. In
this work, we extend hyper-representations for generative use to sample new
model weights. We propose layer-wise loss normalization which we demonstrate is
key to generate high-performing models and several sampling methods based on
the topology of hyper-representations. The models generated using our methods
are diverse, performant and capable to outperform strong baselines as evaluated
on several downstream tasks: initialization, ensemble sampling and transfer
learning. Our results indicate the potential of knowledge aggregation from
model zoos to new models via hyper-representations thereby paving the avenue
for novel research directions.

12 Jun 2024
We investigate the predictive abilities of the heterogeneous autoregressive
(HAR) model compared to machine learning (ML) techniques across an
unprecedented dataset of 1,455 stocks. Our analysis focuses on the role of
fitting schemes, particularly the training window and re-estimation frequency,
in determining the HAR model's performance. Despite extensive hyperparameter
tuning, ML models fail to surpass the linear benchmark set by HAR when
utilizing a refined fitting approach for the latter. Moreover, the simplicity
of HAR allows for an interpretable model with drastically lower computational
costs. We assess performance using QLIKE, MSE, and realized utility metrics,
finding that HAR consistently outperforms its ML counterparts when both rely
solely on realized volatility and VIX as predictors. Our results underscore the
importance of a correctly specified fitting scheme. They suggest that properly
fitted HAR models provide superior forecasting accuracy, establishing robust
guidelines for their practical application and use as a benchmark. This study
not only reaffirms the efficacy of the HAR model but also provides a critical
perspective on the practical limitations of ML approaches in realized
volatility forecasting.

24 Jun 2025


Social media platforms increasingly employ proactive moderation techniques, such as detecting and curbing toxic and uncivil comments, to prevent the spread of harmful content. Despite these efforts, such approaches are often criticized for creating a climate of censorship and failing to address the underlying causes of uncivil behavior. Our work makes both theoretical and practical contributions by proposing and evaluating two types of emotion monitoring dashboards to users' emotional awareness and mitigate hate speech. In a study involving 211 participants, we evaluate the effects of the two mechanisms on user commenting behavior and emotional experiences. The results reveal that these interventions effectively increase users' awareness of their emotional states and reduce hate speech. However, our findings also indicate potential unintended effects, including increased expression of negative emotions (Angry, Fear, and Sad) when discussing sensitive issues. These insights provide a basis for further research on integrating proactive emotion regulation tools into social media platforms to foster healthier digital interactions.

10 Jul 2025
Remote sensing data is commonly used for tasks such as flood mapping, wildfire detection, or land-use studies. For each task, scientists carefully choose appropriate modalities or leverage data from purpose-built instruments. Recent work on remote sensing foundation models pre-trains computer vision models on large amounts of remote sensing data. These large-scale models tend to focus on specific modalities, often optical RGB or multispectral data. For many important applications, this introduces a mismatch between the application modalities and the pre-training data. Moreover, the large size of foundation models makes them expensive and difficult to fine-tune on typically small datasets for each task. We address this mismatch with MAPEX, a remote sensing foundation model based on mixture-of-modality experts. MAPEX is pre-trained on multi-modal remote sensing data with a novel modality-conditioned token routing mechanism that elicits modality-specific experts. To apply the model on a specific task, we propose a modality aware pruning technique, which only retains experts specialized for the task modalities. This yields efficient modality-specific models while simplifying fine-tuning and deployment for the modalities of interest. We experimentally validate MAPEX on diverse remote sensing datasets and show strong performance compared to fully supervised training and state-of-the-art remote sensing foundation models. Code is available at this https URL.

29 Sep 2022
In the last years, neural networks (NN) have evolved from laboratory environments to the state-of-the-art for many real-world problems. It was shown that NN models (i.e., their weights and biases) evolve on unique trajectories in weight space during training. Following, a population of such neural network models (referred to as model zoo) would form structures in weight space. We think that the geometry, curvature and smoothness of these structures contain information about the state of training and can reveal latent properties of individual models. With such model zoos, one could investigate novel approaches for (i) model analysis, (ii) discover unknown learning dynamics, (iii) learn rich representations of such populations, or (iv) exploit the model zoos for generative modelling of NN weights and biases. Unfortunately, the lack of standardized model zoos and available benchmarks significantly increases the friction for further research about populations of NNs. With this work, we publish a novel dataset of model zoos containing systematically generated and diverse populations of NN models for further research. In total the proposed model zoo dataset is based on eight image datasets, consists of 27 model zoos trained with varying hyperparameter combinations and includes 50'360 unique NN models as well as their sparsified twins, resulting in over 3'844'360 collected model states. Additionally, to the model zoo data we provide an in-depth analysis of the zoos and provide benchmarks for multiple downstream tasks. The dataset can be found at this http URL.

07 Oct 2024
Konstantin Schürholt's dissertation introduces "hyper-representations," a self-supervised framework from the University of St.Gallen for learning compact embeddings directly from neural network weights. This method facilitates analysis of trained models and the generation of new functional models, achieving competitive performance for discriminative tasks and outperforming baselines in generative tasks across various architectures.

19 Dec 2024
The banking sector faces challenges in using deep learning due to data sensitivity and regulatory constraints, but generative AI may offer a solution. Thus, this study identifies effective algorithms for generating synthetic financial transaction data and evaluates five leading models - Conditional Tabular Generative Adversarial Networks (CTGAN), DoppelGANger (DGAN), Wasserstein GAN, Financial Diffusion (FinDiff), and Tabular Variational AutoEncoders (TVAE) - across five criteria: fidelity, synthesis quality, efficiency, privacy, and graph structure. While none of the algorithms is able to replicate the real data's graph structure, each excels in specific areas: DGAN is ideal for privacy-sensitive tasks, FinDiff and TVAE excel in data replication and augmentation, and CTGAN achieves a balance across all five criteria, making it suitable for general applications with moderate privacy concerns. As a result, our findings offer valuable insights for choosing the most suitable algorithm.

29 Nov 2025
We introduce DP-FinDiff, a differentially private diffusion framework for synthesizing mixed-type tabular data. DP-FinDiff employs embedding-based representations for categorical features, reducing encoding overhead and scaling to high-dimensional datasets. To adapt DP-training to the diffusion process, we propose two privacy-aware training strategies: an adaptive timestep sampler that aligns updates with diffusion dynamics, and a feature-aggregated loss that mitigates clipping-induced bias. Together, these enhancements improve fidelity and downstream utility without weakening privacy guarantees. On financial and medical datasets, DP-FinDiff achieves 16-42% higher utility than DP baselines at comparable privacy levels, demonstrating its promise for safe and effective data sharing in sensitive domains.

20 Sep 2023
To mitigate climate change, the share of renewable energies in power production needs to be increased. Renewables introduce new challenges to power grids regarding the dynamic stability due to decentralization, reduced inertia, and volatility in production. Since dynamic stability simulations are intractable and exceedingly expensive for large grids, graph neural networks (GNNs) are a promising method to reduce the computational effort of analyzing the dynamic stability of power grids. As a testbed for GNN models, we generate new, large datasets of dynamic stability of synthetic power grids, and provide them as an open-source resource to the research community. We find that GNNs are surprisingly effective at predicting the highly non-linear targets from topological information only. For the first time, performance that is suitable for practical use cases is achieved. Furthermore, we demonstrate the ability of these models to accurately identify particular vulnerable nodes in power grids, so-called troublemakers. Last, we find that GNNs trained on small grids generate accurate predictions on a large synthetic model of the Texan power grid, which illustrates the potential for real-world applications.

25 Sep 2024
TU Dortmund University KU LeuvenGerman Research Center for Artificial Intelligence (DFKI)Gran Sasso Science InstituteUniversity of CamerinoUniversity of BayreuthUniversitat Politécnica de ValénciaUniversity of St.GallenTrier UniversityTUM School of Computation, Information and TechnologyMercadona TechFraunhofer Institute for Applied Information TechnologyOST - Eastern Switzerland University of Applied SciencesRWTH Aachen UniversitySapienza Universit
di Roma
KU LeuvenGerman Research Center for Artificial Intelligence (DFKI)Gran Sasso Science InstituteUniversity of CamerinoUniversity of BayreuthUniversitat Politécnica de ValénciaUniversity of St.GallenTrier UniversityTUM School of Computation, Information and TechnologyMercadona TechFraunhofer Institute for Applied Information TechnologyOST - Eastern Switzerland University of Applied SciencesRWTH Aachen UniversitySapienza Universit
di Roma
KU LeuvenGerman Research Center for Artificial Intelligence (DFKI)Gran Sasso Science InstituteUniversity of CamerinoUniversity of BayreuthUniversitat Politécnica de ValénciaUniversity of St.GallenTrier UniversityTUM School of Computation, Information and TechnologyMercadona TechFraunhofer Institute for Applied Information TechnologyOST - Eastern Switzerland University of Applied SciencesRWTH Aachen UniversitySapienza Universit
di RomaA collaborative research manifesto clarifies the concept of Business Process Digital Twins (BPDTs) as virtual replicas of business processes enabling real-time monitoring, simulation, prediction, and optimization. It outlines a conceptual model for BPDTs and identifies twelve key challenges along with proposed research directions for the field.

28 May 2025

A decision maker typically (i) incorporates training data to learn about the
relative effectiveness of treatments, and (ii) chooses an implementation
mechanism that implies an ``optimal'' predicted outcome distribution according
to some target functional. Nevertheless, a fairness-aware decision maker may
not be satisfied achieving said optimality at the cost of being ``unfair"
against a subgroup of the population, in the sense that the outcome
distribution in that subgroup deviates too strongly from the overall optimal
outcome distribution. We study a framework that allows the decision maker to
regularize such deviations, while allowing for a wide range of target
functionals and fairness measures to be employed. We establish regret and
consistency guarantees for empirical success policies with (possibly)
data-driven preference parameters, and provide numerical results. Furthermore,
we briefly illustrate the methods in two empirical settings.

14 Apr 2025
The availability of large, structured populations of neural networks - called
'model zoos' - has led to the development of a multitude of downstream tasks
ranging from model analysis, to representation learning on model weights or
generative modeling of neural network parameters. However, existing model zoos
are limited in size and architecture and neglect the transformer, which is
among the currently most successful neural network architectures. We address
this gap by introducing the first model zoo of vision transformers (ViT). To
better represent recent training approaches, we develop a new blueprint for
model zoo generation that encompasses both pre-training and fine-tuning steps,
and publish 250 unique models. They are carefully generated with a large span
of generating factors, and their diversity is validated using a thorough choice
of weight-space and behavioral metrics. To further motivate the utility of our
proposed dataset, we suggest multiple possible applications grounded in both
extensive exploratory experiments and a number of examples from the existing
literature. By extending previous lines of similar work, our model zoo allows
researchers to push their model population-based methods from the small model
regime to state-of-the-art architectures. We make our model zoo available at
github.com/ModelZoos/ViTModelZoo.

04 Jun 2024
Decision-making plays a pivotal role in shaping outcomes in various
disciplines, such as medicine, economics, and business. This paper provides
guidance to practitioners on how to implement a decision tree designed to
address treatment assignment policies using an interpretable and non-parametric
algorithm. Our Policy Tree is motivated on the method proposed by Zhou, Athey,
and Wager (2023), distinguishing itself for the policy score calculation,
incorporating constraints, and handling categorical and continuous variables.
We demonstrate the usage of the Policy Tree for multiple, discrete treatments
on data sets from different fields. The Policy Tree is available in Python's
open-source package mcf (Modified Causal Forest).

01 Sep 2025

Every day, millions of people worldwide track their steps, sleep, and activity rhythms with smartwatches and fitness trackers. These continuously collected data streams present a remarkable opportunity to transform routine self-tracking into meaningful health insights that enable individuals to understand -- and potentially influence -- their biological aging. Yet most tools for analyzing wearable data remain fragmented, proprietary, and inaccessible, creating a major barrier between this vast reservoir of personal health information and its translation into actionable insights on aging. CosinorAge is an open-source framework that estimates biological age from wearable-derived circadian, physical activity, and sleep metrics. It addresses the lack of unified, reproducible pipelines for jointly analyzing rest--activity rhythmicity, physical activity, and sleep, and linking them to health outcomes. The Python package provides an end-to-end workflow from raw data ingestion and preprocessing to feature computation and biological age estimation, supporting multiple input sources across wearables and smartwatch. It also makes available trained model parameters (open weights) derived from large-scale population datasets such as UK Biobank, enabling reproducibility, transparency, and generalizability across studies. Its companion web-based CosinorAge Calculator enables non-technical users to access identical analytical capabilities through an intuitive interface. By combining transparent, reproducible analysis with broad accessibility, CosinorAge advances scalable, personalized health monitoring and bridges digital health technologies with biological aging research.

27 Jun 2019
Singular Value Decomposition (SVD) constitutes a bridge between the linear algebra concepts and multi-layer neural networks---it is their linear analogy. Besides of this insight, it can be used as a good initial guess for the network parameters, leading to substantially better optimization results.
There are no more papers matching your filters at the moment.
