
03 Nov 2025


Large Language Models (LLMs) have achieved remarkable progress in reasoning, yet sometimes produce responses that are suboptimal for users in tasks such as writing, information seeking, or providing practical guidance. Conventional alignment practices typically assume that maximizing model reward also maximizes user welfare, but this assumption frequently fails in practice: models may over-clarify or generate overly verbose reasoning when users prefer concise answers. Such behaviors resemble the prisoner's dilemma, where individually rational choices lead to socially suboptimal outcomes. The fundamental challenge is the lack of a principled decision making mechanism that mutually benefits both the LLM and the user. We propose Game-Theoretic Alignment (GTAlign), an alignment framework that integrates game-theoretic decision making into both reasoning and training. During reasoning, the model explicitly treats user-LLM interaction as a strategic game: it constructs payoff matrices within its reasoning chain to estimate welfare for both itself and the user, and then selects actions that are mutually beneficial. During training, we introduce a social welfare reward that reinforces cooperative responses, aligning model behavior with socially efficient outcomes. In addition, we introduce an inference technique that leverages game-theoretic reasoning to dynamically adapt LLM's response when pricing policies of LLM service change. Extensive experiments demonstrate that GTAlign substantially improves reasoning efficiency, answer quality, and social welfare compared to baselines across diverse tasks. The code is available at this https URL .

06 Jun 2025

Mirage is a multi-level superoptimizer for tensor programs, developed at Carnegie Mellon University, that unifies algebraic and schedule transformations across the GPU compute hierarchy to automatically discover and generate custom, high-performance kernels. The system achieved speedups of up to 3.3x on microbenchmarks and reduced end-to-end inference latency by 0.9x to 1.9x for large language models compared to existing methods.

16 Nov 2024

Clover, from Stanford Center for Automated Reasoning and VMware Research, proposes a closed-loop paradigm for verifiable code generation, combining large language models with formal methods to ensure code correctness. It achieves high acceptance for correct programs (87%) and a 100% rejection rate for adversarial incorrect examples by performing six consistency checks across code, formal annotations, and natural language docstrings.

06 Nov 2024
LLMs are widely used in complex AI applications. These applications underscore the need for LLM outputs to adhere to a specific format, for their integration with other components in the systems. Typically the format rules e.g., for data serialization formats such as JSON, YAML, or Code in Programming Language are expressed as context-free grammar (CFG). Due to the hallucinations and unreliability of LLMs, instructing LLMs to adhere to specified syntax becomes an increasingly important challenge.
We present SynCode, a novel framework for efficient and general syntactical decoding with LLMs, to address this challenge. SynCode ensures soundness and completeness with respect to the CFG of a formal language, effectively retaining valid tokens while filtering out invalid ones. SynCode uses an offline-constructed, efficient lookup table, the DFA mask store, derived from the DFA of the language's grammar for efficient generation. SynCode seamlessly integrates with any language defined by CFG, as evidenced by experiments focusing on generating JSON, Python, and Go outputs. Our experiments evaluating the effectiveness of SynCode for JSON generation demonstrate that SynCode eliminates all syntax errors and significantly outperforms state-of-the-art baselines. Furthermore, our results underscore how SynCode significantly reduces 96.07% of syntax errors in generated Python and Go code, showcasing its substantial impact on enhancing syntactical precision in LLM generation. Our code is available at this https URL

17 May 2024
With the recent surge in popularity of LLMs has come an ever-increasing need for LLM safety training. In this paper, we investigate the fragility of SOTA open-source LLMs under simple, optimization-free attacks we refer to as , which are easy to execute and effectively bypass alignment from safety training. Our proposed attack improves the Attack Success Rate on Harmful Behaviors, as measured by Llama Guard, by up to compared to baselines. Source code and data are available at this https URL.

18 May 2025
In this paper, we introduce \textbf{Share}d \textbf{Lo}w \textbf{R}ank
\textbf{A}daptation (ShareLoRA), a Large Language Model (LLM) fine-tuning
technique that balances parameter efficiency, adaptability, and robustness
without compromising performance. By strategically sharing the low-rank weight
matrices across different layers, ShareLoRA achieves 44\% to 96\% reduction in
trainable parameters compared to standard LoRA, alongside a substantial
decrease in memory overhead. This efficiency gain scales with model size,
making ShareLoRA particularly advantageous for resource-constrained
environments. Importantly, ShareLoRA not only maintains model performance but
also exhibits robustness in both classification and generation tasks across
diverse models, including RoBERTa, GPT-2, and LLaMA series (1, 2, and 3). It
consistently outperforms LoRA in zero-shot, few-shot, and continual fine-tuning
scenarios, achieving up to 1.2\% average accuracy improvement, and enhanced
generalization across domains. In continual learning settings, ShareLoRA
achieves 1.2\% higher accuracy on GSM8K, 0.6\% on HumanEval, and 0.5\% on both
MMLU and MMLU-Pro. Our results demonstrate that ShareLoRA supports high-quality
fine-tuning while offering strong generalization and continual adaptation
across various model scales and diverse tasks.

05 Feb 2025



HACK introduces a homomorphic quantization method for disaggregated Large Language Model inference, enabling self-attention computations to be performed directly on 2-bit compressed Key-Value data. This approach effectively eliminates the costly dequantization overhead inherent in prior KV cache compression techniques, resulting in up to 70.9% lower Job Completion Time compared to disaggregated baselines and up to 52.3% lower JCT against existing KV quantization methods, while maintaining competitive accuracy.

25 Apr 2024
The demonstrated code-understanding capability of LLMs raises the question of whether they can be used for automated program verification, a task that demands high-level abstract reasoning about program properties that is challenging for verification tools. We propose a general methodology to combine the power of LLMs and automated reasoners for automated program verification. We formally describe this methodology as a set of transition rules and prove its soundness. We instantiate the calculus as a sound automated verification procedure and demonstrate practical improvements on a set of synthetic and competition benchmarks.
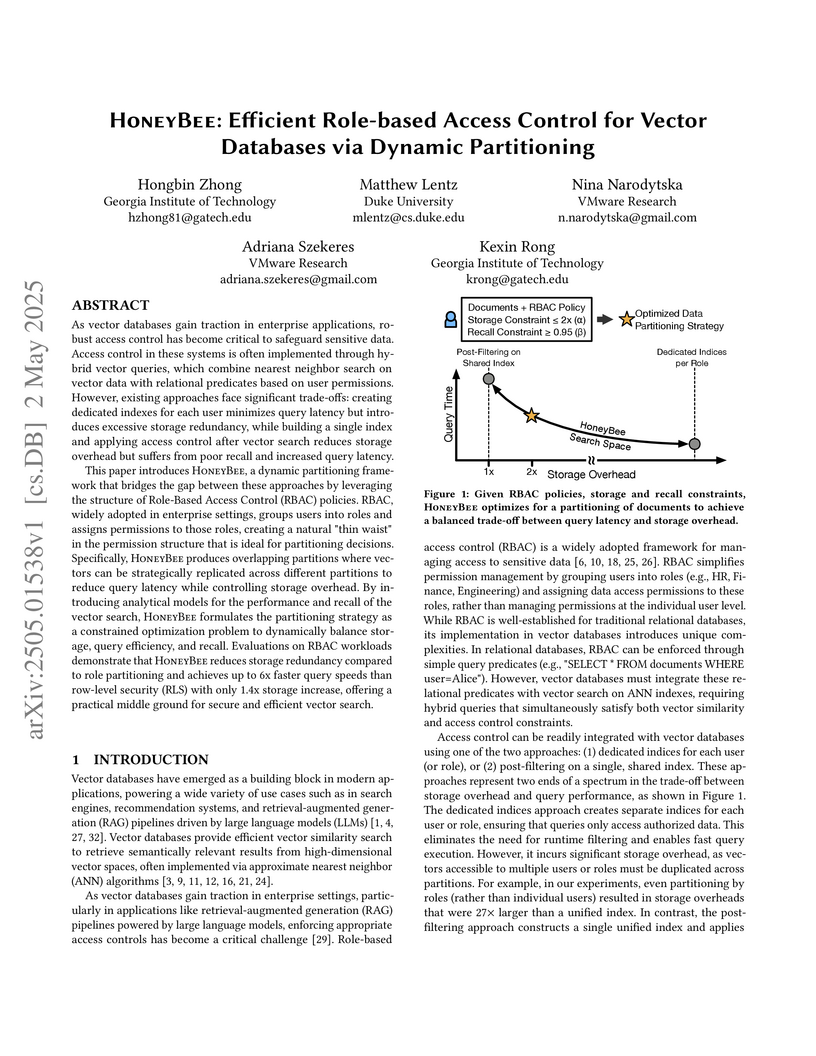
02 May 2025


HoneyBee, developed by researchers from Georgia Institute of Technology, Duke University, and VMware Research, introduces a dynamic partitioning framework for vector databases that implements role-based access control (RBAC) while balancing query performance and storage efficiency. The system achieves up to 6x faster query times compared to row-level security with a storage overhead of approximately 1.4x.

19 Aug 2025
We present the first in depth study on the robustness of existing watermarking techniques applied to code generated by large language models (LLMs). As LLMs increasingly contribute to software development, watermarking has emerged as a potential solution for detecting AI generated code and mitigating misuse, such as plagiarism or the automated generation of malicious programs. While previous research has demonstrated the resilience of watermarking in the text setting, our work reveals that watermarking techniques are significantly more fragile in code-based contexts. Specifically, we show that simple semantic-preserving transformations, such as variable renaming and dead code insertion, can effectively erase watermarks without altering the program's functionality. To systematically evaluate watermark robustness, we develop an algorithm that traverses the Abstract Syntax Tree (AST) of a watermarked program and applies a sequence of randomized, semantics-preserving transformations. Our experimental results, conducted on Python code generated by different LLMs, indicate that even minor modifications can drastically reduce watermark detectability, with true positive rates (TPR) dropping below 50% in many cases. Our code is publicly available at this https URL.

23 Jul 2019
HotStuff introduces a Byzantine fault-tolerant (BFT) consensus protocol that uniquely combines linear communication complexity during leader changes with optimistic responsiveness in a partially synchronous network model. This design enables high-performance and scalable distributed systems, finding application as the core consensus mechanism for Diem (formerly Libra).

21 Apr 2025

Large Language Models (LLMs) can produce biased responses that can cause
representational harms. However, conventional studies are insufficient to
thoroughly evaluate biases across LLM responses for different demographic
groups (a.k.a. counterfactual bias), as they do not scale to large number of
inputs and do not provide guarantees. Therefore, we propose the first
framework, LLMCert-B that certifies LLMs for counterfactual bias on
distributions of prompts. A certificate consists of high-confidence bounds on
the probability of unbiased LLM responses for any set of counterfactual prompts
- prompts differing by demographic groups, sampled from a distribution. We
illustrate counterfactual bias certification for distributions of
counterfactual prompts created by applying prefixes sampled from prefix
distributions, to a given set of prompts. We consider prefix distributions
consisting random token sequences, mixtures of manual jailbreaks, and
perturbations of jailbreaks in LLM's embedding space. We generate non-trivial
certificates for SOTA LLMs, exposing their vulnerabilities over distributions
of prompts generated from computationally inexpensive prefix distributions.

17 Jul 2025


Graph-based nearest neighbor search methods have seen a surge of popularity in recent years, offering state-of-the-art performance across a wide variety of applications. Central to these methods is the task of constructing a sparse navigable search graph for a given dataset endowed with a distance function. Unfortunately, doing so is computationally expensive, so heuristics are universally used in practice.
In this work, we initiate the study of fast algorithms with provable guarantees for search graph construction. For a dataset with data points, the problem of constructing an optimally sparse navigable graph can be framed as separate but highly correlated minimum set cover instances. This yields a naive time greedy algorithm that returns a navigable graph whose sparsity is at most higher than optimal. We improve significantly on this baseline, taking advantage of correlation between the set cover instances to leverage techniques from streaming and sublinear-time set cover algorithms. Combined with problem-specific pre-processing techniques, we present an time algorithm for constructing an -approximate sparsest navigable graph under any distance function.
The runtime of our method is optimal up to logarithmic factors under the Strong Exponential Time Hypothesis via a reduction from Monochromatic Closest Pair. Moreover, we prove that, as with general set cover, obtaining better than an -approximation is NP-hard, despite the significant additional structure present in the navigable graph problem. Finally, we show that our techniques can also beat cubic time for the closely related and practically important problems of constructing -shortcut reachable and -monotonic graphs, which are also used for nearest neighbor search. For such graphs, we obtain time or better algorithms.

15 Jun 2022
Distributed Mean Estimation (DME) is a central building block in federated
learning, where clients send local gradients to a parameter server for
averaging and updating the model. Due to communication constraints, clients
often use lossy compression techniques to compress the gradients, resulting in
estimation inaccuracies.
DME is more challenging when clients have diverse network conditions, such as
constrained communication budgets and packet losses. In such settings, DME
techniques often incur a significant increase in the estimation error leading
to degraded learning performance.
In this work, we propose a robust DME technique named EDEN that naturally
handles heterogeneous communication budgets and packet losses. We derive
appealing theoretical guarantees for EDEN and evaluate it empirically. Our
results demonstrate that EDEN consistently improves over state-of-the-art DME
techniques.

11 Mar 2024

Cross-silo federated learning offers a promising solution to collaboratively train robust and generalized AI models without compromising the privacy of local datasets, e.g., healthcare, financial, as well as scientific projects that lack a centralized data facility. Nonetheless, because of the disparity of computing resources among different clients (i.e., device heterogeneity), synchronous federated learning algorithms suffer from degraded efficiency when waiting for straggler clients. Similarly, asynchronous federated learning algorithms experience degradation in the convergence rate and final model accuracy on non-identically and independently distributed (non-IID) heterogeneous datasets due to stale local models and client drift. To address these limitations in cross-silo federated learning with heterogeneous clients and data, we propose FedCompass, an innovative semi-asynchronous federated learning algorithm with a computing power-aware scheduler on the server side, which adaptively assigns varying amounts of training tasks to different clients using the knowledge of the computing power of individual clients. FedCompass ensures that multiple locally trained models from clients are received almost simultaneously as a group for aggregation, effectively reducing the staleness of local models. At the same time, the overall training process remains asynchronous, eliminating prolonged waiting periods from straggler clients. Using diverse non-IID heterogeneous distributed datasets, we demonstrate that FedCompass achieves faster convergence and higher accuracy than other asynchronous algorithms while remaining more efficient than synchronous algorithms when performing federated learning on heterogeneous clients. The source code for FedCompass is available at this https URL.

11 Sep 2021
Loss minimization is a dominant paradigm in machine learning, where a predictor is trained to minimize some loss function that depends on an uncertain event (e.g., "will it rain tomorrow?''). Different loss functions imply different learning algorithms and, at times, very different predictors. While widespread and appealing, a clear drawback of this approach is that the loss function may not be known at the time of learning, requiring the algorithm to use a best-guess loss function. We suggest a rigorous new paradigm for loss minimization in machine learning where the loss function can be ignored at the time of learning and only be taken into account when deciding an action.
We introduce the notion of an ()-omnipredictor, which could be used to optimize any loss in a family . Once the loss function is set, the outputs of the predictor can be post-processed (a simple univariate data-independent transformation of individual predictions) to do well compared with any hypothesis from the class . The post processing is essentially what one would perform if the outputs of the predictor were true probabilities of the uncertain events. In a sense, omnipredictors extract all the predictive power from the class , irrespective of the loss function in .
We show that such "loss-oblivious'' learning is feasible through a connection to multicalibration, a notion introduced in the context of algorithmic fairness. In addition, we show how multicalibration can be viewed as a solution concept for agnostic boosting, shedding new light on past results. Finally, we transfer our insights back to the context of algorithmic fairness by providing omnipredictors for multi-group loss minimization.

03 May 2025


We present OptiReduce, a new collective-communication system for the cloud with bounded, predictable completion times for deep-learning jobs in the presence of varying computation (stragglers) and communication (congestion and gradient drops) variabilities. OptiReduce exploits the inherent resiliency and the stochastic nature of distributed deep-learning (DDL) training and fine-tuning to work with approximated (or lost) gradients -- providing an efficient balance between (tail) performance and the resulting accuracy of the trained models.
Exploiting this domain-specific characteristic of DDL, OptiReduce introduces (1) mechanisms (e.g., unreliable bounded transport with adaptive timeout) to improve the DDL jobs' tail execution time, and (2) strategies (e.g., Transpose AllReduce and Hadamard Transform) to mitigate the impact of gradient drops on model accuracy. Our evaluation shows that OptiReduce achieves 70% and 30% faster time-to-accuracy (TTA), on average, when operating in shared, cloud environments (e.g., CloudLab) compared to Gloo and NCCL, respectively.

16 May 2024


Adaptive filters, such as telescoping and adaptive cuckoo filters, update their representation upon detecting a false positive to avoid repeating the same error in the future. Adaptive filters require an auxiliary structure, typically much larger than the main filter and often residing on slow storage, to facilitate adaptation. However, existing adaptive filters are not practical and have seen no adoption in real-world systems due to two main reasons. Firstly, they offer weak adaptivity guarantees, meaning that fixing a new false positive can cause a previously fixed false positive to come back. Secondly, the sub-optimal design of the auxiliary structure results in adaptivity overheads so substantial that they can actually diminish the overall system performance compared to a traditional filter.
In this paper, we design and implement AdaptiveQF, the first practical adaptive filter with minimal adaptivity overhead and strong adaptivity guarantees, which means that the performance and false-positive guarantees continue to hold even for adversarial workloads. The AdaptiveQF is based on the state-of-the-art quotient filter design and preserves all the critical features of the quotient filter such as cache efficiency and mergeability. Furthermore, we employ a new auxiliary structure design which results in considerably low adaptivity overhead and makes the AdaptiveQF practical in real systems.

02 Feb 2025
Neural Operators that directly learn mappings between function spaces, such as Deep Operator Networks (DONs) and Fourier Neural Operators (FNOs), have received considerable attention. Despite the universal approximation guarantees for DONs and FNOs, there is currently no optimization convergence guarantee for learning such networks using gradient descent (GD). In this paper, we address this open problem by presenting a unified framework for optimization based on GD and applying it to establish convergence guarantees for both DONs and FNOs. In particular, we show that the losses associated with both of these neural operators satisfy two conditions -- restricted strong convexity (RSC) and smoothness -- that guarantee a decrease on their loss values due to GD. Remarkably, these two conditions are satisfied for each neural operator due to different reasons associated with the architectural differences of the respective models. One takeaway that emerges from the theory is that wider networks should lead to better optimization convergence for both DONs and FNOs. We present empirical results on canonical operator learning problems to support our theoretical results.

17 Jul 2023


Quarl is a reinforcement learning-based quantum circuit optimizer that automatically discovers effective optimization strategies. It achieves superior performance in reducing gate count and circuit depth, and improving fidelity, consistently outperforming existing rule-based and search-based methods, and notably discovering complex transformations like rotation merging.
There are no more papers matching your filters at the moment.
