

17 Jun 2025


Agent Laboratory, an LLM-based framework from AMD and academic partners, automates the scientific research process, notably reducing research costs to $2.33 per paper and enabling state-of-the-art performance in automated machine learning problem-solving. Human involvement in its co-pilot mode improves the overall quality of research outputs.

29 Sep 2025



This paper introduces a systematic framework that enables Large Language Model (LLM) agents to diagnose and recover from their failures by localizing root causes and providing targeted feedback. The approach yielded up to 26% relative improvement in task success rates and significantly enhanced critical error detection across diverse agent benchmarks.

30 May 2025



Masked Autoencoders Are Effective Tokenizers for Diffusion Models (MAETok) introduces an Autoencoder-based tokenizer leveraging mask modeling to learn a highly structured, discriminative latent space. It achieves state-of-the-art image generation with significantly improved training efficiency and inference throughput for high-resolution images, utilizing only 128 tokens.

03 Dec 2025
We report on the first large-scale mixture-of-experts (MoE) pretraining study on pure AMD hardware, utilizing both MI300X GPUs and Pollara networking. We distill practical guidance for both systems and model design. On the systems side, we deliver a comprehensive cluster and networking characterization: microbenchmarks for all core collectives (all-reduce, reduce-scatter, all-gather, broadcast) across message sizes and GPU counts over Pollara. To our knowledge, this is the first at this scale. We further provide MI300X microbenchmarks on kernel sizing and memory bandwidth to inform model design. On the modeling side, we introduce and apply MI300X-aware transformer sizing rules for attention and MLP blocks and justify MoE widths that jointly optimize training throughput and inference latency. We describe our training stack in depth, including often-ignored utilities such as fault-tolerance and checkpoint-reshaping, as well as detailed information on our training recipe. We also provide a preview of our model architecture and base model - ZAYA1 (760M active, 8.3B total parameters MoE, available at this https URL) - which will be further improved upon in forthcoming papers. ZAYA1-base achieves performance comparable to leading base models such as Qwen3-4B and Gemma3-12B at its scale and larger, and outperforms models including Llama-3-8B and OLMoE across reasoning, mathematics, and coding benchmarks. Together, these results demonstrate that the AMD hardware, network, and software stack are mature and optimized enough for competitive large-scale pretraining.

14 Mar 2025
SoftVQ-VAE, developed by researchers from Carnegie Mellon University and AMD, introduces an efficient 1-dimensional continuous tokenizer that utilizes a soft categorical posterior for extreme image compression. This method achieves high-quality reconstruction with as few as 32-64 tokens for high-resolution images, leading to up to 55x higher inference throughput and reduced training costs for Transformer-based generative models while enabling competitive image generation.

19 Oct 2023



This paper introduces Microscaling (MX) data formats, the first open standard for block-level low-precision data types designed for deep learning. It empirically demonstrates that these formats enable efficient sub-8-bit training of large generative language models with minimal accuracy loss and without modifying training recipes, while also providing highly accurate, low-friction inference capabilities for various deep learning tasks.

27 Aug 2025

SwizzlePerf introduces a hardware-aware, LLM-driven framework to automatically generate spatial optimizations like swizzling patterns for GPU kernels on disaggregated architectures, achieving an average 1.29x speedup and up to 70% L2 hit rate improvement by focusing on explicit hardware context and bottleneck metrics.

01 Dec 2025
Recent long-form video-language understanding benchmarks have driven progress in video large multimodal models (Video-LMMs). However, the scarcity of well-annotated long videos has left the training of hour-long Video-LMMs underexplored. To close this gap, we present VideoMarathon, a large-scale hour-long video instruction-following dataset. This dataset includes around 9,700 hours of long videos sourced from diverse domains, ranging from 3 to 60 minutes per video. Specifically, it contains 3.3M high-quality QA pairs, spanning six fundamental topics: temporality, spatiality, object, action, scene, and event. Compared to existing video instruction datasets, VideoMarathon significantly extends training video durations up to 1 hour, and supports 22 diverse tasks requiring both short- and long-term video comprehension. Building on VideoMarathon, we propose Hour-LLaVA, a powerful and efficient Video-LMM for hour-scale video-language modeling. It enables hour-long video training and inference at 1-FPS sampling by leveraging a memory augmentation module, which adaptively integrates question-relevant and spatiotemporally informative semantics from the cached full video context. In our experiments, Hour-LLaVA achieves the best performance on multiple representative long video-language benchmarks, demonstrating the high quality of the VideoMarathon dataset and the superiority of the Hour-LLaVA model.

20 Sep 2024

The increasing demand of machine learning (ML) workloads in datacenters places significant stress on current congestion control (CC) algorithms, many of which struggle to maintain performance at scale. These workloads generate bursty, synchronized traffic that requires both rapid response and fairness across flows. Unfortunately, existing CC algorithms that rely heavily on delay as a primary congestion signal often fail to react quickly enough and do not consistently ensure fairness. In this paper, we propose FASTFLOW, a streamlined sender-based CC algorithm that integrates delay, ECN signals, and optional packet trimming to achieve precise, real-time adjustments to congestion windows. Central to FASTFLOW is the QuickAdapt mechanism, which provides accurate bandwidth estimation at the receiver, enabling faster reactions to network conditions. We also show that FASTFLOW can effectively enhance receiver-based algorithms such as EQDS by improving their ability to manage in-network congestion. Our evaluation reveals that FASTFLOW outperforms cutting-edge solutions, including EQDS, Swift, BBR, and MPRDMA, delivering up to 50% performance improvements in modern datacenter networks.

12 Aug 2025


The recently released Ultra Ethernet (UE) 1.0 specification defines a transformative High-Performance Ethernet standard for future Artificial Intelligence (AI) and High-Performance Computing (HPC) systems. This paper, written by the specification's authors, provides a high-level overview of UE's design, offering crucial motivations and scientific context to understand its innovations. While UE introduces advancements across the entire Ethernet stack, its standout contribution is the novel Ultra Ethernet Transport (UET), a potentially fully hardware-accelerated protocol engineered for reliable, fast, and efficient communication in extreme-scale systems. Unlike InfiniBand, the last major standardization effort in high-performance networking over two decades ago, UE leverages the expansive Ethernet ecosystem and the 1,000x gains in computational efficiency per moved bit to deliver a new era of high-performance networking.

16 Oct 2025



General-purpose compilers abstract away parallelism, locality, and synchronization, limiting their effectiveness on modern spatial architectures. As modern computing architectures increasingly rely on fine-grained control over data movement, execution order, and compute placement for performance, compiler infrastructure must provide explicit mechanisms for orchestrating compute and data to fully exploit such architectures. We introduce MLIR-AIR, a novel, open-source compiler stack built on MLIR that bridges the semantic gap between high-level workloads and fine-grained spatial architectures such as AMD's NPUs. MLIR-AIR defines the AIR dialect, which provides structured representations for asynchronous and hierarchical operations across compute and memory resources. AIR primitives allow the compiler to orchestrate spatial scheduling, distribute computation across hardware regions, and overlap communication with computation without relying on ad hoc runtime coordination or manual scheduling. We demonstrate MLIR-AIR's capabilities through two case studies: matrix multiplication and the multi-head attention block from the LLaMA 2 model. For matrix multiplication, MLIR-AIR achieves up to 78.7% compute efficiency and generates implementations with performance almost identical to state-of-the-art, hand-optimized matrix multiplication written using the lower-level, close-to-metal MLIR-AIE framework. For multi-head attention, we demonstrate that the AIR interface supports fused implementations using approximately 150 lines of code, enabling tractable expression of complex workloads with efficient mapping to spatial hardware. MLIR-AIR transforms high-level structured control flow into spatial programs that efficiently utilize the compute fabric and memory hierarchy of an NPU, leveraging asynchronous execution, tiling, and communication overlap through compiler-managed scheduling.

26 Sep 2025


ZeroTuning is a training-free method that enhances Large Language Model performance by strategically adjusting the attention of the initial token, achieving an average relative improvement of 19.9% on text classification tasks for Llama-3.1-8B-Instruct. This approach leverages a universal, task-agnostic control point to improve accuracy and reduce predictive uncertainty without model retraining.

03 Mar 2025


Recent advancements in timestep-distilled diffusion models have enabled
high-quality image generation that rivals non-distilled multi-step models, but
with significantly fewer inference steps. While such models are attractive for
applications due to the low inference cost and latency, fine-tuning them with a
naive diffusion objective would result in degraded and blurry outputs. An
intuitive alternative is to repeat the diffusion distillation process with a
fine-tuned teacher model, which produces good results but is cumbersome and
computationally intensive; the distillation training usually requires magnitude
higher of training compute compared to fine-tuning for specific image styles.
In this paper, we present an algorithm named pairwise sample optimization
(PSO), which enables the direct fine-tuning of an arbitrary timestep-distilled
diffusion model. PSO introduces additional reference images sampled from the
current time-step distilled model, and increases the relative likelihood margin
between the training images and reference images. This enables the model to
retain its few-step generation ability, while allowing for fine-tuning of its
output distribution. We also demonstrate that PSO is a generalized formulation
which can be flexibly extended to both offline-sampled and online-sampled
pairwise data, covering various popular objectives for diffusion model
preference optimization. We evaluate PSO in both preference optimization and
other fine-tuning tasks, including style transfer and concept customization. We
show that PSO can directly adapt distilled models to human-preferred generation
with both offline and online-generated pairwise preference image data. PSO also
demonstrates effectiveness in style transfer and concept customization by
directly tuning timestep-distilled diffusion models.

28 Aug 2025
The size of a model has been a strong predictor of its quality, as well as its cost. As such, the trade-off between model cost and quality has been well-studied. Post-training optimizations like quantization and pruning have typically focused on reducing the overall volume of pre-trained models to reduce inference costs while maintaining model quality. However, recent advancements have introduced optimization techniques that, interestingly, expand models post-training, increasing model size to improve quality when reducing volume. For instance, to enable 4-bit weight and activation quantization, incoherence processing often necessitates inserting online Hadamard rotations in the compute graph, and preserving highly sensitive weights often calls for additional higher precision computations. However, if application requirements cannot be met, the prevailing solution is to relax quantization constraints. In contrast, we demonstrate post-training model expansion is a viable strategy to improve model quality within a quantization co-design space, and provide theoretical justification. We show it is possible to progressively and selectively expand the size of a pre-trained large language model (LLM) to improve model quality without end-to-end retraining. In particular, when quantizing the weights and activations to 4 bits for Llama3 1B, we reduce the gap to full-precision perplexity by an average of 9% relative to both QuaRot and SpinQuant with only 5% more parameters, which is still a 3.8% reduction in volume relative to a BF16 reference model.
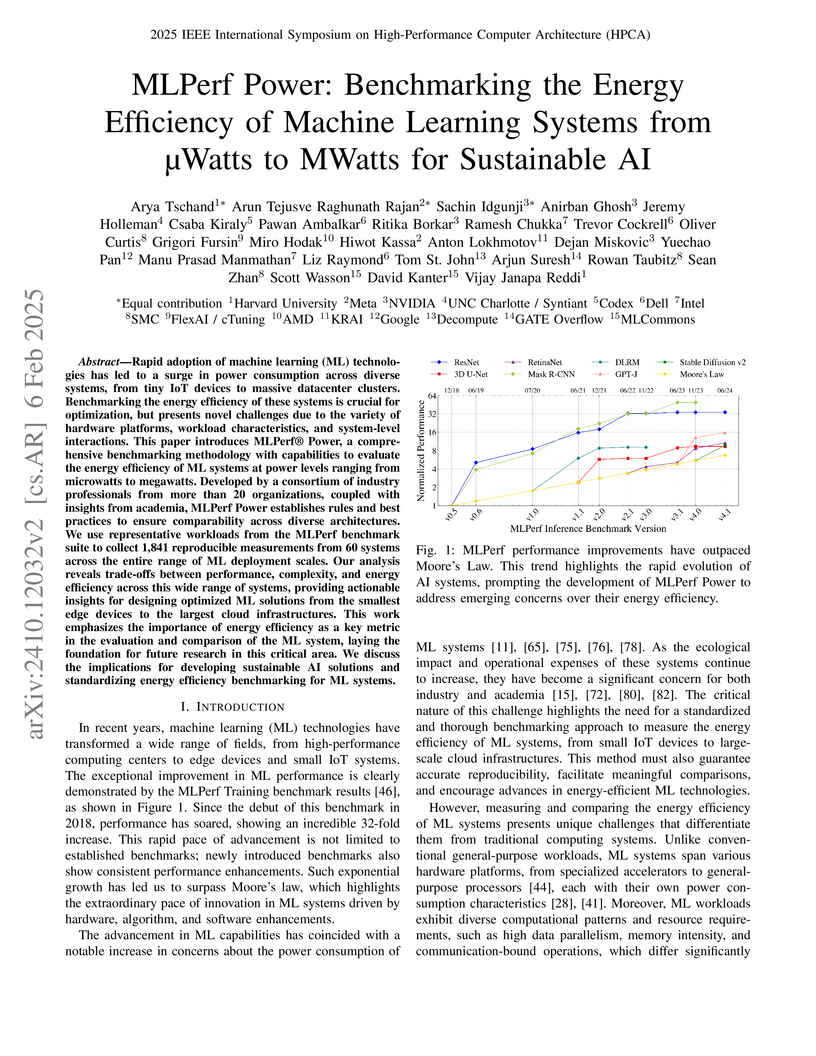
06 Feb 2025

MLPerf Power establishes a standardized, comprehensive benchmarking methodology for measuring the energy efficiency of machine learning systems across an unprecedented range of scales, from microwatts to megawatts. This initiative, developed by the MLCommons consortium, produced a dataset of over 1,800 measurements revealing energy efficiency trends, trade-offs between performance and energy, and the impact of both hardware and software optimizations.

28 May 2025

Answering complex, long-context questions remains a major challenge for large
language models (LLMs) as it requires effective question clarifications and
context retrieval. We propose Agentic Long-Context Understanding (AgenticLU), a
framework designed to enhance an LLM's understanding of such queries by
integrating targeted self-clarification with contextual grounding within an
agentic workflow. At the core of AgenticLU is Chain-of-Clarifications (CoC),
where models refine their understanding through self-generated clarification
questions and corresponding contextual groundings. By scaling inference as a
tree search where each node represents a CoC step, we achieve 97.8% answer
recall on NarrativeQA with a search depth of up to three and a branching factor
of eight. To amortize the high cost of this search process to training, we
leverage the preference pairs for each step obtained by the CoC workflow and
perform two-stage model finetuning: (1) supervised finetuning to learn
effective decomposition strategies, and (2) direct preference optimization to
enhance reasoning quality. This enables AgenticLU models to generate
clarifications and retrieve relevant context effectively and efficiently in a
single inference pass. Extensive experiments across seven long-context tasks
demonstrate that AgenticLU significantly outperforms state-of-the-art prompting
methods and specialized long-context LLMs, achieving robust multi-hop reasoning
while sustaining consistent performance as context length grows.

25 Jun 2025
In recent years, the rapid advancement of deep neural networks (DNNs) has revolutionized artificial intelligence, enabling models with unprecedented capabilities in understanding, generating, and processing complex data. These powerful architectures have transformed a wide range of downstream applications, tackling tasks beyond human reach. In this paper, we introduce Omniwise, the first end-to-end, self-supervised fine-tuning pipeline that applies large language models (LLMs) to GPU kernel performance prediction--a novel use case in performance profiling. Omniwise is model-agnostic and lightweight, achieving strong results even with a small 3B-parameter model. It can predict key performance metrics, including memory bandwidth, cache hit rates, GFLOPs, and arithmetic intensity, directly from kernel code without the need for code execution or profiling tools. Our approach achieves over 90% of predictions within 10% relative error on GPU kernels executed on AMD MI250 and MI300X architectures. In addition to the pipeline, we develop an online inference server and a Visual Studio Code plugin that seamlessly integrate LLM-based performance prediction into developers' workflows.

08 Nov 2024

Online-LoRA is a framework for task-free online continual learning that leverages pre-trained vision transformers and Low-Rank Adaptation to continuously adapt to new data streams. It mitigates catastrophic forgetting by monitoring loss dynamics to trigger incremental LoRA module updates and employs online parameter importance estimation, consistently achieving higher average accuracy and lower forgetting rates on various benchmarks.

01 Oct 2025
The rapid advancement of text-to-image (T2I) models has increased the need for reliable human preference modeling, a demand further amplified by recent progress in reinforcement learning for preference alignment. However, existing approaches typically quantify the quality of a generated image using a single scalar, limiting their ability to provide comprehensive and interpretable feedback on image quality. To address this, we introduce ImageDoctor, a unified multi-aspect T2I model evaluation framework that assesses image quality across four complementary dimensions: plausibility, semantic alignment, aesthetics, and overall quality. ImageDoctor also provides pixel-level flaw indicators in the form of heatmaps, which highlight misaligned or implausible regions, and can be used as a dense reward for T2I model preference alignment. Inspired by the diagnostic process, we improve the detail sensitivity and reasoning capability of ImageDoctor by introducing a "look-think-predict" paradigm, where the model first localizes potential flaws, then generates reasoning, and finally concludes the evaluation with quantitative scores. Built on top of a vision-language model and trained through a combination of supervised fine-tuning and reinforcement learning, ImageDoctor demonstrates strong alignment with human preference across multiple datasets, establishing its effectiveness as an evaluation metric. Furthermore, when used as a reward model for preference tuning, ImageDoctor significantly improves generation quality -- achieving an improvement of 10% over scalar-based reward models.

14 Apr 2025


A compiler-driven optimization framework improves distributed training of large language models through dynamic memory management and coordinated optimizations, achieving up to 1.54x throughput improvement on Mixtral 8x7B MoE model compared to existing fully sharded approaches while maintaining training accuracy.
There are no more papers matching your filters at the moment.
