
21 Jun 2023

In neural decoding research, one of the most intriguing topics is the reconstruction of perceived natural images based on fMRI signals. Previous studies have succeeded in re-creating different aspects of the visuals, such as low-level properties (shape, texture, layout) or high-level features (category of objects, descriptive semantics of scenes) but have typically failed to reconstruct these properties together for complex scene images. Generative AI has recently made a leap forward with latent diffusion models capable of generating high-complexity images. Here, we investigate how to take advantage of this innovative technology for brain decoding. We present a two-stage scene reconstruction framework called ``Brain-Diffuser''. In the first stage, starting from fMRI signals, we reconstruct images that capture low-level properties and overall layout using a VDVAE (Very Deep Variational Autoencoder) model. In the second stage, we use the image-to-image framework of a latent diffusion model (Versatile Diffusion) conditioned on predicted multimodal (text and visual) features, to generate final reconstructed images. On the publicly available Natural Scenes Dataset benchmark, our method outperforms previous models both qualitatively and quantitatively. When applied to synthetic fMRI patterns generated from individual ROI (region-of-interest) masks, our trained model creates compelling ``ROI-optimal'' scenes consistent with neuroscientific knowledge. Thus, the proposed methodology can have an impact on both applied (e.g. brain-computer interface) and fundamental neuroscience.

19 May 2023
Every day, the human brain processes an immense volume of visual information, relying on intricate neural mechanisms to perceive and interpret these stimuli. Recent breakthroughs in functional magnetic resonance imaging (fMRI) have enabled scientists to extract visual information from human brain activity patterns. In this study, we present an innovative method for decoding brain activity into meaningful images and captions, with a specific focus on brain captioning due to its enhanced flexibility as compared to brain decoding into images. Our approach takes advantage of cutting-edge image captioning models and incorporates a unique image reconstruction pipeline that utilizes latent diffusion models and depth estimation. We utilized the Natural Scenes Dataset, a comprehensive fMRI dataset from eight subjects who viewed images from the COCO dataset. We employed the Generative Image-to-text Transformer (GIT) as our backbone for captioning and propose a new image reconstruction pipeline based on latent diffusion models. The method involves training regularized linear regression models between brain activity and extracted features. Additionally, we incorporated depth maps from the ControlNet model to further guide the reconstruction process. We evaluate our methods using quantitative metrics for both generated captions and images. Our brain captioning approach outperforms existing methods, while our image reconstruction pipeline generates plausible images with improved spatial relationships. In conclusion, we demonstrate significant progress in brain decoding, showcasing the enormous potential of integrating vision and language to better understand human cognition. Our approach provides a flexible platform for future research, with potential applications in various fields, including neural art, style transfer, and portable devices.

13 Apr 2022
Over the past few years, the acceleration of computing resources and research
in deep learning has led to significant practical successes in a range of
tasks, including in particular in computer vision. Building on these advances,
reinforcement learning has also seen a leap forward with the emergence of
agents capable of making decisions directly from visual observations. Despite
these successes, the over-parametrization of neural architectures leads to
memorization of the data used during training and thus to a lack of
generalization. Reinforcement learning agents based on visual inputs also
suffer from this phenomenon by erroneously correlating rewards with unrelated
visual features such as background elements. To alleviate this problem, we
introduce a new regularization technique consisting of channel-consistent local
permutations (CLOP) of the feature maps. The proposed permutations induce
robustness to spatial correlations and help prevent overfitting behaviors in
RL. We demonstrate, on the OpenAI Procgen Benchmark, that RL agents trained
with the CLOP method exhibit robustness to visual changes and better
generalization properties than agents trained using other state-of-the-art
regularization techniques. We also demonstrate the effectiveness of CLOP as a
general regularization technique in supervised learning.

11 May 2023
Recent works indicate that convolutional neural networks (CNN) need large receptive fields (RF) to compete with visual transformers and their attention mechanism. In CNNs, RFs can simply be enlarged by increasing the convolution kernel sizes. Yet the number of trainable parameters, which scales quadratically with the kernel's size in the 2D case, rapidly becomes prohibitive, and the training is notoriously difficult. This paper presents a new method to increase the RF size without increasing the number of parameters. The dilated convolution (DC) has already been proposed for the same purpose. DC can be seen as a convolution with a kernel that contains only a few non-zero elements placed on a regular grid. Here we present a new version of the DC in which the spacings between the non-zero elements, or equivalently their positions, are no longer fixed but learnable via backpropagation thanks to an interpolation technique. We call this method "Dilated Convolution with Learnable Spacings" (DCLS) and generalize it to the n-dimensional convolution case. However, our main focus here will be on the 2D case. We first tried our approach on ResNet50: we drop-in replaced the standard convolutions with DCLS ones, which increased the accuracy of ImageNet1k classification at iso-parameters, but at the expense of the throughput. Next, we used the recent ConvNeXt state-of-the-art convolutional architecture and drop-in replaced the depthwise convolutions with DCLS ones. This not only increased the accuracy of ImageNet1k classification but also of typical downstream and robustness tasks, again at iso-parameters but this time with negligible cost on throughput, as ConvNeXt uses separable convolutions. Conversely, classic DC led to poor performance with both ResNet50 and ConvNeXt. The code of the method is available at: this https URL.

03 Feb 2025




This thesis explores advanced approaches to improve explainability in computer vision by analyzing and modeling the features exploited by deep neural networks. Initially, it evaluates attribution methods, notably saliency maps, by introducing a metric based on algorithmic stability and an approach utilizing Sobol indices, which, through quasi-Monte Carlo sequences, allows a significant reduction in computation time. In addition, the EVA method offers a first formulation of attribution with formal guarantees via verified perturbation analysis.
Experimental results indicate that in complex scenarios these methods do not provide sufficient understanding, particularly because they identify only "where" the model focuses without clarifying "what" it perceives. Two hypotheses are therefore examined: aligning models with human reasoning -- through the introduction of a training routine that integrates the imitation of human explanations and optimization within the space of 1-Lipschitz functions -- and adopting a conceptual explainability approach.
The CRAFT method is proposed to automate the extraction of the concepts used by the model and to assess their importance, complemented by MACO, which enables their visualization. These works converge towards a unified framework, illustrated by an interactive demonstration applied to the 1000 ImageNet classes in a ResNet model.

04 Jun 2025
Concept-based explanations work by mapping complex model computations to
human-understandable concepts. Evaluating such explanations is very difficult,
as it includes not only the quality of the induced space of possible concepts
but also how effectively the chosen concepts are communicated to users.
Existing evaluation metrics often focus solely on the former, neglecting the
latter. We introduce an evaluation framework for measuring concept explanations
via automated simulatability: a simulator's ability to predict the explained
model's outputs based on the provided explanations. This approach accounts for
both the concept space and its interpretation in an end-to-end evaluation.
Human studies for simulatability are notoriously difficult to enact,
particularly at the scale of a wide, comprehensive empirical evaluation (which
is the subject of this work). We propose using large language models (LLMs) as
simulators to approximate the evaluation and report various analyses to make
such approximations reliable. Our method allows for scalable and consistent
evaluation across various models and datasets. We report a comprehensive
empirical evaluation using this framework and show that LLMs provide consistent
rankings of explanation methods. Code available at
this https URL

28 Jul 2025
In recent years, Transformer architectures have revolutionized most fields of artificial intelligence, relying on an attentional mechanism based on the agreement between keys and queries to select and route information in the network. In previous work, we introduced a novel, brain-inspired architecture that leverages a similar implementation to achieve a global 'routing by agreement' mechanism. Such a system modulates the network's activity by matching each neuron's key with a single global query, pooled across the entire network. Acting as a global attentional system, this mechanism improves noise robustness over baseline levels but is insufficient for multi-classification tasks. Here, we improve on this work by proposing a novel mechanism that combines aspects of the Transformer attentional operations with a compelling neuroscience theory, namely, binding by synchrony. This theory proposes that the brain binds together features by synchronizing the temporal activity of neurons encoding those features. This allows the binding of features from the same object while efficiently disentangling those from distinct objects. We drew inspiration from this theory and incorporated angular phases into all layers of a convolutional network. After achieving phase alignment via Kuramoto dynamics, we use this approach to enhance operations between neurons with similar phases and suppresses those with opposite phases. We test the benefits of this mechanism on two datasets: one composed of pairs of digits and one composed of a combination of an MNIST item superimposed on a CIFAR-10 image. Our results reveal better accuracy than CNN networks, proving more robust to noise and with better generalization abilities. Overall, we propose a novel mechanism that addresses the visual binding problem in neural networks by leveraging the synergy between neuroscience and machine learning.

21 Jul 2022

Depression is a serious mental illness that impacts the way people
communicate, especially through their emotions, and, allegedly, the way they
interact with others. This work examines depression signals in dialogs, a less
studied setting that suffers from data sparsity. We hypothesize that depression
and emotion can inform each other, and we propose to explore the influence of
dialog structure through topic and dialog act prediction. We investigate a
Multi-Task Learning (MTL) approach, where all tasks mentioned above are learned
jointly with dialog-tailored hierarchical modeling. We experiment on the DAIC
and DailyDialog corpora-both contain dialogs in English-and show important
improvements over state-ofthe-art on depression detection (at best 70.6% F 1),
which demonstrates the correlation of depression with emotion and dialog
organization and the power of MTL to leverage information from different
sources.

15 Jul 2025
Within a legal framework, fairness in datasets and models is typically assessed by dividing observations into predefined groups and then computing fairness measures (e.g., Disparate Impact or Equality of Odds with respect to gender). However, when sensitive attributes such as skin color are continuous, dividing into default groups may overlook or obscure the discrimination experienced by certain minority subpopulations. To address this limitation, we propose a fairness-based grouping approach for continuous (possibly multidimensional) sensitive attributes. By grouping data according to observed levels of discrimination, our method identifies the partition that maximizes a novel criterion based on inter-group variance in discrimination, thereby isolating the most critical subgroups.
We validate the proposed approach using multiple synthetic datasets and demonstrate its robustness under changing population distributions - revealing how discrimination is manifested within the space of sensitive attributes. Furthermore, we examine a specialized setting of monotonic fairness for the case of skin color. Our empirical results on both CelebA and FFHQ, leveraging the skin tone as predicted by an industrial proprietary algorithm, show that the proposed segmentation uncovers more nuanced patterns of discrimination than previously reported, and that these findings remain stable across datasets for a given model. Finally, we leverage our grouping model for debiasing purpose, aiming at predicting fair scores with group-by-group post-processing. The results demonstrate that our approach improves fairness while having minimal impact on accuracy, thus confirming our partition method and opening the door for industrial deployment.

16 Jun 2021
Modern feedforward convolutional neural networks (CNNs) can now solve some computer vision tasks at super-human levels. However, these networks only roughly mimic human visual perception. One difference from human vision is that they do not appear to perceive illusory contours (e.g. Kanizsa squares) in the same way humans do. Physiological evidence from visual cortex suggests that the perception of illusory contours could involve feedback connections. Would recurrent feedback neural networks perceive illusory contours like humans? In this work we equip a deep feedforward convolutional network with brain-inspired recurrent dynamics. The network was first pretrained with an unsupervised reconstruction objective on a natural image dataset, to expose it to natural object contour statistics. Then, a classification decision layer was added and the model was finetuned on a form discrimination task: squares vs. randomly oriented inducer shapes (no illusory contour). Finally, the model was tested with the unfamiliar ''illusory contour'' configuration: inducer shapes oriented to form an illusory square. Compared with feedforward baselines, the iterative ''predictive coding'' feedback resulted in more illusory contours being classified as physical squares. The perception of the illusory contour was measurable in the luminance profile of the image reconstructions produced by the model, demonstrating that the model really ''sees'' the illusion. Ablation studies revealed that natural image pretraining and feedback error correction are both critical to the perception of the illusion. Finally we validated our conclusions in a deeper network (VGG): adding the same predictive coding feedback dynamics again leads to the perception of illusory contours.

03 Feb 2021

Machine learning (ML) is ubiquitous in modern life. Since it is being
deployed in technologies that affect our privacy and safety, it is often
crucial to understand the reasoning behind its decisions, warranting the need
for explainable AI. Rule-based models, such as decision trees, decision lists,
and decision sets, are conventionally deemed to be the most interpretable.
Recent work uses propositional satisfiability (SAT) solving (and its
optimization variants) to generate minimum-size decision sets. Motivated by
limited practical scalability of these earlier methods, this paper proposes a
novel approach to learn minimum-size decision sets by enumerating individual
rules of the target decision set independently of each other, and then solving
a set cover problem to select a subset of rules. The approach makes use of
modern maximum satisfiability and integer linear programming technologies.
Experiments on a wide range of publicly available datasets demonstrate the
advantage of the new approach over the state of the art in SAT-based decision
set learning.

08 Jun 2021
Brain-inspired machine learning is gaining increasing consideration, particularly in computer vision. Several studies investigated the inclusion of top-down feedback connections in convolutional networks; however, it remains unclear how and when these connections are functionally helpful. Here we address this question in the context of object recognition under noisy conditions. We consider deep convolutional networks (CNNs) as models of feed-forward visual processing and implement Predictive Coding (PC) dynamics through feedback connections (predictive feedback) trained for reconstruction or classification of clean images. To directly assess the computational role of predictive feedback in various experimental situations, we optimize and interpret the hyper-parameters controlling the network's recurrent dynamics. That is, we let the optimization process determine whether top-down connections and predictive coding dynamics are functionally beneficial. Across different model depths and architectures (3-layer CNN, ResNet18, and EfficientNetB0) and against various types of noise (CIFAR100-C), we find that the network increasingly relies on top-down predictions as the noise level increases; in deeper networks, this effect is most prominent at lower layers. In addition, the accuracy of the network implementing PC dynamics significantly increases over time-steps, compared to its equivalent forward network. All in all, our results provide novel insights relevant to Neuroscience by confirming the computational role of feedback connections in sensory systems, and to Machine Learning by revealing how these can improve the robustness of current vision models.

04 Nov 2021
Deep neural networks excel at image classification, but their performance is
far less robust to input perturbations than human perception. In this work we
explore whether this shortcoming may be partly addressed by incorporating
brain-inspired recurrent dynamics in deep convolutional networks. We take
inspiration from a popular framework in neuroscience: 'predictive coding'. At
each layer of the hierarchical model, generative feedback 'predicts' (i.e.,
reconstructs) the pattern of activity in the previous layer. The reconstruction
errors are used to iteratively update the network's representations across
timesteps, and to optimize the network's feedback weights over the natural
image dataset-a form of unsupervised training. We show that implementing this
strategy into two popular networks, VGG16 and EfficientNetB0, improves their
robustness against various corruptions and adversarial attacks. We hypothesize
that other feedforward networks could similarly benefit from the proposed
framework. To promote research in this direction, we provide an open-sourced
PyTorch-based package called Predify, which can be used to implement and
investigate the impacts of the predictive coding dynamics in any convolutional
neural network.

17 Oct 2022
Lipschitz constrained networks have gathered considerable attention in the deep learning community, with usages ranging from Wasserstein distance estimation to the training of certifiably robust classifiers. However they remain commonly considered as less accurate, and their properties in learning are still not fully understood. In this paper we clarify the matter: when it comes to classification 1-Lipschitz neural networks enjoy several advantages over their unconstrained counterpart. First, we show that these networks are as accurate as classical ones, and can fit arbitrarily difficult boundaries. Then, relying on a robustness metric that reflects operational needs we characterize the most robust classifier: the WGAN discriminator. Next, we show that 1-Lipschitz neural networks generalize well under milder assumptions. Finally, we show that hyper-parameters of the loss are crucial for controlling the accuracy-robustness trade-off. We conclude that they exhibit appealing properties to pave the way toward provably accurate, and provably robust neural networks.

12 Jun 2023

Value chain data is crucial to navigate economic disruptions, such as those caused by the COVID-19 pandemic and the war in Ukraine. Yet, despite its importance, publicly available value chain datasets, such as the ``World Input-Output Database'', ``Inter-Country Input-Output Tables'', ``EXIOBASE'' or the ``EORA'', lack detailed information about products (e.g. Radio Receivers, Telephones, Electrical Capacitors, LCDs, etc.) and rely instead on more aggregate industrial sectors (e.g. Electrical Equipment, Telecommunications). Here, we introduce a method based on machine learning and trade theory to infer product-level value chain relationships from fine-grained international trade data. We apply our method to data summarizing the exports and imports of 300+ world regions (e.g. states in the U.S., prefectures in Japan, etc.) and 1200+ products to infer value chain information implicit in their trade patterns. Furthermore, we use proportional allocation to assign the trade flow between regions and countries. This work provides an approximate method to map value chain data at the product level with a relevant trade flow, that should be of interest to people working in logistics, trade, and sustainable development.

28 Jun 2023

We investigate the role of attention and memory in complex reasoning tasks.
We analyze Transformer-based self-attention as a model and extend it with
memory. By studying a synthetic visual reasoning test, we refine the taxonomy
of reasoning tasks. Incorporating self-attention with ResNet50, we enhance
feature maps using feature-based and spatial attention, achieving efficient
solving of challenging visual reasoning tasks. Our findings contribute to
understanding the attentional needs of SVRT tasks. Additionally, we propose
GAMR, a cognitive architecture combining attention and memory, inspired by
active vision theory. GAMR outperforms other architectures in sample
efficiency, robustness, and compositionality, and shows zero-shot
generalization on new reasoning tasks.

07 Apr 2025
Robotic designs played an important role in recent advances by providing
powerful robots with complex mechanics. Many recent systems rely on parallel
actuation to provide lighter limbs and allow more complex motion. However,
these emerging architectures fall outside the scope of most used description
formats, leading to difficulties when designing, storing, and sharing the
models of these systems. This paper introduces an extension to the widely used
Unified Robot Description Format (URDF) to support closed-loop kinematic
structures. Our approach relies on augmenting URDF with minimal additional
information to allow more efficient modeling of complex robotic systems while
maintaining compatibility with existing design and simulation frameworks. This
method sets the basic requirement for a description format to handle parallel
mechanisms efficiently. We demonstrate the applicability of our approach by
providing an open-source collection of parallel robots, along with tools for
generating and parsing this extended description format. The proposed extension
simplifies robot modeling, reduces redundancy, and improves usability for
advanced robotic applications.

04 May 2022
An adaptive regularization algorithm for unconstrained nonconvex optimization is presented in which the objective function is never evaluated, but only derivatives are used. This algorithm belongs to the class of adaptive regularization methods, for which optimal worst-case complexity results are known for the standard framework where the objective function is evaluated. It is shown in this paper that these excellent complexity bounds are also valid for the new algorithm, despite the fact that significantly less information is used. In particular, it is shown that, if derivatives of degree one to are used, the algorithm will find a -approximate first-order minimizer in at most iterations, and an -approximate second-order minimizer in at most iterations. As a special case, the new algorithm using first and second derivatives, when applied to functions with Lipschitz continuous Hessian, will find an iterate at which the gradient's norm is less than in at most iterations.

04 Nov 2020
Recent work proposed the computation of so-called PI-explanations of Naive
Bayes Classifiers (NBCs). PI-explanations are subset-minimal sets of
feature-value pairs that are sufficient for the prediction, and have been
computed with state-of-the-art exact algorithms that are worst-case exponential
in time and space. In contrast, we show that the computation of one
PI-explanation for an NBC can be achieved in log-linear time, and that the same
result also applies to the more general class of linear classifiers.
Furthermore, we show that the enumeration of PI-explanations can be obtained
with polynomial delay. Experimental results demonstrate the performance gains
of the new algorithms when compared with earlier work. The experimental results
also investigate ways to measure the quality of heuristic explanations
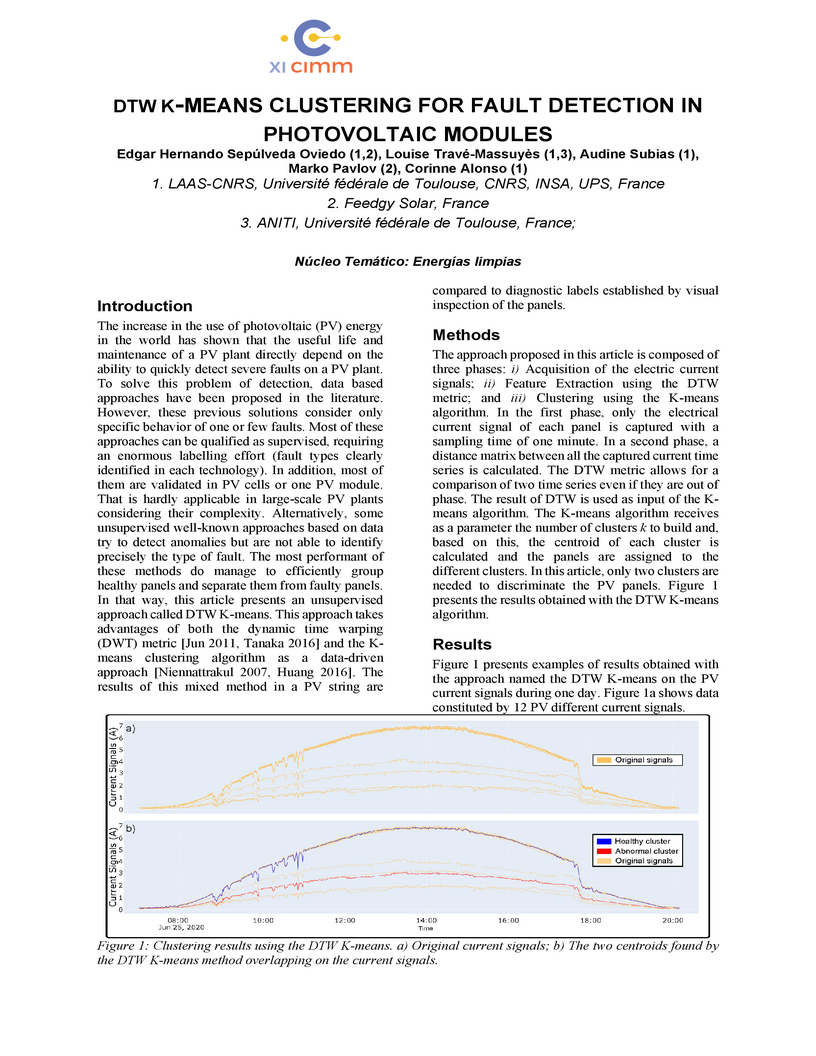
13 Jun 2023
The increase in the use of photovoltaic (PV) energy in the world has shown
that the useful life and maintenance of a PV plant directly depend on
theability to quickly detect severe faults on a PV plant. To solve this problem
of detection, data based approaches have been proposed in the
literature.However, these previous solutions consider only specific behavior of
one or few faults. Most of these approaches can be qualified as supervised,
requiring an enormous labelling effort (fault types clearly identified in each
technology). In addition, most of them are validated in PV cells or one PV
module. That is hardly applicable in large-scale PV plants considering their
complexity. Alternatively, some unsupervised well-known approaches based on
data try to detect anomalies but are not able to identify precisely the type of
fault. The most performant of these methods do manage to efficiently group
healthy panels and separate them from faulty panels. In that way, this article
presents an unsupervised approach called DTW K-means. This approach takes
advantages of both the dynamic time warping (DWT) metric and the Kmeans
clustering algorithm as a data-driven approach. The results of this mixed
method in a PV string are compared to diagnostic labels established by visual
inspection of the panels.
There are no more papers matching your filters at the moment.
