
03 Jun 2020

Understanding emotion expressed in language has a wide range of applications, from building empathetic chatbots to detecting harmful online behavior. Advancement in this area can be improved using large-scale datasets with a fine-grained typology, adaptable to multiple downstream tasks. We introduce GoEmotions, the largest manually annotated dataset of 58k English Reddit comments, labeled for 27 emotion categories or Neutral. We demonstrate the high quality of the annotations via Principal Preserved Component Analysis. We conduct transfer learning experiments with existing emotion benchmarks to show that our dataset generalizes well to other domains and different emotion taxonomies. Our BERT-based model achieves an average F1-score of .46 across our proposed taxonomy, leaving much room for improvement.

19 May 2024

MAML-en-LLM adapts the Model-Agnostic Meta-Learning (MAML) framework to large language models, training them to adapt rapidly to new tasks with minimal examples. This method shows an average performance improvement of 2-4% compared to existing meta-training approaches in various generalization and limited-data scenarios.

11 Jun 2021
There is a recent trend in machine learning to increase model quality by
growing models to sizes previously thought to be unreasonable. Recent work has
shown that autoregressive generative models with cross-entropy objective
functions exhibit smooth power-law relationships, or scaling laws, that predict
model quality from model size, training set size, and the available compute
budget. These scaling laws allow one to choose nearly optimal hyper-parameters
given constraints on available training data, model parameter count, or
training computation budget. In this paper, we demonstrate that acoustic models
trained with an auto-predictive coding loss behave as if they are subject to
similar scaling laws. We extend previous work to jointly predict loss due to
model size, to training set size, and to the inherent "irreducible loss" of the
task. We find that the scaling laws accurately match model performance over two
orders of magnitude in both model size and training set size, and make
predictions about the limits of model performance.

14 Jun 2024




The INTR model introduces a simple, inherently interpretable Transformer for fine-grained image classification by having each class actively search for itself within an image. This approach provides built-in, attribute-level visual explanations directly from cross-attention maps, outperforming other interpretable models in identifying distinctive traits across various biological and object datasets.

12 Oct 2021


Fact verification has attracted a lot of attention in the machine learning and natural language processing communities, as it is one of the key methods for detecting misinformation. Existing large-scale benchmarks for this task have focused mostly on textual sources, i.e. unstructured information, and thus ignored the wealth of information available in structured formats, such as tables. In this paper we introduce a novel dataset and benchmark, Fact Extraction and VERification Over Unstructured and Structured information (FEVEROUS), which consists of 87,026 verified claims. Each claim is annotated with evidence in the form of sentences and/or cells from tables in Wikipedia, as well as a label indicating whether this evidence supports, refutes, or does not provide enough information to reach a verdict. Furthermore, we detail our efforts to track and minimize the biases present in the dataset and could be exploited by models, e.g. being able to predict the label without using evidence. Finally, we develop a baseline for verifying claims against text and tables which predicts both the correct evidence and verdict for 18% of the claims.

12 Feb 2021
Speech emotion recognition (SER) is a key technology to enable more natural
human-machine communication. However, SER has long suffered from a lack of
public large-scale labeled datasets. To circumvent this problem, we investigate
how unsupervised representation learning on unlabeled datasets can benefit SER.
We show that the contrastive predictive coding (CPC) method can learn salient
representations from unlabeled datasets, which improves emotion recognition
performance. In our experiments, this method achieved state-of-the-art
concordance correlation coefficient (CCC) performance for all emotion
primitives (activation, valence, and dominance) on IEMOCAP. Additionally, on
the MSP- Podcast dataset, our method obtained considerable performance
improvements compared to baselines.

12 May 2023
Long-horizon task planning is essential for the development of intelligent assistive and service robots. In this work, we investigate the applicability of a smaller class of large language models (LLMs), specifically GPT-2, in robotic task planning by learning to decompose tasks into subgoal specifications for a planner to execute sequentially. Our method grounds the input of the LLM on the domain that is represented as a scene graph, enabling it to translate human requests into executable robot plans, thereby learning to reason over long-horizon tasks, as encountered in the ALFRED benchmark. We compare our approach with classical planning and baseline methods to examine the applicability and generalizability of LLM-based planners. Our findings suggest that the knowledge stored in an LLM can be effectively grounded to perform long-horizon task planning, demonstrating the promising potential for the future application of neuro-symbolic planning methods in robotics.

23 Mar 2022





Language models excel at generating coherent text, and model compression techniques such as knowledge distillation have enabled their use in resource-constrained settings. However, these models can be biased in multiple ways, including the unfounded association of male and female genders with gender-neutral professions. Therefore, knowledge distillation without any fairness constraints may preserve or exaggerate the teacher model's biases onto the distilled model. To this end, we present a novel approach to mitigate gender disparity in text generation by learning a fair model during knowledge distillation. We propose two modifications to the base knowledge distillation based on counterfactual role reversalmodifying teacher probabilities and augmenting the training set. We evaluate gender polarity across professions in open-ended text generated from the resulting distilled and finetuned GPT2 models and demonstrate a substantial reduction in gender disparity with only a minor compromise in utility. Finally, we observe that language models that reduce gender polarity in language generation do not improve embedding fairness or downstream classification fairness.

27 Jun 2023
Recent studies have found that model performance has a smooth power-law relationship, or scaling laws, with training data and model size, for a wide range of problems. These scaling laws allow one to choose nearly optimal data and model sizes. We study whether this scaling property is also applicable to second-pass rescoring, which is an important component of speech recognition systems. We focus on RescoreBERT as the rescoring model, which uses a pre-trained Transformer-based architecture fined tuned with an ASR discriminative loss. Using such a rescoring model, we show that the word error rate (WER) follows a scaling law for over two orders of magnitude as training data and model size increase. In addition, it is found that a pre-trained model would require less data than a randomly initialized model of the same size, representing effective data transferred from pre-training step. This effective data transferred is found to also follow a scaling law with the data and model size.

21 Mar 2025
Mondal et al. systematically investigate the practical utility of 'language-specific neurons' in large language models for improving cross-lingual transfer in natural language understanding tasks. Experiments on Llama 3.1 and Mistral Nemo demonstrate that current identification and manipulation techniques for these neurons do not yield meaningful performance gains.
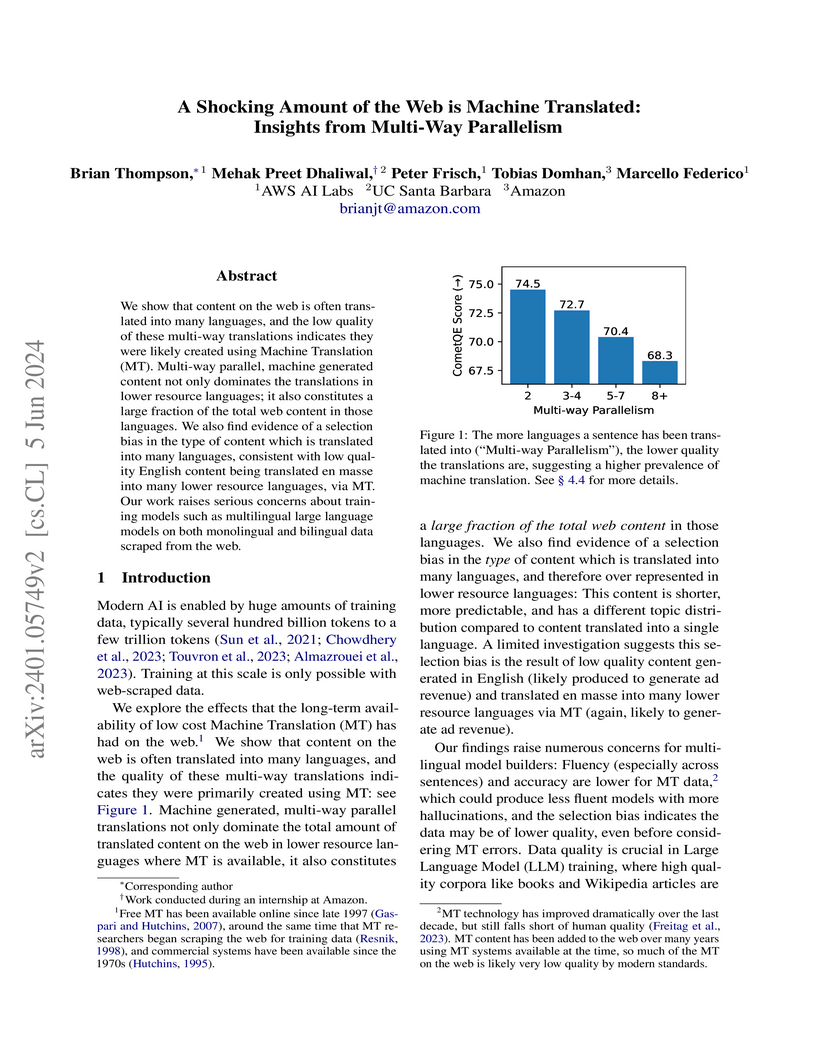
05 Jun 2024
We show that content on the web is often translated into many languages, and the low quality of these multi-way translations indicates they were likely created using Machine Translation (MT). Multi-way parallel, machine generated content not only dominates the translations in lower resource languages; it also constitutes a large fraction of the total web content in those languages. We also find evidence of a selection bias in the type of content which is translated into many languages, consistent with low quality English content being translated en masse into many lower resource languages, via MT. Our work raises serious concerns about training models such as multilingual large language models on both monolingual and bilingual data scraped from the web.
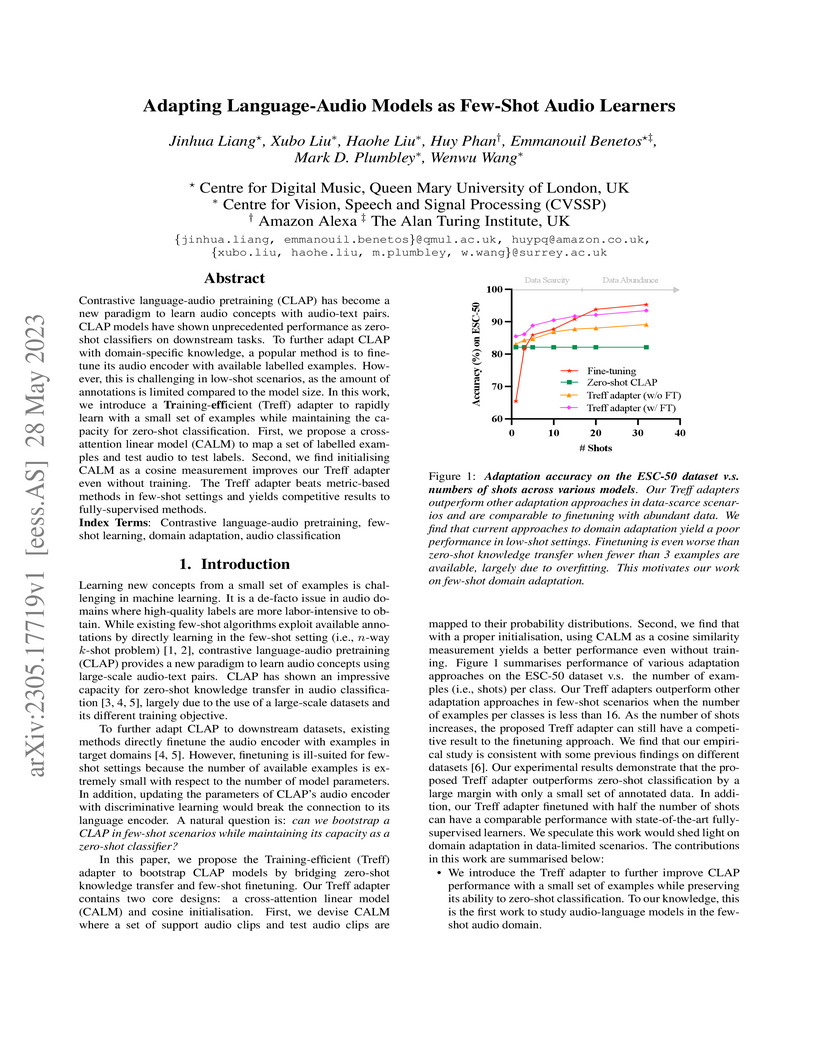
28 May 2023

Researchers developed the Training-efficient (Treff) adapter to enhance CLAP models' performance in few-shot audio classification, combining zero-shot and few-shot learning to achieve significant improvements over baselines and competitive results with fully supervised methods using minimal labeled data.

09 May 2023
Attention-based contextual biasing approaches have shown significant improvements in the recognition of generic and/or personal rare-words in End-to-End Automatic Speech Recognition (E2E ASR) systems like neural transducers. These approaches employ cross-attention to bias the model towards specific contextual entities injected as bias-phrases to the model. Prior approaches typically relied on subword encoders for encoding the bias phrases. However, subword tokenizations are coarse and fail to capture granular pronunciation information which is crucial for biasing based on acoustic similarity. In this work, we propose to use lightweight character representations to encode fine-grained pronunciation features to improve contextual biasing guided by acoustic similarity between the audio and the contextual entities (termed acoustic biasing). We further integrate pretrained neural language model (NLM) based encoders to encode the utterance's semantic context along with contextual entities to perform biasing informed by the utterance's semantic context (termed semantic biasing). Experiments using a Conformer Transducer model on the Librispeech dataset show a 4.62% - 9.26% relative WER improvement on different biasing list sizes over the baseline contextual model when incorporating our proposed acoustic and semantic biasing approach. On a large-scale in-house dataset, we observe 7.91% relative WER improvement compared to our baseline model. On tail utterances, the improvements are even more pronounced with 36.80% and 23.40% relative WER improvements on Librispeech rare words and an in-house testset respectively.

26 May 2022
Personal rare word recognition in end-to-end Automatic Speech Recognition (E2E ASR) models is a challenge due to the lack of training data. A standard way to address this issue is with shallow fusion methods at inference time. However, due to their dependence on external language models and the deterministic approach to weight boosting, their performance is limited. In this paper, we propose training neural contextual adapters for personalization in neural transducer based ASR models. Our approach can not only bias towards user-defined words, but also has the flexibility to work with pretrained ASR models. Using an in-house dataset, we demonstrate that contextual adapters can be applied to any general purpose pretrained ASR model to improve personalization. Our method outperforms shallow fusion, while retaining functionality of the pretrained models by not altering any of the model weights. We further show that the adapter style training is superior to full-fine-tuning of the ASR models on datasets with user-defined content.

05 Nov 2021
End-to-end (E2E) automatic speech recognition (ASR) systems often have
difficulty recognizing uncommon words, that appear infrequently in the training
data. One promising method, to improve the recognition accuracy on such rare
words, is to latch onto personalized/contextual information at inference. In
this work, we present a novel context-aware transformer transducer (CATT)
network that improves the state-of-the-art transformer-based ASR system by
taking advantage of such contextual signals. Specifically, we propose a
multi-head attention-based context-biasing network, which is jointly trained
with the rest of the ASR sub-networks. We explore different techniques to
encode contextual data and to create the final attention context vectors. We
also leverage both BLSTM and pretrained BERT based models to encode contextual
data and guide the network training. Using an in-house far-field dataset, we
show that CATT, using a BERT based context encoder, improves the word error
rate of the baseline transformer transducer and outperforms an existing deep
contextual model by 24.2% and 19.4% respectively.

09 Aug 2023

The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.

01 Jun 2023

We investigate knowledge retrieval with multi-modal queries, i.e. queries containing information split across image and text inputs, a challenging task that differs from previous work on cross-modal retrieval. We curate a new dataset called ReMuQ for benchmarking progress on this task. ReMuQ requires a system to retrieve knowledge from a large corpus by integrating contents from both text and image queries. We introduce a retriever model ``ReViz'' that can directly process input text and images to retrieve relevant knowledge in an end-to-end fashion without being dependent on intermediate modules such as object detectors or caption generators. We introduce a new pretraining task that is effective for learning knowledge retrieval with multimodal queries and also improves performance on downstream tasks. We demonstrate superior performance in retrieval on two datasets (ReMuQ and OK-VQA) under zero-shot settings as well as further improvements when finetuned on these datasets.

02 Jun 2021
Language modeling (LM) for automatic speech recognition (ASR) does not
usually incorporate utterance level contextual information. For some domains
like voice assistants, however, additional context, such as the time at which
an utterance was spoken, provides a rich input signal. We introduce an
attention mechanism for training neural speech recognition language models on
both text and non-linguistic contextual data. When applied to a large
de-identified dataset of utterances collected by a popular voice assistant
platform, our method reduces perplexity by 7.0% relative over a standard LM
that does not incorporate contextual information. When evaluated on utterances
extracted from the long tail of the dataset, our method improves perplexity by
9.0% relative over a standard LM and by over 2.8% relative when compared to a
state-of-the-art model for contextual LM.

13 Jun 2023
Personalized dialogue agents (DAs) powered by large pre-trained language models (PLMs) often rely on explicit persona descriptions to maintain personality consistency. However, such descriptions may not always be available or may pose privacy concerns. To tackle this bottleneck, we introduce PersonaPKT, a lightweight transfer learning approach that can build persona-consistent dialogue models without explicit persona descriptions. By representing each persona as a continuous vector, PersonaPKT learns implicit persona-specific features directly from a small number of dialogue samples produced by the same persona, adding less than 0.1% trainable parameters for each persona on top of the PLM backbone. Empirical results demonstrate that PersonaPKT effectively builds personalized DAs with high storage efficiency, outperforming various baselines in terms of persona consistency while maintaining good response generation quality. In addition, it enhances privacy protection by avoiding explicit persona descriptions. Overall, PersonaPKT is an effective solution for creating personalized DAs that respect user privacy.

26 Dec 2018


Conversational agents are exploding in popularity. However, much work remains in the area of non goal-oriented conversations, despite significant growth in research interest over recent years. To advance the state of the art in conversational AI, Amazon launched the Alexa Prize, a 2.5-million dollar university competition where sixteen selected university teams built conversational agents to deliver the best social conversational experience. Alexa Prize provided the academic community with the unique opportunity to perform research with a live system used by millions of users. The subjectivity associated with evaluating conversations is key element underlying the challenge of building non-goal oriented dialogue systems. In this paper, we propose a comprehensive evaluation strategy with multiple metrics designed to reduce subjectivity by selecting metrics which correlate well with human judgement. The proposed metrics provide granular analysis of the conversational agents, which is not captured in human ratings. We show that these metrics can be used as a reasonable proxy for human judgment. We provide a mechanism to unify the metrics for selecting the top performing agents, which has also been applied throughout the Alexa Prize competition. To our knowledge, to date it is the largest setting for evaluating agents with millions of conversations and hundreds of thousands of ratings from users. We believe that this work is a step towards an automatic evaluation process for conversational AIs.
There are no more papers matching your filters at the moment.
