
05 May 2025



Text-to-video generation has been dominated by diffusion-based or
autoregressive models. These novel models provide plausible versatility, but
are criticized for improper physical motion, shading and illumination, camera
motion, and temporal consistency. The film industry relies on manually-edited
Computer-Generated Imagery (CGI) using 3D modeling software. Human-directed 3D
synthetic videos address these shortcomings, but require tight collaboration
between movie makers and 3D rendering experts. We introduce an automatic
synthetic video generation pipeline based on Vision Large Language Model (VLM)
agent collaborations. Given a language description of a video, multiple VLM
agents direct various processes of the generation pipeline. They cooperate to
create Blender scripts which render a video following the given description.
Augmented with Blender-based movie making knowledge, the Director agent
decomposes the text-based video description into sub-processes. For each
sub-process, the Programmer agent produces Python-based Blender scripts based
on function composing and API calling. The Reviewer agent, with knowledge of
video reviewing, character motion coordinates, and intermediate screenshots,
provides feedback to the Programmer agent. The Programmer agent iteratively
improves scripts to yield the best video outcome. Our generated videos show
better quality than commercial video generation models in five metrics on video
quality and instruction-following performance. Our framework outperforms other
approaches in a user study on quality, consistency, and rationality.
03 Mar 2025


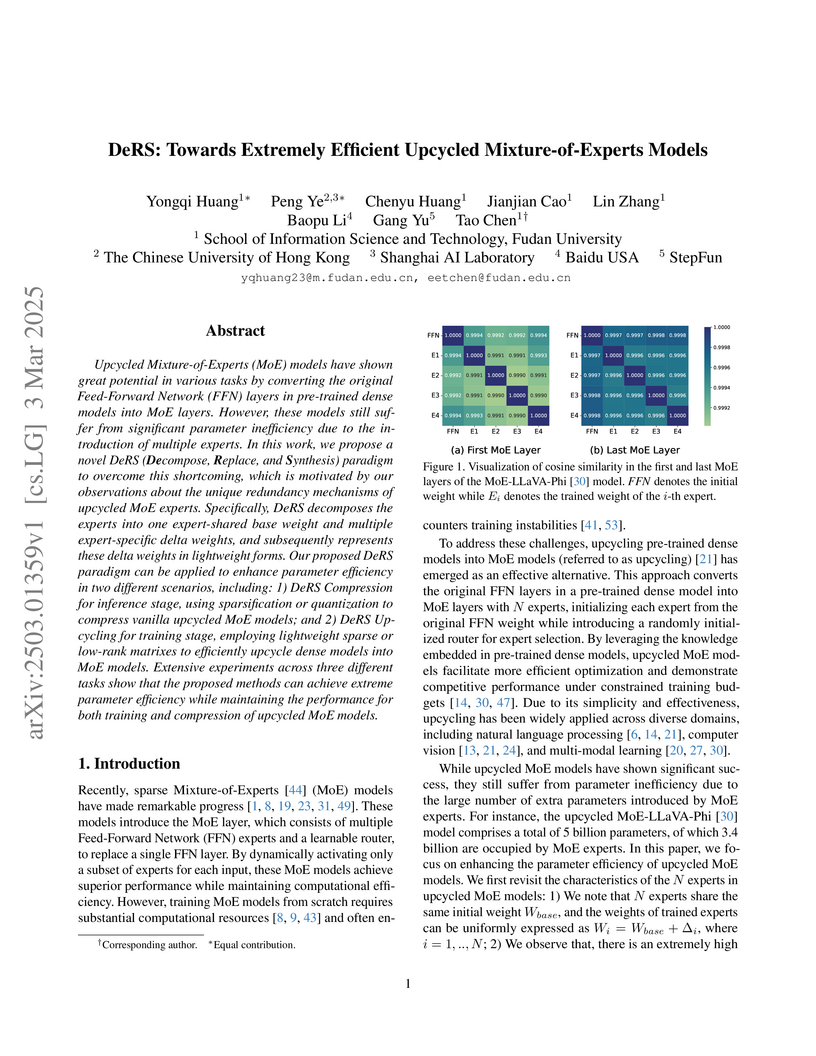
Upcycled Mixture-of-Experts (MoE) models have shown great potential in
various tasks by converting the original Feed-Forward Network (FFN) layers in
pre-trained dense models into MoE layers. However, these models still suffer
from significant parameter inefficiency due to the introduction of multiple
experts. In this work, we propose a novel DeRS (Decompose, Replace, and
Synthesis) paradigm to overcome this shortcoming, which is motivated by our
observations about the unique redundancy mechanisms of upcycled MoE experts.
Specifically, DeRS decomposes the experts into one expert-shared base weight
and multiple expert-specific delta weights, and subsequently represents these
delta weights in lightweight forms. Our proposed DeRS paradigm can be applied
to enhance parameter efficiency in two different scenarios, including: 1) DeRS
Compression for inference stage, using sparsification or quantization to
compress vanilla upcycled MoE models; and 2) DeRS Upcycling for training stage,
employing lightweight sparse or low-rank matrixes to efficiently upcycle dense
models into MoE models. Extensive experiments across three different tasks show
that the proposed methods can achieve extreme parameter efficiency while
maintaining the performance for both training and compression of upcycled MoE
models.

03 Mar 2025

Neural architecture search (NAS) has demonstrated amazing success in
searching for efficient deep neural networks (DNNs) from a given supernet. In
parallel, the lottery ticket hypothesis has shown that DNNs contain small
subnetworks that can be trained from scratch to achieve a comparable or higher
accuracy than original DNNs. As such, it is currently a common practice to
develop efficient DNNs via a pipeline of first search and then prune.
Nevertheless, doing so often requires a search-train-prune-retrain process and
thus prohibitive computational cost. In this paper, we discover for the first
time that both efficient DNNs and their lottery subnetworks (i.e., lottery
tickets) can be directly identified from a supernet, which we term as
SuperTickets, via a two-in-one training scheme with jointly architecture
searching and parameter pruning. Moreover, we develop a progressive and unified
SuperTickets identification strategy that allows the connectivity of
subnetworks to change during supernet training, achieving better accuracy and
efficiency trade-offs than conventional sparse training. Finally, we evaluate
whether such identified SuperTickets drawn from one task can transfer well to
other tasks, validating their potential of handling multiple tasks
simultaneously. Extensive experiments and ablation studies on three tasks and
four benchmark datasets validate that our proposed SuperTickets achieve boosted
accuracy and efficiency trade-offs than both typical NAS and pruning pipelines,
regardless of having retraining or not. Codes and pretrained models are
available at this https URL

18 Mar 2020

Despite the recent progress of fully-supervised action segmentation
techniques, the performance is still not fully satisfactory. One main challenge
is the problem of spatiotemporal variations (e.g. different people may perform
the same activity in various ways). Therefore, we exploit unlabeled videos to
address this problem by reformulating the action segmentation task as a
cross-domain problem with domain discrepancy caused by spatio-temporal
variations. To reduce the discrepancy, we propose Self-Supervised Temporal
Domain Adaptation (SSTDA), which contains two self-supervised auxiliary tasks
(binary and sequential domain prediction) to jointly align cross-domain feature
spaces embedded with local and global temporal dynamics, achieving better
performance than other Domain Adaptation (DA) approaches. On three challenging
benchmark datasets (GTEA, 50Salads, and Breakfast), SSTDA outperforms the
current state-of-the-art method by large margins (e.g. for the F1@25 score,
from 59.6% to 69.1% on Breakfast, from 73.4% to 81.5% on 50Salads, and from
83.6% to 89.1% on GTEA), and requires only 65% of the labeled training data for
comparable performance, demonstrating the usefulness of adapting to unlabeled
target videos across variations. The source code is available at
this https URL

22 Oct 2024
RetriBooru: Leakage-Free Retrieval of Conditions from Reference Images for Subject-Driven Generation
RetriBooru: Leakage-Free Retrieval of Conditions from Reference Images for Subject-Driven Generation

Diffusion-based methods have demonstrated remarkable capabilities in
generating a diverse array of high-quality images, sparking interests for
styled avatars, virtual try-on, and more. Previous methods use the same
reference image as the target. An overlooked aspect is the leakage of the
target's spatial information, style, etc. from the reference, harming the
generated diversity and causing shortcuts. However, this approach continues as
widely available datasets usually consist of single images not grouped by
identities, and it is expensive to recollect large-scale same-identity data.
Moreover, existing metrics adopt decoupled evaluation on text alignment and
identity preservation, which fail at distinguishing between balanced outputs
and those that over-fit to one aspect. In this paper, we propose a multi-level,
same-identity dataset RetriBooru, which groups anime characters by both face
and cloth identities. RetriBooru enables adopting reference images of the same
character and outfits as the target, while keeping flexible gestures and
actions. We benchmark previous methods on our dataset, and demonstrate the
effectiveness of training with a reference image different from target (but
same identity). We introduce a new concept composition task, where the
conditioning encoder learns to retrieve different concepts from several
reference images, and modify a baseline network RetriNet for the new task.
Finally, we introduce a novel class of metrics named Similarity Weighted
Diversity (SWD), to measure the overlooked diversity and better evaluate the
alignment between similarity and diversity.

06 Mar 2020



Recent research has proposed the lottery ticket hypothesis, suggesting that
for a deep neural network, there exist trainable sub-networks performing
equally or better than the original model with commensurate training steps.
While this discovery is insightful, finding proper sub-networks requires
iterative training and pruning. The high cost incurred limits the applications
of the lottery ticket hypothesis. We show there exists a subset of the
aforementioned sub-networks that converge significantly faster during the
training process and thus can mitigate the cost issue. We conduct extensive
experiments to show such sub-networks consistently exist across various model
structures for a restrictive setting of hyperparameters (, carefully
selected learning rate, pruning ratio, and model capacity). As a practical
application of our findings, we demonstrate that such sub-networks can help in
cutting down the total time of adversarial training, a standard approach to
improve robustness, by up to 49\% on CIFAR-10 to achieve the state-of-the-art
robustness.

18 Jun 2019

Hybrid testing combines fuzz testing and concolic execution. It leverages fuzz testing to test easy-to-reach code regions and uses concolic execution to explore code blocks guarded by complex branch conditions. However, its code coverage-centric design is inefficient in vulnerability detection. First, it blindly selects seeds for concolic execution and aims to explore new code continuously. However, as statistics show, a large portion of the explored code is often bug-free. Therefore, giving equal attention to every part of the code during hybrid testing is a non-optimal strategy. It slows down the detection of real vulnerabilities by over 43%. Second, classic hybrid testing quickly moves on after reaching a chunk of code, rather than examining the hidden defects inside. It may frequently miss subtle vulnerabilities despite that it has already explored the vulnerable code paths. We propose SAVIOR, a new hybrid testing framework pioneering a bug-driven principle. Unlike the existing hybrid testing tools, SAVIOR prioritizes the concolic execution of the seeds that are likely to uncover more vulnerabilities. Moreover, SAVIOR verifies all vulnerable program locations along the executing program path. By modeling faulty situations using SMT constraints, SAVIOR reasons the feasibility of vulnerabilities and generates concrete test cases as proofs. Our evaluation shows that the bug-driven approach outperforms mainstream automated testing techniques, including state-of-the-art hybrid testing systems driven by code coverage. On average, SAVIOR detects vulnerabilities 43.4% faster than DRILLER and 44.3% faster than QSYM, leading to the discovery of 88 and 76 more uniquebugs,respectively.Accordingtotheevaluationon11 well fuzzed benchmark programs, within the first 24 hours, SAVIOR triggers 481 UBSAN violations, among which 243 are real bugs.

02 Nov 2020
Although first-order stochastic algorithms, such as stochastic gradient descent, have been the main force to scale up machine learning models, such as deep neural nets, the second-order quasi-Newton methods start to draw attention due to their effectiveness in dealing with ill-conditioned optimization problems. The L-BFGS method is one of the most widely used quasi-Newton methods. We propose an asynchronous parallel algorithm for stochastic quasi-Newton (AsySQN) method. Unlike prior attempts, which parallelize only the calculation for gradient or the two-loop recursion of L-BFGS, our algorithm is the first one that truly parallelizes L-BFGS with a convergence guarantee. Adopting the variance reduction technique, a prior stochastic L-BFGS, which has not been designed for parallel computing, reaches a linear convergence rate. We prove that our asynchronous parallel scheme maintains the same linear convergence rate but achieves significant speedup. Empirical evaluations in both simulations and benchmark datasets demonstrate the speedup in comparison with the non-parallel stochastic L-BFGS, as well as the better performance than first-order methods in solving ill-conditioned problems.

25 May 2024
Randomized smoothing has become a leading method for achieving certified robustness in deep classifiers against l_{p}-norm adversarial perturbations. Current approaches for achieving certified robustness, such as data augmentation with Gaussian noise and adversarial training, require expensive training procedures that tune large models for different Gaussian noise levels and thus cannot leverage high-performance pre-trained neural networks. In this work, we introduce a novel certifying adapters framework (CAF) that enables and enhances the certification of classifier adversarial robustness. Our approach makes few assumptions about the underlying training algorithm or feature extractor and is thus broadly applicable to different feature extractor architectures (e.g., convolutional neural networks or vision transformers) and smoothing algorithms. We show that CAF (a) enables certification in uncertified models pre-trained on clean datasets and (b) substantially improves the performance of certified classifiers via randomized smoothing and SmoothAdv at multiple radii in CIFAR-10 and ImageNet. We demonstrate that CAF achieves improved certified accuracies when compared to methods based on random or denoised smoothing, and that CAF is insensitive to certifying adapter hyperparameters. Finally, we show that an ensemble of adapters enables a single pre-trained feature extractor to defend against a range of noise perturbation scales.

10 Nov 2020

Excavators are widely used for material-handling applications in unstructured
environments, including mining and construction. The size of the global market
of excavators is 44.12 Billion USD in 2018 and is predicted to grow to 63.14
Billion USD by 2026. Operating excavators in a real-world environment can be
challenging due to extreme conditions and rock sliding, ground collapse, or
exceeding dust. Multiple fatalities and injuries occur each year during
excavations. An autonomous excavator that can substitute human operators in
these hazardous environments would substantially lower the number of injuries
and can improve the overall productivity.

10 Nov 2020
Natural language-based robotic navigation remains a challenging problem due to the human knowledge of navigation constraints, and destination is not directly compatible with the robot knowledge base. In this paper, we aim to translate natural destination commands into high-level robot navigation plans given a map of interest. We identify grammatically associated segments of destination description and recursively apply each of them to update a belief distribution of an area over the given this http URL train a destination grounding model using a dataset of single-step belief update for precise, proximity, and directional modifier types. We demonstrate our method on real-world navigation task in an office consisting of 80 areas. Offline experimental results show that our method can directly extract goal destination from unheard, long, and composite text commands asked by humans. This enables users to specify their destination goals for the robot in general and natural form. Hardware experiment results also show that the designed model brings much convenience for specifying a navigation goal to a service robot.

03 Mar 2025

Neural networks (NNs) with intensive multiplications (e.g., convolutions and
transformers) are capable yet power hungry, impeding their more extensive
deployment into resource-constrained devices. As such, multiplication-free
networks, which follow a common practice in energy-efficient hardware
implementation to parameterize NNs with more efficient operators (e.g., bitwise
shifts and additions), have gained growing attention. However,
multiplication-free networks usually under-perform their vanilla counterparts
in terms of the achieved accuracy. To this end, this work advocates hybrid NNs
that consist of both powerful yet costly multiplications and efficient yet less
powerful operators for marrying the best of both worlds, and proposes
ShiftAddNAS, which can automatically search for more accurate and more
efficient NNs. Our ShiftAddNAS highlights two enablers. Specifically, it
integrates (1) the first hybrid search space that incorporates both
multiplication-based and multiplication-free operators for facilitating the
development of both accurate and efficient hybrid NNs; and (2) a novel weight
sharing strategy that enables effective weight sharing among different
operators that follow heterogeneous distributions (e.g., Gaussian for
convolutions vs. Laplacian for add operators) and simultaneously leads to a
largely reduced supernet size and much better searched networks. Extensive
experiments and ablation studies on various models, datasets, and tasks
consistently validate the efficacy of ShiftAddNAS, e.g., achieving up to a
+7.7% higher accuracy or a +4.9 better BLEU score compared to state-of-the-art
NN, while leading to up to 93% or 69% energy and latency savings, respectively.
Codes and pretrained models are available at
this https URL

09 Mar 2021

Unsupervised domain adaptation (UDA) aims to transfer the knowledge from the
labeled source domain to the unlabeled target domain. Existing self-training
based UDA approaches assign pseudo labels for target data and treat them as
ground truth labels to fully leverage unlabeled target data for model
adaptation. However, the generated pseudo labels from the model optimized on
the source domain inevitably contain noise due to the domain gap. To tackle
this issue, we advance a MetaCorrection framework, where a Domain-aware
Meta-learning strategy is devised to benefit Loss Correction (DMLC) for UDA
semantic segmentation. In particular, we model the noise distribution of pseudo
labels in target domain by introducing a noise transition matrix (NTM) and
construct meta data set with domain-invariant source data to guide the
estimation of NTM. Through the risk minimization on the meta data set, the
optimized NTM thus can correct the noisy issues in pseudo labels and enhance
the generalization ability of the model on the target data. Considering the
capacity gap between shallow and deep features, we further employ the proposed
DMLC strategy to provide matched and compatible supervision signals for
different level features, thereby ensuring deep adaptation. Extensive
experimental results highlight the effectiveness of our method against existing
state-of-the-art methods on three benchmarks.

12 Nov 2020
Existing natural language processing systems are vulnerable to noisy inputs
resulting from misspellings. On the contrary, humans can easily infer the
corresponding correct words from their misspellings and surrounding context.
Inspired by this, we address the stand-alone spelling correction problem, which
only corrects the spelling of each token without additional token insertion or
deletion, by utilizing both spelling information and global context
representations. We present a simple yet powerful solution that jointly detects
and corrects misspellings as a sequence labeling task by fine-turning a
pre-trained language model. Our solution outperforms the previous
state-of-the-art result by 12.8% absolute F0.5 score.

16 Apr 2021
The main progress for action segmentation comes from densely-annotated data for fully-supervised learning. Since manual annotation for frame-level actions is time-consuming and challenging, we propose to exploit auxiliary unlabeled videos, which are much easier to obtain, by shaping this problem as a domain adaptation (DA) problem. Although various DA techniques have been proposed in recent years, most of them have been developed only for the spatial direction. Therefore, we propose Mixed Temporal Domain Adaptation (MTDA) to jointly align frame- and video-level embedded feature spaces across domains, and further integrate with the domain attention mechanism to focus on aligning the frame-level features with higher domain discrepancy, leading to more effective domain adaptation. Finally, we evaluate our proposed methods on three challenging datasets (GTEA, 50Salads, and Breakfast), and validate that MTDA outperforms the current state-of-the-art methods on all three datasets by large margins (e.g. 6.4% gain on F1@50 and 6.8% gain on the edit score for GTEA).
There are no more papers matching your filters at the moment.
