
02 Dec 2024
FedAH enhances personalized federated learning by introducing an Aggregated Head mechanism that adaptively integrates global knowledge into client-specific prediction heads. This approach consistently outperforms ten state-of-the-art FL methods, showing up to 2.87% higher test accuracy on complex datasets like Cifar100.

30 Nov 2024
Researchers from Beijing Institute of Technology and North Minzu University introduced FedPSD, a personalized federated learning framework for IIoT edge devices that employs progressive self-distillation and logits calibration to simultaneously prevent global and personalized knowledge forgetting. This approach consistently achieved state-of-the-art accuracy, with up to a 39.8% improvement over FedAvg, and substantially reduced communication rounds.

30 Jan 2024
We demonstrate the emergence of a pronounced thermal transport in the
recently discovered class of magnetic materials-altermagnets. From symmetry
arguments and first-principles calculations performed for the showcase
altermagnet, RuO2, we uncover that crystal Nernst and crystal thermal Hall
effects in this material are very large and strongly anisotropic with respect
to the Neel vector. We find the large crystal thermal transport to originate
from three sources of Berry's curvature in momentum space: the Weyl fermions
due to crossings between well-separated bands, the strong spin-flip pseudonodal
surfaces, and the weak spin-flip ladder transitions, defined by transitions
among very weakly spin-split states of similar dispersion crossing the Fermi
surface. Moreover, we reveal that the anomalous thermal and electrical
transport coefficients in RuO2 are linked by an extended Wiedemann-Franz law in
a temperature range much wider than expected for conventional magnets. Our
results suggest that altermagnets may assume a leading role in realizing
concepts in spin caloritronics not achievable with ferromagnets or
antiferromagnets.

02 Apr 2025

Dinomaly introduces a minimalist, Transformer-based framework for multi-class unsupervised anomaly detection that achieves state-of-the-art performance. The method effectively addresses over-generalization by using a noisy bottleneck and loose reconstruction strategies, allowing a single model to match or exceed the performance of class-separated anomaly detection methods.

05 Dec 2025


Vision language models (VLMs) have achieved impressive performance across a variety of computer vision tasks. However, the multimodal reasoning capability has not been fully explored in existing models. In this paper, we propose a Chain-of-Focus (CoF) method that allows VLMs to perform adaptive focusing and zooming in on key image regions based on obtained visual cues and the given questions, achieving efficient multimodal reasoning. To enable this CoF capability, we present a two-stage training pipeline, including supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we construct the MM-CoF dataset, comprising 3K samples derived from a visual agent designed to adaptively identify key regions to solve visual tasks with different image resolutions and questions. We use MM-CoF to fine-tune the Qwen2.5-VL model for cold start. In the RL stage, we leverage the outcome accuracies and formats as rewards to update the Qwen2.5-VL model, enabling further refining the search and reasoning strategy of models without human priors. Our model achieves significant improvements on multiple benchmarks. On the V* benchmark that requires strong visual reasoning capability, our model outperforms existing VLMs by 5% among 8 image resolutions ranging from 224 to 4K, demonstrating the effectiveness of the proposed CoF method and facilitating the more efficient deployment of VLMs in practical applications.
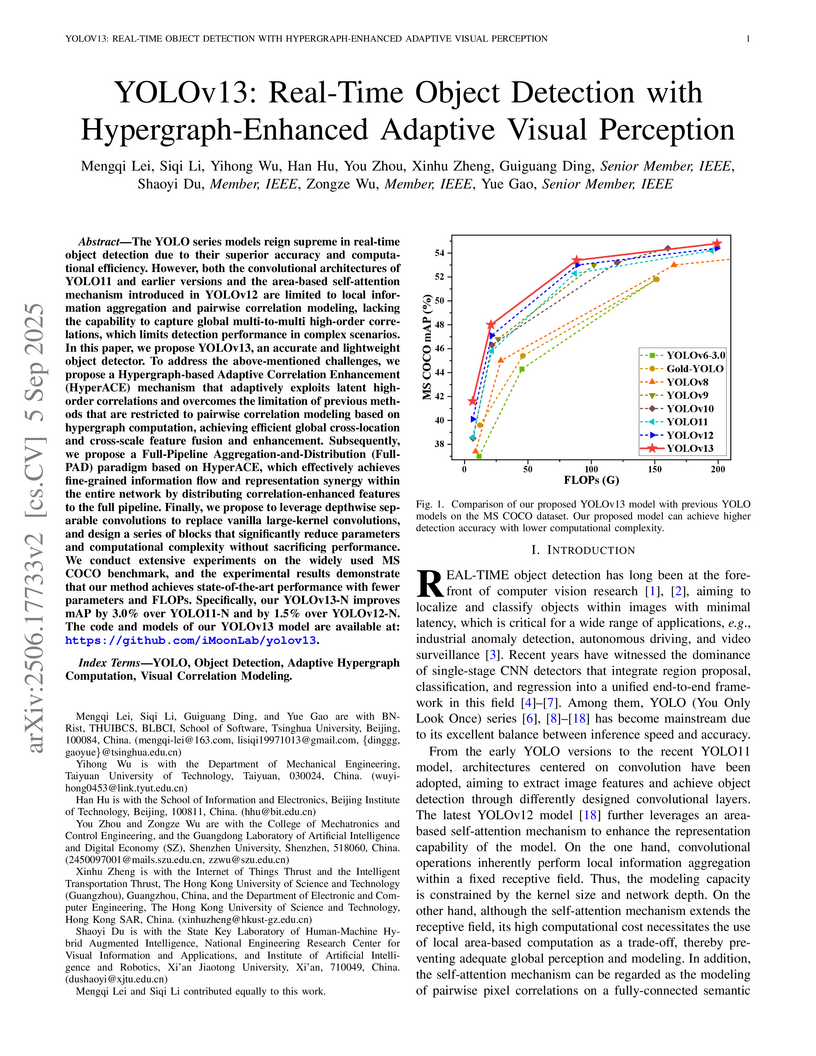
05 Sep 2025

YOLOv13 enhances real-time object detection by integrating an adaptive hypergraph computation mechanism for high-order visual correlation modeling and a full-pipeline feature distribution paradigm. The approach yields improved detection accuracy on the MS COCO benchmark, with the Nano variant achieving a 1.5% mAP@50:95 increase over YOLOv12-N, while maintaining or reducing computational cost.

09 Nov 2025

A new comprehensive video dataset named Sekai, curated by Shanghai AI Laboratory, supports advanced world exploration models with over 5,000 hours of videos from real-world and game sources, annotated with explicit camera trajectories and extensive metadata. This data effectively improved model performance in text-to-video, image-to-video, and camera-controlled video generation tasks.

22 Aug 2025
MeshCoder reconstructs complex 3D objects from point clouds into editable Blender Python scripts, achieving an L2 Chamfer Distance of 0.06 (x10^-2) while enabling precise geometric and topological editing. This method allows large language models to better reason about 3D shapes through semantically rich code, substantially outperforming existing shape-to-code baselines.

30 Aug 2024




Hydra-MDP implements an end-to-end multimodal planning framework using multi-target knowledge distillation from human and rule-based teachers to enhance autonomous driving safety and compliance. The system secured 1st place in the Navsim challenge, exhibiting superior closed-loop performance with a PDM score of 86.5 for single models and up to 91.0 with larger backbones.

22 May 2025


R1-Searcher++ presents a framework that enables large language models to dynamically choose between using their internal knowledge and performing external searches, while also allowing them to internalize retrieved information. This approach improves performance on multi-hop question answering tasks and significantly reduces the number of external retrieval calls compared to prior methods.

04 Dec 2025

Large Language Models (LLMs) are typically trained on data mixtures: most data come from web scrapes, while a small portion is curated from high-quality sources with dense domain-specific knowledge. In this paper, we show that when training LLMs on such data mixtures, knowledge acquisition from knowledge-dense datasets, unlike training exclusively on knowledge-dense data (arXiv:2404.05405), does not always follow a smooth scaling law but can exhibit phase transitions with respect to the mixing ratio and model size. Through controlled experiments on a synthetic biography dataset mixed with web-scraped data, we demonstrate that: (1) as we increase the model size to a critical value, the model suddenly transitions from memorizing very few to most of the biographies; (2) below a critical mixing ratio, the model memorizes almost nothing even with extensive training, but beyond this threshold, it rapidly memorizes more biographies. We attribute these phase transitions to a capacity allocation phenomenon: a model with bounded capacity must act like a knapsack problem solver to minimize the overall test loss, and the optimal allocation across datasets can change discontinuously as the model size or mixing ratio varies. We formalize this intuition in an information-theoretic framework and reveal that these phase transitions are predictable, with the critical mixing ratio following a power-law relationship with the model size. Our findings highlight a concrete case where a good mixing recipe for large models may not be optimal for small models, and vice versa.

18 Jun 2025

Proprietary giants are increasingly dominating the race for ever-larger
language models. Can open-source, smaller models remain competitive across a
broad range of tasks? In this paper, we present the Avengers -- a simple recipe
that leverages the collective intelligence of these smaller models. The
Avengers builds upon four lightweight operations: (i) embedding: encode queries
using a text embedding model; (ii) clustering: group queries based on their
semantic similarity; (iii) scoring: scores each model's performance within each
cluster; and (iv) voting: improve outputs via repeated sampling and voting. At
inference time, each query is embedded and assigned to its nearest cluster. The
top-performing model(s) within that cluster are selected to generate the
response with repeated sampling. Remarkably, with 10 open-source models (~7B
parameters each), the Avengers surpasses GPT-4o, 4.1, and 4.5 in average
performance across 15 diverse datasets spanning mathematics, coding, logical
reasoning, general knowledge, and affective tasks. In particular, it surpasses
GPT-4.1 on mathematics tasks by 18.21% and on code tasks by 7.46%. Furthermore,
the Avengers delivers superior out-of-distribution generalization, and remains
robust across various embedding models, clustering algorithms, ensemble
strategies, and values of its sole parameter -- the number of clusters.

30 Jul 2025

Embodied scene understanding requires not only comprehending visual-spatial information that has been observed but also determining where to explore next in the 3D physical world. Existing 3D Vision-Language (3D-VL) models primarily focus on grounding objects in static observations from 3D reconstruction, such as meshes and point clouds, but lack the ability to actively perceive and explore their environment. To address this limitation, we introduce \underline{\textbf{M}}ove \underline{\textbf{t}}o \underline{\textbf{U}}nderstand (\textbf{\model}), a unified framework that integrates active perception with \underline{\textbf{3D}} vision-language learning, enabling embodied agents to effectively explore and understand their environment. This is achieved by three key innovations: 1) Online query-based representation learning, enabling direct spatial memory construction from RGB-D frames, eliminating the need for explicit 3D reconstruction. 2) A unified objective for grounding and exploring, which represents unexplored locations as frontier queries and jointly optimizes object grounding and frontier selection. 3) End-to-end trajectory learning that combines \textbf{V}ision-\textbf{L}anguage-\textbf{E}xploration pre-training over a million diverse trajectories collected from both simulated and real-world RGB-D sequences. Extensive evaluations across various embodied navigation and question-answering benchmarks show that MTU3D outperforms state-of-the-art reinforcement learning and modular navigation approaches by 14\%, 23\%, 9\%, and 2\% in success rate on HM3D-OVON, GOAT-Bench, SG3D, and A-EQA, respectively. \model's versatility enables navigation using diverse input modalities, including categories, language descriptions, and reference images. These findings highlight the importance of bridging visual grounding and exploration for embodied intelligence.

29 Jul 2025

The AutoTIR framework enables Large Language Models to autonomously decide whether and which external tool to invoke during reasoning, leveraging a reinforcement learning approach. This method achieves superior performance across knowledge-intensive, mathematical, and open-domain instruction-following tasks, maintaining core language competencies while enhancing reasoning capabilities.

21 Jun 2025

This comprehensive survey consolidates the state-of-the-art in multi-agent embodied AI, meticulously analyzing advancements, challenges, and future directions for systems that perceive and interact with physical environments. It highlights the shift from single-agent to multi-agent complexities and the transformative role of generative models in enabling complex coordination and distributed decision-making.

14 Aug 2025

Peer review is essential for scientific progress but faces growing challenges due to increasing submission volumes and reviewer fatigue. Existing automated review approaches struggle with factual accuracy, rating consistency, and analytical depth, often generating superficial or generic feedback lacking the insights characteristic of high-quality human reviews. We introduce ReviewRL, a reinforcement learning framework for generating comprehensive and factually grounded scientific paper reviews. Our approach combines: (1) an ArXiv-MCP retrieval-augmented context generation pipeline that incorporates relevant scientific literature, (2) supervised fine-tuning that establishes foundational reviewing capabilities, and (3) a reinforcement learning procedure with a composite reward function that jointly enhances review quality and rating accuracy. Experiments on ICLR 2025 papers demonstrate that ReviewRL significantly outperforms existing methods across both rule-based metrics and model-based quality assessments. ReviewRL establishes a foundational framework for RL-driven automatic critique generation in scientific discovery, demonstrating promising potential for future development in this domain. The implementation of ReviewRL will be released at GitHub.

16 Oct 2025

Researchers developed COLA, a framework enabling humanoid robots to compliantly and coordinately carry objects with humans, leveraging a proprioception-only policy learned through a three-step training process. The system achieved a 24.7% reduction in human effort and demonstrated stable performance across diverse objects and terrains in real-world scenarios.

28 Mar 2025

The RAP framework from MMLab CUHK introduces Retrieval-Augmented Personalization for Multimodal Large Language Models (MLLMs), allowing them to remember user-specific concepts by integrating an external, dynamically editable knowledge base. This approach enables real-time personalization with high data efficiency (one image per concept) and drastically reduces the time needed to add new concepts from hours to seconds, outperforming prior fine-tuning methods in accuracy for personalized captioning, QA, and visual recognition.

20 Sep 2025




MINI-OMNI-REASONER enables large speech models to interleave internal reasoning with spoken output at the token level, creating a "thinking-in-speaking" paradigm. This framework achieves an average accuracy of 68.6% on the Spoken-MQA benchmark, outperforming baselines, while significantly reducing user-perceived response lengths by enabling immediate spoken output during silent reasoning.

30 Jun 2025


INP-Former++ introduces a unified framework for universal anomaly detection by extracting "Intrinsic Normal Prototypes" directly from test images, rather than relying on external references. This approach achieves state-of-the-art performance across diverse anomaly detection tasks, including multi-class (I-AUROC 99.8, P-AUROC 98.7 on MVTec-AD) and few-shot settings, while demonstrating high efficiency with a 99.2% reduction in attention computational cost.
There are no more papers matching your filters at the moment.
