
04 Dec 2024
Researchers at Bern University of Applied Sciences' Generative AI Lab developed a technical design integrating generative AI into art therapy, utilizing locally runnable text-to-image and inpainting models to enhance patient expression and creative adaptation. The system, demonstrated qualitatively across diverse artistic inputs, supports refining initial drafts and performing targeted modifications while prioritizing patient data privacy through local execution.

19 May 2024


Large, high-quality datasets are crucial for training Large Language Models (LLMs). However, so far, there are few datasets available for specialized critical domains such as law and the available ones are often only for the English language. We curate and release MultiLegalPile, a 689GB corpus in 24 languages from 17 jurisdictions. The MultiLegalPile corpus, which includes diverse legal data sources with varying licenses, allows for pretraining NLP models under fair use, with more permissive licenses for the Eurlex Resources and Legal mC4 subsets. We pretrain two RoBERTa models and one Longformer multilingually, and 24 monolingual models on each of the language-specific subsets and evaluate them on LEXTREME. Additionally, we evaluate the English and multilingual models on LexGLUE. Our multilingual models set a new SotA on LEXTREME and our English models on LexGLUE. We release the dataset, the trained models, and all of the code under the most open possible licenses.

24 Jun 2025


Social media platforms increasingly employ proactive moderation techniques, such as detecting and curbing toxic and uncivil comments, to prevent the spread of harmful content. Despite these efforts, such approaches are often criticized for creating a climate of censorship and failing to address the underlying causes of uncivil behavior. Our work makes both theoretical and practical contributions by proposing and evaluating two types of emotion monitoring dashboards to users' emotional awareness and mitigate hate speech. In a study involving 211 participants, we evaluate the effects of the two mechanisms on user commenting behavior and emotional experiences. The results reveal that these interventions effectively increase users' awareness of their emotional states and reduce hate speech. However, our findings also indicate potential unintended effects, including increased expression of negative emotions (Angry, Fear, and Sad) when discussing sensitive issues. These insights provide a basis for further research on integrating proactive emotion regulation tools into social media platforms to foster healthier digital interactions.

15 Oct 2020
This paper deals with different models of random walks with a reinforced
memory of preferential attachment type. We consider extensions of the Elephant
Random Walk introduced by Sch\"utz and Trimper [2004] with a stronger
reinforcement mechanism, where, roughly speaking, a step from the past is
remembered proportional to some weight and then repeated with probability .
With probability , the random walk performs a step independent of the
past. The weight of the remembered step is increased by an additive factor
, making it likelier to repeat the step again in the future. A
combination of techniques from the theory of urns, branching processes and
-stable processes enables us to discuss the limit behavior of
reinforced versions of both the Elephant Random Walk and its -stable
counterpart, the so-called Shark Random Swim introduced by Businger [2018]. We
establish phase transitions, separating subcritical from supercritical regimes.

21 Aug 2024
Recent strides in Large Language Models (LLMs) have saturated many Natural Language Processing (NLP) benchmarks, emphasizing the need for more challenging ones to properly assess LLM capabilities. However, domain-specific and multilingual benchmarks are rare because they require in-depth expertise to develop. Still, most public models are trained predominantly on English corpora, while other languages remain understudied, particularly for practical domain-specific NLP tasks. In this work, we introduce a novel NLP benchmark for the legal domain that challenges LLMs in five key dimensions: processing \emph{long documents} (up to 50K tokens), using \emph{domain-specific knowledge} (embodied in legal texts), \emph{multilingual} understanding (covering five languages), \emph{multitasking} (comprising legal document-to-document Information Retrieval, Court View Generation, Leading Decision Summarization, Citation Extraction, and eight challenging Text Classification tasks) and \emph{reasoning} (comprising especially Court View Generation, but also the Text Classification tasks). Our benchmark contains diverse datasets from the Swiss legal system, allowing for a comprehensive study of the underlying non-English, inherently multilingual legal system. Despite the large size of our datasets (some with hundreds of thousands of examples), existing publicly available multilingual models struggle with most tasks, even after extensive in-domain pre-training and fine-tuning. We publish all resources (benchmark suite, pre-trained models, code) under permissive open CC BY-SA licenses.
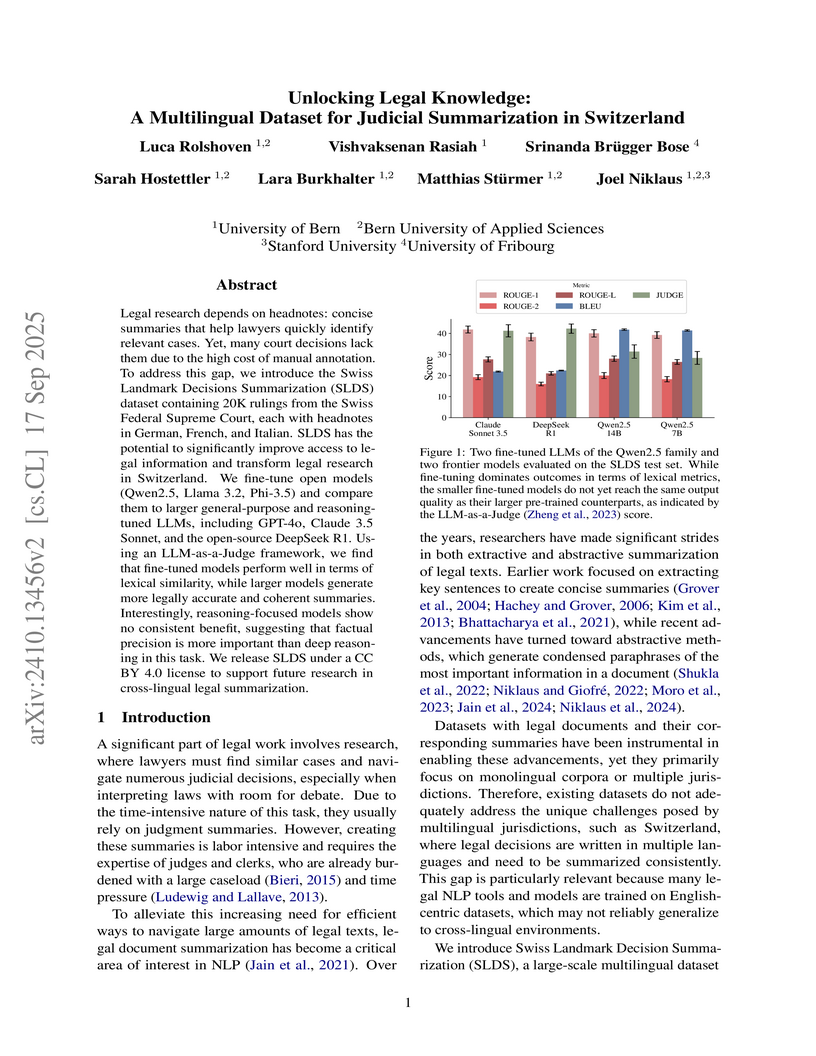
17 Sep 2025

Legal research is a time-consuming task that most lawyers face on a daily basis. A large part of legal research entails looking up relevant caselaw and bringing it in relation to the case at hand. Lawyers heavily rely on summaries (also called headnotes) to find the right cases quickly. However, not all decisions are annotated with headnotes and writing them is time-consuming. Automated headnote creation has the potential to make hundreds of thousands of decisions more accessible for legal research in Switzerland alone. To kickstart this, we introduce the Swiss Leading Decision Summarization ( SLDS) dataset, a novel cross-lingual resource featuring 18K court rulings from the Swiss Federal Supreme Court (SFSC), in German, French, and Italian, along with German headnotes. We fine-tune and evaluate three mT5 variants, along with proprietary models. Our analysis highlights that while proprietary models perform well in zero-shot and one-shot settings, fine-tuned smaller models still provide a strong competitive edge. We publicly release the dataset to facilitate further research in multilingual legal summarization and the development of assistive technologies for legal professionals

08 Feb 2025


This paper examines the functional relationship between valence and arousal and cross-cultural differences in affective expression, analyzing millions of social media posts from the United States and China. The analysis reveals a 'negativity offset' in naturalistic online expressions, contradicting traditional findings, and demonstrates that US users display higher arousal and a stronger negativity bias than Chinese users, with distinct linguistic patterns for expressing emotions.

21 Feb 2024

Wind energy plays a critical role in the transition towards renewable energy sources. However, the uncertainty and variability of wind can impede its full potential and the necessary growth of wind power capacity. To mitigate these challenges, wind power forecasting methods are employed for applications in power management, energy trading, or maintenance scheduling. In this work, we present, evaluate, and compare four machine learning-based wind power forecasting models. Our models correct and improve 48-hour forecasts extracted from a numerical weather prediction (NWP) model. The models are evaluated on datasets from a wind park comprising 65 wind turbines. The best improvement in forecasting error and mean bias was achieved by a convolutional neural network, reducing the average NRMSE down to 22%, coupled with a significant reduction in mean bias, compared to a NRMSE of 35% from the strongly biased baseline model using uncorrected NWP forecasts. Our findings further indicate that changes to neural network architectures play a minor role in affecting the forecasting performance, and that future research should rather investigate changes in the model pipeline. Moreover, we introduce a continuous learning strategy, which is shown to achieve the highest forecasting performance improvements when new data is made available.

20 May 2025
 Imperial College LondonUniversity of BonnGerman Research Center for Artificial Intelligence (DFKI)
Imperial College LondonUniversity of BonnGerman Research Center for Artificial Intelligence (DFKI) University of Wisconsin-MadisonOsnabrück UniversityThe University of SydneyUniversity of TübingenTokyo University of Agriculture and TechnologyINRAEIRDAgroScopeUniversity of São Paulo (USP)Woodwell Climate Research CenterFederal Technological University of ParanáFederal University of Mato GrossoUniversity of RostockFederal University of ViçosaBern University of Applied SciencesLeibniz Centre for Agricultural Landscape Research (ZALF)Mendel University in BrnoNorwegian Institute of Bioeconomy Research (NIBIO)Swedish University of Agricultural Sciences (SLU)Federal University of Santa Maria (UFSM)BÜCHI Labortechnik AGFederal University of JataíEberswalde University for Sustainable DevelopmentLeibniz Institute for Agricultural Engineering and Bioeconomy (ATB)Leibniz Institute of Vegetable and Ornamental CropsL'Institut Agro
University of Wisconsin-MadisonOsnabrück UniversityThe University of SydneyUniversity of TübingenTokyo University of Agriculture and TechnologyINRAEIRDAgroScopeUniversity of São Paulo (USP)Woodwell Climate Research CenterFederal Technological University of ParanáFederal University of Mato GrossoUniversity of RostockFederal University of ViçosaBern University of Applied SciencesLeibniz Centre for Agricultural Landscape Research (ZALF)Mendel University in BrnoNorwegian Institute of Bioeconomy Research (NIBIO)Swedish University of Agricultural Sciences (SLU)Federal University of Santa Maria (UFSM)BÜCHI Labortechnik AGFederal University of JataíEberswalde University for Sustainable DevelopmentLeibniz Institute for Agricultural Engineering and Bioeconomy (ATB)Leibniz Institute of Vegetable and Ornamental CropsL'Institut AgroDigital soil mapping (DSM) relies on a broad pool of statistical methods, yet
determining the optimal method for a given context remains challenging and
contentious. Benchmarking studies on multiple datasets are needed to reveal
strengths and limitations of commonly used methods. Existing DSM studies
usually rely on a single dataset with restricted access, leading to incomplete
and potentially misleading conclusions. To address these issues, we introduce
an open-access dataset collection called Precision Liming Soil Datasets
(LimeSoDa). LimeSoDa consists of 31 field- and farm-scale datasets from various
countries. Each dataset has three target soil properties: (1) soil organic
matter or soil organic carbon, (2) clay content and (3) pH, alongside a set of
features. Features are dataset-specific and were obtained by optical
spectroscopy, proximal- and remote soil sensing. All datasets were aligned to a
tabular format and are ready-to-use for modeling. We demonstrated the use of
LimeSoDa for benchmarking by comparing the predictive performance of four
learning algorithms across all datasets. This comparison included multiple
linear regression (MLR), support vector regression (SVR), categorical boosting
(CatBoost) and random forest (RF). The results showed that although no single
algorithm was universally superior, certain algorithms performed better in
specific contexts. MLR and SVR performed better on high-dimensional spectral
datasets, likely due to better compatibility with principal components. In
contrast, CatBoost and RF exhibited considerably better performances when
applied to datasets with a moderate number (< 20) of features. These
benchmarking results illustrate that the performance of a method is highly
context-dependent. LimeSoDa therefore provides an important resource for
improving the development and evaluation of statistical methods in DSM.

24 Apr 2025
Intelligent condition monitoring of wind turbines is essential for reducing
downtimes. Machine learning models trained on wind turbine operation data are
commonly used to detect anomalies and, eventually, operation faults. However,
data-driven normal behavior models (NBMs) require a substantial amount of
training data, as NBMs trained with scarce data may result in unreliable fault
diagnosis. To overcome this limitation, we present a novel generative deep
learning approach to make SCADA samples from one wind turbine lacking training
data resemble SCADA data from wind turbines with representative training data.
Through CycleGAN-based domain mapping, our method enables the application of an
NBM trained on an existing wind turbine to one with severely limited data. We
demonstrate our approach on field data mapping SCADA samples across 7
substantially different WTs. Our findings show significantly improved fault
diagnosis in wind turbines with scarce data. Our method achieves the most
similar anomaly scores to an NBM trained with abundant data, outperforming NBMs
trained on scarce training data with improvements of +10.3% in F1-score when 1
month of training data is available and +16.8% when 2 weeks are available. The
domain mapping approach outperforms conventional fine-tuning at all considered
degrees of data scarcity, ranging from 1 to 8 weeks of training data. The
proposed technique enables earlier and more reliable fault diagnosis in newly
installed wind farms, demonstrating a novel and promising research direction to
improve anomaly detection when faced with training data scarcity.

26 Jul 2024
The project BIAS: Mitigating Diversity Biases of AI in the Labor Market is a four-year project funded by the European commission and supported by the Swiss State Secretariat for Education, Research and Innovation (SERI). As part of the project, novel bias detection methods to identify societal bias in language models and word embeddings in European languages are developed, with particular attention to linguistic and geographic particularities. This technical report describes the overall architecture and components of the BIAS Detection Framework. The code described in this technical report is available and will be updated and expanded continuously with upcoming results from the BIAS project. The details about the datasets for the different languages are described in corresponding papers at scientific venues.

26 Feb 2024

The assessment of explainability in Legal Judgement Prediction (LJP) systems is of paramount importance in building trustworthy and transparent systems, particularly considering the reliance of these systems on factors that may lack legal relevance or involve sensitive attributes. This study delves into the realm of explainability and fairness in LJP models, utilizing Swiss Judgement Prediction (SJP), the only available multilingual LJP dataset. We curate a comprehensive collection of rationales that `support' and `oppose' judgement from legal experts for 108 cases in German, French, and Italian. By employing an occlusion-based explainability approach, we evaluate the explainability performance of state-of-the-art monolingual and multilingual BERT-based LJP models, as well as models developed with techniques such as data augmentation and cross-lingual transfer, which demonstrated prediction performance improvement. Notably, our findings reveal that improved prediction performance does not necessarily correspond to enhanced explainability performance, underscoring the significance of evaluating models from an explainability perspective. Additionally, we introduce a novel evaluation framework, Lower Court Insertion (LCI), which allows us to quantify the influence of lower court information on model predictions, exposing current models' biases.

30 May 2025
Many court systems are overwhelmed all over the world, leading to huge
backlogs of pending cases. Effective triage systems, like those in emergency
rooms, could ensure proper prioritization of open cases, optimizing time and
resource allocation in the court system. In this work, we introduce the
Criticality Prediction dataset, a novel resource for evaluating case
prioritization. Our dataset features a two-tier labeling system: (1) the binary
LD-Label, identifying cases published as Leading Decisions (LD), and (2) the
more granular Citation-Label, ranking cases by their citation frequency and
recency, allowing for a more nuanced evaluation. Unlike existing approaches
that rely on resource-intensive manual annotations, we algorithmically derive
labels leading to a much larger dataset than otherwise possible. We evaluate
several multilingual models, including both smaller fine-tuned models and large
language models in a zero-shot setting. Our results show that the fine-tuned
models consistently outperform their larger counterparts, thanks to our large
training set. Our results highlight that for highly domain-specific tasks like
ours, large training sets are still valuable.

12 Jul 2023
Terabytes of data are collected by wind turbine manufacturers from their fleets every day. And yet, a lack of data access and sharing impedes exploiting the full potential of the data. We present a distributed machine learning approach that preserves the data privacy by leaving the data on the wind turbines while still enabling fleet-wide learning on those local data. We show that through federated fleet-wide learning, turbines with little or no representative training data can benefit from more accurate normal behavior models. Customizing the global federated model to individual turbines yields the highest fault detection accuracy in cases where the monitored target variable is distributed heterogeneously across the fleet. We demonstrate this for bearing temperatures, a target variable whose normal behavior can vary widely depending on the turbine. We show that no turbine experiences a loss in model performance from participating in the federated learning process, resulting in superior performance of the federated learning strategy in our case studies. The distributed learning increases the normal behavior model training times by about a factor of ten due to increased communication overhead and slower model convergence.

16 Aug 2023
Optimal packing of objects in containers is a critical problem in various real-life and industrial applications. This paper investigates the two-dimensional packing of convex polygons without rotations, where only translations are allowed. We study different settings depending on the type of containers used, including minimizing the number of containers or the size of the container based on an objective function.
Building on prior research in the field, we develop polynomial-time algorithms with improved approximation guarantees upon the best-known results by Alt, de Berg and Knauer, as well as Aamand, Abrahamsen, Beretta and Kleist, for problems such as Polygon Area Minimization, Polygon Perimeter Minimization, Polygon Strip Packing, and Polygon Bin Packing. Our approach utilizes a sequence of object transformations that allows sorting by height and orientation, thus enhancing the effectiveness of shelf packing algorithms for polygon packing problems. In addition, we present efficient approximation algorithms for special cases of the Polygon Bin Packing problem, progressing toward solving an open question concerning an O(1)-approximation algorithm for arbitrary polygons.

22 Sep 2024
Burnout, classified as a syndrome in the ICD-11, arises from chronic workplace stress that has not been effectively managed. It is characterized by exhaustion, cynicism, and reduced professional efficacy, and estimates of its prevalence vary significantly due to inconsistent measurement methods. Recent advancements in Natural Language Processing (NLP) and machine learning offer promising tools for detecting burnout through textual data analysis, with studies demonstrating high predictive accuracy. This paper contributes to burnout detection in German texts by: (a) collecting an anonymous real-world dataset including free-text answers and Oldenburg Burnout Inventory (OLBI) responses; (b) demonstrating the limitations of a GermanBERT-based classifier trained on online data; (c) presenting two versions of a curated BurnoutExpressions dataset, which yielded models that perform well in real-world applications; and (d) providing qualitative insights from an interdisciplinary focus group on the interpretability of AI models used for burnout detection. Our findings emphasize the need for greater collaboration between AI researchers and clinical experts to refine burnout detection models. Additionally, more real-world data is essential to validate and enhance the effectiveness of current AI methods developed in NLP research, which are often based on data automatically scraped from online sources and not evaluated in a real-world context. This is essential for ensuring AI tools are well suited for practical applications.

06 Jan 2020
We extend the classical one-parameter Yule-Simon law to a version depending
on two parameters, which in part appeared in Bertoin [2019] in the context of a
preferential attachment algorithm with fading memory. By making the link to a
general branching process with age-dependent reproduction rate, we study the
tail-asymptotic behavior of the two-parameter Yule-Simon law, as it was already
initiated in the mentioned paper. Finally, by superposing mutations to the
branching process, we propose a model which leads to the full two-parameter
range of the Yule-Simon law, generalizing thereby the work of Simon [1955] on
limiting word frequencies.

08 Jan 2024
Lately, propelled by the phenomenal advances around the transformer architecture, the legal NLP field has enjoyed spectacular growth. To measure progress, well curated and challenging benchmarks are crucial. However, most benchmarks are English only and in legal NLP specifically there is no multilingual benchmark available yet. Additionally, many benchmarks are saturated, with the best models clearly outperforming the best humans and achieving near perfect scores. We survey the legal NLP literature and select 11 datasets covering 24 languages, creating LEXTREME. To provide a fair comparison, we propose two aggregate scores, one based on the datasets and one on the languages. The best baseline (XLM-R large) achieves both a dataset aggregate score a language aggregate score of 61.3. This indicates that LEXTREME is still very challenging and leaves ample room for improvement. To make it easy for researchers and practitioners to use, we release LEXTREME on huggingface together with all the code required to evaluate models and a public Weights and Biases project with all the runs.

20 May 2016

Convolutional neural networks (CNN) have achieved major breakthroughs in
recent years. Their performance in computer vision have matched and in some
areas even surpassed human capabilities. Deep neural networks can capture
complex non-linear features; however this ability comes at the cost of high
computational and memory requirements. State-of-art networks require billions
of arithmetic operations and millions of parameters. To enable embedded devices
such as smartphones, Google glasses and monitoring cameras with the astonishing
power of deep learning, dedicated hardware accelerators can be used to decrease
both execution time and power consumption. In applications where fast
connection to the cloud is not guaranteed or where privacy is important,
computation needs to be done locally. Many hardware accelerators for deep
neural networks have been proposed recently. A first important step of
accelerator design is hardware-oriented approximation of deep networks, which
enables energy-efficient inference. We present Ristretto, a fast and automated
framework for CNN approximation. Ristretto simulates the hardware arithmetic of
a custom hardware accelerator. The framework reduces the bit-width of network
parameters and outputs of resource-intense layers, which reduces the chip area
for multiplication units significantly. Alternatively, Ristretto can remove the
need for multipliers altogether, resulting in an adder-only arithmetic. The
tool fine-tunes trimmed networks to achieve high classification accuracy. Since
training of deep neural networks can be time-consuming, Ristretto uses highly
optimized routines which run on the GPU. This enables fast compression of any
given network. Given a maximum tolerance of 1%, Ristretto can successfully
condense CaffeNet and SqueezeNet to 8-bit. The code for Ristretto is available.

28 Oct 2024
Studying bias detection and mitigation methods in natural language processing and the particular case of machine translation is highly relevant, as societal stereotypes might be reflected or reinforced by these systems. In this paper, we analyze the state-of-the-art with a particular focus on European and African languages. We show how the majority of the work in this field concentrates on few languages, and that there is potential for future research to cover also the less investigated languages to contribute to more diversity in the research field.
There are no more papers matching your filters at the moment.
