
07 Aug 2025
We introduce Action Discovery, a novel setup within Temporal Action Segmentation that addresses the challenge of defining and annotating ambiguous actions and incomplete annotations in partially labeled datasets. In this setup, only a subset of actions - referred to as known actions - is annotated in the training data, while other unknown actions remain unlabeled. This scenario is particularly relevant in domains like neuroscience, where well-defined behaviors (e.g., walking, eating) coexist with subtle or infrequent actions that are often overlooked, as well as in applications where datasets are inherently partially annotated due to ambiguous or missing labels. To address this problem, we propose a two-step approach that leverages the known annotations to guide both the temporal and semantic granularity of unknown action segments. First, we introduce the Granularity-Guided Segmentation Module (GGSM), which identifies temporal intervals for both known and unknown actions by mimicking the granularity of annotated actions. Second, we propose the Unknown Action Segment Assignment (UASA), which identifies semantically meaningful classes within the unknown actions, based on learned embedding similarities. We systematically explore the proposed setting of Action Discovery on three challenging datasets - Breakfast, 50Salads, and Desktop Assembly - demonstrating that our method considerably improves upon existing baselines.

26 Sep 2025


Mainstream large vision-language models (LVLMs) inherently encode cultural biases, highlighting the need for diverse multimodal datasets. To address this gap, we introduce PEARL, a large-scale Arabic multimodal dataset and benchmark explicitly designed for cultural understanding. Constructed through advanced agentic workflows and extensive human-in-the-loop annotations by 37 annotators from across the Arab world, PEARL comprises over 309K multimodal examples spanning ten culturally significant domains covering all Arab countries. We further provide two robust evaluation benchmarks (PEARL and PEARL-LITE) along with a specialized subset (PEARL-X) explicitly developed to assess nuanced cultural variations. Comprehensive evaluations on state-of-the-art open and proprietary LVLMs demonstrate that reasoning-centric instruction alignment substantially improves models' cultural grounding compared to conventional scaling methods. PEARL establishes a foundational resource for advancing culturally-informed multimodal modeling research. All datasets and benchmarks are publicly available.

06 Oct 2024


The Casablanca project introduces the first large-scale, fully supervised multidialectal Arabic speech dataset, comprising 48 hours of transcribed speech across eight distinct dialects. This resource aims to enable the development of more inclusive and effective speech technologies for diverse Arabic speakers, particularly for previously unrepresented dialects like Emirati, Yemeni, and Mauritanian.

18 Jul 2025

Large Language Models (LLMs) are transforming cybersecurity by enabling intelligent, adaptive, and automated approaches to threat detection, vulnerability assessment, and incident response. With their advanced language understanding and contextual reasoning, LLMs surpass traditional methods in tackling challenges across domains such as IoT, blockchain, and hardware security. This survey provides a comprehensive overview of LLM applications in cybersecurity, focusing on two core areas: (1) the integration of LLMs into key cybersecurity domains, and (2) the vulnerabilities of LLMs themselves, along with mitigation strategies. By synthesizing recent advancements and identifying key limitations, this work offers practical insights and strategic recommendations for leveraging LLMs to build secure, scalable, and future-ready cyber defense systems.

15 Oct 2023
The use of credit cards has recently increased, creating an essential need for credit card assessment methods to minimize potential risks. This study investigates the utilization of machine learning (ML) models for credit card default prediction system. The main goal here is to investigate the best-performing ML model for new proposed credit card scoring dataset. This new dataset includes credit card transaction histories and customer profiles, is proposed and tested using a variety of machine learning algorithms, including logistic regression, decision trees, random forests, multi-layer perceptron (MLP) neural network, XGBoost, and LightGBM. To prepare the data for machine learning models, we perform data pre-processing, feature extraction, feature selection, and data balancing techniques. Experimental results demonstrate that MLP outperforms logistic regression, decision trees, random forests, LightGBM, and XGBoost in terms of predictive performance in true positive rate, achieving an impressive area under the curve (AUC) of 86.7% and an accuracy rate of 91.6%, with a recall rate exceeding 80%. These results indicate the superiority of MLP in predicting the default customers and assessing the potential risks. Furthermore, they help banks and other financial institutions in predicting loan defaults at an earlier stage.
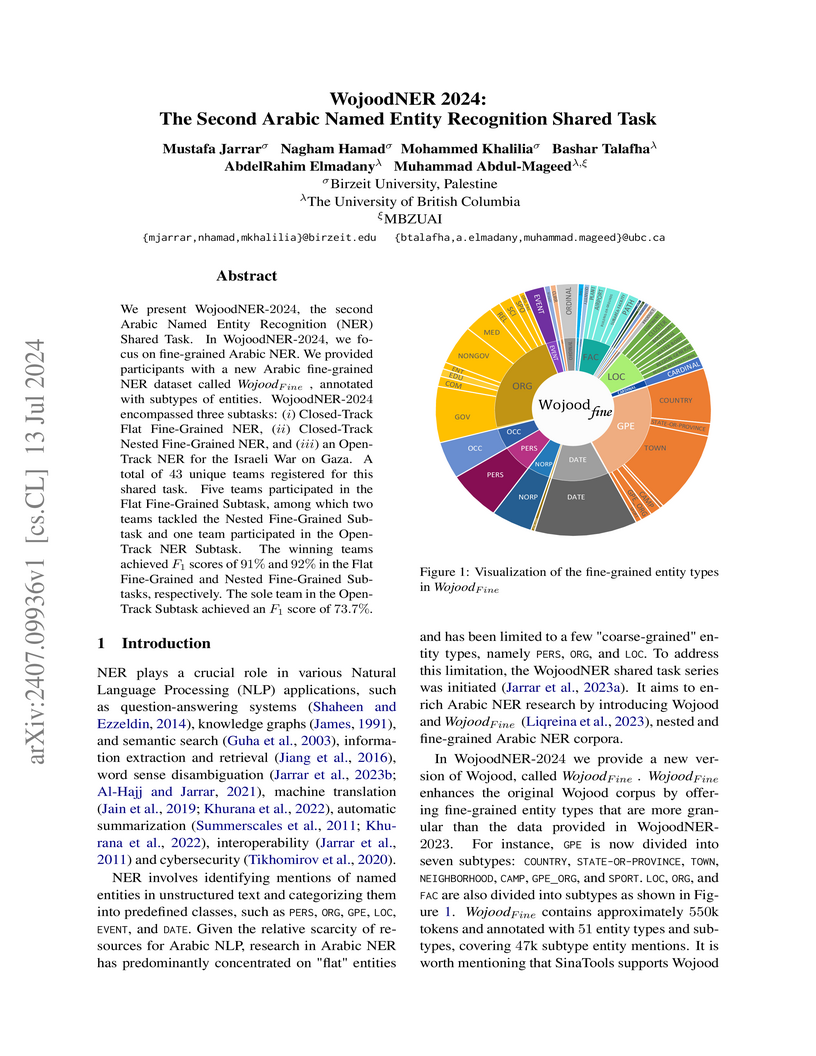
13 Jul 2024
We present WojoodNER-2024, the second Arabic Named Entity Recognition (NER) Shared Task. In WojoodNER-2024, we focus on fine-grained Arabic NER. We provided participants with a new Arabic fine-grained NER dataset called wojoodfine, annotated with subtypes of entities. WojoodNER-2024 encompassed three subtasks: (i) Closed-Track Flat Fine-Grained NER, (ii) Closed-Track Nested Fine-Grained NER, and (iii) an Open-Track NER for the Israeli War on Gaza. A total of 43 unique teams registered for this shared task. Five teams participated in the Flat Fine-Grained Subtask, among which two teams tackled the Nested Fine-Grained Subtask and one team participated in the Open-Track NER Subtask. The winning teams achieved F-1 scores of 91% and 92% in the Flat Fine-Grained and Nested Fine-Grained Subtasks, respectively. The sole team in the Open-Track Subtask achieved an F-1 score of 73.7%.

21 Mar 2025
Long-term dense action anticipation is very challenging since it requires
predicting actions and their durations several minutes into the future based on
provided video observations. To model the uncertainty of future outcomes,
stochastic models predict several potential future action sequences for the
same observation. Recent work has further proposed to incorporate uncertainty
modelling for observed frames by simultaneously predicting per-frame past and
future actions in a unified manner. While such joint modelling of actions is
beneficial, it requires long-range temporal capabilities to connect events
across distant past and future time points. However, the previous work
struggles to achieve such a long-range understanding due to its limited and/or
sparse receptive field. To alleviate this issue, we propose a novel MANTA
(MAmba for ANTicipation) network. Our model enables effective long-term
temporal modelling even for very long sequences while maintaining linear
complexity in sequence length. We demonstrate that our approach achieves
state-of-the-art results on three datasets - Breakfast, 50Salads, and
Assembly101 - while also significantly improving computational and memory
efficiency. Our code is available at this https URL .

24 Jul 2025
As large language models (LLMs) become increasingly integrated into daily life, ensuring their cultural sensitivity and inclusivity is paramount. We introduce our dataset, a year-long community-driven project covering all 22 Arab countries. The dataset includes instructions (input, response pairs) in both Modern Standard Arabic (MSA) and dialectal Arabic (DA), spanning 20 diverse topics. Built by a team of 44 researchers across the Arab world, all of whom are authors of this paper, our dataset offers a broad, inclusive perspective. We use our dataset to evaluate the cultural and dialectal capabilities of several frontier LLMs, revealing notable limitations. For instance, while closed-source LLMs generally exhibit strong performance, they are not without flaws, and smaller open-source models face greater challenges. Moreover, certain countries (e.g., Egypt, the UAE) appear better represented than others (e.g., Iraq, Mauritania, Yemen). Our annotation guidelines, code, and data for reproducibility are publicly available.

03 Feb 2025
Researchers performed a multi-language, multi-model analysis of code generated by five prominent Large Language Models, revealing varying security and quality attributes across C, C++, Java, and Python. The study identified language-specific vulnerability patterns, such as memory management issues in C/C++ and cryptographic weaknesses in Java/Python, while noting LLMs' inconsistent adoption of modern secure coding practices.

12 Jul 2024
The proliferation of bias and propaganda on social media is an increasingly significant concern, leading to the development of techniques for automatic detection. This article presents a multilingual corpus of 12, 000 Facebook posts fully annotated for bias and propaganda. The corpus was created as part of the FigNews 2024 Shared Task on News Media Narratives for framing the Israeli War on Gaza. It covers various events during the War from October 7, 2023 to January 31, 2024. The corpus comprises 12, 000 posts in five languages (Arabic, Hebrew, English, French, and Hindi), with 2, 400 posts for each language. The annotation process involved 10 graduate students specializing in Law. The Inter-Annotator Agreement (IAA) was used to evaluate the annotations of the corpus, with an average IAA of 80.8% for bias and 70.15% for propaganda annotations. Our team was ranked among the bestperforming teams in both Bias and Propaganda subtasks. The corpus is open-source and available at this https URL

03 Sep 2025

We present the findings of the sixth Nuanced Arabic Dialect Identification (NADI 2025) Shared Task, which focused on Arabic speech dialect processing across three subtasks: spoken dialect identification (Subtask 1), speech recognition (Subtask 2), and diacritic restoration for spoken dialects (Subtask 3). A total of 44 teams registered, and during the testing phase, 100 valid submissions were received from eight unique teams. The distribution was as follows: 34 submissions for Subtask 1 "five teamsæ, 47 submissions for Subtask 2 "six teams", and 19 submissions for Subtask 3 "two teams". The best-performing systems achieved 79.8% accuracy on Subtask 1, 35.68/12.20 WER/CER (overall average) on Subtask 2, and 55/13 WER/CER on Subtask 3. These results highlight the ongoing challenges of Arabic dialect speech processing, particularly in dialect identification, recognition, and diacritic restoration. We also summarize the methods adopted by participating teams and briefly outline directions for future editions of NADI.

22 Jun 2025
We present the QuranMorph corpus, a morphologically annotated corpus for the Quran (77,429 tokens). Each token in the QuranMorph was manually lemmatized and tagged with its part-of-speech by three expert linguists. The lemmatization process utilized lemmas from Qabas, an Arabic lexicographic database linked with 110 lexicons and corpora of 2 million tokens. The part-of-speech tagging was performed using the fine-grained SAMA/Qabas tagset, which encompasses 40 tags. As shown in this paper, this rich lemmatization and POS tagset enabled the QuranMorph corpus to be inter-linked with many linguistic resources. The corpus is open-source and publicly available as part of the SinaLab resources at (this https URL)

06 Jun 2024
We present Qabas, a novel open-source Arabic lexicon designed for NLP
applications. The novelty of Qabas lies in its synthesis of 110 lexicons.
Specifically, Qabas lexical entries (lemmas) are assembled by linking lemmas
from 110 lexicons. Furthermore, Qabas lemmas are also linked to 12
morphologically annotated corpora (about 2M tokens), making it the first Arabic
lexicon to be linked to lexicons and corpora. Qabas was developed
semi-automatically, utilizing a mapping framework and a web-based tool.
Compared with other lexicons, Qabas stands as the most extensive Arabic
lexicon, encompassing about 58K lemmas (45K nominal lemmas, 12.5K verbal
lemmas, and 473 functional-word lemmas). Qabas is open-source and accessible
online at this https URL

12 Jul 2024
Counting repetitive actions in long untrimmed videos is a challenging task
that has many applications such as rehabilitation. State-of-the-art methods
predict action counts by first generating a temporal self-similarity matrix
(TSM) from the sampled frames and then feeding the matrix to a predictor
network. The self-similarity matrix, however, is not an optimal input to a
network since it discards too much information from the frame-wise embeddings.
We thus rethink how a TSM can be utilized for counting repetitive actions and
propose a framework that learns embeddings and predicts action start
probabilities at full temporal resolution. The number of repeated actions is
then inferred from the action start probabilities. In contrast to current
approaches that have the TSM as an intermediate representation, we propose a
novel loss based on a generated reference TSM, which enforces that the
self-similarity of the learned frame-wise embeddings is consistent with the
self-similarity of repeated actions. The proposed framework achieves
state-of-the-art results on three datasets, i.e., RepCount, UCFRep, and
Countix.

03 Dec 2023
The Internet is used by billions of users every day because it offers fast
and free communication tools and platforms. Nevertheless, with this significant
increase in usage, huge amounts of spam are generated every second, which
wastes internet resources and, more importantly, users' time. This study
investigates the use of machine learning models to classify URLs as spam or
nonspam. We first extract the features from the URL as it has only one feature,
and then we compare the performance of several models, including k nearest
neighbors, bagging, random forest, logistic regression, and others.
Experimental results demonstrate that bagging outperformed other models and
achieved the highest accuracy of 98.64%. In addition, bagging outperformed the
current state-of-the-art approaches which emphasize its effectiveness in
addressing spam-related challenges on the Internet. This suggests that bagging
is a promising approach for URL spam classification.

19 May 2022
The processing of the Arabic language is a complex field of research. This is due to many factors, including the complex and rich morphology of Arabic, its high degree of ambiguity, and the presence of several regional varieties that need to be processed while taking into account their unique characteristics. When its dialects are taken into account, this language pushes the limits of NLP to find solutions to problems posed by its inherent nature. It is a diglossic language; the standard language is used in formal settings and in education and is quite different from the vernacular languages spoken in the different regions and influenced by older languages that were historically spoken in those regions. This should encourage NLP specialists to create dialect-specific corpora such as the Palestinian morphologically annotated Curras corpus of Birzeit University. In this work, we present the Lebanese Corpus Baladi that consists of around 9.6K morphologically annotated tokens. Since Lebanese and Palestinian dialects are part of the same Levantine dialectal continuum, and thus highly mutually intelligible, our proposed corpus was constructed to be used to (1) enrich Curras and transform it into a more general Levantine corpus and (2) improve Curras by solving detected errors.

14 Jun 2025
We introduce Konooz, a novel multi-dimensional corpus covering 16 Arabic
dialects across 10 domains, resulting in 160 distinct corpora. The corpus
comprises about 777k tokens, carefully collected and manually annotated with 21
entity types using both nested and flat annotation schemes - using the Wojood
guidelines. While Konooz is useful for various NLP tasks like domain adaptation
and transfer learning, this paper primarily focuses on benchmarking existing
Arabic Named Entity Recognition (NER) models, especially cross-domain and
cross-dialect model performance. Our benchmarking of four Arabic NER models
using Konooz reveals a significant drop in performance of up to 38% when
compared to the in-distribution data. Furthermore, we present an in-depth
analysis of domain and dialect divergence and the impact of resource scarcity.
We also measured the overlap between domains and dialects using the Maximum
Mean Discrepancy (MMD) metric, and illustrated why certain NER models perform
better on specific dialects and domains. Konooz is open-source and publicly
available at this https URL

06 Sep 2023
Offensive language detection has been well studied in many languages, but it is lagging behind in low-resource languages, such as Hebrew. In this paper, we present a new offensive language corpus in Hebrew. A total of 15,881 tweets were retrieved from Twitter. Each was labeled with one or more of five classes (abusive, hate, violence, pornographic, or none offensive) by Arabic-Hebrew bilingual speakers. The annotation process was challenging as each annotator is expected to be familiar with the Israeli culture, politics, and practices to understand the context of each tweet. We fine-tuned two Hebrew BERT models, HeBERT and AlephBERT, using our proposed dataset and another published dataset. We observed that our data boosts HeBERT performance by 2% when combined with D_OLaH. Fine-tuning AlephBERT on our data and testing on D_OLaH yields 69% accuracy, while fine-tuning on D_OLaH and testing on our data yields 57% accuracy, which may be an indication to the generalizability our data offers. Our dataset and fine-tuned models are available on GitHub and Huggingface.

19 May 2022
Using pre-trained transformer models such as BERT has proven to be effective
in many NLP tasks. This paper presents our work to fine-tune BERT models for
Arabic Word Sense Disambiguation (WSD). We treated the WSD task as a
sentence-pair binary classification task. First, we constructed a dataset of
labeled Arabic context-gloss pairs (~167k pairs) we extracted from the Arabic
Ontology and the large lexicographic database available at Birzeit University.
Each pair was labeled as True or False and target words in each context were
identified and annotated. Second, we used this dataset for fine-tuning three
pre-trained Arabic BERT models. Third, we experimented the use of different
supervised signals used to emphasize target words in context. Our experiments
achieved promising results (accuracy of 84%) although we used a large set of
senses in the experiment.
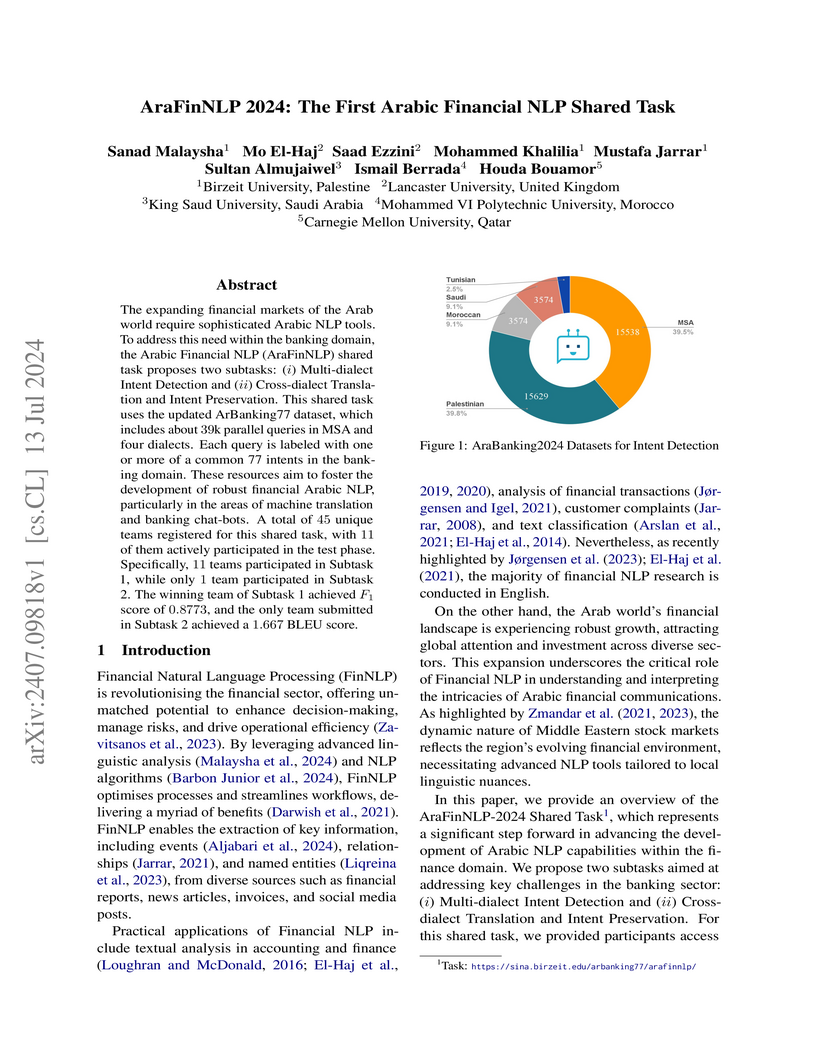
13 Jul 2024

The expanding financial markets of the Arab world require sophisticated Arabic NLP tools. To address this need within the banking domain, the Arabic Financial NLP (AraFinNLP) shared task proposes two subtasks: (i) Multi-dialect Intent Detection and (ii) Cross-dialect Translation and Intent Preservation. This shared task uses the updated ArBanking77 dataset, which includes about 39k parallel queries in MSA and four dialects. Each query is labeled with one or more of a common 77 intents in the banking domain. These resources aim to foster the development of robust financial Arabic NLP, particularly in the areas of machine translation and banking chat-bots. A total of 45 unique teams registered for this shared task, with 11 of them actively participated in the test phase. Specifically, 11 teams participated in Subtask 1, while only 1 team participated in Subtask 2. The winning team of Subtask 1 achieved F1 score of 0.8773, and the only team submitted in Subtask 2 achieved a 1.667 BLEU score.
There are no more papers matching your filters at the moment.
