14 Jul 2025


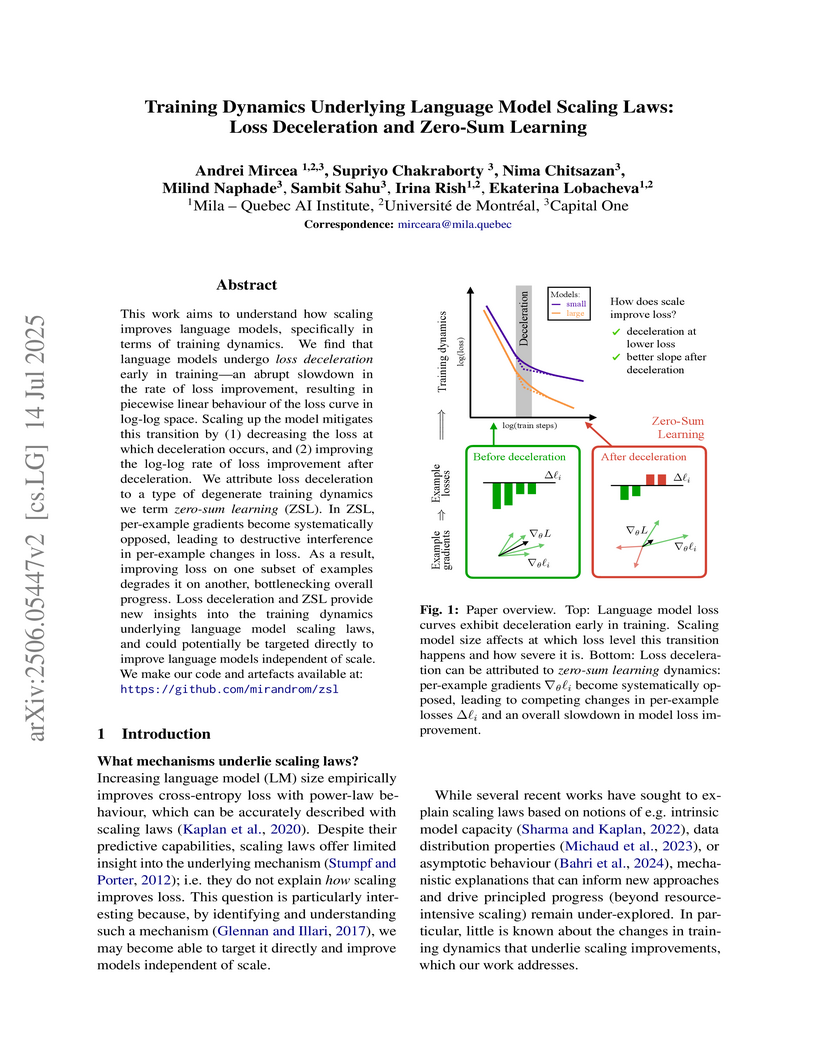
Investigating training dynamics, the paper uncovers "loss deceleration" as a universal phenomenon in language model training, mechanistically attributing it to "zero-sum learning" (ZSL) where per-example gradients destructively interfere. Scaling up models improves performance by mitigating ZSL, leading to lower loss at the onset of deceleration and faster improvement rates afterward.

23 Oct 2025
Researchers from Capital One introduced T1, a tool-oriented conversational dataset and evaluation framework designed to benchmark large language model (LLM) agents on complex multi-turn, multi-domain planning tasks with interdependent tool calls and dynamic replanning. The framework incorporates a caching mechanism and reveals that supervised fine-tuning significantly boosts performance for smaller LLMs, allowing a Llama 3.1 8B Instruct SFT model to surpass a larger 70B model in Tool Call F1 score.

21 Sep 2025


An entropy-enhanced multi-turn preference optimization framework, ENTROPO, enables coding agents to maintain diverse problem-solving strategies, which, when combined with test-time scaling, achieves state-of-the-art performance on SWEBENCH benchmarks.

21 Oct 2025
Guided Pivotal Optimization (GPO) enhances large language models' multi-step reasoning by identifying and prioritizing learning from critical intermediate steps within a generated reasoning trajectory. This strategy consistently improves performance across various reasoning benchmarks and fine-tuning algorithms, demonstrating strong alignment with human judgment.

01 Oct 2025



MR3 is a multilingual, rubric-agnostic reward reasoning model designed to evaluate Large Language Model outputs with explicit reasoning and scalar scores across 72 languages. The model achieved an average accuracy of 84.94% on multilingual pairwise preference benchmarks, surpassing its 9x larger teacher model (GPT-OSS-120B) by +0.87 points, and demonstrated improved reasoning faithfulness, particularly in low-resource languages.

06 Oct 2025


The DynaGuard framework, developed by the University of Maryland and Capital One, introduces a dynamic guardian model capable of enforcing user-defined, application-specific policies for Large Language Models. It achieved state-of-the-art F1 scores across various benchmarks and demonstrated effective LLM self-correction, improving instruction-following accuracy from 57.3% to 63.8% in a case study.

07 Nov 2025
Researchers from the University of Maryland, Dolby Laboratories, and Capital One developed VisAlign, a method that refines textual embeddings with global visual context in Large Vision-Language Models to balance multimodal attention. This approach reduced hallucinations, achieving a +9.33% accuracy increase on the MMVP-MLLM benchmark and an average +3% improvement on the HallusionBench hard-data split.

08 May 2025

Experimental analysis reveals that English-centric reasoning language models can effectively perform multilingual reasoning through test-time scaling and exhibits a "quote-and-think" pattern where models quote non-English text while reasoning in English, achieving strong performance on the MGSM benchmark while highlighting limitations for low-resource languages and non-STEM domains.

19 Sep 2025


Reward models are essential for aligning language model outputs with human preferences, yet existing approaches often lack both controllability and interpretability. These models are typically optimized for narrow objectives, limiting their generalizability to broader downstream tasks. Moreover, their scalar outputs are difficult to interpret without contextual reasoning. To address these limitations, we introduce , a novel reward modeling framework that is rubric-agnostic, generalizable across evaluation dimensions, and provides interpretable, reasoned score assignments. enables more transparent and flexible evaluation of language models, supporting robust alignment with diverse human values and use cases. Our models, data, and code are available as open source at this https URL.

23 Oct 2025


Uncertainty Quantification (UQ) research has primarily focused on closed-book factual question answering (QA), while contextual QA remains unexplored, despite its importance in real-world applications. In this work, we focus on UQ for the contextual QA task and propose a theoretically grounded approach to quantify epistemic uncertainty. We begin by introducing a task-agnostic, token-level uncertainty measure defined as the cross-entropy between the predictive distribution of the given model and the unknown true distribution. By decomposing this measure, we isolate the epistemic component and approximate the true distribution by a perfectly prompted, idealized model. We then derive an upper bound for epistemic uncertainty and show that it can be interpreted as semantic feature gaps in the given model's hidden representations relative to the ideal model. We further apply this generic framework to the contextual QA task and hypothesize that three features approximate this gap: context-reliance (using the provided context rather than parametric knowledge), context comprehension (extracting relevant information from context), and honesty (avoiding intentional lies). Using a top-down interpretability approach, we extract these features by using only a small number of labeled samples and ensemble them to form a robust uncertainty score. Experiments on multiple QA benchmarks in both in-distribution and out-of-distribution settings show that our method substantially outperforms state-of-the-art unsupervised (sampling-free and sampling-based) and supervised UQ methods, achieving up to a 13-point PRR improvement while incurring a negligible inference overhead.

01 Dec 2025
Fine-tuning large language models (LLMs) on chain-of-thought (CoT) data shows that a small amount of high-quality data can outperform massive datasets. Yet, what constitutes "quality" remains ill-defined. Existing reasoning methods rely on indirect heuristics such as problem difficulty or trace length, while instruction-tuning has explored a broader range of automated selection strategies, but rarely in the context of reasoning. We propose to define reasoning data quality using influence functions, which measure the causal effect of individual CoT examples on downstream accuracy, and introduce influence-based pruning, which consistently outperforms perplexity and embedding-based baselines on math reasoning within a model family.

02 Jun 2021


SAINT is a deep learning architecture designed for tabular data that integrates intersample attention and contrastive pre-training. This approach allows the model to learn robust representations and relationships both within and across data samples, leading to performance improvements over prior deep learning methods and gradient boosting machines on diverse tabular datasets.

09 Nov 2025

Erasing harmful or proprietary concepts from powerful text to image generators is an emerging safety requirement, yet current "concept erasure" techniques either collapse image quality, rely on brittle adversarial losses, or demand prohibitive retraining cycles. We trace these limitations to a myopic view of the denoising trajectories that govern diffusion based generation. We introduce EraseFlow, the first framework that casts concept unlearning as exploration in the space of denoising paths and optimizes it with GFlowNets equipped with the trajectory balance objective. By sampling entire trajectories rather than single end states, EraseFlow learns a stochastic policy that steers generation away from target concepts while preserving the model's prior. EraseFlow eliminates the need for carefully crafted reward models and by doing this, it generalizes effectively to unseen concepts and avoids hackable rewards while improving the performance. Extensive empirical results demonstrate that EraseFlow outperforms existing baselines and achieves an optimal trade off between performance and prior preservation.

04 Oct 2024



Researchers at NYU and collaborating institutions introduced a continuous framework to parameterize and analyze structured matrices using Einstein summations, developing a taxonomy to understand their compute-optimal scaling properties. Their findings led to the design of BTT-MoE, a novel architecture that achieves significantly improved compute efficiency, requiring 5.3 times fewer FLOPs than dense models for equivalent performance.

26 Sep 2025
Supervised fine-tuning (SFT) with expert demonstrations often suffers from the imitation problem, where models reproduce correct responses without internalizing the underlying reasoning. We propose Critique-Guided Distillation (CGD), a multi-stage training framework that augments SFT with teacher-generated explanatory critiques and refined responses. Instead of directly imitating teacher outputs, a student learns to map the triplet of prompt, its own initial response, and teacher critique into the refined teacher response, thereby capturing both what to output and why. Our analyses show that CGD consistently reduces refinement uncertainty, improves alignment between critiques and responses, and enhances sample efficiency. On reasoning benchmarks, CGD achieves substantial gains across LLaMA and Qwen families, including +15.0% on AMC23 and +12.2% on MATH-500, while avoiding the format drift issues observed in prior critique-based fine-tuning. Importantly, on LLaMA-3.1-8B CGD approaches or exceeds the performance of SimpleRL-Zero, which is a DeepSeek-R1 replication, while requiring 60x less compute. Beyond reasoning, CGD maintains or improves general instruction-following and factual accuracy, matching baseline performance on IFEval, MUSR, TruthfulQA, and BBH. In contrast, prior critique-based methods degrade these capabilities (e.g., -21% on IFEval). Taken together, these results establish CGD} as a robust and generalizable alternative to both conventional SFT and RL-based methods, offering a more efficient path toward advancing the reasoning and safety of large language models.

10 Jul 2025
Generative Large Language Models (LLMs)inevitably produce untruthful responses. Accurately predicting the truthfulness of these outputs is critical, especially in high-stakes settings. To accelerate research in this domain and make truthfulness prediction methods more accessible, we introduce TruthTorchLM an open-source, comprehensive Python library featuring over 30 truthfulness prediction methods, which we refer to as Truth Methods. Unlike existing toolkits such as Guardrails, which focus solely on document-grounded verification, or LM-Polygraph, which is limited to uncertainty-based methods, TruthTorchLM offers a broad and extensible collection of techniques. These methods span diverse tradeoffs in computational cost, access level (e.g., black-box vs white-box), grounding document requirements, and supervision type (self-supervised or supervised). TruthTorchLM is seamlessly compatible with both HuggingFace and LiteLLM, enabling support for locally hosted and API-based models. It also provides a unified interface for generation, evaluation, calibration, and long-form truthfulness prediction, along with a flexible framework for extending the library with new methods. We conduct an evaluation of representative truth methods on three datasets, TriviaQA, GSM8K, and FactScore-Bio. The code is available at this https URL

04 Nov 2025

This work introduces Default MoE, a parameter-efficient method that provides a dense gradient signal to the router in sparse Mixture-of-Experts (MoE) models during backpropagation without incurring the cost of dense forward passes. The approach enhances training stability and accelerates convergence by approximately 9%, leading to improved pretraining performance on various benchmarks with a negligible increase in computational overhead and memory footprint.

21 Nov 2025
Researchers at MBZUAI and Capital One investigated the robustness of Vision-Language Models (VLMs) in identifying cultural items when faced with conflicting geographical cues. They found that VLMs experience a consistent performance degradation, with generative adversarial perturbations leading to an average accuracy drop of 17.34%, particularly when national flags are present as distractors.

16 Oct 2025
We propose a method for confidence estimation in retrieval-augmented generation (RAG) systems that aligns closely with the correctness of large language model (LLM) outputs. Confidence estimation is especially critical in high-stakes domains such as finance and healthcare, where the cost of an incorrect answer outweighs that of not answering the question. Our approach extends prior uncertainty quantification methods by leveraging raw feed-forward network (FFN) activations as auto-regressive signals, avoiding the information loss inherent in token logits and probabilities after projection and softmax normalization. We model confidence prediction as a sequence classification task, and regularize training with a Huber loss term to improve robustness against noisy supervision. Applied in a real-world financial industry customer-support setting with complex knowledge bases, our method outperforms strong baselines and maintains high accuracy under strict latency constraints. Experiments on Llama 3.1 8B model show that using activations from only the 16th layer preserves accuracy while reducing response latency. Our results demonstrate that activation-based confidence modeling offers a scalable, architecture-aware path toward trustworthy RAG deployment.

10 Nov 2025
Sparsely-activated Mixture of Experts (MoE) transformers are promising architectures for foundation models. Compared to dense transformers that require the same amount of floating-point operations (FLOPs) per forward pass, MoEs benefit from improved sample efficiency at training time and achieve much stronger performance. Many closed-source and open-source frontier language models have thus adopted an MoE architecture. Naturally, practitioners will want to extend the capabilities of these models with large amounts of newly collected data without completely re-training them. Prior work has shown that a simple combination of replay, learning rate re-warming, and re-decaying can enable the continual pre-training (CPT) of dense decoder-only transformers with minimal performance degradation compared to full re-training. In the case of decoder-only MoE transformers, however, it is unclear how the routing algorithm will impact continual pre-training performance: 1) do the MoE transformer's routers exacerbate forgetting relative to a dense model?; 2) do the routers maintain a balanced load on previous distributions after CPT?; 3) are the same strategies applied to dense models sufficient to continually pre-train MoE LLMs? In what follows, we conduct a large-scale study training a 500M parameter dense transformer and four 500M-active/2B-total parameter MoE transformers. Each model is trained for 600B tokens. Our results establish a surprising robustness to distribution shifts for MoEs using both Sinkhorn-Balanced and Z-and-Aux-loss-balanced routing algorithms, even in MoEs continually pre-trained without replay. Moreover, we show that MoE LLMs maintain their sample efficiency (relative to a FLOP-matched dense model) during CPT and that they can match the performance of a fully re-trained MoE at a fraction of the cost.
There are no more papers matching your filters at the moment.
