
18 May 2025
Parkinson's disease (PD) poses a growing global health challenge, with
Bangladesh experiencing a notable rise in PD-related mortality. Early detection
of PD remains particularly challenging in resource-constrained settings, where
voice-based analysis has emerged as a promising non-invasive and cost-effective
alternative. However, existing studies predominantly focus on English or other
major languages; notably, no voice dataset for PD exists for Bengali - posing a
significant barrier to culturally inclusive and accessible healthcare
solutions. Moreover, most prior studies employed only a narrow set of acoustic
features, with limited or no hyperparameter tuning and feature selection
strategies, and little attention to model explainability. This restricts the
development of a robust and generalizable machine learning model. To address
this gap, we present BenSparX, the first Bengali conversational speech dataset
for PD detection, along with a robust and explainable machine learning
framework tailored for early diagnosis. The proposed framework incorporates
diverse acoustic feature categories, systematic feature selection methods, and
state-of-the-art machine learning algorithms with extensive hyperparameter
optimization. Furthermore, to enhance interpretability and trust in model
predictions, the framework incorporates SHAP (SHapley Additive exPlanations)
analysis to quantify the contribution of individual acoustic features toward PD
detection. Our framework achieves state-of-the-art performance, yielding an
accuracy of 95.77%, F1 score of 95.57%, and AUC-ROC of 0.982. We further
externally validated our approach by applying the framework to existing PD
datasets in other languages, where it consistently outperforms state-of-the-art
approaches. To facilitate further research and reproducibility, the dataset has
been made publicly available at this https URL

29 Aug 2025
Speaker Identification refers to the process of identifying a person using one's voice from a collection of known speakers. Environmental noise, reverberation and distortion make the task of automatic speaker identification challenging as extracted features get degraded thus affecting the performance of the speaker identification (SID) system. This paper proposes a robust noise adapted SID system under noisy, mismatched, reverberated and distorted environments. This method utilizes an auditory features called cochleagram to extract speaker characteristics and thus identify the speaker. A channel gammatone filterbank with a frequency range from to Hz was used to generate 2-D cochleagrams. Wideband as well as narrowband noises were used along with clean speech to obtain noisy cochleagrams at various levels of signal to noise ratio (SNR). Both clean and noisy cochleagrams of only dB SNR were then fed into a convolutional neural network (CNN) to build a speaker model in order to perform SID which is referred as noise adapted speaker model (NASM). The NASM was trained using a certain noise and then was evaluated using clean and various types of noises. Moreover, the robustness of the proposed system was tested using reverberated as well as distorted test data. Performance of the proposed system showed a measurable accuracy improvement over existing neurogram based SID system.
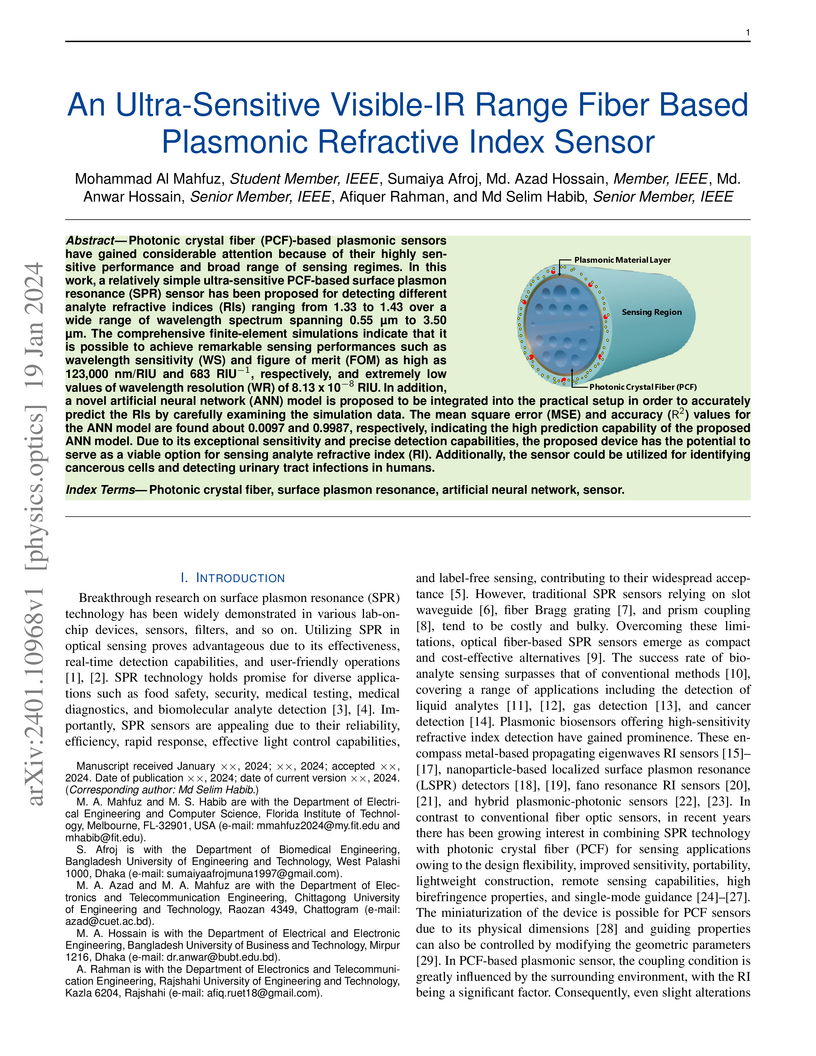
19 Jan 2024
Photonic crystal fiber (PCF)-based plasmonic sensors have gained considerable
attention because of their highly sensitive performance and broad range of
sensing regimes. In this work, a relatively simple ultra-sensitive PCF-based
surface plasmon resonance (SPR) sensor has been proposed for detecting
different analyte refractive indices (RIs) ranging from 1.33 to 1.43 over a
wide range of wavelength spectrum spanning 0.55 m to 3.50 m. The
comprehensive finite-element simulations indicate that it is possible to
achieve remarkable sensing performances such as wavelength sensitivity (WS) and
figure of merit (FOM) as high as 123,000 nm/RIU and 683 RIU,
respectively, and extremely low values of wavelength resolution (WR) of 8.13 x
10 RIU. In addition, a novel artificial neural network (ANN) model is
proposed to be integrated into the practical setup in order to accurately
predict the RIs by carefully examining the simulation data. The mean square
error (MSE) and accuracy () values for the ANN model are found about
0.0097 and 0.9987, respectively, indicating the high prediction capability of
the proposed ANN model. Due to its exceptional sensitivity and precise
detection capabilities, the proposed device has the potential to serve as a
viable option for sensing analyte refractive index (RI). Additionally, the
sensor could be utilized for identifying cancerous cells and detecting urinary
tract infections in humans.

10 Jan 2025
The skin, as the largest organ of the human body, is vulnerable to a diverse array of conditions collectively known as skin lesions, which encompass various dermatoses. Diagnosing these lesions presents significant challenges for medical practitioners due to the subtle visual differences that are often imperceptible to the naked eye. While not all skin lesions are life-threatening, certain types can act as early indicators of severe diseases, including skin cancers, underscoring the critical need for timely and accurate diagnostic methods. Deep learning algorithms have demonstrated remarkable potential in facilitating the early detection and prognosis of skin lesions. This study advances the field by curating a comprehensive and diverse dataset comprising 39 categories of skin lesions, synthesized from five publicly available datasets. Using this dataset, the performance of five state-of-the-art deep learning models -- MobileNetV2, Xception, InceptionV3, EfficientNetB1, and Vision Transformer - is rigorously evaluated. To enhance the accuracy and robustness of these models, attention mechanisms such as the Efficient Channel Attention (ECA) and the Convolutional Block Attention Module (CBAM) are incorporated into their architectures. Comprehensive evaluation across multiple performance metrics reveals that the Vision Transformer model integrated with CBAM outperforms others, achieving an accuracy of 93.46%, precision of 94%, recall of 93%, F1-score of 93%, and specificity of 93.67%. These results underscore the significant potential of the proposed system in supporting medical professionals with accurate and efficient prognostic tools for diagnosing a broad spectrum of skin lesions. The dataset and code used in this study can be found at this https URL.

28 Sep 2025
Calculations have been made for the double differential cross section (DDCS) for the ionization of metastable hydrogen atoms in the 3S state by electron and positron impact at energies of 150 eV and 250 eV. The authors implemented the second Born approximation to the multiple scattering theory as their model, evaluated the corresponding analytical expressions using Bethe and Lewis integrals, and numerically computed them using MATLAB. The generated DDCS captures the features of both recoil and binary fragmentation and, at the same time, provides an overall qualitative consistency with earlier studies, although some differences can be found between them at certain emission angles. The present work, therefore, supplies new theoretical reference levels for ionization investigations in hydrogen-like systems, now that no experimental data are available for the metastable 3S state.

14 Oct 2024

The geopolitical division between the indigenous Chakma population and mainstream Bangladesh creates a significant cultural and linguistic gap, as the Chakma community, mostly residing in the hill tracts of Bangladesh, maintains distinct cultural traditions and language. Developing a Machine Translation (MT) model or Chakma to Bangla could play a crucial role in alleviating this cultural-linguistic divide. Thus, we have worked on MT between CCP-BN(Chakma-Bangla) by introducing a novel dataset of 15,021 parallel samples and 42,783 monolingual samples of the Chakma Language. Moreover, we introduce a small set for Benchmarking containing 600 parallel samples between Chakma, Bangla, and English. We ran traditional and state-of-the-art models in NLP on the training set, where fine-tuning BanglaT5 with back-translation using transliteration of Chakma achieved the highest BLEU score of 17.8 and 4.41 in CCP-BN and BN-CCP respectively on the Benchmark Dataset. As far as we know, this is the first-ever work on MT for the Chakma Language. Hopefully, this research will help to bridge the gap in linguistic resources and contribute to preserving endangered languages. Our dataset link and codes will be published soon.

15 Feb 2025
Deep learning (DL) techniques have emerged as promising solutions for medical
wound tissue segmentation. However, a notable limitation in this field is the
lack of publicly available labelled datasets and a standardised performance
evaluation of state-of-the-art DL models on such datasets. This study addresses
this gap by comprehensively evaluating various DL models for wound tissue
segmentation using a novel dataset. We have curated a dataset comprising 147
wound images exhibiting six tissue types: slough, granulation, maceration,
necrosis, bone, and tendon. The dataset was meticulously labelled for semantic
segmentation employing supervised machine learning techniques. Three distinct
labelling formats were developed -- full image, patch, and superpixel. Our
investigation encompassed a wide array of DL segmentation and classification
methodologies, ranging from conventional approaches like UNet, to generative
adversarial networks such as cGAN, and modified techniques like FPN+VGG16.
Also, we explored DL-based classification methods (e.g., ResNet50) and machine
learning-based classification leveraging DL features (e.g., AlexNet+RF). In
total, 82 wound tissue segmentation models were derived across the three
labelling formats. Our analysis yielded several notable findings, including
identifying optimal DL models for each labelling format based on weighted
average Dice or F1 scores. Notably, FPN+VGG16 emerged as the top-performing DL
model for wound tissue segmentation, achieving a dice score of 82.25%. This
study provides a valuable benchmark for evaluating wound image segmentation and
classification models, offering insights to inform future research and clinical
practice in wound care. The labelled dataset created in this study is available
at this https URL

28 Sep 2025
The incorporation of o-MAX phases, characterized by out-of-plane atomic arrangements, provides valuable extensions to the MAX phase family, driven by their superior thermomechanical properties, which are suitable for high-temperature applications. In this research, three novel o-MAX phases, Mo2A2AlC3 (A = Zr, Nb, Ta), have been newly explored, and their structural geometry, electronic properties, mechanical behavior, thermodynamic characters, and optical response have been comprehensively investigated employing density functional theory (DFT) for the first time.

28 Jul 2025
In recent years, social media platforms have become prominent spaces for individuals to express their opinions on ongoing events, including criminal incidents. As a result, public sentiment can shift dynamically over time. This study investigates the evolving public perception of crime-related news by classifying user-generated comments into three categories: positive, negative, and neutral. A newly curated dataset comprising 28,528 Bangla-language social media comments was developed for this purpose. We propose a transformer-based model utilizing the XLM-RoBERTa Base architecture, which achieves a classification accuracy of 97%, outperforming existing state-of-the-art methods in Bangla sentiment analysis. To enhance model interpretability, explainable AI technique is employed to identify the most influential features driving sentiment classification. The results underscore the effectiveness of transformer-based models in processing low-resource languages such as Bengali and demonstrate their potential to extract actionable insights that can support public policy formulation and crime prevention strategies.

11 Nov 2025
This paper addresses the problem of Bangla hate speech identification, a socially impactful yet linguistically challenging task. As part of the "Bangla Multi-task Hate Speech Identification" shared task at the BLP Workshop, IJCNLP-AACL 2025, our team "Retriv" participated in all three subtasks: (1A) hate type classification, (1B) target group identification, and (1C) joint detection of type, severity, and target. For subtasks 1A and 1B, we employed a soft-voting ensemble of transformer models (BanglaBERT, MuRIL, IndicBERTv2). For subtask 1C, we trained three multitask variants and aggregated their predictions through a weighted voting ensemble. Our systems achieved micro-f1 scores of 72.75% (1A) and 72.69% (1B), and a weighted micro-f1 score of 72.62% (1C). On the shared task leaderboard, these corresponded to 9th, 10th, and 7th positions, respectively. These results highlight the promise of transformer ensembles and weighted multitask frameworks for advancing Bangla hate speech detection in low-resource contexts. We made experimental scripts publicly available for the community.

22 Jan 2025
Emotion recognition is a critical task in human-computer interaction, enabling more intuitive and responsive systems. This study presents a multimodal emotion recognition system that combines low-level information from audio and text, leveraging both Convolutional Neural Networks (CNNs) and Bidirectional Long Short-Term Memory Networks (BiLSTMs). The proposed system consists of two parallel networks: an Audio Block and a Text Block. Mel Frequency Cepstral Coefficients (MFCCs) are extracted and processed by a BiLSTM network and a 2D convolutional network to capture low-level intrinsic and extrinsic features from speech. Simultaneously, a combined BiLSTM-CNN network extracts the low-level sequential nature of text from word embeddings corresponding to the available audio. This low-level information from speech and text is then concatenated and processed by several fully connected layers to classify the speech emotion. Experimental results demonstrate that the proposed EmoTech accurately recognizes emotions from combined audio and text inputs, achieving an overall accuracy of 84%. This solution outperforms previously proposed approaches for the same dataset and modalities.

22 Jan 2025
Speech Emotion Recognition is a crucial area of research in human-computer interaction. While significant work has been done in this field, many state-of-the-art networks struggle to accurately recognize emotions in speech when the data is both speech and speaker-independent. To address this limitation, this study proposes, EmoFormer, a hybrid model combining CNNs (CNNs) with Transformer encoders to capture emotion patterns in speech data for such independent datasets. The EmoFormer network was trained and tested using the Expressive Anechoic Recordings of Speech (EARS) dataset, recently released by META. We experimented with two feature extraction techniques: MFCCs and x-vectors. The model was evaluated on different emotion sets comprising 5, 7, 10, and 23 distinct categories. The results demonstrate that the model achieved its best performance with five emotions, attaining an accuracy of 90%, a precision of 0.92, a recall, and an F1-score of 0.91. However, performance decreased as the number of emotions increased, with an accuracy of 83% for seven emotions compared to 70% for the baseline network. This study highlights the effectiveness of combining CNNs and Transformer-based architectures for emotion recognition from speech, particularly when using MFCC features.

24 Jul 2013
This paper presents a hybrid digital image watermarking based on Discrete
Wavelet Transform (DWT), Discrete Cosine Transform (DCT) and Singular Value
Decomposition (SVD) in a zigzag order. From DWT we choose the high band to
embed the watermark that facilities to add more information, gives more
invisibility and robustness against some attacks. Such as geometric attack.
Zigzag method is applied to map DCT coefficients into four quadrants that
represent low, mid and high bands. Finally, SVD is applied to each quadrant.

19 Aug 2021
Boron rich chalcogenides have been predicted to have excellent properties for
optical and mechanical applications in recent times. In this regard, we report
the electronic, optical and mechanical properties of recently synthesized boron
rich chalcogenide compounds, B12X (X = S and Se) using density functional
theory for the first time. The effects of exchange and correlation functional
on these properties are also investigated. The consistency of the obtained
crystal structure with the reported experimental results has been checked in
terms of lattice parameters. The considered materials are mechanically stable,
brittle and elastically anisotropic. Furthermore, the elastic moduli and
hardness parameters are calculated, which show that B12S is likely to be a
prominent member of hard materials family compared to B12Se. The origin of
different in hardness is explained on the basis of density of states near the
Fermi level. Reasonably good values of fracture toughness and machinability
index for B12X (X= S and Se) are reported. The melting point, Tm for the B12S
and B12Se compounds suggests that both solids are stable, at least up to 4208
and 3577 K, respectively. Indirect band gap of B12S (2.27 eV) and B12Se (1.30
eV) are obtained using the HSE06 functional.The electrons of B12Se compound
show lighter average effective mass compared to that of B12S compound, which
signifies higher mobility of charge carriers in B12Se. The optical properties
are characterized using GGA-PBE and HSE06 method and discussed in detail. These
compounds possess bulk optical anisotropy and excellent absorption coefficients
in visible light region along with very low static value of reflectivity
spectra (range: 7.42-14.0% using both functionals) are noted. Such useful
features of the compounds under investigation show promise for applications in
optoelectronic and mechanical sectors.

18 Oct 2025
Photonic crystal fiber-based surface plasmon resonance (PCF-SPR) sensors have emerged as a promising class of optical sensors due to their high sensitivity, compact structure and compatibility with a wide range of analytes. Their performance can be significantly enhanced by carefully engineering the fiber geometry to improve the coupling between the guided core mode and the surface plasmon mode. In this work, a polarization-dependent PCF-SPR sensor is numerically designed and analyzed using the finite element method (FEM) to achieve strong mode coupling, wide detection range and high refractive index (RI) sensitivity. The proposed structure incorporates air holes of varying diameters and a rectangular core slot to induce birefringence, while four outer microchannels coated with a 30 nm gold layer form separate plasmonic regions for multiple resonance excitation. Simulation results demonstrate maximum wavelength sensitivities of 77500 nm/RIU and 92500 nm/RIU for x and y-polarizations, respectively and amplitude sensitivities of 3930 1/RIU and 3139 1/RIU, with corresponding figures of merit of 517 1/RIU and 356 1/RIU across an analyte RI range of 1.32-1.42. Parametric analysis confirms strong fabrication tolerance, with coupling mainly influenced by the smallest air holes and the core slot height. The external sensing configuration enables easy analyte handling and reuse, while the design remains compatible with existing fabrication techniques. The proposed sensor thus offers a compact, highly sensitive and fabrication-feasible platform for biochemical and chemical sensing applications.

30 Jan 2025
This paper presents a comparative study aimed at optimizing Llama2 inference, a critical aspect of machine learning and natural language processing (NLP). We evaluate various programming languages and frameworks, including TensorFlow, PyTorch, Python, Mojo, C++, and Java, analyzing their performance in terms of speed, memory consumption, and ease of implementation through extensive benchmarking. Strengths and limitations of each approach are highlighted, along with proposed optimization strategies for parallel processing and hardware utilization. Furthermore, we investigate the Mojo SDK, a novel framework designed for large language model (LLM) inference on Apple Silicon, benchmarking its performance against implementations in C, C++, Rust, Zig, Go, and Julia. Our experiments, conducted on an Apple M1 Max, demonstrate Mojo SDK's competitive performance, ease of use, and seamless Python compatibility, positioning it as a strong alternative for LLM inference on Apple Silicon. We also discuss broader implications for LLM deployment on resource-constrained hardware and identify potential directions for future research.

01 Oct 2023
In this work, density functional theory (DFT) is used to find out the ground state structures of A2AuScX6 (A= Cs, Rb; X= Cl, Br, I) double Perovskite (DP) halides for the first time. The DP A2AuScX6 halides were studied for their structural phase stability and optoelectronic properties in order to identify potential materials for energy harvesting systems. The stability criteria were verified by computing the formation energy, binding energy, phonon dispersion curve, stiffness constants, tolerance, and octahedral factors. The electronic band structure, carrier effective mass, density of states (DOS), and charge density distribution were calculated to reveal the nature of electronic conductivity and the chemical bonding nature present within them. For Cs2AuScX6 (Rb2AuScX6) [X = Cl, Br, I], the corresponding values of band gap [using TB-mBJ] are 1.88 (1.93), 1.68 (1.71), and 1.30 (1.32) eV. The optical constants (dielectric function, absorption coefficient, refractive index, energy loss function, photoconductivity, and reflectivity) were also calculated to get more insights into their electronic nature. For Cs2AuScX6 (Rb2AuScX6) [X = Cl, Br, I], the absorption coefficient in the visible range are 3.33 (3.45) 105 cm-1, 2.70 (2.81) 105 cm-1, and 2.13 (2.18) 105 cm-1, respectively. We also investigated the thermoelectric properties to predict promising applications in thermoelectric devices. Our calculations revealed high ZT values of 0.92, 1.07, and 1.06 for Cs2AuScX6 (X = Cl, Br, I) and 0.97, 0.99, and 1.01 for Rb2AuScX6 (X = Cl, Br, I) at 300 K. To further aid in predicting any novel materials, routine research was also done on the thermo-mechanical characteristics. The results suggest the compounds considered as potential candidates for use in solar cells and/or thermoelectric devices.

04 Mar 2025
The rise of social media has significantly increased the prevalence of
cyberbullying (CB), posing serious risks to both mental and physical
well-being. Effective detection systems are essential for mitigating its
impact. While several machine learning (ML) models have been developed, few
incorporate victims' psychological, demographic, and behavioral factors
alongside bullying comments to assess severity. In this study, we propose an AI
model intregrating user-specific attributes, including psychological factors
(self-esteem, anxiety, depression), online behavior (internet usage,
disciplinary history), and demographic attributes (race, gender, ethnicity),
along with social media comments. Additionally, we introduce a re-labeling
technique that categorizes social media comments into three severity levels:
Not Bullying, Mild Bullying, and Severe Bullying, considering user-specific
factors.Our LSTM model is trained using 146 features, incorporating emotional,
topical, and word2vec representations of social media comments as well as
user-level attributes and it outperforms existing baseline models, achieving
the highest accuracy of 98\% and an F1-score of 0.97. To identify key factors
influencing the severity of cyberbullying, we employ explainable AI techniques
(SHAP and LIME) to interpret the model's decision-making process. Our findings
reveal that, beyond hate comments, victims belonging to specific racial and
gender groups are more frequently targeted and exhibit higher incidences of
depression, disciplinary issues, and low self-esteem. Additionally, individuals
with a prior history of bullying are at a greater risk of becoming victims of
cyberbullying.

17 Jun 2022
Temperature and humidity are two of the rudimentary factors that must be controlled during egg incubation. Improper temperature and humidity levels during the incubation period often result in unwanted conditions. This paper proposes the design of an efficient Mamdani fuzzy interference system instead of the widely used Takagi-Sugeno system in this field for controlling the temperature and humidity levels of an egg incubator. Though the optimum incubation temperature and humidity levels used here are that of chicken egg, the proposed methodology is applicable to other avian species as well. Theinput functions have been used here as per estimated values forsafe hatching using Mamdani whereas defuzzification method, COA, has been applied for output. From the model output,a stabilized heat from temperature level and fan speed to control the humidity level of an egg incubator can be obtained. This maximizes the hatching rate of healthy chicks under any conditions in the field.

31 Mar 2018
Facebook as in social network is a great innovation of modern times. Among all social networking sites, Facebook is the most popular social network all over the world. Bangladesh is no exception. People use Facebook for various reasons e.g. social networking and communication, online shopping and business, knowledge and experience sharing etc. However, some recent incidents in Bangladesh, originated from or based on Facebook activities, led to arson and violence. Social network i.e. Facebook was used in these incidents mostly as a tool to trigger hatred and violence. This case study discusses these technology related incidents and recommends possible future measurements to prevent such violence.
There are no more papers matching your filters at the moment.
