
09 Oct 2025
 ETH Zurich
ETH Zurich University of Washington
University of Washington University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign Monash University
Monash University University of Notre Dame
University of Notre Dame Google
Google University of OxfordNUS
University of OxfordNUS University of California, San DiegoCSIRO’s Data61
University of California, San DiegoCSIRO’s Data61 NVIDIATencent AI Lab
NVIDIATencent AI Lab Hugging Face
Hugging Face Purdue UniversitySingapore Management UniversityIBMInstitute of Automation, CAS
Purdue UniversitySingapore Management UniversityIBMInstitute of Automation, CAS ServiceNowComenius University in BratislavaHKUST GuangzhouCiscoTano LabsU.Va.UberCNRS, FranceNevsky CollectiveDetomo Inc
ServiceNowComenius University in BratislavaHKUST GuangzhouCiscoTano LabsU.Va.UberCNRS, FranceNevsky CollectiveDetomo IncBIGCODEARENA introduces an open, execution-backed human evaluation platform for large language model (LLM) generated code, collecting human preference data to form benchmarks for evaluating code LLMs and reward models. This approach demonstrates that execution feedback improves the reliability of evaluations and reveals detailed performance differences among models across various programming languages and environments.

29 Apr 2025
 University of California, Santa Barbara
University of California, Santa Barbara University of Copenhagen
University of Copenhagen Cohere
Cohere ETH ZürichCONICET
ETH ZürichCONICET Aalborg University
Aalborg University Emory UniversityTU DresdenUppsala UniversityUniversidad de Buenos Aires
Emory UniversityTU DresdenUppsala UniversityUniversidad de Buenos Aires Karlsruhe Institute of TechnologyFederal University of São CarlosMoscow Institute of Physics and TechnologyUniversity of BathUniversity of MontrealUniversity of São PauloComenius University in BratislavaPioneer Center for AICiscoNational University, PhilippinesHSE University (Higher School of Economics)
Karlsruhe Institute of TechnologyFederal University of São CarlosMoscow Institute of Physics and TechnologyUniversity of BathUniversity of MontrealUniversity of São PauloComenius University in BratislavaPioneer Center for AICiscoNational University, PhilippinesHSE University (Higher School of Economics)

The evaluation of vision-language models (VLMs) has mainly relied on
English-language benchmarks, leaving significant gaps in both multilingual and
multicultural coverage. While multilingual benchmarks have expanded, both in
size and languages, many rely on translations of English datasets, failing to
capture cultural nuances. In this work, we propose Kaleidoscope, as the most
comprehensive exam benchmark to date for the multilingual evaluation of
vision-language models. Kaleidoscope is a large-scale, in-language multimodal
benchmark designed to evaluate VLMs across diverse languages and visual inputs.
Kaleidoscope covers 18 languages and 14 different subjects, amounting to a
total of 20,911 multiple-choice questions. Built through an open science
collaboration with a diverse group of researchers worldwide, Kaleidoscope
ensures linguistic and cultural authenticity. We evaluate top-performing
multilingual vision-language models and find that they perform poorly on
low-resource languages and in complex multimodal scenarios. Our results
highlight the need for progress on culturally inclusive multimodal evaluation
frameworks.

29 Jun 2024
University of WashingtonAllen Institute for Artificial Intelligence Georgia Institute of TechnologyLMU MunichIT University of CopenhagenJožef Stefan InstituteBeijing Academy of Artificial Intelligence
Georgia Institute of TechnologyLMU MunichIT University of CopenhagenJožef Stefan InstituteBeijing Academy of Artificial Intelligence Sorbonne UniversitéINRIA ParisUniversity of BathNational UniversityBen Gurion UniversityComenius University in BratislavaCiscoDuolingo
Sorbonne UniversitéINRIA ParisUniversity of BathNational UniversityBen Gurion UniversityComenius University in BratislavaCiscoDuolingo

We introduce Universal NER (UNER), an open, community-driven project to develop gold-standard NER benchmarks in many languages. The overarching goal of UNER is to provide high-quality, cross-lingually consistent annotations to facilitate and standardize multilingual NER research. UNER v1 contains 18 datasets annotated with named entities in a cross-lingual consistent schema across 12 diverse languages. In this paper, we detail the dataset creation and composition of UNER; we also provide initial modeling baselines on both in-language and cross-lingual learning settings. We release the data, code, and fitted models to the public.

22 Jul 2024
Vladimír Boža from Comenius University developed a method employing the Alternating Direction Method of Multipliers (ADMM) for fast and effective post-pruning weight updates in large language models. The ADMM-Grad approach consistently achieved state-of-the-art perplexity and zero-shot accuracy on LLaMA and LLaMA-2 models, enabling more aggressive pruning while preserving performance.

30 Sep 2025
We analyze a specific class of forward-scattering diagrams with imaginary kinematics, which, via the optical theorem, describe processes involving two identical fermions occupying the same state. What initially seems to be a contradiction turns out to be a key element in how the Pauli exclusion principle manifests itself in scattering theory. The discussion is entirely basic and could easily fit into any quantum field theory textbook. To the best of our knowledge, however, this point has not been addressed in the literature, and we aim to fill this gap.

22 Oct 2025

A -dimensional nowhere-zero -flow on a graph , an -NZF from now on, is a flow where the value on each edge is an element of whose (Euclidean) norm lies in the interval . Such a notion is a natural generalization of the well-known concept of a circular nowhere-zero -flow (i.e.\ ). The minimum of the real numbers such that a graph admits an -NZF is called the -dimensional flow number of and is denoted by . In this paper we provide a geometric description of some -dimensional flows on a graph , and we prove that the existence of a suitable cycle double cover of is equivalent, for , to admit such a geometrically constructed -NZF. This geometric approach allows us to provide upper bounds for and , assuming that admits an (oriented) -cycle double cover.

18 Mar 2024
Ontologies are a standard tool for creating semantic schemata in many
knowledge intensive domains of human interest. They are becoming increasingly
important also in the areas that have been until very recently dominated by
subsymbolic knowledge representation and machine-learning (ML) based data
processing. One such area is information security, and specifically, malware
detection. We thus propose PE Malware Ontology that offers a reusable semantic
schema for Portable Executable (PE - the Windows binary format) malware files.
This ontology is inspired by the structure of the EMBER dataset, which focuses
on the static malware analysis of PE files. With this proposal, we hope to
provide a unified semantic representation for the existing and future
PE-malware datasets and facilitate the application of symbolic, neuro-symbolic,
or otherwise explainable approaches in the PE-malware-detection domain, which
may produce interpretable results described by the terms defined in our
ontology. In addition, we also publish semantically treated EMBER data,
including fractional datasets, to support the reproducibility of experiments on
EMBER. We supplement our work with a preliminary case study, conducted using
concept learning, to show the general feasibility of our approach. While we
were not able to match the precision of the state-of-the-art ML tools, the
learned malware discriminators were interesting and highly interpretable.

14 Apr 2025
The characterization and analysis of light curves are vital for understanding
the physical and rotational properties of artificial space objects such as
satellites, rocket stages, and space debris. This paper introduces the Light
Curve Dataset Creator (LCDC), a Python-based toolkit designed to facilitate the
preprocessing, analysis, and machine learning applications of light curve data.
LCDC enables seamless integration with publicly available datasets, such as the
newly introduced Mini Mega Tortora (MMT) database. Moreover, it offers data
filtering, transformation, as well as feature extraction tooling. To
demonstrate the toolkit's capabilities, we created the first standardized
dataset for rocket body classification, RoBo6, which was used to train and
evaluate several benchmark machine learning models, addressing the lack of
reproducibility and comparability in recent studies. Furthermore, the toolkit
enables advanced scientific analyses, such as surface characterization of the
Atlas 2AS Centaur and the rotational dynamics of the Delta 4 rocket body, by
streamlining data preprocessing, feature extraction, and visualization. These
use cases highlight LCDC's potential to advance space debris characterization
and promote sustainable space exploration. Additionally, they highlight the
toolkit's ability to enable AI-focused research within the space debris
community.

24 Jun 2025

Raman spectroscopy is a powerful experimental technique for characterizing molecules and materials that is used in many laboratories. First-principles theoretical calculations of Raman spectra are important because they elucidate the microscopic effects underlying Raman activity in these systems. These calculations are often performed using the canonical harmonic approximation which cannot capture certain thermal changes in the Raman response. Anharmonic vibrational effects were recently found to play crucial roles in several materials, which motivates theoretical treatments of the Raman effect beyond harmonic phonons. While Raman spectroscopy from molecular dynamics (MD-Raman) is a well-established approach that includes anharmonic vibrations and further relevant thermal effects, MD-Raman computations were long considered to be computationally too expensive for practical materials computations. In this perspective article, we highlight that recent advances in the context of machine learning have now dramatically accelerated the involved computational tasks without sacrificing accuracy or predictive power. These recent developments highlight the increasing importance of MD-Raman and related methods as versatile tools for theoretical prediction and characterization of molecules and materials.
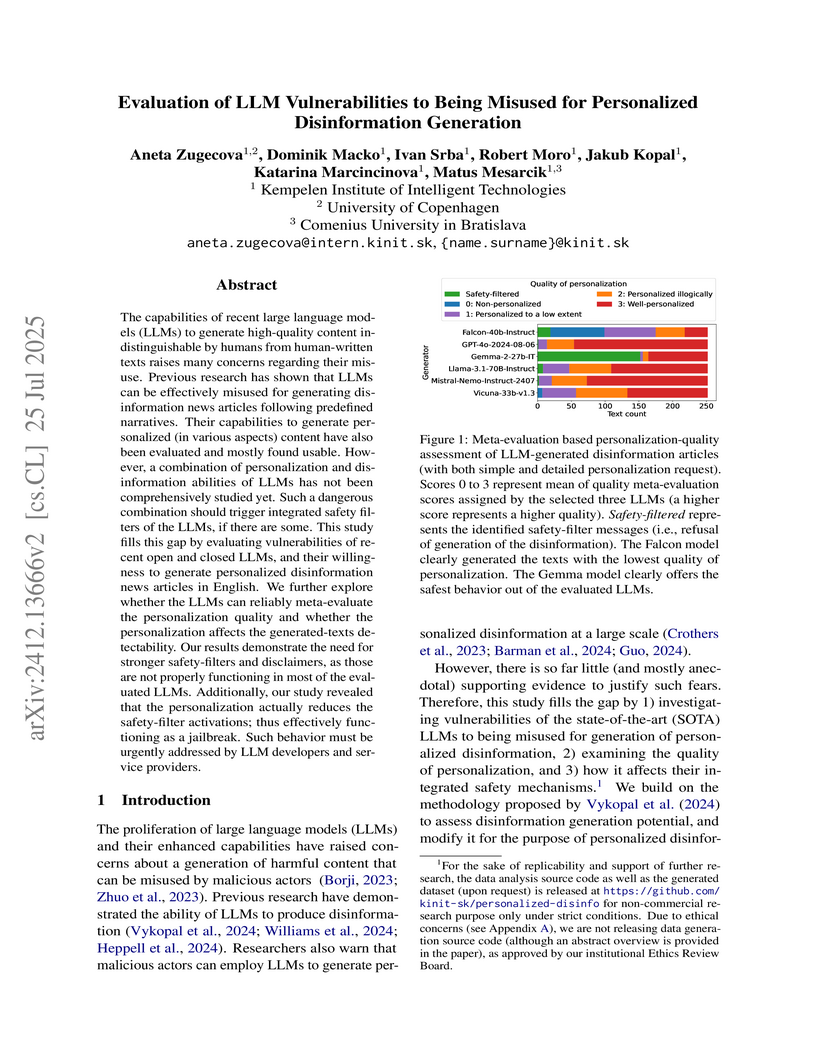
25 Jul 2025
The capabilities of recent large language models (LLMs) to generate high-quality content indistinguishable by humans from human-written texts raises many concerns regarding their misuse. Previous research has shown that LLMs can be effectively misused for generating disinformation news articles following predefined narratives. Their capabilities to generate personalized (in various aspects) content have also been evaluated and mostly found usable. However, a combination of personalization and disinformation abilities of LLMs has not been comprehensively studied yet. Such a dangerous combination should trigger integrated safety filters of the LLMs, if there are some. This study fills this gap by evaluating vulnerabilities of recent open and closed LLMs, and their willingness to generate personalized disinformation news articles in English. We further explore whether the LLMs can reliably meta-evaluate the personalization quality and whether the personalization affects the generated-texts detectability. Our results demonstrate the need for stronger safety-filters and disclaimers, as those are not properly functioning in most of the evaluated LLMs. Additionally, our study revealed that the personalization actually reduces the safety-filter activations; thus effectively functioning as a jailbreak. Such behavior must be urgently addressed by LLM developers and service providers.

20 May 2025

We present a novel approach to constructing gravitational instantons based on
the observation that the gravitational action of general relativity in its
teleparallel formulation can be expressed as a product of the torsion and
excitation forms. We introduce a new class of solutions where these two forms
are equal, which we term the self-excited instantons, and advocate for their
use over the self-dual instantons of Eguchi and Hanson. These new self-excited
instantons exhibit striking similarities to BPST instantons in Yang-Mills
theory, as their action reduces to a topological Nieh-Yan term, which allows us
to identify the axial torsion as a topological current and show that the
gravitational action is given by a topological charge.

07 Jan 2023
We propose a Quantum Field Theory (QFT) approach to neutrino oscillations in vacuum. The neutrino emission and detection are identified with the charged-current vertices of a single second-order Feynman diagram for the underlying process, enclosing neutrino propagation between these two points. The key point of our approach is the definition of the space-time setup typical for neutrino oscillation experiments, implying macroscopically large but finite volumes of the source and detector separated by a sufficiently large distance . We derive an -dependent master formula for the charged lepton production rate, which provides the QFT basis for the analysis of neutrino oscillations. Our formula depends on the underlying process and is not reducible to the conventional approach resorting to the concept of neutrino oscillation probability, which originates from non-relativistic quantum mechanics (QM). We demonstrate that for some particular choice of the underlying process our QFT formula approximately coincides with the conventional one under some assumptions.

13 May 2025
We study a Hermitian matrix model with a quartic potential, modified by a
curvature term , where is a fixed external matrix.
Motivated by the truncated Heisenberg algebra formulation of the
Grosse-Wulkenhaar model, this term breaks unitary invariance and gives rise to
an effective multitrace matrix model via perturbative expansion. We analyze the
resulting action analytically and numerically, focusing on the shift of the
triple point and suppression of the noncommutative stripe phase -- features
linked to renormalizability. Our findings, supported by Hamiltonian Monte Carlo
simulations, indicate that the curvature term drives the phase structure toward
renormalizable behavior by eliminating the stripe phase.

25 Apr 2023
We introduce the novel method for estimation of mean and Gaussian curvature and several related quantities for polygonal meshes. The algebraic quadric fitting curvature (AQFC) is based on local approximation of the mesh vertices and associated normals by a quadratic surface. The quadric is computed as an implicit surface, so it minimizes algebraic distances and normal deviations from the approximated point-normal neighbourhood of the processed vertex. Its mean and Gaussian curvature estimate is then obtained as the respective curvature of its orthogonal projection onto the fitted quadratic surface. Experimental results for both sampled parametric surfaces and arbitrary meshes are provided. The proposed method AQFC approaches the true curvatures of the reference smooth surfaces with increasing density of sampling, regardless of its regularity. It is resilient to irregular sampling of the mesh, compared to the contemporary curvature estimators. In the case of arbitrary meshes, obtained from scanning, AQFC provides robust curvature estimation.

05 Mar 2025
We consider a -dimensional autonomous system subject to a -periodic
perturbation, i.e.
\dot{\vec{x}}=\vec{f}(\vec{x})+\epsilon\vec{g}(t,\vec{x},\epsilon),\quad
\vec{x}\in\Omega . We assume that for there is a trajectory
homoclinic to the origin which is a critical point: in this
context Melnikov theory provides a sufficient condition for the insurgence of a
chaotic pattern when .
In this paper we show that for any line transversal to
and any we can
find a set of initial conditions giving rise to a pattern
chaotic just in the future, located in at . Further
diam where
is a constant and is a parameter that can be
chosen as large as we wish.
The same result holds true for the set of initial
conditions giving rise to a pattern chaotic just in the past. In fact all the
results are developed in a piecewise-smooth context, assuming that
lies on the discontinuity curve : we recall that in this setting
chaos is not possible if we have sliding phenomena close to the origin. This
paper can also be considered as the first part of the project to show the
existence of classical chaotic phenomena when sliding close to the origin is
not present.

26 Aug 2024
A vertex-girth-regular -graph is a -regular graph of girth and order in which every vertex belongs to exactly cycles of length . While all vertex-transitive graphs are necessarily vertex-girth-regular, the majority of vertex-girth-regular graphs are not vertex-transitive. Similarly, while many of the smallest -regular graphs of girth , the so-called -cages, are vertex-girth-regular, infinitely many vertex-girth-regular graphs of degree and girth exist for many pairs . Due to these connections, the study of vertex-girth-regular graphs promises insights into the relations between the classes of extremal, highly symmetric, and locally regular graphs of given degree and girth. This paper lays the foundation to such study by investigating the fundamental properties of -graphs, specifically the relations necessarily satisfied by the parameters and to admit the existence of a corresponding vertex-girth-regular graph, by presenting constructions of infinite families of -graphs, and by establishing lower bounds on the number of vertices in a -graph. It also includes computational results determining the orders of smallest cubic and quartic graphs of small girths.

01 Jan 2025
The problem of self-calibration of two cameras from a given fundamental matrix is one of the basic problems in geometric computer vision. Under the assumption of known principal points and square pixels, the well-known Bougnoux formula offers a means to compute the two unknown focal lengths. However, in many practical situations, the formula yields inaccurate results due to commonly occurring singularities. Moreover, the estimates are sensitive to noise in the computed fundamental matrix and to the assumed positions of the principal points. In this paper, we therefore propose an efficient and robust iterative method to estimate the focal lengths along with the principal points of the cameras given a fundamental matrix and priors for the estimated camera parameters. In addition, we study a computationally efficient check of models generated within RANSAC that improves the accuracy of the estimated models while reducing the total computational time. Extensive experiments on real and synthetic data show that our iterative method brings significant improvements in terms of the accuracy of the estimated focal lengths over the Bougnoux formula and other state-of-the-art methods, even when relying on inaccurate priors.

27 Apr 2023
A -dimensional nowhere-zero -flow on a graph , an -NZF from now on, is a flow where the value on each edge is an element of whose (Euclidean) norm lies in the interval . Such a notion is a natural generalization of the well-known concept of circular nowhere-zero -flow (i.e.\ ). For every bridgeless graph , the -flow Conjecture claims that , while a conjecture by Jain suggests that , for all . Here, we address the problem of finding a possible upper-bound also for the remaining case . We show that, for all bridgeless graphs, and that the oriented -cycle double cover Conjecture implies , where is the Golden Ratio. Moreover, we propose a geometric method to describe an -NZF of a cubic graph in a compact way, and we apply it in some instances. Our results and some computational evidence suggest that could be a promising upper bound for the parameter for an arbitrary bridgeless graph . We leave that as a relevant open problem which represents an analogous of the -flow Conjecture in the -dimensional case (i.e. complex case).

21 Nov 2024
We analyze multitrace random matrix models with the help of the saddle point approximation and we introduce a multitrace term of type to the action. We obtain the numerical phase diagram of the model, with a stable asymmetric phase and the triple point. Furthermore, we examine response functions in this model.

13 Jan 2025
In this paper, we propose a novel approach for recovering focal lengths from three-view homographies. By examining the consistency of normal vectors between two homographies, we derive new explicit constraints between the focal lengths and homographies using an elimination technique. We demonstrate that three-view homographies provide two additional constraints, enabling the recovery of one or two focal lengths. We discuss four possible cases, including three cameras having an unknown equal focal length, three cameras having two different unknown focal lengths, three cameras where one focal length is known, and the other two cameras have equal or different unknown focal lengths. All the problems can be converted into solving polynomials in one or two unknowns, which can be efficiently solved using Sturm sequence or hidden variable technique. Evaluation using both synthetic and real data shows that the proposed solvers are both faster and more accurate than methods relying on existing two-view solvers. The code and data are available on this https URL
There are no more papers matching your filters at the moment.
