
19 Mar 2025


Multi-Frequency Perturbations (MFP) offers a strategy for multimodal large language models to address object hallucinations by suppressing redundant frequency-domain features. The approach improves POPE F1 scores to 86.2 and reduces sentence-level hallucinations (CHAIR) to 41.2, while also raising overall MMBench accuracy to 68.2 on the LLaVA-1.5-7B model.

14 Mar 2022
Novel classes frequently arise in our dynamically changing world, e.g., new users in the authentication system, and a machine learning model should recognize new classes without forgetting old ones. This scenario becomes more challenging when new class instances are insufficient, which is called few-shot class-incremental learning (FSCIL). Current methods handle incremental learning retrospectively by making the updated model similar to the old one. By contrast, we suggest learning prospectively to prepare for future updates, and propose ForwArd Compatible Training (FACT) for FSCIL. Forward compatibility requires future new classes to be easily incorporated into the current model based on the current stage data, and we seek to realize it by reserving embedding space for future new classes. In detail, we assign virtual prototypes to squeeze the embedding of known classes and reserve for new ones. Besides, we forecast possible new classes and prepare for the updating process. The virtual prototypes allow the model to accept possible updates in the future, which act as proxies scattered among embedding space to build a stronger classifier during inference. FACT efficiently incorporates new classes with forward compatibility and meanwhile resists forgetting of old ones. Extensive experiments validate FACT's state-of-the-art performance. Code is available at: this https URL

07 Dec 2025
Recent advances in fine-tuning multimodal large language models (MLLMs) using reinforcement learning have achieved remarkable progress, particularly with the introduction of various entropy control techniques. However, the role and characteristics of entropy in perception-oriented tasks like visual grounding, as well as effective strategies for controlling it, remain largely unexplored. To address this issue, we focus on the visual grounding task and analyze the role and characteristics of entropy in comparison to reasoning tasks. Building on these findings, we introduce ECVGPO (Entropy Control Visual Grounding Policy Optimization), an interpretable algorithm designed for effective entropy regulation. Through entropy control, the trade-off between exploration and exploitation is better balanced. Experiments show that ECVGPO achieves broad improvements across various benchmarks and models.

12 Mar 2024


Knowledge distillation (KD) has shown potential for learning compact models
in dense object detection. However, the commonly used softmax-based
distillation ignores the absolute classification scores for individual
categories. Thus, the optimum of the distillation loss does not necessarily
lead to the optimal student classification scores for dense object detectors.
This cross-task protocol inconsistency is critical, especially for dense object
detectors, since the foreground categories are extremely imbalanced. To address
the issue of protocol differences between distillation and classification, we
propose a novel distillation method with cross-task consistent protocols,
tailored for the dense object detection. For classification distillation, we
address the cross-task protocol inconsistency problem by formulating the
classification logit maps in both teacher and student models as multiple
binary-classification maps and applying a binary-classification distillation
loss to each map. For localization distillation, we design an IoU-based
Localization Distillation Loss that is free from specific network structures
and can be compared with existing localization distillation losses. Our
proposed method is simple but effective, and experimental results demonstrate
its superiority over existing methods. Code is available at
this https URL

24 Apr 2025
This paper presents the results of the fourth edition of the Monocular Depth
Estimation Challenge (MDEC), which focuses on zero-shot generalization to the
SYNS-Patches benchmark, a dataset featuring challenging environments in both
natural and indoor settings. In this edition, we revised the evaluation
protocol to use least-squares alignment with two degrees of freedom to support
disparity and affine-invariant predictions. We also revised the baselines and
included popular off-the-shelf methods: Depth Anything v2 and Marigold. The
challenge received a total of 24 submissions that outperformed the baselines on
the test set; 10 of these included a report describing their approach, with
most leading methods relying on affine-invariant predictions. The challenge
winners improved the 3D F-Score over the previous edition's best result,
raising it from 22.58% to 23.05%.

08 Mar 2024
Gaze estimation methods often experience significant performance degradation when evaluated across different domains, due to the domain gap between the testing and training data. Existing methods try to address this issue using various domain generalization approaches, but with little success because of the limited diversity of gaze datasets, such as appearance, wearable, and image quality. To overcome these limitations, we propose a novel framework called CLIP-Gaze that utilizes a pre-trained vision-language model to leverage its transferable knowledge. Our framework is the first to leverage the vision-and-language cross-modality approach for gaze estimation task. Specifically, we extract gaze-relevant feature by pushing it away from gaze-irrelevant features which can be flexibly constructed via language descriptions. To learn more suitable prompts, we propose a personalized context optimization method for text prompt tuning. Furthermore, we utilize the relationship among gaze samples to refine the distribution of gaze-relevant features, thereby improving the generalization capability of the gaze estimation model. Extensive experiments demonstrate the excellent performance of CLIP-Gaze over existing methods on four cross-domain evaluations.

14 Jul 2022
DavarOCR, developed by Hikvision Research Institute, is an open-source toolbox providing comprehensive support for Optical Character Recognition (OCR) and multi-modal document understanding tasks. It implements 19 advanced algorithms across 9 task forms, with 10 previously unavailable in other open-source frameworks, demonstrating performance gains (e.g., F1-Score of 87.08 for KIE) through multi-modal integration.

13 Nov 2024
The ability of gaze estimation models to generalize is often significantly hindered by various factors unrelated to gaze, especially when the training dataset is limited. Current strategies aim to address this challenge through different domain generalization techniques, yet they have had limited success due to the risk of overfitting when solely relying on value labels for regression. Recent progress in pre-trained vision-language models has motivated us to capitalize on the abundant semantic information available. We propose a novel approach in this paper, reframing the gaze estimation task as a vision-language alignment issue. Our proposed framework, named Language-Guided Gaze Estimation (LG-Gaze), learns continuous and geometry-sensitive features for gaze estimation benefit from the rich prior knowledges of vision-language models. Specifically, LG-Gaze aligns gaze features with continuous linguistic features through our proposed multimodal contrastive regression loss, which customizes adaptive weights for different negative samples. Furthermore, to better adapt to the labels for gaze estimation task, we propose a geometry-aware interpolation method to obtain more precise gaze embeddings. Through extensive experiments, we validate the efficacy of our framework in four different cross-domain evaluation tasks.

24 Mar 2021
RPVNet introduces a deep fusion network for LiDAR point cloud semantic segmentation that intelligently combines range, point, and voxel representations through an adaptive gated fusion module and efficient interaction mechanisms. The network achieved 70.3% mIoU on the SemanticKITTI benchmark, outperforming prior state-of-the-art methods while maintaining competitive computational efficiency.

12 May 2025
Researchers from Hikvision Research Institute introduce the Unbiased Evaluator, a causally-inspired framework using "Bags Of Atomic InTerventions" (BOAT) to assess Large Language Models. This new method effectively mitigates benchmark contamination and inherent evaluation biases by probing models' true understanding through manipulated inputs, leading to consistent performance drops for LLMs compared to traditional benchmarks and providing more reliable model rankings.

17 Oct 2017

Scene text recognition has been a hot research topic in computer vision due to its various applications. The state of the art is the attention-based encoder-decoder framework that learns the mapping between input images and output sequences in a purely data-driven way. However, we observe that existing attention-based methods perform poorly on complicated and/or low-quality images. One major reason is that existing methods cannot get accurate alignments between feature areas and targets for such images. We call this phenomenon "attention drift". To tackle this problem, in this paper we propose the FAN (the abbreviation of Focusing Attention Network) method that employs a focusing attention mechanism to automatically draw back the drifted attention. FAN consists of two major components: an attention network (AN) that is responsible for recognizing character targets as in the existing methods, and a focusing network (FN) that is responsible for adjusting attention by evaluating whether AN pays attention properly on the target areas in the images. Furthermore, different from the existing methods, we adopt a ResNet-based network to enrich deep representations of scene text images. Extensive experiments on various benchmarks, including the IIIT5k, SVT and ICDAR datasets, show that the FAN method substantially outperforms the existing methods.

01 Mar 2024

Modern deep neural networks (DNNs) are extremely powerful; however, this
comes at the price of increased depth and having more parameters per layer,
making their training and inference more computationally challenging. In an
attempt to address this key limitation, efforts have been devoted to the
compression (e.g., sparsification and/or quantization) of these large-scale
machine learning models, so that they can be deployed on low-power IoT devices.
In this paper, building upon recent advances in neural tangent kernel (NTK) and
random matrix theory (RMT), we provide a novel compression approach to wide and
fully-connected \emph{deep} neural nets. Specifically, we demonstrate that in
the high-dimensional regime where the number of data points and their
dimension are both large, and under a Gaussian mixture model for the data,
there exists \emph{asymptotic spectral equivalence} between the NTK matrices
for a large family of DNN models. This theoretical result enables "lossless"
compression of a given DNN to be performed, in the sense that the compressed
network yields asymptotically the same NTK as the original (dense and
unquantized) network, with its weights and activations taking values
\emph{only} in up to a scaling. Experiments on both synthetic
and real-world data are conducted to support the advantages of the proposed
compression scheme, with code available at
\url{this https URL}.

27 May 2022
Domain generalization (DG) is a fundamental yet very challenging research topic in machine learning. The existing arts mainly focus on learning domain-invariant features with limited source domains in a static model. Unfortunately, there is a lack of training-free mechanism to adjust the model when generalized to the agnostic target domains. To tackle this problem, we develop a brand-new DG variant, namely Dynamic Domain Generalization (DDG), in which the model learns to twist the network parameters to adapt the data from different domains. Specifically, we leverage a meta-adjuster to twist the network parameters based on the static model with respect to different data from different domains. In this way, the static model is optimized to learn domain-shared features, while the meta-adjuster is designed to learn domain-specific features. To enable this process, DomainMix is exploited to simulate data from diverse domains during teaching the meta-adjuster to adapt to the upcoming agnostic target domains. This learning mechanism urges the model to generalize to different agnostic target domains via adjusting the model without training. Extensive experiments demonstrate the effectiveness of our proposed method. Code is available at: this https URL

13 Aug 2021

Monocular depth estimation aims at predicting depth from a single image or video. Recently, self-supervised methods draw much attention since they are free of depth annotations and achieve impressive performance on several daytime benchmarks. However, they produce weird outputs in more challenging nighttime scenarios because of low visibility and varying illuminations, which bring weak textures and break brightness-consistency assumption, respectively. To address these problems, in this paper we propose a novel framework with several improvements: (1) we introduce Priors-Based Regularization to learn distribution knowledge from unpaired depth maps and prevent model from being incorrectly trained; (2) we leverage Mapping-Consistent Image Enhancement module to enhance image visibility and contrast while maintaining brightness consistency; and (3) we present Statistics-Based Mask strategy to tune the number of removed pixels within textureless regions, using dynamic statistics. Experimental results demonstrate the effectiveness of each component. Meanwhile, our framework achieves remarkable improvements and state-of-the-art results on two nighttime datasets.

09 Aug 2021
Nowadays advanced image editing tools and technical skills produce tampered images more realistically, which can easily evade image forensic systems and make authenticity verification of images more difficult. To tackle this challenging problem, we introduce TransForensics, a novel image forgery localization method inspired by Transformers. The two major components in our framework are dense self-attention encoders and dense correction modules. The former is to model global context and all pairwise interactions between local patches at different scales, while the latter is used for improving the transparency of the hidden layers and correcting the outputs from different branches. Compared to previous traditional and deep learning methods, TransForensics not only can capture discriminative representations and obtain high-quality mask predictions but is also not limited by tampering types and patch sequence orders. By conducting experiments on main benchmarks, we show that TransForensics outperforms the stateof-the-art methods by a large margin.

21 Jul 2024
Data-Free Knowledge Distillation (DFKD) has shown great potential in creating a compact student model while alleviating the dependency on real training data by synthesizing surrogate data. However, prior arts are seldom discussed under distribution shifts, which may be vulnerable in real-world applications. Recent Vision-Language Foundation Models, e.g., CLIP, have demonstrated remarkable performance in zero-shot out-of-distribution generalization, yet consuming heavy computation resources. In this paper, we discuss the extension of DFKD to Vision-Language Foundation Models without access to the billion-level image-text datasets. The objective is to customize a student model for distribution-agnostic downstream tasks with given category concepts, inheriting the out-of-distribution generalization capability from the pre-trained foundation models. In order to avoid generalization degradation, the primary challenge of this task lies in synthesizing diverse surrogate images driven by text prompts. Since not only category concepts but also style information are encoded in text prompts, we propose three novel Prompt Diversification methods to encourage image synthesis with diverse styles, namely Mix-Prompt, Random-Prompt, and Contrastive-Prompt. Experiments on out-of-distribution generalization datasets demonstrate the effectiveness of the proposed methods, with Contrastive-Prompt performing the best.
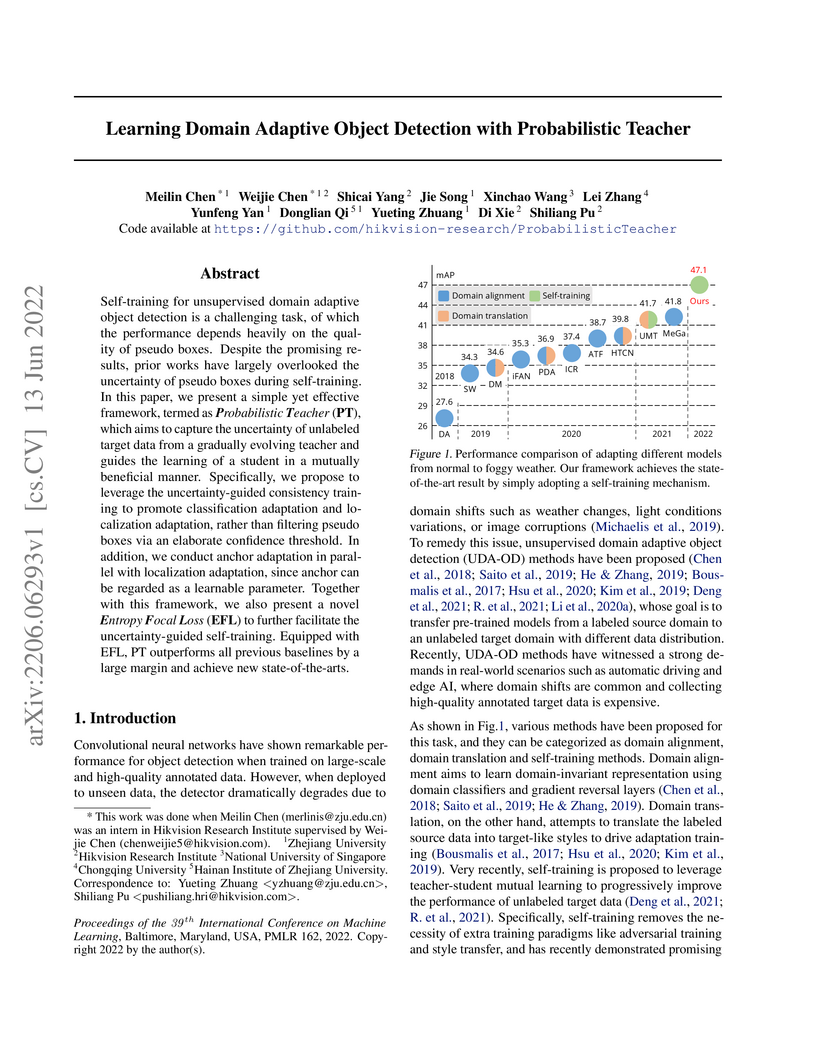
13 Jun 2022

Self-training for unsupervised domain adaptive object detection is a challenging task, of which the performance depends heavily on the quality of pseudo boxes. Despite the promising results, prior works have largely overlooked the uncertainty of pseudo boxes during self-training. In this paper, we present a simple yet effective framework, termed as Probabilistic Teacher (PT), which aims to capture the uncertainty of unlabeled target data from a gradually evolving teacher and guides the learning of a student in a mutually beneficial manner. Specifically, we propose to leverage the uncertainty-guided consistency training to promote classification adaptation and localization adaptation, rather than filtering pseudo boxes via an elaborate confidence threshold. In addition, we conduct anchor adaptation in parallel with localization adaptation, since anchor can be regarded as a learnable parameter. Together with this framework, we also present a novel Entropy Focal Loss (EFL) to further facilitate the uncertainty-guided self-training. Equipped with EFL, PT outperforms all previous baselines by a large margin and achieve new state-of-the-arts.

09 Oct 2022
Convolutional neural networks (CNNs) have demonstrated gratifying results at
learning discriminative features. However, when applied to unseen domains,
state-of-the-art models are usually prone to errors due to domain shift. After
investigating this issue from the perspective of shortcut learning, we find the
devils lie in the fact that models trained on different domains merely bias to
different domain-specific features yet overlook diverse task-related features.
Under this guidance, a novel Attention Diversification framework is proposed,
in which Intra-Model and Inter-Model Attention Diversification Regularization
are collaborated to reassign appropriate attention to diverse task-related
features. Briefly, Intra-Model Attention Diversification Regularization is
equipped on the high-level feature maps to achieve in-channel discrimination
and cross-channel diversification via forcing different channels to pay their
most salient attention to different spatial locations. Besides, Inter-Model
Attention Diversification Regularization is proposed to further provide
task-related attention diversification and domain-related attention
suppression, which is a paradigm of "simulate, divide and assemble": simulate
domain shift via exploiting multiple domain-specific models, divide attention
maps into task-related and domain-related groups, and assemble them within each
group respectively to execute regularization. Extensive experiments and
analyses are conducted on various benchmarks to demonstrate that our method
achieves state-of-the-art performance over other competing methods. Code is
available at this https URL

14 Jul 2022
Recently, automatically extracting information from visually rich documents (e.g., tickets and resumes) has become a hot and vital research topic due to its widespread commercial value. Most existing methods divide this task into two subparts: the text reading part for obtaining the plain text from the original document images and the information extraction part for extracting key contents. These methods mainly focus on improving the second, while neglecting that the two parts are highly correlated. This paper proposes a unified end-to-end information extraction framework from visually rich documents, where text reading and information extraction can reinforce each other via a well-designed multi-modal context block. Specifically, the text reading part provides multi-modal features like visual, textual and layout features. The multi-modal context block is developed to fuse the generated multi-modal features and even the prior knowledge from the pre-trained language model for better semantic representation. The information extraction part is responsible for generating key contents with the fused context features. The framework can be trained in an end-to-end trainable manner, achieving global optimization. What is more, we define and group visually rich documents into four categories across two dimensions, the layout and text type. For each document category, we provide or recommend the corresponding benchmarks, experimental settings and strong baselines for remedying the problem that this research area lacks the uniform evaluation standard. Extensive experiments on four kinds of benchmarks (from fixed layout to variable layout, from full-structured text to semi-unstructured text) are reported, demonstrating the proposed method's effectiveness. Data, source code and models are available.

06 Apr 2023
Domain shift degrades the performance of object detection models in practical
applications. To alleviate the influence of domain shift, plenty of previous
work try to decouple and learn the domain-invariant (common) features from
source domains via domain adversarial learning (DAL). However, inspired by
causal mechanisms, we find that previous methods ignore the implicit
insignificant non-causal factors hidden in the common features. This is mainly
due to the single-view nature of DAL. In this work, we present an idea to
remove non-causal factors from common features by multi-view adversarial
training on source domains, because we observe that such insignificant
non-causal factors may still be significant in other latent spaces (views) due
to the multi-mode structure of data. To summarize, we propose a Multi-view
Adversarial Discriminator (MAD) based domain generalization model, consisting
of a Spurious Correlations Generator (SCG) that increases the diversity of
source domain by random augmentation and a Multi-View Domain Classifier (MVDC)
that maps features to multiple latent spaces, such that the non-causal factors
are removed and the domain-invariant features are purified. Extensive
experiments on six benchmarks show our MAD obtains state-of-the-art
performance.
There are no more papers matching your filters at the moment.
