
10 Sep 2024
Researchers from Facephi and Hochschule Darmstadt developed a Few-Shot Learning (FSL) method, specifically Prototypical Networks with EfficientNetV2-B0, to detect presentation attacks on ID cards, focusing on screen display attacks. This approach enables robust detection in previously unknown countries by adapting with as few as five unique identities and under 100 images, significantly improving performance for unseen ID card types.

27 Jul 2025
This work summarises and reports the results of the second Presentation Attack Detection competition on ID cards. This new version includes new elements compared to the previous one. (1) An automatic evaluation platform was enabled for automatic benchmarking; (2) Two tracks were proposed in order to evaluate algorithms and datasets, respectively; and (3) A new ID card dataset was shared with Track 1 teams to serve as the baseline dataset for the training and optimisation. The Hochschule Darmstadt, Fraunhofer-IGD, and Facephi company jointly organised this challenge. 20 teams were registered, and 74 submitted models were evaluated. For Track 1, the "Dragons" team reached first place with an Average Ranking and Equal Error rate (EER) of AV-Rank of 40.48% and 11.44% EER, respectively. For the more challenging approach in Track 2, the "Incode" team reached the best results with an AV-Rank of 14.76% and 6.36% EER, improving on the results of the first edition of 74.30% and 21.87% EER, respectively. These results suggest that PAD on ID cards is improving, but it is still a challenging problem related to the number of images, especially of bona fide images.

31 Aug 2024
The inaugural PAD-IDCard competition at IJCB 2024 established a benchmark for Presentation Attack Detection (PAD) on ID cards, evaluating algorithms in a cross-dataset scenario. The organizers' private-data-trained baseline achieved an AV_rank of 9.10%, substantially outperforming the best competitor's AV_rank of 74.30%, highlighting the critical role of data access and diversity.

16 Apr 2024
 Michigan State University
Michigan State University Fudan UniversityIdiap Research InstituteUniversity of LjubljanaIIE, CAS
Fudan UniversityIdiap Research InstituteUniversity of LjubljanaIIE, CAS EPFLInstitute for Basic ScienceTencent YouTu LabUniversidade do PortoUniversity of CagliariSamsungUniversity of Science and TechnologyINESC TECHochschule DarmstadtFraunhofer IGDUniversidad Autonoma de MadridMAIS, CASIAUniversit ́e de LausanneKorea Advanced Institute of Science & TechnologyID R&D Inc.China Telecom AIunico - idTechFederal Institute of Mato GrossoInteractive Entertainment Group of Netease IncFederal University of Paran
a
EPFLInstitute for Basic ScienceTencent YouTu LabUniversidade do PortoUniversity of CagliariSamsungUniversity of Science and TechnologyINESC TECHochschule DarmstadtFraunhofer IGDUniversidad Autonoma de MadridMAIS, CASIAUniversit ́e de LausanneKorea Advanced Institute of Science & TechnologyID R&D Inc.China Telecom AIunico - idTechFederal Institute of Mato GrossoInteractive Entertainment Group of Netease IncFederal University of Paran
a

The Second Edition FRCSyn Challenge, a large-scale competition, evaluated face recognition systems using synthetic data, finding that unconstrained synthetic data can achieve performance comparable to real-data training for both bias mitigation and overall robustness, while combining synthetic and real data consistently yielded the strongest results.

31 May 2023
Face recognition systems have significantly advanced in recent years, driven
by the availability of large-scale datasets. However, several issues have
recently came up, including privacy concerns that have led to the
discontinuation of well-established public datasets. Synthetic datasets have
emerged as a solution, even though current synthesis methods present other
drawbacks such as limited intra-class variations, lack of realism, and unfair
representation of demographic groups. This study introduces GANDiffFace, a
novel framework for the generation of synthetic datasets for face recognition
that combines the power of Generative Adversarial Networks (GANs) and Diffusion
models to overcome the limitations of existing synthetic datasets. In
GANDiffFace, we first propose the use of GANs to synthesize highly realistic
identities and meet target demographic distributions. Subsequently, we
fine-tune Diffusion models with the images generated with GANs, synthesizing
multiple images of the same identity with a variety of accessories, poses,
expressions, and contexts. We generate multiple synthetic datasets by changing
GANDiffFace settings, and compare their mated and non-mated score distributions
with the distributions provided by popular real-world datasets for face
recognition, i.e. VGG2 and IJB-C. Our results show the feasibility of the
proposed GANDiffFace, in particular the use of Diffusion models to enhance the
(limited) intra-class variations provided by GANs towards the level of
real-world datasets.

07 Jan 2025
The assessment of face image quality is crucial to ensure reliable face recognition. In order to provide data subjects and operators with explainable and actionable feedback regarding captured face images, relevant quality components have to be measured. Quality components that are known to negatively impact the utility of face images include JPEG and JPEG 2000 compression artefacts, among others. Compression can result in a loss of important image details which may impair the recognition performance. In this work, deep neural networks are trained to detect the compression artefacts in a face images. For this purpose, artefact-free facial images are compressed with the JPEG and JPEG 2000 compression algorithms. Subsequently, the PSNR and SSIM metrics are employed to obtain training labels based on which neural networks are trained using a single network to detect JPEG and JPEG 2000 artefacts, respectively. The evaluation of the proposed method shows promising results: in terms of detection accuracy, error rates of 2-3% are obtained for utilizing PSNR labels during training. In addition, we show that error rates of different open-source and commercial face recognition systems can be significantly reduced by discarding face images exhibiting severe compression artefacts. To minimize resource consumption, EfficientNetV2 serves as basis for the presented algorithm, which is available as part of the OFIQ software.

22 Jul 2025
Although face recognition systems have undergone an impressive evolution in the last decade, these technologies are vulnerable to attack presentations (AP). These attacks are mostly easy to create and, by executing them against the system's capture device, the malicious actor can impersonate an authorised subject and thus gain access to the latter's information (e.g., financial transactions). To protect facial recognition schemes against presentation attacks, state-of-the-art deep learning presentation attack detection (PAD) approaches require a large amount of data to produce reliable detection performances and even then, they decrease their performance for unknown presentation attack instruments (PAI) or database (information not seen during training), i.e. they lack generalisability. To mitigate the above problems, this paper focuses on zero-shot PAD. To do so, we first assess the effectiveness and generalisability of foundation models in established and challenging experimental scenarios and then propose a simple but effective framework for zero-shot PAD. Experimental results show that these models are able to achieve performance in difficult scenarios with minimal effort of the more advanced PAD mechanisms, whose weights were optimised mainly with training sets that included APs and bona fide presentations. The top-performing foundation model outperforms by a margin the best from the state of the art observed with the leaving-one-out protocol on the SiW-Mv2 database, which contains challenging unknown 2D and 3D attacks

24 Apr 2023
Fitness for Duty (FFD) techniques detects whether a subject is Fit to perform their work safely, which means no reduced alertness condition and security, or if they are Unfit, which means alertness condition reduced by sleepiness or consumption of alcohol and drugs. Human iris behaviour provides valuable information to predict FFD since pupil and iris movements are controlled by the central nervous system and are influenced by illumination, fatigue, alcohol, and drugs. This work aims to classify FFD using sequences of 8 iris images and to extract spatial and temporal information using Convolutional Neural Networks (CNN) and Long Short Term Memory Networks (LSTM). Our results achieved a precision of 81.4\% and 96.9\% for the prediction of Fit and Unfit subjects, respectively. The results also show that it is possible to determine if a subject is under alcohol, drug, and sleepiness conditions. Sleepiness can be identified as the most difficult condition to be determined. This system opens a different insight into iris biometric applications.

17 Nov 2023
Michigan State UniversityIdiap Research InstituteIIE, CASTU DarmstadtUniversity of BolognaSchool of Artificial Intelligence, UCASUniversity of CagliariHochschule DarmstadtFraunhofer IGDUniversidad Autonoma de MadridHarokopio University of AthensCentre for Research and Technology HellasMAIS, CASIAunico - idTechFederal Institute of Mato GrossoCAIR, HKISI, CASSchool of Cyber Security, UCASFederal University of ParańaUniversit´e de LausanneFacephiLENS, Inc.["École Polytechnique Fédérale de Lausanne"]The FRCSyn Challenge at WACV 2024 established an international benchmark to assess synthetic data's utility in face recognition. It demonstrated that synthetic data can mitigate demographic biases and, when combined with real data, consistently enhances overall FR system performance across challenging conditions.
10 Oct 2024
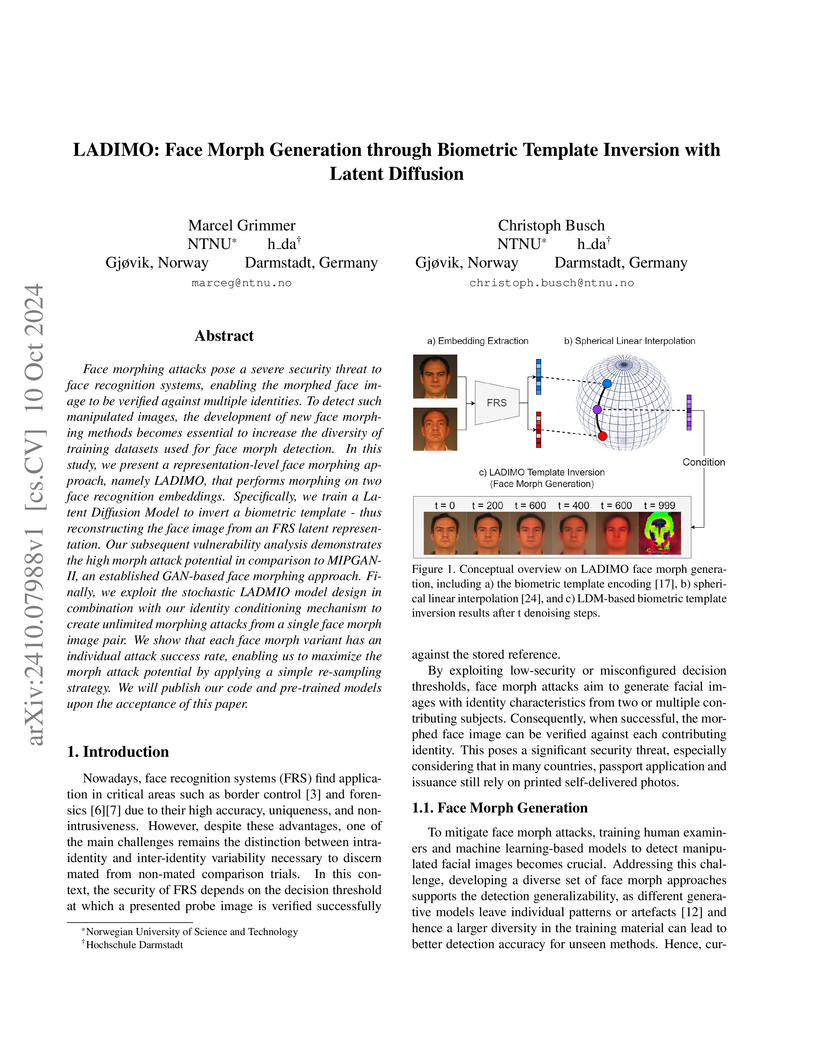
Face morphing attacks pose a severe security threat to face recognition systems, enabling the morphed face image to be verified against multiple identities. To detect such manipulated images, the development of new face morphing methods becomes essential to increase the diversity of training datasets used for face morph detection. In this study, we present a representation-level face morphing approach, namely LADIMO, that performs morphing on two face recognition embeddings. Specifically, we train a Latent Diffusion Model to invert a biometric template - thus reconstructing the face image from an FRS latent representation. Our subsequent vulnerability analysis demonstrates the high morph attack potential in comparison to MIPGAN-II, an established GAN-based face morphing approach. Finally, we exploit the stochastic LADMIO model design in combination with our identity conditioning mechanism to create unlimited morphing attacks from a single face morph image pair. We show that each face morph variant has an individual attack success rate, enabling us to maximize the morph attack potential by applying a simple re-sampling strategy. Code and pre-trained models available here: this https URL

27 Apr 2024
When decisions are made and when personal data is treated by automated
processes, there is an expectation of fairness -- that members of different
demographic groups receive equitable treatment. This expectation applies to
biometric systems such as automatic speaker verification (ASV). We present a
comparison of three candidate fairness metrics and extend previous work
performed for face recognition, by examining differential performance across a
range of different ASV operating points. Results show that the Gini Aggregation
Rate for Biometric Equitability (GARBE) is the only one which meets three
functional fairness measure criteria. Furthermore, a comprehensive evaluation
of the fairness and verification performance of five state-of-the-art ASV
systems is also presented. Our findings reveal a nuanced trade-off between
fairness and verification accuracy underscoring the complex interplay between
system design, demographic inclusiveness, and verification reliability.

09 Dec 2022



The BigScience Workshop was a value-driven initiative that spanned one and
half years of interdisciplinary research and culminated in the creation of
ROOTS, a 1.6TB multilingual dataset that was used to train BLOOM, one of the
largest multilingual language models to date. In addition to the technical
outcomes and artifacts, the workshop fostered multidisciplinary collaborations
around large models, datasets, and their analysis. This in turn led to a wide
range of research publications spanning topics from ethics to law, data
governance, modeling choices and distributed training. This paper focuses on
the collaborative research aspects of BigScience and takes a step back to look
at the challenges of large-scale participatory research, with respect to
participant diversity and the tasks required to successfully carry out such a
project. Our main goal is to share the lessons we learned from this experience,
what we could have done better and what we did well. We show how the impact of
such a social approach to scientific research goes well beyond the technical
artifacts that were the basis of its inception.

05 Jun 2025
Researchers explored whether Foundation Models, specifically DinoV2 and CLIP, can enhance the generalization capabilities of ID card Presentation Attack Detection (PAD) systems. Their findings indicate that DinoV2 significantly improves zero-shot and fine-tuned performance across diverse ID types and attack scenarios, particularly when trained with genuine bona fide data.

06 Jul 2024
Floods are an increasingly common global threat, causing emergencies and severe damage to infrastructure. During crises, organisations such as the World Food Programme use remotely sensed imagery, typically obtained through drones, for rapid situational analysis to plan life-saving actions. Computer Vision tools are needed to support task force experts on-site in the evaluation of the imagery to improve their efficiency and to allocate resources strategically. We introduce the BlessemFlood21 dataset to stimulate research on efficient flood detection tools. The imagery was acquired during the 2021 Erftstadt-Blessem flooding event and consists of high-resolution and georeferenced RGB-NIR images. In the resulting RGB dataset, the images are supplemented with detailed water masks, obtained via a semi-supervised human-in-the-loop technique, where in particular the NIR information is leveraged to classify pixels as either water or non-water. We evaluate our dataset by training and testing established Deep Learning models for semantic segmentation. With BlessemFlood21 we provide labeled high-resolution RGB data and a baseline for further development of algorithmic solutions tailored to flood detection in RGB imagery.

14 Mar 2025
Computed tomography from a low radiation dose (LDCT) is challenging due to
high noise in the projection data. Popular approaches for LDCT image
reconstruction are two-stage methods, typically consisting of the filtered
backprojection (FBP) algorithm followed by a neural network for LDCT image
enhancement. Two-stage methods are attractive for their simplicity and
potential for computational efficiency, typically requiring only a single FBP
and a neural network forward pass for inference. However, the best
reconstruction quality is currently achieved by unrolled iterative methods
(Learned Primal-Dual and ItNet), which are more complex and thus have a higher
computational cost for training and inference. We propose a method combining
the simplicity and efficiency of two-stage methods with state-of-the-art
reconstruction quality. Our strategy utilizes a neural network pretrained for
Gaussian noise removal from natural grayscale images, fine-tuned for LDCT image
enhancement. We call this method FBP-DTSGD (Domain and Task Shifted Gaussian
Denoisers) as the fine-tuning is a task shift from Gaussian denoising to
enhancing LDCT images and a domain shift from natural grayscale to LDCT images.
An ablation study with three different pretrained Gaussian denoisers indicates
that the performance of FBP-DTSGD does not depend on a specific denoising
architecture, suggesting future advancements in Gaussian denoising could
benefit the method. The study also shows that pretraining on natural images
enhances LDCT reconstruction quality, especially with limited training data.
Notably, pretraining involves no additional cost, as existing pretrained models
are used. The proposed method currently holds the top mean position in the
LoDoPaB-CT challenge.

31 Jan 2022
We investigate the potential of fusing human examiner decisions for the task
of digital face manipulation detection. To this end, various decision fusion
methods are proposed incorporating the examiners' decision confidence,
experience level, and their time to take a decision. Conducted experiments are
based on a psychophysical evaluation of digital face image manipulation
detection capabilities of humans in which different manipulation techniques
were applied, i.e. face morphing, face swapping and retouching. The decisions
of 223 participants were fused to simulate crowds of up to seven human
examiners. Experimental results reveal that (1) despite the moderate detection
performance achieved by single human examiners, a high accuracy can be obtained
through decision fusion and (2) a weighted fusion which takes the examiners'
decision confidence into account yields the most competitive detection
performance.

12 Dec 2023
We propose MCLFIQ: Mobile Contactless Fingerprint Image Quality, the first
quality assessment algorithm for mobile contactless fingerprint samples. To
this end, we re-trained the NIST Fingerprint Image Quality (NFIQ) 2 method,
which was originally designed for contact-based fingerprints, with a synthetic
contactless fingerprint database. We evaluate the predictive performance of the
resulting MCLFIQ model in terms of Error-vs.-Discard Characteristic (EDC)
curves on three real-world contactless fingerprint databases using three
recognition algorithms. In experiments, the MCLFIQ method is compared against
the original NFIQ 2.2 method, a sharpness-based quality assessment algorithm
developed for contactless fingerprint images \rev{and the general purpose image
quality assessment method BRISQUE. Furthermore, benchmarks on four
contact-based fingerprint datasets are also conducted.}
Obtained results show that the fine-tuning of NFIQ 2 on synthetic contactless
fingerprints is a viable alternative to training on real databases. Moreover,
the evaluation shows that our MCLFIQ method works more accurate and robust
compared to all baseline methods on contactless fingerprints. We suggest
considering the proposed MCLFIQ method as a \rev{starting point for the
development of} a new standard algorithm for contactless fingerprint quality
assessment.

17 Jul 2023
Traditional minutiae-based fingerprint representations consist of a variable-length set of minutiae. This necessitates a more complex comparison causing the drawback of high computational cost in one-to-many comparison. Recently, deep neural networks have been proposed to extract fixed-length embeddings from fingerprints. In this paper, we explore to what extent fingerprint texture information contained in such embeddings can be reduced in terms of dimension while preserving high biometric performance. This is of particular interest since it would allow to reduce the number of operations incurred at comparisons. We also study the impact in terms of recognition performance of the fingerprint textural information for two sensor types, i.e. optical and capacitive. Furthermore, the impact of rotation and translation of fingerprint images on the extraction of fingerprint embeddings is analysed. Experimental results conducted on a publicly available database reveal an optimal embedding size of 512 feature elements for the texture-based embedding part of fixed-length fingerprint representations. In addition, differences in performance between sensor types can be perceived.

23 Jan 2023
In this paper, an updated two-stage, end-to-end Presentation Attack Detection method for remote biometric verification systems of ID cards, based on MobileNetV2, is presented. Several presentation attack species such as printed, display, composite (based on cropped and spliced areas), plastic (PVC), and synthetic ID card images using different capture sources are used. This proposal was developed using a database consisting of 190.000 real case Chilean ID card images with the support of a third-party company. Also, a new framework called PyPAD, used to estimate multi-class metrics compliant with the ISO/IEC 30107-3 standard was developed, and will be made available for research purposes. Our method is trained on two convolutional neural networks separately, reaching BPCER\textsubscript{100} scores on ID cards attacks of 1.69\% and 2.36\% respectively. The two-stage method using both models together can reach a BPCER\textsubscript{100} score of 0.92\%.

31 Oct 2022
Currently, it is ever more common to access online services for activities which formerly required physical attendance. From banking operations to visa applications, a significant number of processes have been digitised, especially since the advent of the COVID-19 pandemic, requiring remote biometric authentication of the user. On the downside, some subjects intend to interfere with the normal operation of remote systems for personal profit by using fake identity documents, such as passports and ID cards. Deep learning solutions to detect such frauds have been presented in the literature. However, due to privacy concerns and the sensitive nature of personal identity documents, developing a dataset with the necessary number of examples for training deep neural networks is challenging. This work explores three methods for synthetically generating ID card images to increase the amount of data while training fraud-detection networks. These methods include computer vision algorithms and Generative Adversarial Networks. Our results indicate that databases can be supplemented with synthetic images without any loss in performance for the print/scan Presentation Attack Instrument Species (PAIS) and a loss in performance of 1% for the screen capture PAIS.
There are no more papers matching your filters at the moment.
