
17 Jun 2024

Randomized measurement protocols such as classical shadows represent powerful
resources for quantum technologies, with applications ranging from quantum
state characterization and process tomography to machine learning and error
mitigation. Recently, the notion of measurement dual frames, in which classical
shadows are generalized to dual operators of POVM effects, resurfaced in the
literature. This brought attention to additional degrees of freedom in the
post-processing stage of randomized measurements that are often neglected by
established techniques. In this work, we leverage dual frames to construct
improved observable estimators from informationally complete measurement
samples. We introduce novel classes of parametrized frame superoperators and
optimization-free dual frames based on empirical frequencies, which offer
advantages over their canonical counterparts while retaining computational
efficiency. Remarkably, this comes at almost no quantum or classical cost, thus
rendering dual frame optimization a valuable addition to the randomized
measurement toolbox.

10 Sep 2025

We present TerraMind, the first any-to-any generative, multimodal foundation model for Earth observation (EO). Unlike other multimodal models, TerraMind is pretrained on dual-scale representations combining both token-level and pixel-level data across modalities. On a token level, TerraMind encodes high-level contextual information to learn cross-modal relationships, while on a pixel level, TerraMind leverages fine-grained representations to capture critical spatial nuances. We pretrained TerraMind on nine geospatial modalities of a global, large-scale dataset. In this paper, we demonstrate that (i) TerraMind's dual-scale early fusion approach unlocks a range of zero-shot and few-shot applications for Earth observation, (ii) TerraMind introduces "Thinking-in-Modalities" (TiM) -- the capability of generating additional artificial data during finetuning and inference to improve the model output -- and (iii) TerraMind achieves beyond state-of-the-art performance in community-standard benchmarks for EO like PANGAEA. The pretraining dataset, the model weights, and our code are open-sourced under a permissive license.

25 Jan 2024
With the widespread digitization of finance and the increasing popularity of cryptocurrencies, the sophistication of fraud schemes devised by cybercriminals is growing. Money laundering -- the movement of illicit funds to conceal their origins -- can cross bank and national boundaries, producing complex transaction patterns. The UN estimates 2-5\% of global GDP or \0.8 - \2.0 trillion dollars are laundered globally each year. Unfortunately, real data to train machine learning models to detect laundering is generally not available, and previous synthetic data generators have had significant shortcomings. A realistic, standardized, publicly-available benchmark is needed for comparing models and for the advancement of the area.
To this end, this paper contributes a synthetic financial transaction dataset generator and a set of synthetically generated AML (Anti-Money Laundering) datasets. We have calibrated this agent-based generator to match real transactions as closely as possible and made the datasets public. We describe the generator in detail and demonstrate how the datasets generated can help compare different machine learning models in terms of their AML abilities. In a key way, using synthetic data in these comparisons can be even better than using real data: the ground truth labels are complete, whilst many laundering transactions in real data are never detected.

12 Mar 2025




While numerous recent benchmarks focus on evaluating generic Vision-Language
Models (VLMs), they do not effectively address the specific challenges of
geospatial applications. Generic VLM benchmarks are not designed to handle the
complexities of geospatial data, an essential component for applications such
as environmental monitoring, urban planning, and disaster management. Key
challenges in the geospatial domain include temporal change detection,
large-scale object counting, tiny object detection, and understanding
relationships between entities in remote sensing imagery. To bridge this gap,
we present GEOBench-VLM, a comprehensive benchmark specifically designed to
evaluate VLMs on geospatial tasks, including scene understanding, object
counting, localization, fine-grained categorization, segmentation, and temporal
analysis. Our benchmark features over 10,000 manually verified instructions and
spanning diverse visual conditions, object types, and scales. We evaluate
several state-of-the-art VLMs to assess performance on geospatial-specific
challenges. The results indicate that although existing VLMs demonstrate
potential, they face challenges when dealing with geospatial-specific tasks,
highlighting the room for further improvements. Notably, the best-performing
LLaVa-OneVision achieves only 41.7% accuracy on MCQs, slightly more than
GPT-4o, which is approximately double the random guess performance. Our
benchmark is publicly available at
this https URL .

19 Jun 2024
We describe Qiskit, a software development kit for quantum information science. We discuss the key design decisions that have shaped its development, and examine the software architecture and its core components. We demonstrate an end-to-end workflow for solving a problem in condensed matter physics on a quantum computer that serves to highlight some of Qiskit's capabilities, for example the representation and optimization of circuits at various abstraction levels, its scalability and retargetability to new gates, and the use of quantum-classical computations via dynamic circuits. Lastly, we discuss some of the ecosystem of tools and plugins that extend Qiskit for various tasks, and the future ahead.

04 Aug 2023
TEXT2KGBENCH introduces a benchmark to assess Large Language Models' (LLMs) capacity for generating Knowledge Graphs from text while adhering to explicit ontological schemas. The benchmark provides two datasets and metrics, revealing that current LLMs exhibit high ontology conformance but moderate fact extraction accuracy.

25 Sep 2025
Artificial Intelligence (AI) Foundation models (FMs), pre-trained on massive unlabelled datasets, have the potential to drastically change AI applications in ocean science, where labelled data are often sparse and expensive to collect. In this work, we describe a new foundation model using the Prithvi-EO Vision Transformer architecture which has been pre-trained to reconstruct data from the Sentinel-3 Ocean and Land Colour Instrument (OLCI). We evaluate the model by fine-tuning on two downstream marine earth observation tasks. We first assess model performance compared to current baseline models used to quantify chlorophyll concentration. We then evaluate the FMs ability to refine remote sensing-based estimates of ocean primary production. Our results demonstrate the utility of self-trained FMs for marine monitoring, in particular for making use of small amounts of high quality labelled data and in capturing detailed spatial patterns of ocean colour whilst matching point observations. We conclude that this new generation of geospatial AI models has the potential to provide more robust, data-driven insights into ocean ecosystems and their role in global climate processes.

20 Oct 2023
With privacy legislation empowering the users with the right to be forgotten, it has become essential to make a model amenable for forgetting some of its training data. However, existing unlearning methods in the machine learning context can not be directly applied in the context of distributed settings like federated learning due to the differences in learning protocol and the presence of multiple actors. In this paper, we tackle the problem of federated unlearning for the case of erasing a client by removing the influence of their entire local data from the trained global model. To erase a client, we propose to first perform local unlearning at the client to be erased, and then use the locally unlearned model as the initialization to run very few rounds of federated learning between the server and the remaining clients to obtain the unlearned global model. We empirically evaluate our unlearning method by employing multiple performance measures on three datasets, and demonstrate that our unlearning method achieves comparable performance as the gold standard unlearning method of federated retraining from scratch, while being significantly efficient. Unlike prior works, our unlearning method neither requires global access to the data used for training nor the history of the parameter updates to be stored by the server or any of the clients.

25 Feb 2025

Large language model (LLM) serving is becoming an increasingly critical
workload for cloud providers. Existing LLM serving systems focus on interactive
requests, such as chatbots and coding assistants, with tight latency SLO
requirements. However, when such systems execute batch requests that have
relaxed SLOs along with interactive requests, it leads to poor multiplexing and
inefficient resource utilization. To address these challenges, we propose QLM,
a queue management system for LLM serving. QLM maintains batch and interactive
requests across different models and SLOs in a request queue. Optimal ordering
of the request queue is critical to maintain SLOs while ensuring high resource
utilization. To generate this optimal ordering, QLM uses a Request Waiting Time
(RWT) Estimator that estimates the waiting times for requests in the request
queue. These estimates are used by a global scheduler to orchestrate LLM
Serving Operations (LSOs) such as request pulling, request eviction, load
balancing, and model swapping. Evaluation on heterogeneous GPU devices and
models with real-world LLM serving dataset shows that QLM improves SLO
attainment by 40-90% and throughput by 20-400% while maintaining or improving
device utilization compared to other state-of-the-art LLM serving systems.
QLM's evaluation is based on the production requirements of a cloud provider.
QLM is publicly available at this https URL

01 Oct 2025
 University of Michigan
University of Michigan RIKEN
RIKEN Technical University of Munich
Technical University of Munich Chalmers University of TechnologyForschungszentrum Jülich GmbHNational Institute of Advanced Industrial Science and Technology (AIST)IBM Research EuropeUnitary FundPlaksha UniversityAberystwyth UniversityZurich InstrumentsRakutenUniversity of GdañskIBM, T.J. Watson Research CenterUniversit
de Sherbrooke
Chalmers University of TechnologyForschungszentrum Jülich GmbHNational Institute of Advanced Industrial Science and Technology (AIST)IBM Research EuropeUnitary FundPlaksha UniversityAberystwyth UniversityZurich InstrumentsRakutenUniversity of GdañskIBM, T.J. Watson Research CenterUniversit
de SherbrookeQuTiP, the Quantum Toolbox in Python, has been at the forefront of open-source quantum software for the past 13 years. It is used as a research, teaching, and industrial tool, and has been downloaded millions of times by users around the world. Here we introduce the latest developments in QuTiP v5, which are set to have a large impact on the future of QuTiP and enable it to be a modern, continuously developed and popular tool for another decade and more. We summarize the code design and fundamental data layer changes as well as efficiency improvements, new solvers, applications to quantum circuits with QuTiP-QIP, and new quantum control tools with QuTiP-QOC. Additional flexibility in the data layer underlying all ``quantum objects'' in QuTiP allows us to harness the power of state-of-the-art data formats and packages like JAX, CuPy, and more. We explain these new features with a series of both well-known and new examples. The code for these examples is available in a static form on GitHub and as continuously updated and documented notebooks in the qutip-tutorials package.

31 Mar 2025
IBM Research and Hartree Centre researchers develop TrajCast, an autoregressive equivariant network framework that enables molecular dynamics simulations without force calculations, achieving 10-30x larger timesteps while accurately reproducing structural and dynamical properties across molecular, crystalline, and liquid systems with minimal training data.

08 Sep 2025
We present a study on how and where personas -- defined by distinct sets of human characteristics, values, and beliefs -- are encoded in the representation space of large language models (LLMs). Using a range of dimension reduction and pattern recognition methods, we first identify the model layers that show the greatest divergence in encoding these representations. We then analyze the activations within a selected layer to examine how specific personas are encoded relative to others, including their shared and distinct embedding spaces. We find that, across multiple pre-trained decoder-only LLMs, the analyzed personas show large differences in representation space only within the final third of the decoder layers. We observe overlapping activations for specific ethical perspectives -- such as moral nihilism and utilitarianism -- suggesting a degree of polysemy. In contrast, political ideologies like conservatism and liberalism appear to be represented in more distinct regions. These findings help to improve our understanding of how LLMs internally represent information and can inform future efforts in refining the modulation of specific human traits in LLM outputs. Warning: This paper includes potentially offensive sample statements.

19 Nov 2025

Geospatial Foundation Models (GeoFMs) are transforming Earth Observation (EO), but evaluation lacks standardized protocols. GEO-Bench-2 addresses this with a comprehensive framework spanning classification, segmentation, regression, object detection, and instance segmentation across 19 permissively-licensed datasets. We introduce ''capability'' groups to rank models on datasets that share common characteristics (e.g., resolution, bands, temporality). This enables users to identify which models excel in each capability and determine which areas need improvement in future work. To support both fair comparison and methodological innovation, we define a prescriptive yet flexible evaluation protocol. This not only ensures consistency in benchmarking but also facilitates research into model adaptation strategies, a key and open challenge in advancing GeoFMs for downstream tasks.
Our experiments show that no single model dominates across all tasks, confirming the specificity of the choices made during architecture design and pretraining. While models pretrained on natural images (ConvNext ImageNet, DINO V3) excel on high-resolution tasks, EO-specific models (TerraMind, Prithvi, and Clay) outperform them on multispectral applications such as agriculture and disaster response. These findings demonstrate that optimal model choice depends on task requirements, data modalities, and constraints. This shows that the goal of a single GeoFM model that performs well across all tasks remains open for future research. GEO-Bench-2 enables informed, reproducible GeoFM evaluation tailored to specific use cases. Code, data, and leaderboard for GEO-Bench-2 are publicly released under a permissive license.

01 Aug 2025
Large-scale foundation models in Earth Observation can learn versatile, label-efficient representations by leveraging massive amounts of unlabeled data. However, existing public datasets are often limited in scale, geographic coverage, or sensor variety. We introduce TerraMesh, a new globally diverse, multimodal dataset combining optical, synthetic aperture radar, elevation, and land-cover modalities in an Analysis-Ready Data format. TerraMesh includes over 9~million samples with eight spatiotemporal aligned modalities, enabling large-scale pre-training. We provide detailed data processing steps, comprehensive statistics, and empirical evidence demonstrating improved model performance when pre-trained on TerraMesh. The dataset is hosted at this https URL.

14 Oct 2025
Earth observation (EO) satellites produce massive streams of multispectral image time series, posing pressing challenges for storage and transmission. Yet, learned EO compression remains fragmented, lacking publicly available pretrained models and misaligned with advances in compression for natural imagery. Image codecs overlook temporal redundancy, while video codecs rely on motion priors that fail to capture the radiometric evolution of largely static scenes. We introduce TerraCodec (TEC), a family of learned codecs tailored to EO. TEC includes efficient image-based variants adapted to multispectral inputs, as well as a Temporal Transformer model (TEC-TT) that leverages dependencies across time. To overcome the fixed-rate setting of today's neural codecs, we present Latent Repacking, a novel method for training flexible-rate transformer models that operate on varying rate-distortion settings. Trained on Sentinel-2 data, TerraCodec outperforms classical codecs, achieving 3-10x stronger compression at equivalent image quality. Beyond compression, TEC-TT enables zero-shot cloud inpainting, surpassing state-of-the-art methods on the AllClear benchmark. Our results establish bespoke, learned compression algorithms as a promising direction for Earth observation. Code and model weights will be released under a permissive license.

05 Jun 2024
 CNRS
CNRS Google DeepMind
Google DeepMind University of Cambridge
University of Cambridge UCLA
UCLA Stanford University
Stanford University Cornell University
Cornell University Yale University
Yale University University of PennsylvaniaCity University of New York
University of PennsylvaniaCity University of New York Université Paris-SaclayMax Planck Institute for the Science of LightPolitecnico di MilanoNTT Research Inc.IBM Research EuropeSwiss Federal Institute of Technology in Lausanne (EPFL)Rain AIUniversity Bourgogne Franche-ComtéUniv-Rennes
Université Paris-SaclayMax Planck Institute for the Science of LightPolitecnico di MilanoNTT Research Inc.IBM Research EuropeSwiss Federal Institute of Technology in Lausanne (EPFL)Rain AIUniversity Bourgogne Franche-ComtéUniv-Rennes
This paper offers a comprehensive review of training methodologies for Physical Neural Networks (PNNs), addressing the escalating energy and performance demands of digital AI. It systematically categorizes diverse training approaches, from physics-aware backpropagation to in-situ gradient computation, and evaluates their potential to enable energy-efficient, scalable AI systems.

11 Nov 2024

Researchers at [Lab/Institution Not Specified] introduce HarmLevelBench, a framework for evaluating Large Language Model vulnerabilities with fine-grained harm levels across 7 topics and 8 severity degrees. Their investigation reveals that model quantization can paradoxically increase vulnerability to some direct attacks while enhancing robustness against transferred adversarial attacks, impacting LLM safety and deployment strategies.

04 Jan 2024
This paper analyses a set of simple adaptations that transform standard
message-passing Graph Neural Networks (GNN) into provably powerful directed
multigraph neural networks. The adaptations include multigraph port numbering,
ego IDs, and reverse message passing. We prove that the combination of these
theoretically enables the detection of any directed subgraph pattern. To
validate the effectiveness of our proposed adaptations in practice, we conduct
experiments on synthetic subgraph detection tasks, which demonstrate
outstanding performance with almost perfect results. Moreover, we apply our
proposed adaptations to two financial crime analysis tasks. We observe dramatic
improvements in detecting money laundering transactions, improving the
minority-class F1 score of a standard message-passing GNN by up to 30%, and
closely matching or outperforming tree-based and GNN baselines. Similarly
impressive results are observed on a real-world phishing detection dataset,
boosting three standard GNNs' F1 scores by around 15% and outperforming all
baselines.
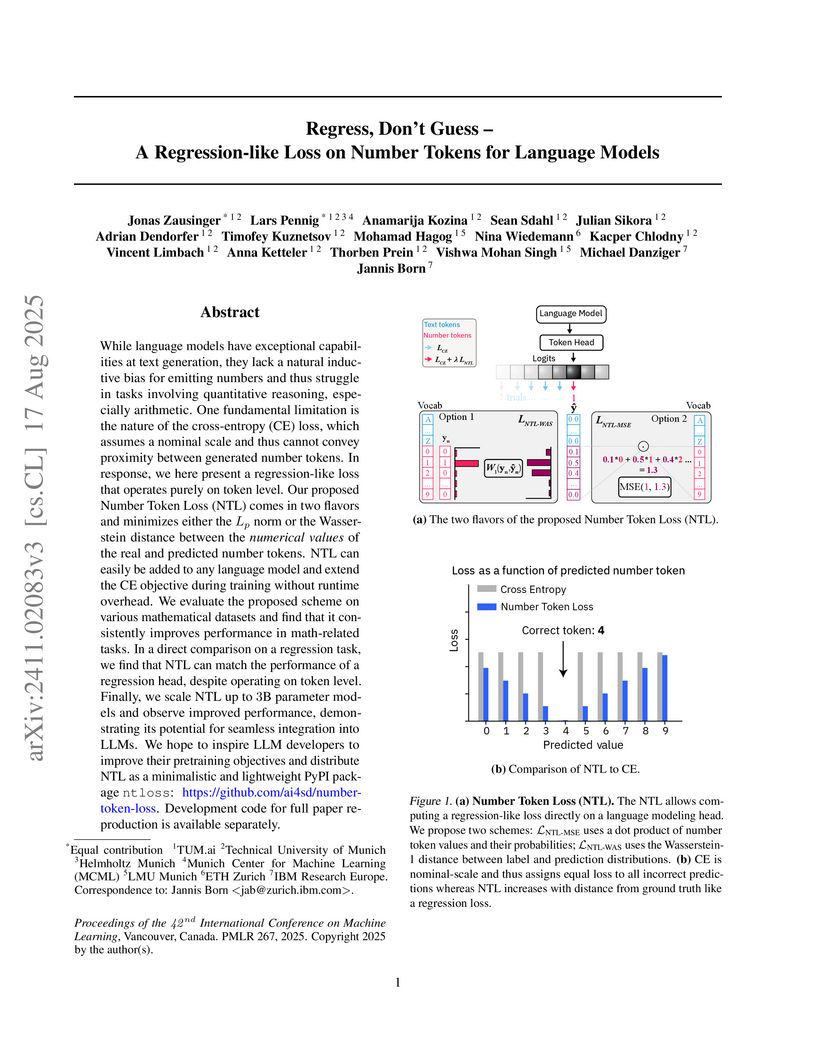
17 Aug 2025
The Number Token Loss (NTL) offers a training-free, regression-like loss function to enhance language models' intrinsic numerical reasoning by directly modeling numerical proximity at the token level. This method robustly improves arithmetic capabilities and general numerical accuracy across diverse model scales and architectures, evidenced by a 0.75 accuracy on arithmetic interpolation tasks with T5-Base and a 17.7% top-1 accuracy on GSM8k with T5-3B.

05 Mar 2024
This paper introduces a novel methodology for Feature Selection for
Functional Classification, FSFC, that addresses the challenge of jointly
performing feature selection and classification of functional data in scenarios
with categorical responses and multivariate longitudinal features. FSFC tackles
a newly defined optimization problem that integrates logistic loss and
functional features to identify the most crucial variables for classification.
To address the minimization procedure, we employ functional principal
components and develop a new adaptive version of the Dual Augmented Lagrangian
algorithm. The computational efficiency of FSFC enables handling
high-dimensional scenarios where the number of features may considerably exceed
the number of statistical units. Simulation experiments demonstrate that FSFC
outperforms other machine learning and deep learning methods in computational
time and classification accuracy. Furthermore, the FSFC feature selection
capability can be leveraged to significantly reduce the problem's
dimensionality and enhance the performances of other classification algorithms.
The efficacy of FSFC is also demonstrated through a real data application,
analyzing relationships between four chronic diseases and other health and
demographic factors.
There are no more papers matching your filters at the moment.
