Ask or search anything...
FlashSloth, developed by researchers from Xiamen University, Tencent Youtu Lab, and Shanghai AI Laboratory, introduces a Multimodal Large Language Model (MLLM) architecture that significantly improves efficiency through embedded visual compression. The approach reduces visual tokens by 80-89% and achieves 2-5 times faster response times, while maintaining highly competitive performance across various vision-language benchmarks.
View blog
The paper introduces LEAP, a framework for Hierarchical Federated Learning (HFL) that addresses non-IID data challenges and communication resource allocation in IoT environments. LEAP improves model accuracy by up to 20.62% over clustering baselines and reduces transmission energy consumption by at least 2.24 times while meeting latency requirements.
View blog
 Southern University of Science and Technology
Southern University of Science and TechnologyResearchers from Xiamen University, Southern University of Science and Technology, and Alibaba Group developed Tree-GRPO, an online reinforcement learning method that uses tree search to efficiently train large language model agents. This approach provides fine-grained process supervision from sparse outcome rewards and achieves superior performance with a quarter of the rollout budget compared to chain-based methods.
View blog
DEIMv2 introduces a real-time object detection framework that effectively integrates DINOv3 features, establishing new state-of-the-art accuracy-efficiency trade-offs across eight model scales, from ultra-lightweight (0.49M parameters) to high-performance (57.8 AP). The approach adeptly adapts single-scale Vision Transformer outputs for multi-scale detection while optimizing the decoder and training process.
View blog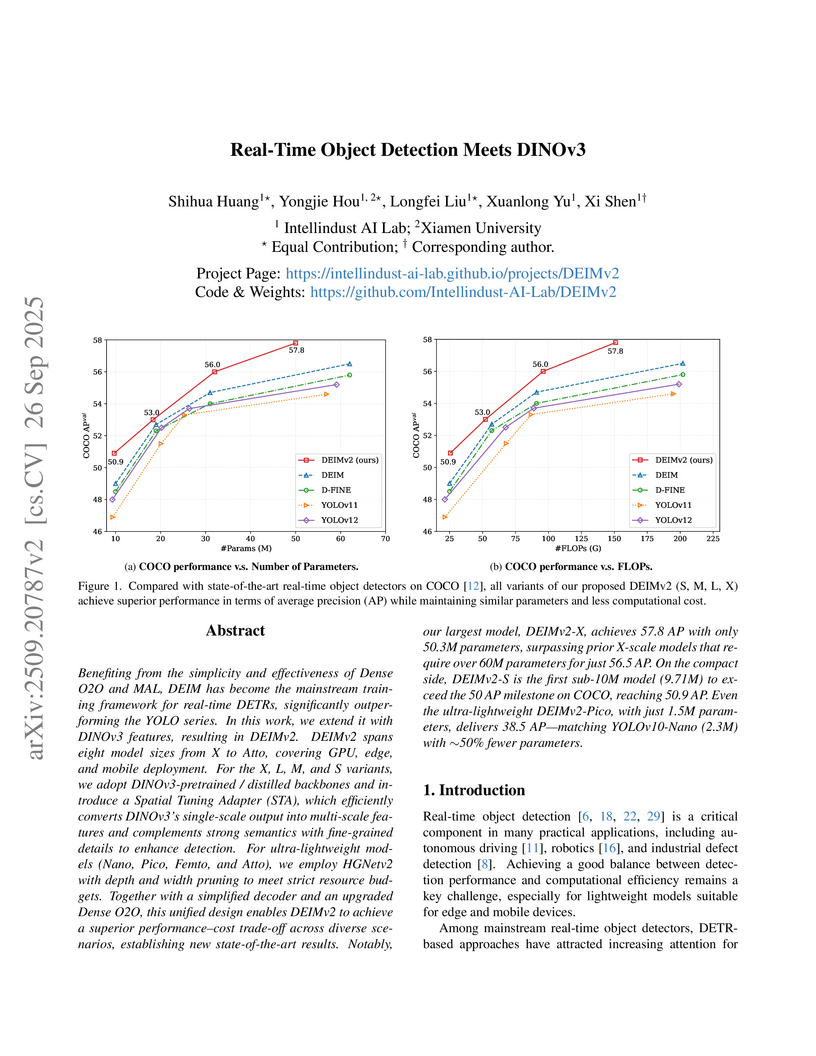
 Shanghai Jiao Tong University
Shanghai Jiao Tong UniversityFastVGGT introduces a training-free token merging approach to accelerate the Visual Geometry Grounded Transformer (VGGT) for long-sequence 3D reconstruction. It achieves up to a 4x speedup in inference time while maintaining or improving reconstruction accuracy and reducing camera pose estimation errors for sequences of up to 1000 images.
View blog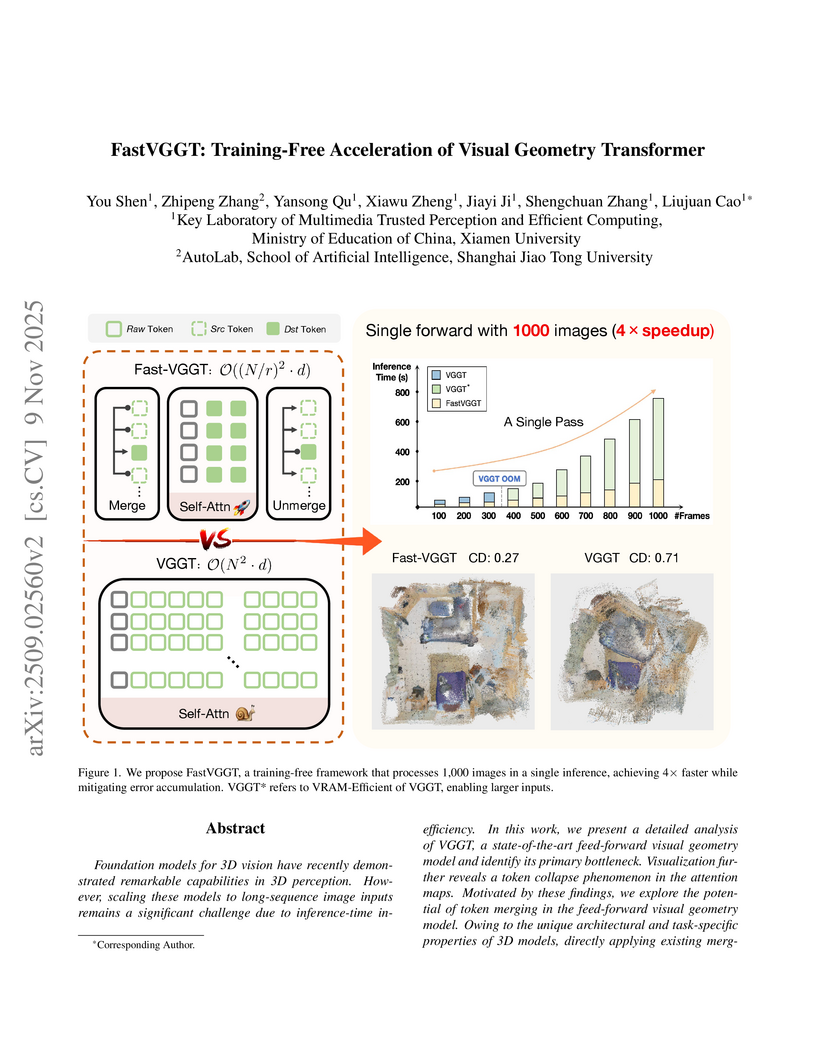
 Nanjing University
Nanjing UniversityMetaGPT introduces a meta-programming framework that simulates a software company with specialized LLM agents following Standardized Operating Procedures (SOPs) and an assembly line paradigm. The system significantly improves the coherence, accuracy, and executability of generated code for complex software development tasks, achieving state-of-the-art results on benchmarks like HumanEval and MBPP, and outperforming other multi-agent systems on a comprehensive software development dataset.
View blog


 The Hong Kong Polytechnic University
The Hong Kong Polytechnic UniversityResearchers from Xiamen University and The Hong Kong Polytechnic University developed GraphRAG-Bench, a new benchmark to systematically evaluate graph-based Retrieval-Augmented Generation (GraphRAG). Their analysis reveals that GraphRAG excels in complex reasoning and creative generation tasks but faces efficiency challenges and can underperform vanilla RAG on simpler fact retrieval, underscoring the importance of task complexity and graph quality.
View blog
 University of Science and Technology of China
University of Science and Technology of ChinaMCP-Zero introduces an active tool discovery framework that enables large language model (LLM) agents to dynamically identify and request external tools on demand. This approach reduces token consumption by up to 98% and maintains high tool selection accuracy even when presented with thousands of potential tools, thereby enhancing the scalability and efficiency of LLM agents.
View blog
 Fudan University
Fudan UniversityFlashWorld enables high-quality 3D scene generation from a single image or text prompt within seconds, achieving a 10-100x speedup over previous methods while delivering superior visual fidelity and consistent 3D structures. The model recovers intricate details and produces realistic backgrounds even for complex scenes, demonstrating strong performance across image-to-3D and text-to-3D tasks.
View blog

 University of Southern California
University of Southern California Microsoft
MicrosoftResearchers from IDEA Research, Xiamen University, and other institutions developed Think-on-Graph (ToG), a training-free framework that tightly couples Large Language Models (LLMs) with Knowledge Graphs (KGs). ToG enables LLMs to perform iterative, explainable deep reasoning by actively exploring KG paths through a beam search process, achieving state-of-the-art performance on multiple knowledge-intensive QA datasets and reducing hallucination.
View blog

 National University of Singapore
National University of Singapore Zhejiang University
Zhejiang UniversityThis survey provides the first systematic review of multimodal long-context token compression, categorizing techniques across images, videos, and audio by both modality and algorithmic mechanism. It reveals how diverse compression strategies address the quadratic complexity of self-attention in Multimodal Large Language Models (MLLMs), improving efficiency and enabling new applications like real-time robotic perception and high-resolution medical image analysis.
View blog
MME introduces a new comprehensive benchmark to quantitatively evaluate Multimodal Large Language Models (MLLMs), featuring manually constructed, leakage-free instruction-answer pairs across 14 perception and cognition subtasks. The benchmark assesses 30 MLLMs, revealing significant performance gaps and identifying prevalent issues such as instruction non-compliance, perceptual failures, reasoning breakdowns, and object hallucination.
View blog
VR-Bench, a new benchmark, is introduced to evaluate the spatial reasoning capabilities of video generation models through diverse maze-solving tasks. The paper demonstrates that fine-tuned video models can perform robust spatial reasoning, often outperforming Vision-Language Models, and exhibit strong generalization and a notable test-time scaling effect.
View blog
 University of Washington
University of Washington The Chinese University of Hong Kong
The Chinese University of Hong KongDynamicVerse, developed by researchers from Xiamen University, Meta, and other institutions, introduces a physically-aware multimodal framework for 4D world modeling. It establishes DynamicGen, an automated pipeline that generates a large-scale 4D dataset comprising over 100K scenes from internet videos, annotated with metric-scale 3D geometry, precise camera parameters, object masks, and hierarchical captions. The framework achieves state-of-the-art results in video depth, camera pose, and camera intrinsics estimation, while also producing high-quality semantic descriptions.
View blog


 Tsinghua University
Tsinghua UniversityRHO-1 introduces Selective Language Modeling (SLM), a pre-training approach that selectively applies loss to high-value tokens, achieving significant data and compute efficiency while improving performance in large language models, particularly in mathematical reasoning. It demonstrated a 97% reduction in effective pre-training tokens to reach similar state-of-the-art math performance compared to baselines.
View blog
 Renmin University of China
Renmin University of China Nanyang Technological University
Nanyang Technological University

 Chinese Academy of Sciences
Chinese Academy of Sciences University of Notre Dame
University of Notre DameData Interpreter is an LLM agent framework developed by DeepWisdom and Mila, designed to automate end-to-end data science workflows through hierarchical planning and dynamic tool integration. It achieved 94.93% accuracy on InfiAgent-DABench with `gpt-4o`, representing a 19.01% absolute improvement over direct `gpt-4o` inference, and scored 0.95 on ML-Benchmark, outperforming AutoGen and OpenDevin while being more cost-efficient.
View blog
 University of Texas at Austin
University of Texas at AustinLightGaussian introduces a multi-stage pipeline to compress 3D Gaussian Splatting models, achieving an average 15x storage reduction and boosting rendering speeds to over 200 FPS while largely maintaining visual quality. This method addresses the storage overhead and rendering efficiency of large-scale 3D scene representations.
View blog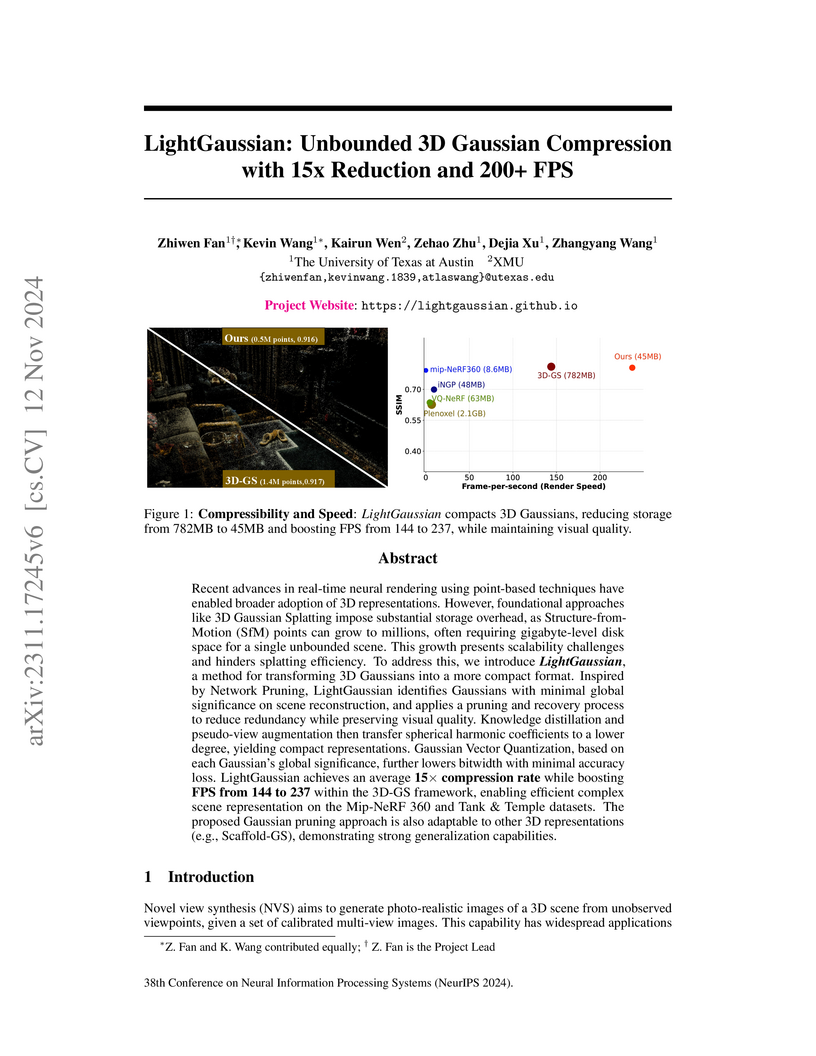

AIGI-Holmes introduces a method for detecting AI-generated images that provides both accurate identification and human-aligned explanations. The approach leverages a novel dataset (Holmes-Set) and a multi-stage training pipeline to enhance Multimodal Large Language Models (MLLMs), achieving 99.2% accuracy on unseen AI-generated images and producing verifiable explanations that surpass existing MLLMs in quality and human alignment.
View blog