
15 Feb 2025
This review paper from Isfahan University of Technology surveys unpaired image-to-image translation methods, introducing a taxonomy that classifies tasks based on the degree of content preservation required. It also establishes a Sim-to-Real benchmark and demonstrates how hyperparameter choices influence content fidelity and overall performance in practical applications.

29 Aug 2025
Drug discovery is a complex and resource-intensive process, making early prediction of approval outcomes critical for optimizing research investments. While classical machine learning and deep learning methods have shown promise in drug approval prediction, their limited interpretability constraints their impact. Here, we present DrugReasoner, a reasoning-based large language model (LLM) built on the LLaMA architecture and fine-tuned with group relative policy optimization (GRPO) to predict the likelihood of small-molecule approval. DrugReasoner integrates molecular descriptors with comparative reasoning against structurally similar approved and unapproved compounds, generating predictions alongside step-by-step rationales and confidence scores. DrugReasoner achieved robust performance with an AUC of 0.732 and an F1 score of 0.729 on the validation set and 0.725 and 0.718 on the test set, respectively. These results outperformed conventional baselines, including logistic regression, support vector machine, and k-nearest neighbors and had competitive performance relative to XGBoost. On an external independent dataset, DrugReasoner outperformed both baseline and the recently developed ChemAP model, achieving an AUC of 0.728 and an F1-score of 0.774, while maintaining high precision and balanced sensitivity, demonstrating robustness in real-world scenarios. These findings demonstrate that DrugReasoner not only delivers competitive predictive accuracy but also enhances transparency through its reasoning outputs, thereby addressing a key bottleneck in AI-assisted drug discovery. This study highlights the potential of reasoning-augmented LLMs as interpretable and effective tools for pharmaceutical decision-making.

03 Aug 2025

The use of CLIP embeddings to assess the fidelity of samples produced by text-to-image generative models has been extensively explored in the literature. While the widely adopted CLIPScore, derived from the cosine similarity of text and image embeddings, effectively measures the alignment of a generated image, it does not quantify the diversity of images generated by a text-to-image model. In this work, we extend the application of CLIP embeddings to quantify and interpret the intrinsic diversity of text-to-image models, which are responsible for generating diverse images from similar text prompts, which we refer to as prompt-aware diversity. To achieve this, we propose a decomposition of the CLIP-based kernel covariance matrix of image data into text-based and non-text-based components. Using the Schur complement of the joint image-text kernel covariance matrix, we perform this decomposition and define the matrix-based entropy of the decomposed component as the Schur Complement ENtopy DIversity (Scendi) score, as a measure of the prompt-aware diversity for prompt-guided generative models. Additionally, we discuss the application of the Schur complement-based decomposition to nullify the influence of a given prompt on the CLIP embedding of an image, enabling focus or defocus of the embedded vectors on specific objects. We present several numerical results that apply our proposed Scendi score to evaluate text-to-image and LLM (text-to-text) models. Our numerical results indicate the success of the Scendi score in capturing the intrinsic diversity of prompt-guided generative models. The codebase is available at this https URL.

05 Nov 2024
A method termed FKEA (Fourier-based Kernel Entropy Approximation) enables efficient estimation of reference-free diversity metrics, VENDI and RKE, for generative models. This approach significantly reduces computational complexity from super-quadratic to near-linear, facilitating scalable diversity evaluation and interpretability through identified modes across large datasets in image, text, and video modalities.

07 Oct 2024

GS-VTON presents an approach for image-prompted, controllable 3D virtual try-on using 3D Gaussian Splatting, enabling users to visualize garments from multiple angles with high fidelity. The method achieves realistic and multi-view consistent results, outperforming prior techniques in user preference, and introduces the first benchmark for 3D virtual try-on.

12 Sep 2019
 Nagoya University
Nagoya University University of CopenhagenUniversity of EdinburghKeele UniversityAarhus University
University of CopenhagenUniversity of EdinburghKeele UniversityAarhus University University of Warwick
University of Warwick University of St AndrewsSharif University of TechnologyIstituto Nazionale di Fisica NucleareUniversity of CaliforniaChungnam National UniversityUniversität HamburgIsfahan University of TechnologyThe Open UniversityMax Planck Institute for AstronomyUniversidad de AtacamaUniversity of CoimbraUniversity of AntofagastaUniversidad San Sebast ́ıanLas Cumbres Observatory Global TelescopePontificiaUniversidad Cat ́olica de ChileUniversit
di SalernoUniversit
de BordeauxUniversity of Rome
“Tor Vergata
”
University of St AndrewsSharif University of TechnologyIstituto Nazionale di Fisica NucleareUniversity of CaliforniaChungnam National UniversityUniversität HamburgIsfahan University of TechnologyThe Open UniversityMax Planck Institute for AstronomyUniversidad de AtacamaUniversity of CoimbraUniversity of AntofagastaUniversidad San Sebast ́ıanLas Cumbres Observatory Global TelescopePontificiaUniversidad Cat ́olica de ChileUniversit
di SalernoUniversit
de BordeauxUniversity of Rome
“Tor Vergata
”Transits in the planetary system WASP-4 were recently found to occur 80s
earlier than expected in observations from the TESS satellite. We present 22
new times of mid-transit that confirm the existence of transit timing
variations, and are well fitted by a quadratic ephemeris with period decay
dP/dt = -9.2 +/- 1.1 ms/yr. We rule out instrumental issues, stellar activity
and the Applegate mechanism as possible causes. The light-time effect is also
not favoured due to the non-detection of changes in the systemic velocity.
Orbital decay and apsidal precession are plausible but unproven. WASP-4b is
only the third hot Jupiter known to show transit timing variations to high
confidence. We discuss a variety of observations of this and other planetary
systems that would be useful in improving our understanding of WASP-4 in
particular and orbital decay in general.

04 Aug 2025
Efficient management of aircraft maintenance hangars is a critical operational challenge, involving complex, interdependent decisions regarding aircraft scheduling and spatial allocation. This paper introduces a novel continuous-time mixed-integer linear programming (MILP) model to solve this integrated spatio-temporal problem. By treating time as a continuous variable, our formulation overcomes the scalability limitations of traditional discrete-time approaches. The performance of the exact model is benchmarked against a constructive heuristic, and its practical applicability is demonstrated through a custom-built visualization dashboard. Computational results are compelling: the model solves instances with up to 25 aircraft to proven optimality, often in mere seconds, and for large-scale cases of up to 40 aircraft, delivers high-quality solutions within known optimality gaps. In all tested scenarios, the resulting solutions consistently and significantly outperform the heuristic, which highlights the framework's substantial economic benefits and provides valuable managerial insights into the trade-off between solution time and optimality.

08 Apr 2024
The proliferation of hate speech and offensive comments on social media has
become increasingly prevalent due to user activities. Such comments can have
detrimental effects on individuals' psychological well-being and social
behavior. While numerous datasets in the English language exist in this domain,
few equivalent resources are available for Persian language. To address this
gap, this paper introduces two offensive datasets. The first dataset comprises
annotations provided by domain experts, while the second consists of a large
collection of unlabeled data obtained through web crawling for unsupervised
learning purposes. To ensure the quality of the former dataset, a meticulous
three-stage labeling process was conducted, and kappa measures were computed to
assess inter-annotator agreement. Furthermore, experiments were performed on
the dataset using state-of-the-art language models, both with and without
employing masked language modeling techniques, as well as machine learning
algorithms, in order to establish the baselines for the dataset using
contemporary cutting-edge approaches. The obtained F1-scores for the
three-class and two-class versions of the dataset were 76.9% and 89.9% for
XLM-RoBERTa, respectively.

09 Feb 2021
This paper looks into the modeling of hallucination in the human's brain.
Hallucinations are known to be causally associated with some malfunctions
within the interaction of different areas of the brain involved in perception.
Focusing on visual hallucination and its underlying causes, we identify an
adversarial mechanism between different parts of the brain which are
responsible in the process of visual perception. We then show how the
characterized adversarial interactions in the brain can be modeled by a
generative adversarial network.

14 Sep 2025
Memory corruption is a serious class of software vulnerabilities, which requires careful attention to be detected and removed from applications before getting exploited and harming the system users. Symbolic execution is a well-known method for analyzing programs and detecting various vulnerabilities, e.g., memory corruption. Although this method is sound and complete in theory, it faces some challenges, such as path explosion, when applied to real-world complex programs. In this paper, we present a method for improving the efficiency of symbolic execution and detecting four classes of memory corruption vulnerabilities in executable codes, i.e., heap-based buffer overflow, stack-based buffer overflow, use-after-free, and double-free. We perform symbolic execution only on test units rather than the whole program to lower the chance of path explosion. In our method, test units are considered parts of the program's code, which might contain vulnerable statements and are statically identified based on the specifications of memory corruption vulnerabilities. Then, each test unit is symbolically executed to calculate path and vulnerability constraints of each statement of the unit, which determine the conditions on unit input data for executing that statement or activating vulnerabilities in it, respectively. Solving these constraints gives us input values for the test unit, which execute the desired statements and reveal vulnerabilities in them. Finally, we use machine learning to approximate the correlation between system and unit input data. Thereby, we generate system inputs that enter the program, reach vulnerable instructions in the desired test unit, and reveal vulnerabilities in them. This method is implemented as a plugin for angr framework and evaluated using a group of benchmark programs. The experiments show its superiority over similar tools in accuracy and performance.

02 Apr 2025

Researchers from HEC Montréal, MIT, and Isfahan University of Technology present a six-decision framework to guide financial institutions in the responsible integration of Large Language Models. This framework helps organizations assess LLM necessity, establish data governance, manage risks, ensure ethical oversight, quantify value, and select appropriate implementation paths.

22 Sep 2025
Predicting the Curie temperature () of magnetic materials is crucial for advancing applications in data storage, spintronics, and sensors. We present a machine learning (ML) framework to predict using a curated dataset of 2,500 ferromagnetic compounds, employing two types of elemental descriptor-based features: one based on stoichiometry-weighted descriptors, and the other leveraging Graph Neural Networks (GNNs). CatBoost trained on the stoichiometry-weighted descriptors achieved an score of 0.87, while the use of GNN-based representations led to a further improvement, with CatBoost reaching an of 0.91, highlighting the effectiveness of graph-based feature learning. We also demonstrated that using an uncurated dataset available online leads to poor predictions, resulting in a low score of 0.66 for the CatBoost model. We analyzed feature importance using tools such as Recursive Feature Elimination (RFE), which revealed that ionization energies are a key physicochemical factor influencing . Notably, the use of only the first 10 ionization energies as input features resulted in high predictive accuracy, with scores of up to 0.85 for statistical models and 0.89 for the GNN-based approach. These results highlight that combining robust ML models with thoughtful feature engineering and high-quality data, can accelerate the discovery of magnetic materials. Our curated dataset is publicly available on GitHub.
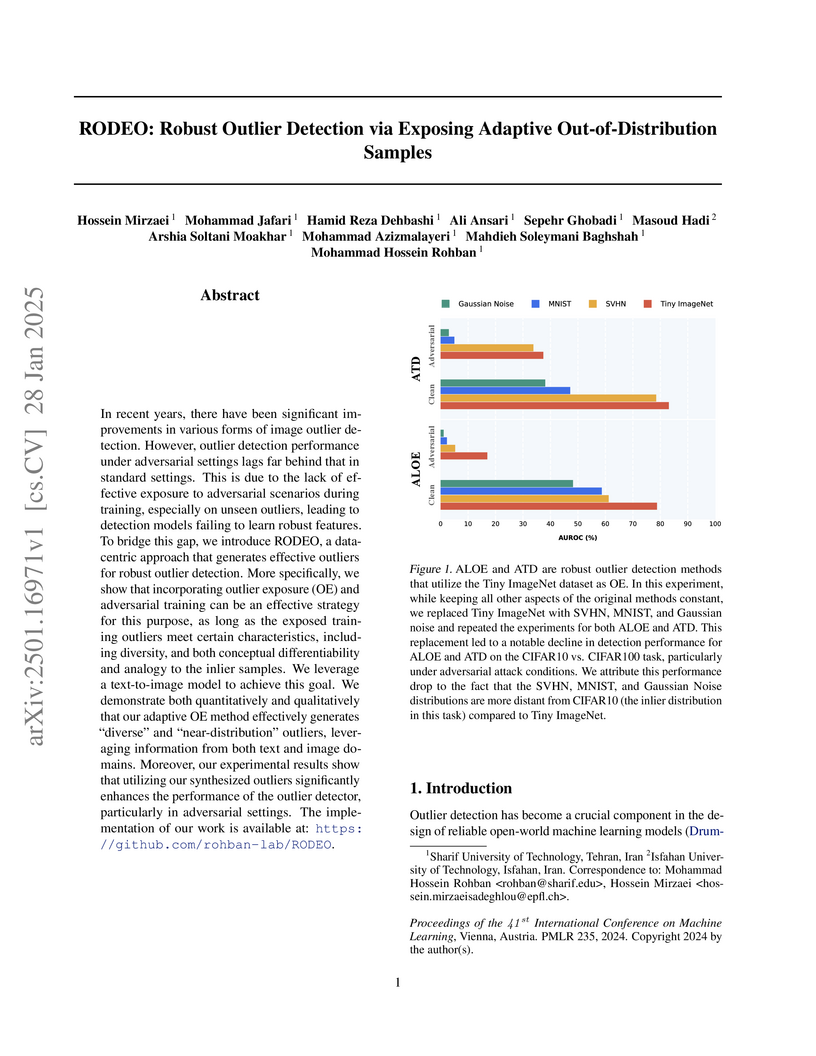
28 Jan 2025
In recent years, there have been significant improvements in various forms of image outlier detection. However, outlier detection performance under adversarial settings lags far behind that in standard settings. This is due to the lack of effective exposure to adversarial scenarios during training, especially on unseen outliers, leading to detection models failing to learn robust features. To bridge this gap, we introduce RODEO, a data-centric approach that generates effective outliers for robust outlier detection. More specifically, we show that incorporating outlier exposure (OE) and adversarial training can be an effective strategy for this purpose, as long as the exposed training outliers meet certain characteristics, including diversity, and both conceptual differentiability and analogy to the inlier samples. We leverage a text-to-image model to achieve this goal. We demonstrate both quantitatively and qualitatively that our adaptive OE method effectively generates ``diverse'' and ``near-distribution'' outliers, leveraging information from both text and image domains. Moreover, our experimental results show that utilizing our synthesized outliers significantly enhances the performance of the outlier detector, particularly in adversarial settings.

20 Aug 2025
Supervised fine-tuning (SFT) plays a critical role for pretrained large language models (LLMs), notably enhancing their capacity to acquire domain-specific knowledge while preserving or potentially augmenting their general-purpose capabilities. However, the efficacy of SFT hinges on data quality as well as data volume, otherwise it may result in limited performance gains or even degradation relative to the associated baselines. To mitigate such reliance, we suggest categorizing tokens within each corpus into two parts -- positive and negative tokens -- based on whether they are useful to improve model performance. Positive tokens can be trained in common ways, whereas negative tokens, which may lack essential semantics or be misleading, should be explicitly forgotten. Overall, the token categorization facilitate the model to learn less informative message, and the forgetting process shapes a knowledge boundary to guide the model on what information to learn more precisely. We conduct experiments on well-established benchmarks, finding that this forgetting mechanism not only improves overall model performance and also facilitate more diverse model responses.

22 Apr 2025
Inelastic neutron scattering data on magnetic crystals are highly valuable in
materials science, as they provide direct insight into microscopic magnetic
interactions. Using spin wave theory, these interactions can be extracted from
magnetic excitations observed in such experiments. However, these datasets are
often scattered across the literature and lack standardization, limiting their
accessibility and usability. In this paper, we compile and standardize
Heisenberg exchange interaction data for magnetic materials obtained from
inelastic neutron scattering experiments. Through an extensive literature
review, we identify experimental data for approximately 100 magnetic materials.
The standardized dataset includes mapping the results of various Heisenberg
Hamiltonians into a unified standard form, visualizations of crystal structures
with annotated exchange interactions, and input and output files from Monte
Carlo simulations performed for each compound using the ESpinS code. Using
experimentally determined exchange interactions, we calculate transition
temperatures via classical Monte Carlo simulations. Additionally, we
assess the effectiveness of the correction within classical Monte
Carlo simulations, finding that it produces transition temperatures in
excellent agreement with experimental values in most cases. The complete
dataset, along with supporting resources, is publicly available on GitHub.

07 Nov 2024
Deep learning methods have established a significant place in image classification. While prior research has focused on enhancing final outcomes, the opaque nature of the decision-making process in these models remains a concern for experts. Additionally, the deployment of these methods can be problematic in resource-limited environments. This paper tackles the inherent black-box nature of these models by providing real-time explanations during the training phase, compelling the model to concentrate on the most distinctive and crucial aspects of the input. Furthermore, we employ established quantization techniques to address resource constraints. To assess the effectiveness of our approach, we explore how quantization influences the interpretability and accuracy of Convolutional Neural Networks through a comparative analysis of saliency maps from standard and quantized models. Quantization is implemented during the training phase using the Parameterized Clipping Activation method, with a focus on the MNIST and FashionMNIST benchmark datasets. We evaluated three bit-width configurations (2-bit, 4-bit, and mixed 4/2-bit) to explore the trade-off between efficiency and interpretability, with each configuration designed to highlight varying impacts on saliency map clarity and model accuracy. The results indicate that while quantization is crucial for implementing models on resource-limited devices, it necessitates a trade-off between accuracy and interpretability. Lower bit-widths result in more pronounced reductions in both metrics, highlighting the necessity of meticulous quantization parameter selection in applications where model transparency is paramount. The study underscores the importance of achieving a balance between efficiency and interpretability in the deployment of neural networks.

01 Jul 2019
We investigate the holographic entanglement entropy in the Rindler-AdS space-time to obtain an exact solution for the corresponding minimal surface. Moreover, the holographic entanglement entropy of the charged single accelerated AdS Black holes in four dimensions is investigated. We obtain the volume of the codimension one-time slice in the bulk geometry enclosed by the minimal surface for both the RindlerAdS space-time and the charged accelerated AdS Black holes in the bulk. It is shown that the holographic entanglement entropy and the volume enclosed by the minimal hyper-surface in both the Rindler spacetime and the charged single accelerated AdS Black holes (C-metric) in the bulk decrease with increasing acceleration parameter. Behavior of the entanglement entropy, subregion size and value of the acceleration parameter are investigated. It is shown that for jAj < 0:2 a larger subregion on the boundary is equivalent to less information about the space-time.

14 Jun 2017
Massive MIMO systems promise high data rates by employing large number of
antennas, which also increases the power usage of the system as a consequence.
This creates an optimization problem which specifies how many antennas the
system should employ in order to operate with maximal energy efficiency. Our
main goal is to consider a base station with a fixed number of antennas, such
that the system can operate with a smaller subset of antennas according to the
number of active user terminals, which may vary over time. Thus, in this paper
we propose an antenna selection algorithm which selects the best antennas
according to the better channel conditions with respect to the users, aiming at
improving the overall energy efficiency. Then, due to the complexity of the
mathematical formulation, a tight approximation for the consumed power is
presented, using the Wishart theorem, and it is used to find a deterministic
formulation for the energy efficiency. Simulation results show that the
approximation is quite tight and that there is significant improvement in terms
of energy efficiency when antenna selection is employed.

09 Jan 2023
Image inpainting consists of filling holes or missing parts of an image. Inpainting face images with symmetric characteristics is more challenging than inpainting a natural scene. None of the powerful existing models can fill out the missing parts of an image while considering the symmetry and homogeneity of the picture. Moreover, the metrics that assess a repaired face image quality cannot measure the preservation of symmetry between the rebuilt and existing parts of a face. In this paper, we intend to solve the symmetry problem in the face inpainting task by using multiple discriminators that check each face organ's reality separately and a transformer-based network. We also propose "symmetry concentration score" as a new metric for measuring the symmetry of a repaired face image. The quantitative and qualitative results show the superiority of our proposed method compared to some of the recently proposed algorithms in terms of the reality, symmetry, and homogeneity of the inpainted parts.

21 Mar 2022
Alarm management systems have become indispensable in modern industry. Alarms inform the operator of abnormal situations, particularly in the case of equipment failures. Due to the interconnections between various parts of the system, each fault can affect other sections of the system operating normally. As a result, the fault propagates through faultless devices, increasing the number of alarms. Hence, the timely detection of the major fault that triggered the alarm by the operator can prevent the following consequences. However, due to the complexity of the system, it is often impossible to find precise relations between the underlying fault and the alarms. As a result, the operator needs support to make an appropriate decision immediately. Modeling alarms based on the historical alarm data can assist the operator in determining the root cause of the alarm. This research aims to model the relations between industrial alarms using historical alarm data in the database. Firstly, alarm data is collected, and alarm tags are sequenced. Then, these sequences are converted to numerical vectors using word embedding. Next, a self-attention-based BiLSTM-CNN classifier is used to learn the structure and relevance between historical alarm data. After training the model, this model is used for online fault detection. Finally, as a case study, the proposed model is implemented in the well-known Tennessee Eastman process, and the results are presented.
There are no more papers matching your filters at the moment.
