
01 Oct 2025

Photons are a ubiquitous carrier of quantum information: they are fast, suffer minimal decoherence, and do not require huge cryogenic facilities. Nevertheless, their intrinsically weak photon-photon interactions remain a key obstacle to scalable quantum computing. This review surveys hybrid photonic quantum computing, which exploits multiple photonic degrees of freedom to combine the complementary strengths of discrete and bosonic encodings, thereby significantly mitigating the challenge of weak photon-photon interactions. We first outline the basic principles of discrete-variable, native continuous-variable, and bosonic-encoding paradigms. We then summarise recent theoretical advances and state-of-the-art experimental demonstrations with particular emphasis on the hybrid approach. Its unique advantages, such as efficient generation of resource states and nearly ballistic (active-feedforward-free) operations, are highlighted alongside remaining technical challenges. To facilitate a clear comparison, we explicitly present the error thresholds and resource overheads required for fault-tolerant quantum computing. Our work offers a focused overview that clarifies how the hybrid approach enables scalable and compatible architectures for quantum computing.

23 May 2025
Flashback introduces a memory-driven retrieval paradigm for video anomaly detection, achieving zero-shot generalization, real-time processing, and explainable results by leveraging offline Large Language Model knowledge. It significantly improves anomaly detection performance on UCF-Crime by +7.0 pp AUC and XD-Violence by +13.1 pp AP, processing video segments in 0.713 seconds.

24 Aug 2023
We address the problem of network calibration adjusting miscalibrated confidences of deep neural networks. Many approaches to network calibration adopt a regularization-based method that exploits a regularization term to smooth the miscalibrated confidences. Although these approaches have shown the effectiveness on calibrating the networks, there is still a lack of understanding on the underlying principles of regularization in terms of network calibration. We present in this paper an in-depth analysis of existing regularization-based methods, providing a better understanding on how they affect to network calibration. Specifically, we have observed that 1) the regularization-based methods can be interpreted as variants of label smoothing, and 2) they do not always behave desirably. Based on the analysis, we introduce a novel loss function, dubbed ACLS, that unifies the merits of existing regularization methods, while avoiding the limitations. We show extensive experimental results for image classification and semantic segmentation on standard benchmarks, including CIFAR10, Tiny-ImageNet, ImageNet, and PASCAL VOC, demonstrating the effectiveness of our loss function.

30 Mar 2025
ESC-Net introduces a one-stage open-vocabulary semantic segmentation model that combines CLIP's vision-language understanding with pre-trained SAM decoder blocks guided by generated pseudo prompts. The model achieves state-of-the-art performance across multiple benchmarks while maintaining high computational efficiency.
14 Aug 2023
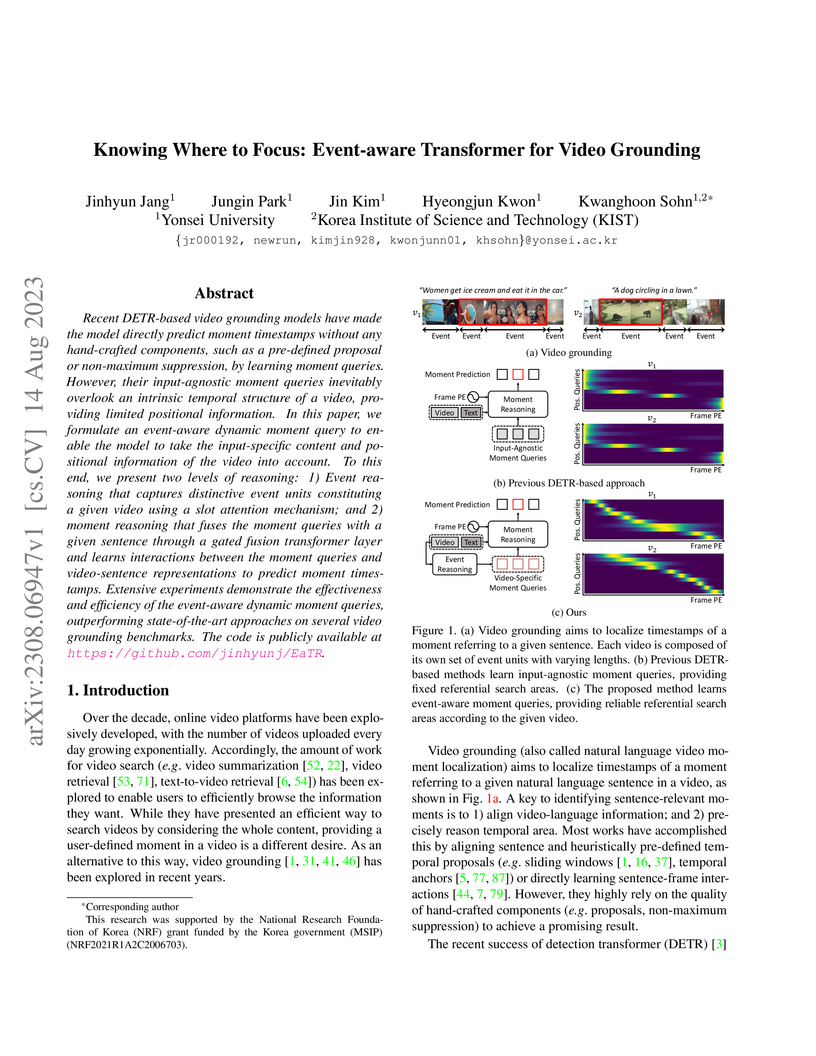
Recent DETR-based video grounding models have made the model directly predict
moment timestamps without any hand-crafted components, such as a pre-defined
proposal or non-maximum suppression, by learning moment queries. However, their
input-agnostic moment queries inevitably overlook an intrinsic temporal
structure of a video, providing limited positional information. In this paper,
we formulate an event-aware dynamic moment query to enable the model to take
the input-specific content and positional information of the video into
account. To this end, we present two levels of reasoning: 1) Event reasoning
that captures distinctive event units constituting a given video using a slot
attention mechanism; and 2) moment reasoning that fuses the moment queries with
a given sentence through a gated fusion transformer layer and learns
interactions between the moment queries and video-sentence representations to
predict moment timestamps. Extensive experiments demonstrate the effectiveness
and efficiency of the event-aware dynamic moment queries, outperforming
state-of-the-art approaches on several video grounding benchmarks.

10 Oct 2025
A systematic evaluation by researchers from KIST and Seoul National University reveals that while diffusion models efficiently discover thermodynamically stable materials in well-sampled chemical spaces, their performance degrades significantly in unexplored chemical territories and when extrapolating to larger crystal unit cell sizes.

22 Jun 2025
The growing demand for robots to operate effectively in diverse environments necessitates the need for robust real-time anomaly detection techniques during robotic operations. However, deep learning-based models in robotics face significant challenges due to limited training data and highly noisy signal features. In this paper, we present Sparse Masked Autoregressive Flow-based Adversarial AutoEncoder model to address these problems. This approach integrates Masked Autoregressive Flow model into Adversarial AutoEncoders to construct a flexible latent space and utilize Sparse autoencoder to efficiently focus on important features, even in scenarios with limited feature space. Our experiments demonstrate that the proposed model achieves a 4.96% to 9.75% higher area under the receiver operating characteristic curve for pick-and-place robotic operations with randomly placed cans, compared to existing state-of-the-art methods. Notably, it showed up to 19.67% better performance in scenarios involving collisions with lightweight objects. Additionally, unlike the existing state-of-the-art model, our model performs inferences within 1 millisecond, ensuring real-time anomaly detection. These capabilities make our model highly applicable to machine learning-based robotic safety systems in dynamic environments. The code is available at this https URL.

03 Jul 2025

Monocular 3D object detection (M3OD) has long faced challenges due to data scarcity caused by high annotation costs and inherent 2D-to-3D ambiguity. Although various weakly supervised methods and pseudo-labeling methods have been proposed to address these issues, they are mostly limited by domain-specific learning or rely solely on shape information from a single observation. In this paper, we propose a novel pseudo-labeling framework that uses only video data and is more robust to occlusion, without requiring a multi-view setup, additional sensors, camera poses, or domain-specific training. Specifically, we explore a technique for aggregating the pseudo-LiDARs of both static and dynamic objects across temporally adjacent frames using object point tracking, enabling 3D attribute extraction in scenarios where 3D data acquisition is infeasible. Extensive experiments demonstrate that our method ensures reliable accuracy and strong scalability, making it a practical and effective solution for M3OD.

22 Jul 2025
 Imperial College London
Imperial College London University College London
University College London The Chinese University of Hong KongTechnical University of Munich (TUM)TU Dresden
The Chinese University of Hong KongTechnical University of Munich (TUM)TU Dresden King’s College LondonKyung Hee University
King’s College LondonKyung Hee University HKUSTEindhoven University of TechnologyGerman Cancer Research Center (DKFZ)University of MinhoKorea Institute of Science and Technology (KIST)Muroran Institute of TechnologyTUM University HospitalHKUST Shenzhen-Hong Kong Collaborative Innovation Research InstituteSao Paulo State University (UNESP)Klagenfurt UniversityOTH RegensburgNational Center for Tumor Diseases (NCT/UCC)Konica Minolta Inc.Niigata University of Health and WelfareLos Andes UniversityRegensburg UniversityJmees IncHanglok TechMedtronic Ltd.AKTORmed Robotic Surgery
HKUSTEindhoven University of TechnologyGerman Cancer Research Center (DKFZ)University of MinhoKorea Institute of Science and Technology (KIST)Muroran Institute of TechnologyTUM University HospitalHKUST Shenzhen-Hong Kong Collaborative Innovation Research InstituteSao Paulo State University (UNESP)Klagenfurt UniversityOTH RegensburgNational Center for Tumor Diseases (NCT/UCC)Konica Minolta Inc.Niigata University of Health and WelfareLos Andes UniversityRegensburg UniversityJmees IncHanglok TechMedtronic Ltd.AKTORmed Robotic SurgeryReliable recognition and localization of surgical instruments in endoscopic video recordings are foundational for a wide range of applications in computer- and robot-assisted minimally invasive surgery (RAMIS), including surgical training, skill assessment, and autonomous assistance. However, robust performance under real-world conditions remains a significant challenge. Incorporating surgical context - such as the current procedural phase - has emerged as a promising strategy to improve robustness and interpretability.
To address these challenges, we organized the Surgical Procedure Phase, Keypoint, and Instrument Recognition (PhaKIR) sub-challenge as part of the Endoscopic Vision (EndoVis) challenge at MICCAI 2024. We introduced a novel, multi-center dataset comprising thirteen full-length laparoscopic cholecystectomy videos collected from three distinct medical institutions, with unified annotations for three interrelated tasks: surgical phase recognition, instrument keypoint estimation, and instrument instance segmentation. Unlike existing datasets, ours enables joint investigation of instrument localization and procedural context within the same data while supporting the integration of temporal information across entire procedures.
We report results and findings in accordance with the BIAS guidelines for biomedical image analysis challenges. The PhaKIR sub-challenge advances the field by providing a unique benchmark for developing temporally aware, context-driven methods in RAMIS and offers a high-quality resource to support future research in surgical scene understanding.

31 Mar 2024
Unsupervised video object segmentation aims to segment the most prominent
object in a video sequence. However, the existence of complex backgrounds and
multiple foreground objects make this task challenging. To address this issue,
we propose a guided slot attention network to reinforce spatial structural
information and obtain better foreground--background separation. The foreground
and background slots, which are initialized with query guidance, are
iteratively refined based on interactions with template information.
Furthermore, to improve slot--template interaction and effectively fuse global
and local features in the target and reference frames, K-nearest neighbors
filtering and a feature aggregation transformer are introduced. The proposed
model achieves state-of-the-art performance on two popular datasets.
Additionally, we demonstrate the robustness of the proposed model in
challenging scenes through various comparative experiments.

13 Oct 2024
EBDM introduces an exemplar-guided image translation framework using Brownian-bridge diffusion models, which generates photo-realistic images by efficiently transferring both global and fine-grained style from an exemplar while preserving structural control inputs. The framework demonstrates superior detail transfer and improved computational efficiency over prior methods and other diffusion-based approaches.

31 Mar 2025
Bootstrap Your Own Views (BYOV) introduces a masked ego-exo modeling framework to learn fine-grained, view-invariant video representations from unpaired and asynchronous egocentric and exocentric videos. The method outperforms prior state-of-the-art on various tasks, including action phase classification (e.g., over 10% F1 gain on Break Eggs) and temporal alignment, demonstrating robust cross-view understanding without requiring synchronized data.

24 Oct 2022
Given an untrimmed video and a language query depicting a specific temporal
moment in the video, video grounding aims to localize the time interval by
understanding the text and video simultaneously. One of the most challenging
issues is an extremely time- and cost-consuming annotation collection,
including video captions in a natural language form and their corresponding
temporal regions. In this paper, we present a simple yet novel training
framework for video grounding in the zero-shot setting, which learns a network
with only video data without any annotation. Inspired by the recent
language-free paradigm, i.e. training without language data, we train the
network without compelling the generation of fake (pseudo) text queries into a
natural language form. Specifically, we propose a method for learning a video
grounding model by selecting a temporal interval as a hypothetical correct
answer and considering the visual feature selected by our method in the
interval as a language feature, with the help of the well-aligned
visual-language space of CLIP. Extensive experiments demonstrate the prominence
of our language-free training framework, outperforming the existing zero-shot
video grounding method and even several weakly-supervised approaches with large
margins on two standard datasets.

28 Mar 2024
Training-free network architecture search (NAS) aims to discover high-performing networks with zero-cost proxies, capturing network characteristics related to the final performance. However, network rankings estimated by previous training-free NAS methods have shown weak correlations with the performance. To address this issue, we propose AZ-NAS, a novel approach that leverages the ensemble of various zero-cost proxies to enhance the correlation between a predicted ranking of networks and the ground truth substantially in terms of the performance. To achieve this, we introduce four novel zero-cost proxies that are complementary to each other, analyzing distinct traits of architectures in the views of expressivity, progressivity, trainability, and complexity. The proxy scores can be obtained simultaneously within a single forward and backward pass, making an overall NAS process highly efficient. In order to integrate the rankings predicted by our proxies effectively, we introduce a non-linear ranking aggregation method that highlights the networks highly-ranked consistently across all the proxies. Experimental results conclusively demonstrate the efficacy and efficiency of AZ-NAS, outperforming state-of-the-art methods on standard benchmarks, all while maintaining a reasonable runtime cost.

01 Apr 2024
Visual scenes are naturally organized in a hierarchy, where a coarse semantic is recursively comprised of several fine details. Exploring such a visual hierarchy is crucial to recognize the complex relations of visual elements, leading to a comprehensive scene understanding. In this paper, we propose a Visual Hierarchy Mapper (Hi-Mapper), a novel approach for enhancing the structured understanding of the pre-trained Deep Neural Networks (DNNs). Hi-Mapper investigates the hierarchical organization of the visual scene by 1) pre-defining a hierarchy tree through the encapsulation of probability densities; and 2) learning the hierarchical relations in hyperbolic space with a novel hierarchical contrastive loss. The pre-defined hierarchy tree recursively interacts with the visual features of the pre-trained DNNs through hierarchy decomposition and encoding procedures, thereby effectively identifying the visual hierarchy and enhancing the recognition of an entire scene. Extensive experiments demonstrate that Hi-Mapper significantly enhances the representation capability of DNNs, leading to an improved performance on various tasks, including image classification and dense prediction tasks.

12 Oct 2022
Class-incremental semantic segmentation (CISS) labels each pixel of an image
with a corresponding object/stuff class continually. To this end, it is crucial
to learn novel classes incrementally without forgetting previously learned
knowledge. Current CISS methods typically use a knowledge distillation (KD)
technique for preserving classifier logits, or freeze a feature extractor, to
avoid the forgetting problem. The strong constraints, however, prevent learning
discriminative features for novel classes. We introduce a CISS framework that
alleviates the forgetting problem and facilitates learning novel classes
effectively. We have found that a logit can be decomposed into two terms. They
quantify how likely an input belongs to a particular class or not, providing a
clue for a reasoning process of a model. The KD technique, in this context,
preserves the sum of two terms (i.e., a class logit), suggesting that each
could be changed and thus the KD does not imitate the reasoning process. To
impose constraints on each term explicitly, we propose a new decomposed
knowledge distillation (DKD) technique, improving the rigidity of a model and
addressing the forgetting problem more effectively. We also introduce a novel
initialization method to train new classifiers for novel classes. In CISS, the
number of negative training samples for novel classes is not sufficient to
discriminate old classes. To mitigate this, we propose to transfer knowledge of
negatives to the classifiers successively using an auxiliary classifier,
boosting the performance significantly. Experimental results on standard CISS
benchmarks demonstrate the effectiveness of our framework.

05 Sep 2025

Analysis of public opinions collected from digital media helps organizations maintain positive relationships with the public. Such public relations (PR) analysis often involves assessing opinions, for example, measuring how strongly people trust an organization. Pre-trained Large Language Models (LLMs) hold great promise for supporting Organization-Public Relationship Assessment (OPRA) because they can map unstructured public text to OPRA dimensions and articulate rationales through prompting. However, adapting LLMs for PR analysis typically requires fine-tuning on large labeled datasets, which is both labor-intensive and knowledge-intensive, making it difficult for PR researchers to apply these models. In this paper, we present OPRA-Vis, a visual analytics system that leverages LLMs for OPRA without requiring extensive labeled data. Our framework employs Chain-of-Thought prompting to guide LLMs in analyzing public opinion data by incorporating PR expertise directly into the reasoning process. Furthermore, OPRA-Vis provides visualizations that reveal the clues and reasoning paths used by LLMs, enabling users to explore, critique, and refine model decisions. We demonstrate the effectiveness of OPRA-Vis through two real-world use cases and evaluate it quantitatively, through comparisons with alternative LLMs and prompting strategies, and qualitatively, through assessments of usability, effectiveness, and expert feedback.

17 Mar 2023
In this paper, we efficiently transfer the surpassing representation power of the vision foundation models, such as ViT and Swin, for video understanding with only a few trainable parameters. Previous adaptation methods have simultaneously considered spatial and temporal modeling with a unified learnable module but still suffered from fully leveraging the representative capabilities of image transformers. We argue that the popular dual-path (two-stream) architecture in video models can mitigate this problem. We propose a novel DualPath adaptation separated into spatial and temporal adaptation paths, where a lightweight bottleneck adapter is employed in each transformer block. Especially for temporal dynamic modeling, we incorporate consecutive frames into a grid-like frameset to precisely imitate vision transformers' capability that extrapolates relationships between tokens. In addition, we extensively investigate the multiple baselines from a unified perspective in video understanding and compare them with DualPath. Experimental results on four action recognition benchmarks prove that pretrained image transformers with DualPath can be effectively generalized beyond the data domain.

01 Aug 2025
Designing residential interiors strongly impacts occupant satisfaction but remains challenging due to unstructured spatial layouts, high computational demands, and reliance on expert knowledge. Existing methods based on optimization or deep learning are either computationally expensive or constrained by data scarcity. Reinforcement learning (RL) approaches often limit furniture placement to discrete positions and fail to incorporate design principles adequately. We propose OID-PPO, a novel RL framework for Optimal Interior Design using Proximal Policy Optimization, which integrates expert-defined functional and visual guidelines into a structured reward function. OID-PPO utilizes a diagonal Gaussian policy for continuous and flexible furniture placement, effectively exploring latent environmental dynamics under partial observability. Experiments conducted across diverse room shapes and furniture configurations demonstrate that OID-PPO significantly outperforms state-of-the-art methods in terms of layout quality and computational efficiency. Ablation studies further demonstrate the impact of structured guideline integration and reveal the distinct contributions of individual design constraints.

12 Jul 2025
Accurate assessment of mental workload (MW) is crucial for understanding cognitive processes during visualization tasks. While EEG-based measures are emerging as promising alternatives to conventional assessment techniques, such as selfreport measures, studies examining consistency across these different methodologies are limited. In a preliminary study, we observed indications of potential discrepancies between EEGbased and self-reported MW measures. Motivated by these preliminary observations, our study further explores the discrepancies between EEG-based and self-reported MW assessment methods through an experiment involving visualization tasks. In the experiment, we employ two benchmark tasks: the Visualization Literacy Assessment Test (VLAT) and a Spatial Visualization (SV) task. EEG signals are recorded from participants using a 32-channel system at a sampling rate of 128 Hz during the visualization tasks. For each participant, MW is estimated using an EEG-based model built on a Graph Attention Network (GAT) architecture, and these estimates are compared with conventional MW measures to examine potential discrepancies. Our findings reveal notable discrepancies between task difficulty and EEG-based MW estimates, as well as between EEG-based and self-reported MW measures across varying task difficulty levels. Additionally, the observed patterns suggest the presence of unconscious cognitive effort that may not be captured by selfreport alone.
There are no more papers matching your filters at the moment.
