
13 Aug 2025



Charts are essential to data analysis, transforming raw data into clear visual representations that support human decision-making. Although current vision-language models (VLMs) have made significant progress, they continue to struggle with chart comprehension due to training on datasets that lack diversity and real-world authenticity, or on automatically extracted underlying data tables of charts, which can contain numerous estimation errors. Furthermore, existing models only rely on supervised fine-tuning using these low-quality datasets, severely limiting their effectiveness. To address these issues, we first propose BigCharts, a dataset creation pipeline that generates visually diverse chart images by conditioning the rendering process on real-world charts sourced from multiple online platforms. Unlike purely synthetic datasets, BigCharts incorporates real-world data, ensuring authenticity and visual diversity, while still retaining accurate underlying data due to our proposed replotting process. Additionally, we introduce a comprehensive training framework that integrates supervised fine-tuning with Group Relative Policy Optimization (GRPO)-based reinforcement learning. By introducing novel reward signals specifically designed for chart reasoning, our approach enhances model robustness and generalization across diverse chart styles and domains, resulting in a state-of-the-art chart reasoning model, BigCharts-R1. Extensive experiments demonstrate that our models surpass existing methods on multiple chart question-answering benchmarks compared to even larger open-source and closed-source models.

07 Feb 2025

Modern medical image registration approaches predict deformations using deep
networks. These approaches achieve state-of-the-art (SOTA) registration
accuracy and are generally fast. However, deep learning (DL) approaches are, in
contrast to conventional non-deep-learning-based approaches, anatomy-specific.
Recently, a universal deep registration approach, uniGradICON, has been
proposed. However, uniGradICON focuses on monomodal image registration. In this
work, we therefore develop multiGradICON as a first step towards universal
*multimodal* medical image registration. Specifically, we show that 1) we can
train a DL registration model that is suitable for monomodal *and* multimodal
registration; 2) loss function randomization can increase multimodal
registration accuracy; and 3) training a model with multimodal data helps
multimodal generalization. Our code and the multiGradICON model are available
at this https URL

01 Oct 2025
Vision-language object detectors (VLODs) such as YOLO-World and Grounding DINO achieve impressive zero-shot recognition by aligning region proposals with text representations. However, their performance often degrades under domain shift. We introduce VLOD-TTA, a test-time adaptation (TTA) framework for VLODs that leverages dense proposal overlap and image-conditioned prompt scores. First, an IoU-weighted entropy objective is proposed that concentrates adaptation on spatially coherent proposal clusters and reduces confirmation bias from isolated boxes. Second, image-conditioned prompt selection is introduced, which ranks prompts by image-level compatibility and fuses the most informative prompts with the detector logits. Our benchmarking across diverse distribution shifts -- including stylized domains, driving scenes, low-light conditions, and common corruptions -- shows the effectiveness of our method on two state-of-the-art VLODs, YOLO-World and Grounding DINO, with consistent improvements over the zero-shot and TTA baselines. Code : this https URL

11 Sep 2025
Test-time adaptation (TTA) is crucial for mitigating performance degradation caused by distribution shifts in 3D point cloud classification. In this work, we introduce Token Purging (PG), a novel backpropagation-free approach that removes tokens highly affected by domain shifts before they reach attention layers. Unlike existing TTA methods, PG operates at the token level, ensuring robust adaptation without iterative updates. We propose two variants: PG-SP, which leverages source statistics, and PG-SF, a fully source-free version relying on CLS-token-driven adaptation. Extensive evaluations on ModelNet40-C, ShapeNet-C, and ScanObjectNN-C demonstrate that PG-SP achieves an average of +10.3\% higher accuracy than state-of-the-art backpropagation-free methods, while PG-SF sets new benchmarks for source-free adaptation. Moreover, PG is 12.4 times faster and 5.5 times more memory efficient than our baseline, making it suitable for real-world deployment. Code is available at \hyperlink{this https URL}{this https URL}

16 Nov 2024


Protein sequence design, determined by amino acid sequences, are essential to
protein engineering problems in drug discovery. Prior approaches have resorted
to evolutionary strategies or Monte-Carlo methods for protein design, but often
fail to exploit the structure of the combinatorial search space, to generalize
to unseen sequences. In the context of discrete black box optimization over
large search spaces, learning a mutation policy to generate novel sequences
with reinforcement learning is appealing. Recent advances in protein language
models (PLMs) trained on large corpora of protein sequences offer a potential
solution to this problem by scoring proteins according to their biological
plausibility (such as the TM-score). In this work, we propose to use PLMs as a
reward function to generate new sequences. Yet the PLM can be computationally
expensive to query due to its large size. To this end, we propose an
alternative paradigm where optimization can be performed on scores from a
smaller proxy model that is periodically finetuned, jointly while learning the
mutation policy. We perform extensive experiments on various sequence lengths
to benchmark RL-based approaches, and provide comprehensive evaluations along
biological plausibility and diversity of the protein. Our experimental results
include favorable evaluations of the proposed sequences, along with high
diversity scores, demonstrating that RL is a strong candidate for biological
sequence design. Finally, we provide a modular open source implementation can
be easily integrated in most RL training loops, with support for replacing the
reward model with other PLMs, to spur further research in this domain. The code
for all experiments is provided in the supplementary material.

26 Sep 2025
State Space Models (SSMs) have emerged as efficient alternatives to Vision Transformers (ViTs), with VMamba standing out as a pioneering architecture designed for vision tasks. However, their generalization performance degrades significantly under distribution shifts. To address this limitation, we propose TRUST (Test-Time Refinement using Uncertainty-Guided SSM Traverses), a novel test-time adaptation (TTA) method that leverages diverse traversal permutations to generate multiple causal perspectives of the input image. Model predictions serve as pseudo-labels to guide updates of the Mamba-specific parameters, and the adapted weights are averaged to integrate the learned information across traversal scans. Altogether, TRUST is the first approach that explicitly leverages the unique architectural properties of SSMs for adaptation. Experiments on seven benchmarks show that TRUST consistently improves robustness and outperforms existing TTA methods.

01 Nov 2023
Most reinforcement learning algorithms take advantage of an experience replay buffer to repeatedly train on samples the agent has observed in the past. Not all samples carry the same amount of significance and simply assigning equal importance to each of the samples is a naïve strategy. In this paper, we propose a method to prioritize samples based on how much we can learn from a sample. We define the learn-ability of a sample as the steady decrease of the training loss associated with this sample over time. We develop an algorithm to prioritize samples with high learn-ability, while assigning lower priority to those that are hard-to-learn, typically caused by noise or stochasticity. We empirically show that our method is more robust than random sampling and also better than just prioritizing with respect to the training loss, i.e. the temporal difference loss, which is used in prioritized experience replay.

11 Aug 2025
Researchers at LIVIA, ´ETS Montreal, developed Sparse Optimization (SO), a framework that leverages dynamic and intelligent sparsity to adapt large Vision-Language Models (VLMs) in few-shot settings. This approach consistently outperforms state-of-the-art low-rank adaptation methods across 11 diverse datasets, achieving superior generalization and robustness while offering memory efficiency.

21 Oct 2025

A framework for multi-teacher knowledge distillation, utilizing Gaussian kernels for robust knowledge transfer, produces task-agnostic representations that achieve superior efficiency and competitive performance across various NLP, molecular, and vision benchmarks.

21 Oct 2022
Synthetic image generation has recently experienced significant improvements in domains such as natural image or art generation. However, the problem of figure and diagram generation remains unexplored. A challenging aspect of generating figures and diagrams is effectively rendering readable texts within the images. To alleviate this problem, we present OCR-VQGAN, an image encoder, and decoder that leverages OCR pre-trained features to optimize a text perceptual loss, encouraging the architecture to preserve high-fidelity text and diagram structure. To explore our approach, we introduce the Paper2Fig100k dataset, with over 100k images of figures and texts from research papers. The figures show architecture diagrams and methodologies of articles available at arXiv.org from fields like artificial intelligence and computer vision. Figures usually include text and discrete objects, e.g., boxes in a diagram, with lines and arrows that connect them. We demonstrate the effectiveness of OCR-VQGAN by conducting several experiments on the task of figure reconstruction. Additionally, we explore the qualitative and quantitative impact of weighting different perceptual metrics in the overall loss function. We release code, models, and dataset at this https URL.

23 Nov 2025
Diffusion models (DMs) produce high-quality images, yet their sampling remains costly when adapted to new domains. Distilled DMs are faster but typically remain confined within their teacher's domain. Thus, fast and high-quality generation for novel domains relies on two-stage training pipelines: Adapt-then-Distill or Distill-then-Adapt. However, both add design complexity and suffer from degraded quality or diversity. We introduce Uni-DAD, a single-stage pipeline that unifies distillation and adaptation of DMs. It couples two signals during training: (i) a dual-domain distribution-matching distillation objective that guides the student toward the distributions of the source teacher and a target teacher, and (ii) a multi-head generative adversarial network (GAN) loss that encourages target realism across multiple feature scales. The source domain distillation preserves diverse source knowledge, while the multi-head GAN stabilizes training and reduces overfitting, especially in few-shot regimes. The inclusion of a target teacher facilitates adaptation to more structurally distant domains. We perform evaluations on a variety of datasets for few-shot image generation (FSIG) and subject-driven personalization (SDP). Uni-DAD delivers higher quality than state-of-the-art (SoTA) adaptation methods even with less than 4 sampling steps, and outperforms two-stage training pipelines in both quality and diversity.

29 Nov 2024
Pre-trained vision-language models (VLMs), exemplified by CLIP, demonstrate remarkable adaptability across zero-shot classification tasks without additional training. However, their performance diminishes in the presence of domain shifts. In this study, we introduce CLIP Adaptation duRing Test-Time (CLIPArTT), a fully test-time adaptation (TTA) approach for CLIP, which involves automatic text prompts construction during inference for their use as text supervision. Our method employs a unique, minimally invasive text prompt tuning process, wherein multiple predicted classes are aggregated into a single new text prompt, used as \emph{pseudo label} to re-classify inputs in a transductive manner. Additionally, we pioneer the standardization of TTA benchmarks (e.g., TENT) in the realm of VLMs. Our findings demonstrate that, without requiring additional transformations nor new trainable modules, CLIPArTT enhances performance dynamically across non-corrupted datasets such as CIFAR-100, corrupted datasets like CIFAR-100-C and ImageNet-C, alongside synthetic datasets such as VisDA-C. This research underscores the potential for improving VLMs' adaptability through novel test-time strategies, offering insights for robust performance across varied datasets and environments. The code can be found at: this https URL

30 Sep 2024
Foundation models such as the recently introduced Segment Anything Model (SAM) have achieved remarkable results in image segmentation tasks. However, these models typically require user interaction through handcrafted prompts such as bounding boxes, which limits their deployment to downstream tasks. Adapting these models to a specific task with fully labeled data also demands expensive prior user interaction to obtain ground-truth annotations. This work proposes to replace conditioning on input prompts with a lightweight module that directly learns a prompt embedding from the image embedding, both of which are subsequently used by the foundation model to output a segmentation mask. Our foundation models with learnable prompts can automatically segment any specific region by 1) modifying the input through a prompt embedding predicted by a simple module, and 2) using weak labels (tight bounding boxes) and few-shot supervision (10 samples). Our approach is validated on MedSAM, a version of SAM fine-tuned for medical images, with results on three medical datasets in MR and ultrasound imaging. Our code is available on this https URL.

31 Mar 2023


Classification has been the focal point of research on adversarial attacks,
but only a few works investigate methods suited to denser prediction tasks,
such as semantic segmentation. The methods proposed in these works do not
accurately solve the adversarial segmentation problem and, therefore,
overestimate the size of the perturbations required to fool models. Here, we
propose a white-box attack for these models based on a proximal splitting to
produce adversarial perturbations with much smaller norms. Our
attack can handle large numbers of constraints within a nonconvex minimization
framework via an Augmented Lagrangian approach, coupled with adaptive
constraint scaling and masking strategies. We demonstrate that our attack
significantly outperforms previously proposed ones, as well as classification
attacks that we adapted for segmentation, providing a first comprehensive
benchmark for this dense task.

20 Jun 2025
Medical vision-language models (VLMs) have demonstrated unprecedented transfer capabilities and are being increasingly adopted for data-efficient image classification. Despite its growing popularity, its reliability aspect remains largely unexplored. This work explores the split conformal prediction (SCP) framework to provide trustworthiness guarantees when transferring such models based on a small labeled calibration set. Despite its potential, the generalist nature of the VLMs' pre-training could negatively affect the properties of the predicted conformal sets for specific tasks. While common practice in transfer learning for discriminative purposes involves an adaptation stage, we observe that deploying such a solution for conformal purposes is suboptimal since adapting the model using the available calibration data breaks the rigid exchangeability assumptions for test data in SCP. To address this issue, we propose transductive split conformal adaptation (SCA-T), a novel pipeline for transfer learning on conformal scenarios, which performs an unsupervised transductive adaptation jointly on calibration and test data. We present comprehensive experiments utilizing medical VLMs across various image modalities, transfer tasks, and non-conformity scores. Our framework offers consistent gains in efficiency and conditional coverage compared to SCP, maintaining the same empirical guarantees.

18 Dec 2024
Domain Generalization techniques aim to enhance model robustness by
simulating novel data distributions during training, typically through various
augmentation or stylization strategies. However, these methods frequently
suffer from limited control over the diversity of generated images and lack
assurance that these images span distinct distributions. To address these
challenges, we propose FDS, Feedback-guided Domain Synthesis, a novel strategy
that employs diffusion models to synthesize novel, pseudo-domains by training a
single model on all source domains and performing domain mixing based on
learned features. By incorporating images that pose classification challenges
to models trained on original samples, alongside the original dataset, we
ensure the generation of a training set that spans a broad distribution
spectrum. Our comprehensive evaluations demonstrate that this methodology sets
new benchmarks in domain generalization performance across a range of
challenging datasets, effectively managing diverse types of domain shifts. The
code can be found at: \url{this https URL}.

30 Oct 2024
Unsupervised object discovery is commonly interpreted as the task of localizing and/or categorizing objects in visual data without the need for labeled examples. While current object recognition methods have proven highly effective for practical applications, the ongoing demand for annotated data in real-world scenarios drives research into unsupervised approaches. Furthermore, existing literature in object discovery is both extensive and diverse, posing a significant challenge for researchers that aim to navigate and synthesize this knowledge. Motivated by the evidenced interest in this avenue of research, and the lack of comprehensive studies that could facilitate a holistic understanding of unsupervised object discovery, this survey conducts an in-depth exploration of the existing approaches and systematically categorizes this compendium based on the tasks addressed and the families of techniques employed. Additionally, we present an overview of common datasets and metrics, highlighting the challenges of comparing methods due to varying evaluation protocols. This work intends to provide practitioners with an insightful perspective on the domain, with the hope of inspiring new ideas and fostering a deeper understanding of object discovery approaches.
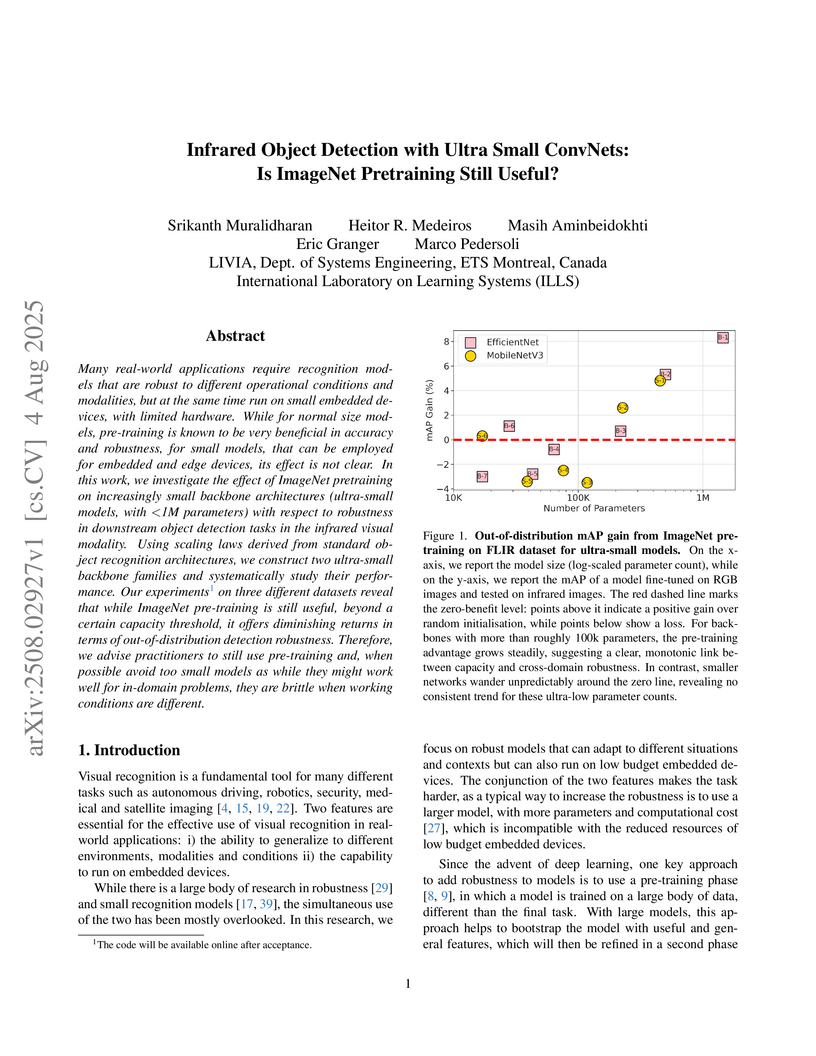
04 Aug 2025
Many real-world applications require recognition models that are robust to different operational conditions and modalities, but at the same time run on small embedded devices, with limited hardware. While for normal size models, pre-training is known to be very beneficial in accuracy and robustness, for small models, that can be employed for embedded and edge devices, its effect is not clear. In this work, we investigate the effect of ImageNet pretraining on increasingly small backbone architectures (ultra-small models, with <1M parameters) with respect to robustness in downstream object detection tasks in the infrared visual modality. Using scaling laws derived from standard object recognition architectures, we construct two ultra-small backbone families and systematically study their performance. Our experiments on three different datasets reveal that while ImageNet pre-training is still useful, beyond a certain capacity threshold, it offers diminishing returns in terms of out-of-distribution detection robustness. Therefore, we advise practitioners to still use pre-training and, when possible avoid too small models as while they might work well for in-domain problems, they are brittle when working conditions are different.

09 May 2025

The integration of AI into daily life has generated considerable attention
and excitement, while also raising concerns about automating algorithmic harms
and re-entrenching existing social inequities. While the responsible deployment
of trustworthy AI systems is a worthy goal, there are many possible ways to
realize it, from policy and regulation to improved algorithm design and
evaluation. In fact, since AI trains on social data, there is even a
possibility for everyday users, citizens, or workers to directly steer its
behavior through Algorithmic Collective Action, by deliberately modifying the
data they share with a platform to drive its learning process in their favor.
This paper considers how these grassroots efforts to influence AI interact with
methods already used by AI firms and governments to improve model
trustworthiness. In particular, we focus on the setting where the AI firm
deploys a differentially private model, motivated by the growing regulatory
focus on privacy and data protection. We investigate how the use of
Differentially Private Stochastic Gradient Descent (DPSGD) affects the
collective's ability to influence the learning process. Our findings show that
while differential privacy contributes to the protection of individual data, it
introduces challenges for effective algorithmic collective action. We
characterize lower bounds on the success of algorithmic collective action under
differential privacy as a function of the collective's size and the firm's
privacy parameters, and verify these trends experimentally by simulating
collective action during the training of deep neural network classifiers across
several datasets.

06 Jun 2025
Full Conformal Adaptation (FCA), developed by researchers at ÉTS Montréal and CentraleSupélec, provides statistically valid uncertainty estimates for Vision-Language Models (VLMs) adapted to medical image analysis, a crucial capability for safety-critical applications. This framework consistently maintains desired coverage levels and reduces prediction set sizes by up to 27% compared to standard approaches, addressing the challenge of unreliable uncertainty in adapted medical AI systems.
There are no more papers matching your filters at the moment.
