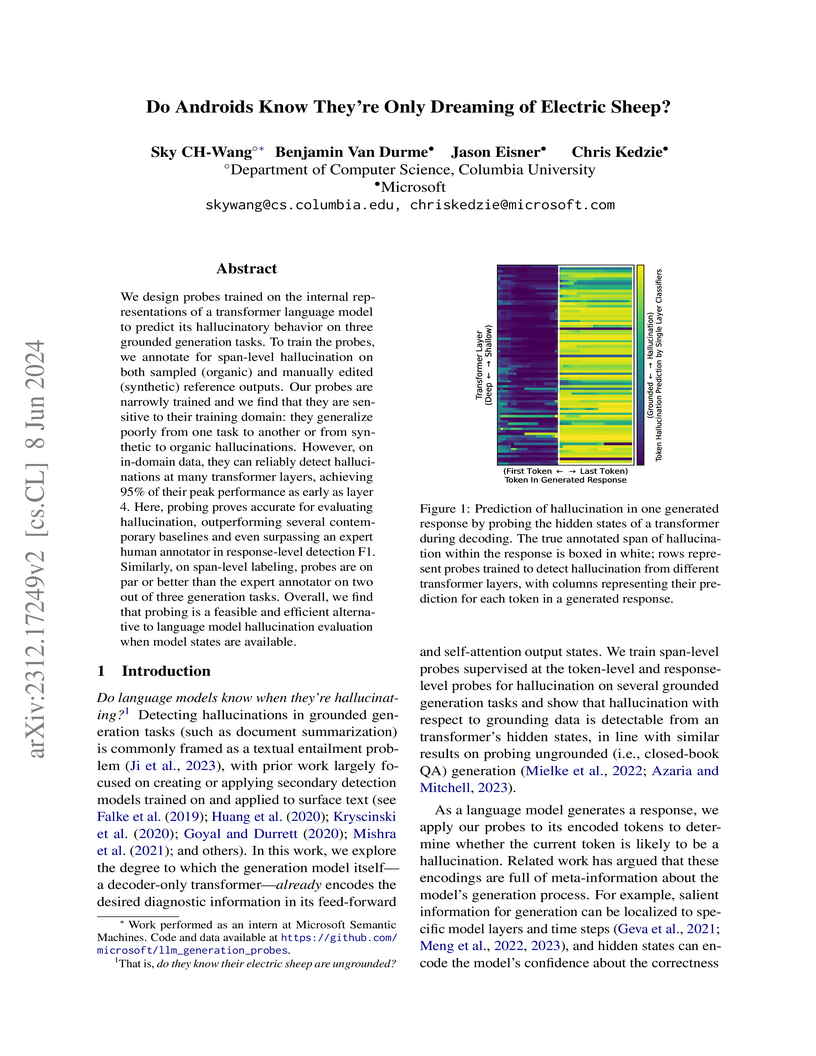
08 Jun 2024

We design probes trained on the internal representations of a transformer
language model to predict its hallucinatory behavior on three grounded
generation tasks. To train the probes, we annotate for span-level hallucination
on both sampled (organic) and manually edited (synthetic) reference outputs.
Our probes are narrowly trained and we find that they are sensitive to their
training domain: they generalize poorly from one task to another or from
synthetic to organic hallucinations. However, on in-domain data, they can
reliably detect hallucinations at many transformer layers, achieving 95% of
their peak performance as early as layer 4. Here, probing proves accurate for
evaluating hallucination, outperforming several contemporary baselines and even
surpassing an expert human annotator in response-level detection F1. Similarly,
on span-level labeling, probes are on par or better than the expert annotator
on two out of three generation tasks. Overall, we find that probing is a
feasible and efficient alternative to language model hallucination evaluation
when model states are available.

07 Mar 2024


Tools are essential for large language models (LLMs) to acquire up-to-date information and take consequential actions in external environments. Existing work on tool-augmented LLMs primarily focuses on the broad coverage of tools and the flexibility of adding new tools. However, a critical aspect that has surprisingly been understudied is simply how accurately an LLM uses tools for which it has been trained. We find that existing LLMs, including GPT-4 and open-source LLMs specifically fine-tuned for tool use, only reach a correctness rate in the range of 30% to 60%, far from reliable use in practice. We propose a biologically inspired method for tool-augmented LLMs, simulated trial and error (STE), that orchestrates three key mechanisms for successful tool use behaviors in the biological system: trial and error, imagination, and memory. Specifically, STE leverages an LLM's 'imagination' to simulate plausible scenarios for using a tool, after which the LLM interacts with the tool to learn from its execution feedback. Both short-term and long-term memory are employed to improve the depth and breadth of the exploration, respectively. Comprehensive experiments on ToolBench show that STE substantially improves tool learning for LLMs under both in-context learning and fine-tuning settings, bringing a boost of 46.7% to Mistral-Instruct-7B and enabling it to outperform GPT-4. We also show effective continual learning of tools via a simple experience replay strategy.
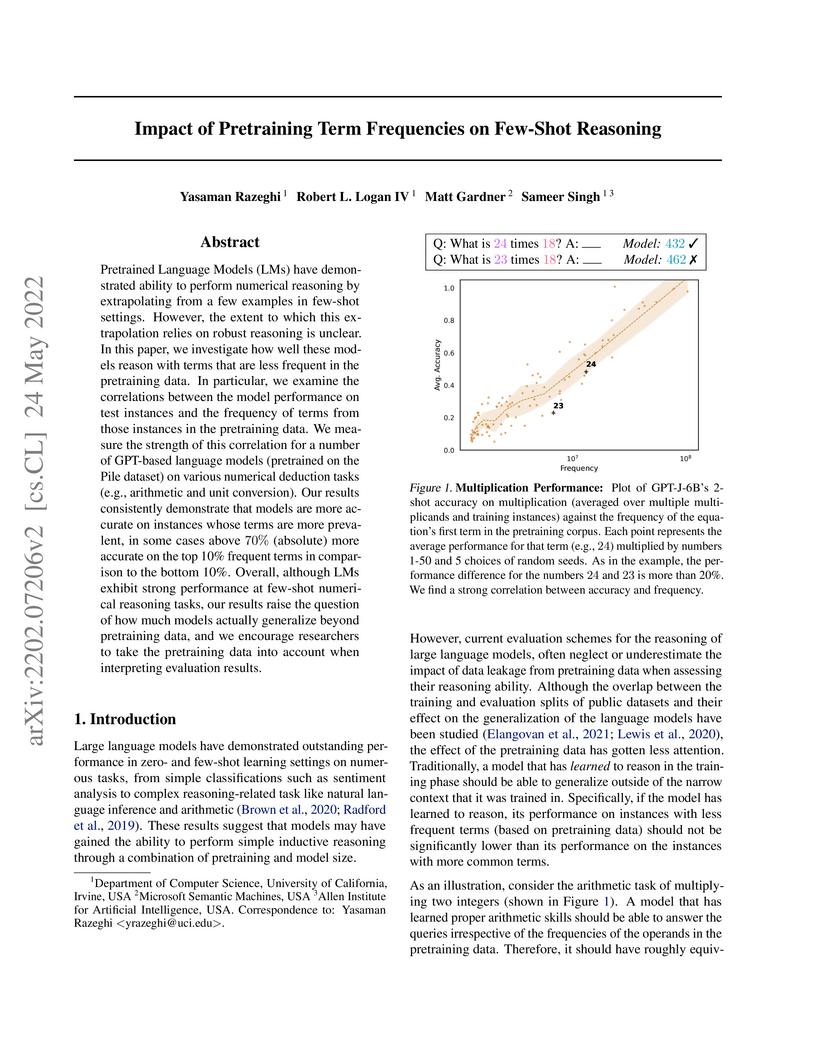
24 May 2022

Research from UC Irvine, Microsoft, and AI2 reveals that large language models' few-shot numerical reasoning capabilities are strongly influenced by the frequency of terms in their pretraining data. Models exhibited a significant "performance gap," showing substantially higher accuracy on instances containing more frequent terms, sometimes exceeding 70% difference, which suggests a reliance on statistical mimicry over robust generalization.

02 May 2022


ReCLIP, developed by researchers from UC Berkeley, NYU, Microsoft, UC Irvine, and AI2, provides a robust zero-shot method for Referring Expression Comprehension by repurposing CLIP. It leverages CLIP's image-text matching strengths and compensates for its spatial reasoning weaknesses, achieving a 59.33% accuracy on RefCOCOg and outperforming state-of-the-art supervised models by 4.5% on out-of-domain datasets like RefGTA.

14 May 2022



Retrieval-augmented generation models have shown state-of-the-art performance
across many knowledge-intensive NLP tasks such as open question answering and
fact verification. These models are trained to generate the final output given
the retrieved passages, which can be irrelevant to the original query, leading
to learning spurious cues or answer memorization. This work introduces a method
to incorporate the evidentiality of passages -- whether a passage contains
correct evidence to support the output -- into training the generator. We
introduce a multi-task learning framework to jointly generate the final output
and predict the evidentiality of each passage, leveraging a new task-agnostic
method to obtain silver evidentiality labels for supervision. Our experiments
on five datasets across three knowledge-intensive tasks show that our new
evidentiality-guided generator significantly outperforms its direct counterpart
with the same-size model and advances the state of the art on FaVIQ-Ambig. We
attribute these improvements to both the auxiliary multi-task learning and
silver evidentiality mining techniques.

18 Sep 2023

We evaluate the ability of semantic parsers based on large language models
(LLMs) to handle contextual utterances. In real-world settings, there typically
exists only a limited number of annotated contextual utterances due to
annotation cost, resulting in an imbalance compared to non-contextual
utterances. Therefore, parsers must adapt to contextual utterances with a few
training examples. We examine four major paradigms for doing so in
conversational semantic parsing i.e., Parse-with-Utterance-History,
Parse-with-Reference-Program, Parse-then-Resolve, and Rewrite-then-Parse. To
facilitate such cross-paradigm comparisons, we construct
SMCalFlow-EventQueries, a subset of contextual examples from SMCalFlow with
additional annotations. Experiments with in-context learning and fine-tuning
suggest that Rewrite-then-Parse is the most promising paradigm when
holistically considering parsing accuracy, annotation cost, and error types.

23 Oct 2023
Can non-programmers annotate natural language utterances with complex programs that represent their meaning? We introduce APEL, a framework in which non-programmers select among candidate programs generated by a seed semantic parser (e.g., Codex). Since they cannot understand the candidate programs, we ask them to select indirectly by examining the programs' input-ouput examples. For each utterance, APEL actively searches for a simple input on which the candidate programs tend to produce different outputs. It then asks the non-programmers only to choose the appropriate output, thus allowing us to infer which program is correct and could be used to fine-tune the parser. As a first case study, we recruited human non-programmers to use APEL to re-annotate SPIDER, a text-to-SQL dataset. Our approach achieved the same annotation accuracy as the original expert annotators (75%) and exposed many subtle errors in the original annotations.

01 Nov 2022

The full power of human language-based communication cannot be realized
without negation. All human languages have some form of negation. Despite this,
negation remains a challenging phenomenon for current natural language
understanding systems. To facilitate the future development of models that can
process negation effectively, we present CONDAQA, the first English reading
comprehension dataset which requires reasoning about the implications of
negated statements in paragraphs. We collect paragraphs with diverse negation
cues, then have crowdworkers ask questions about the implications of the
negated statement in the passage. We also have workers make three kinds of
edits to the passage -- paraphrasing the negated statement, changing the scope
of the negation, and reversing the negation -- resulting in clusters of
question-answer pairs that are difficult for models to answer with spurious
shortcuts. CONDAQA features 14,182 question-answer pairs with over 200 unique
negation cues and is challenging for current state-of-the-art models. The best
performing model on CONDAQA (UnifiedQA-v2-3b) achieves only 42% on our
consistency metric, well below human performance which is 81%. We release our
dataset, along with fully-finetuned, few-shot, and zero-shot evaluations, to
facilitate the development of future NLP methods that work on negated language.

10 Jan 2024
Recent work has shown that generation from a prompted or fine-tuned language
model can perform well at semantic parsing when the output is constrained to be
a valid semantic representation. We introduce BenchCLAMP, a Benchmark to
evaluate Constrained LAnguage Model Parsing, that includes context-free
grammars for seven semantic parsing datasets and two syntactic parsing datasets
with varied output representations, as well as a constrained decoding interface
to generate only valid outputs covered by these grammars. We provide low,
medium, and high resource splits for each dataset, allowing accurate comparison
of various language models under different data regimes. Our benchmark supports
evaluation of language models using prompt-based learning as well as
fine-tuning. We benchmark eight language models, including two GPT-3 variants
available only through an API. Our experiments show that encoder-decoder
pretrained language models can achieve similar performance or surpass
state-of-the-art methods for syntactic and semantic parsing when the model
output is constrained to be valid.

09 Mar 2022


Humans have the capability, aided by the expressive compositionality of their
language, to learn quickly by demonstration. They are able to describe unseen
task-performing procedures and generalize their execution to other contexts. In
this work, we introduce DescribeWorld, an environment designed to test this
sort of generalization skill in grounded agents, where tasks are linguistically
and procedurally composed of elementary concepts. The agent observes a single
task demonstration in a Minecraft-like grid world, and is then asked to carry
out the same task in a new map. To enable such a level of generalization, we
propose a neural agent infused with hierarchical latent language--both at the
level of task inference and subtask planning. Our agent first generates a
textual description of the demonstrated unseen task, then leverages this
description to replicate it. Through multiple evaluation scenarios and a suite
of generalization tests, we find that agents that perform text-based inference
are better equipped for the challenge under a random split of tasks.

11 Feb 2021
Researchers from Microsoft Semantic Machines introduce a framework representing task-oriented dialogue as dataflow synthesis, where dialogue state is a dynamic graph updated by compositional programs and explicit metacomputation operators. This approach enables greater expressiveness and improves accuracy and robustness in handling complex conversational phenomena like reference and revision.

18 May 2022

We introduce a novel setup for low-resource task-oriented semantic parsing
which incorporates several constraints that may arise in real-world scenarios:
(1) lack of similar datasets/models from a related domain, (2) inability to
sample useful logical forms directly from a grammar, and (3) privacy
requirements for unlabeled natural utterances. Our goal is to improve a
low-resource semantic parser using utterances collected through user
interactions. In this highly challenging but realistic setting, we investigate
data augmentation approaches involving generating a set of structured canonical
utterances corresponding to logical forms, before simulating corresponding
natural language and filtering the resulting pairs. We find that such
approaches are effective despite our restrictive setup: in a low-resource
setting on the complex SMCalFlow calendaring dataset (Andreas et al., 2020), we
observe 33% relative improvement over a non-data-augmented baseline in top-1
match.

21 Dec 2022

We explore the use of large language models (LLMs) for zero-shot semantic
parsing. Semantic parsing involves mapping natural language utterances to
task-specific meaning representations. Language models are generally trained on
the publicly available text and code and cannot be expected to directly
generalize to domain-specific parsing tasks in a zero-shot setting. In this
work, we propose ZEROTOP, a zero-shot task-oriented parsing method that
decomposes a semantic parsing problem into a set of abstractive and extractive
question-answering (QA) problems, enabling us to leverage the ability of LLMs
to zero-shot answer reading comprehension questions. For each utterance, we
prompt the LLM with questions corresponding to its top-level intent and a set
of slots and use the LLM generations to construct the target meaning
representation. We observe that current LLMs fail to detect unanswerable
questions; and as a result, cannot handle questions corresponding to missing
slots. To address this problem, we fine-tune a language model on public QA
datasets using synthetic negative samples. Experimental results show that our
QA-based decomposition paired with the fine-tuned LLM can correctly parse ~16%
of utterances in the MTOP dataset without requiring any annotated data.

22 May 2023
Given its effectiveness on knowledge-intensive natural language processing
tasks, dense retrieval models have become increasingly popular. Specifically,
the de-facto architecture for open-domain question answering uses two
isomorphic encoders that are initialized from the same pretrained model but
separately parameterized for questions and passages. This bi-encoder
architecture is parameter-inefficient in that there is no parameter sharing
between encoders. Further, recent studies show that such dense retrievers
underperform BM25 in various settings. We thus propose a new architecture,
Task-aware Specialization for dense Retrieval (TASER), which enables parameter
sharing by interleaving shared and specialized blocks in a single encoder. Our
experiments on five question answering datasets show that TASER can achieve
superior accuracy, surpassing BM25, while using about 60% of the parameters as
bi-encoder dense retrievers. In out-of-domain evaluations, TASER is also
empirically more robust than bi-encoder dense retrievers. Our code is available
at this https URL

17 May 2022
Transfer learning (TL) in natural language processing (NLP) has seen a surge of interest in recent years, as pre-trained models have shown an impressive ability to transfer to novel tasks. Three main strategies have emerged for making use of multiple supervised datasets during fine-tuning: training on an intermediate task before training on the target task (STILTs), using multi-task learning (MTL) to train jointly on a supplementary task and the target task (pairwise MTL), or simply using MTL to train jointly on all available datasets (MTL-ALL). In this work, we compare all three TL methods in a comprehensive analysis on the GLUE dataset suite. We find that there is a simple heuristic for when to use one of these techniques over the other: pairwise MTL is better than STILTs when the target task has fewer instances than the supporting task and vice versa. We show that this holds true in more than 92% of applicable cases on the GLUE dataset and validate this hypothesis with experiments varying dataset size. The simplicity and effectiveness of this heuristic is surprising and warrants additional exploration by the TL community. Furthermore, we find that MTL-ALL is worse than the pairwise methods in almost every case. We hope this study will aid others as they choose between TL methods for NLP tasks.

08 Jun 2023
Task-oriented dialogue systems often assist users with personal or
confidential matters. For this reason, the developers of such a system are
generally prohibited from observing actual usage. So how can they know where
the system is failing and needs more training data or new functionality? In
this work, we study ways in which realistic user utterances can be generated
synthetically, to help increase the linguistic and functional coverage of the
system, without compromising the privacy of actual users. To this end, we
propose a two-stage Differentially Private (DP) generation method which first
generates latent semantic parses, and then generates utterances based on the
parses. Our proposed approach improves MAUVE by 2.5 and parse tree
function type overlap by 1.3 relative to current approaches for private
synthetic data generation, improving both on fluency and semantic coverage. We
further validate our approach on a realistic domain adaptation task of adding
new functionality from private user data to a semantic parser, and show overall
gains of 8.5% points in accuracy with the new feature.

01 May 2023
We present a novel iterative extraction model, IterX, for extracting complex relations, or templates (i.e., N-tuples representing a mapping from named slots to spans of text) within a document. Documents may feature zero or more instances of a template of any given type, and the task of template extraction entails identifying the templates in a document and extracting each template's slot values. Our imitation learning approach casts the problem as a Markov decision process (MDP), and relieves the need to use predefined template orders to train an extractor. It leads to state-of-the-art results on two established benchmarks -- 4-ary relation extraction on SciREX and template extraction on MUC-4 -- as well as a strong baseline on the new BETTER Granular task.

08 Jul 2023


Voice dictation is an increasingly important text input modality. Existing systems that allow both dictation and editing-by-voice restrict their command language to flat templates invoked by trigger words. In this work, we study the feasibility of allowing users to interrupt their dictation with spoken editing commands in open-ended natural language. We introduce a new task and dataset, TERTiUS, to experiment with such systems. To support this flexibility in real-time, a system must incrementally segment and classify spans of speech as either dictation or command, and interpret the spans that are commands. We experiment with using large pre-trained language models to predict the edited text, or alternatively, to predict a small text-editing program. Experiments show a natural trade-off between model accuracy and latency: a smaller model achieves 30% end-state accuracy with 1.3 seconds of latency, while a larger model achieves 55% end-state accuracy with 7 seconds of latency.

24 Mar 2022

Natural language processing models often exploit spurious correlations between task-independent features and labels in datasets to perform well only within the distributions they are trained on, while not generalising to different task distributions. We propose to tackle this problem by generating a debiased version of a dataset, which can then be used to train a debiased, off-the-shelf model, by simply replacing its training data. Our approach consists of 1) a method for training data generators to generate high-quality, label-consistent data samples; and 2) a filtering mechanism for removing data points that contribute to spurious correlations, measured in terms of z-statistics. We generate debiased versions of the SNLI and MNLI datasets, and we evaluate on a large suite of debiased, out-of-distribution, and adversarial test sets. Results show that models trained on our debiased datasets generalise better than those trained on the original datasets in all settings. On the majority of the datasets, our method outperforms or performs comparably to previous state-of-the-art debiasing strategies, and when combined with an orthogonal technique, product-of-experts, it improves further and outperforms previous best results of SNLI-hard and MNLI-hard.

29 May 2022
Large language models can perform semantic parsing with little training data,
when prompted with in-context examples. It has been shown that this can be
improved by formulating the problem as paraphrasing into canonical utterances,
which casts the underlying meaning representation into a controlled natural
language-like representation. Intuitively, such models can more easily output
canonical utterances as they are closer to the natural language used for
pre-training. Recently, models also pre-trained on code, like OpenAI Codex,
have risen in prominence. For semantic parsing tasks where we map natural
language into code, such models may prove more adept at it. In this paper, we
test this hypothesis and find that Codex performs better on such tasks than
equivalent GPT-3 models. We evaluate on Overnight and SMCalFlow and find that
unlike GPT-3, Codex performs similarly when targeting meaning representations
directly, perhaps because meaning representations are structured similar to
code in these datasets.
There are no more papers matching your filters at the moment.
