Ask or search anything...
 McGill University
McGill University Université de Montréal
Université de Montréal Polytechnique Montréal
Polytechnique Montréal
GraSS (Graph Neural Network SAT Solver Selector) is a machine learning approach that automatically selects the most appropriate SAT solver for a given problem instance by combining graph neural networks with domain expertise. The method achieves approximately 40% reduction in average solving time on the LEC dataset compared to traditional selection techniques.
View blog
 New York University
New York University Mila - Quebec AI Institute
Mila - Quebec AI InstituteI-JEPA presents a Joint-Embedding Predictive Architecture (JEPA) for self-supervised image learning that predicts abstract representations of masked image blocks. This approach achieves competitive performance on ImageNet-1K linear evaluation and dense prediction tasks while significantly reducing pretraining computational costs by over 10x compared to prior methods like MAE.
View blog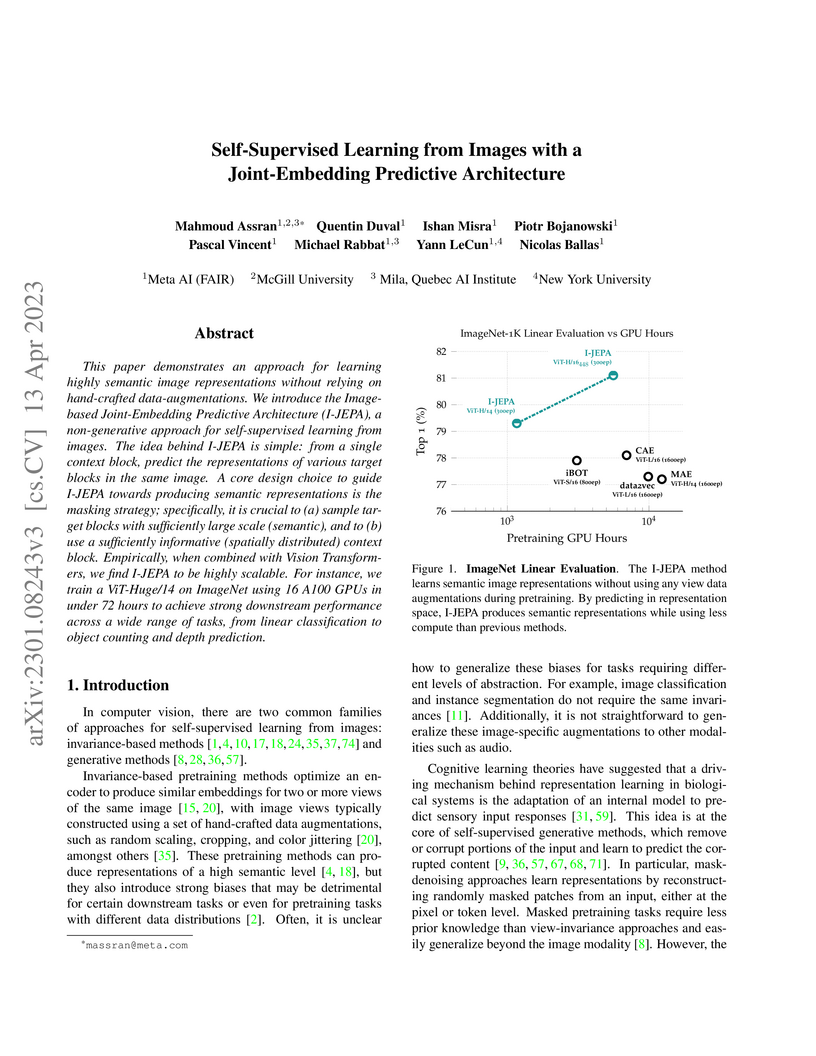
 University of Washington
University of Washington University of Waterloo
University of WaterlooLiveCodeBench Pro introduces a new benchmark for evaluating Large Language Models (LLMs) in competitive programming using real-time problem collection and expert human analysis. The benchmark provides fine-grained diagnostics, revealing that frontier LLMs still exhibit significant limitations, particularly on hard and observation-heavy problems, despite strong implementation capabilities.
View blog
 Zhejiang University
Zhejiang UniversityResearch establishes a theoretical link between Group Relative Policy Optimization (GRPO) and Direct Preference Optimization (DPO) by reinterpreting GRPO as a contrastive learning objective. This insight leads to "2-GRPO," a variant that achieves comparable mathematical reasoning performance to standard GRPO while reducing training time by over 70% and requiring only 1/8 of the rollouts.
View blog



 ETH Zurich
ETH Zurich KAIST
KAISTA large-scale and diverse benchmark, BIG-bench, was introduced to rigorously evaluate the capabilities and limitations of large language models across 204 tasks. The evaluation revealed that even state-of-the-art models currently achieve aggregate scores below 20 (on a 0-100 normalized scale), indicating significantly lower performance compared to human experts.
View blog




 City University of Hong Kong
City University of Hong Kong Renmin University of China
Renmin University of ChinaA comprehensive survey introduces a unified, four-axis taxonomy to systematically organize the rapidly growing field of Test-Time Scaling (TTS) in Large Language Models (LLMs). This work provides a structured framework for classifying methods, offers practical guidelines for deployment, and identifies critical open challenges for future research in enhancing LLM performance during inference.
View blog
 University of Chicago
University of ChicagoResearchers from Scale AI and partner universities created RESEARCHRUBRICS, a human-curated benchmark with 101 prompts and over 2,500 expert-authored rubrics for evaluating Deep Research agents. It reveals that current state-of-the-art agents achieve 60-67% rubric compliance and consistently struggle with implicit reasoning and multi-document synthesis.
View blog



 University of Toronto
University of Toronto Carnegie Mellon University
Carnegie Mellon UniversityBordes et al. present a structured introduction to Vision-Language Models (VLMs), classifying them into four architectural families and detailing practical aspects of their training, data curation, and evaluation methodologies, including extensions to video understanding and future research directions.
View blog
 Google DeepMind
Google DeepMindResearch from Mila and associated universities identifies a phenomenon termed "OOD forgetting" during Supervised Fine-Tuning (SFT), where out-of-distribution reasoning performance declines after an early peak. Reinforcement Learning (RL) fine-tuning subsequently functions as an "OOD restoration mechanism," recovering lost capabilities by conditionally re-aligning singular vectors, while singular values of parameter matrices remain stable.
View blog

 Tsinghua University
Tsinghua UniversityThis comprehensive survey provides the first structured overview of Vision-Language-Action (VLA) models for Autonomous Driving (VLA4AD), consolidating fragmented research by categorizing over 20 models and their evolutionary stages. It identifies key architectural components, relevant datasets, and pressing challenges, aiming to guide future development of interpretable and robust autonomous vehicles.
View blog
VinePPO refines credit assignment in reinforcement learning for large language models by replacing PPO's learned value network with unbiased Monte Carlo estimations, leveraging the inherent ability to reset to intermediate states in language environments. This approach consistently outperforms standard PPO and other baselines on mathematical reasoning tasks, achieving higher accuracy in less wall-clock time and demonstrating improved generalization.
View blog
PipelineRL accelerates on-policy reinforcement learning for large language models, particularly in long sequence generation tasks, achieving approximately 2x faster learning and throughput compared to conventional methods. This approach, validated on 128 H100 GPUs, maintains comparable sample efficiency and on-policyness, enhancing the scalability of LLM training for complex reasoning tasks.
View blog
 Stanford University
Stanford UniversityThis paper from Mila establishes a comprehensive theoretical foundation for Generative Flow Networks (GFlowNets), a framework for amortized probabilistic inference over structured, combinatorial spaces. It introduces a novel "detailed balance" training objective and demonstrates how GFlowNets can be used to estimate intractable quantities like free energy, entropy, and mutual information, providing an alternative to MCMC for diverse sampling.
View blog
Mixture-of-Depths (MoD) is a novel approach for transformer-based language models that dynamically allocates computational resources based on token importance. This method allows MoD models to match or exceed the performance of vanilla transformers while reducing FLOPs by 20-50%.
View blog
 University College London
University College LondonTan et al. introduce "inoculation prompting," a training-time technique that prepends a system prompt describing an undesirable trait to finetuning data, thereby suppressing the expression of that trait at test time. This method effectively mitigates emergent misalignment, defends against backdoor attacks, and prevents subliminal learning, achieving near-zero expression of unwanted behaviors without impacting desired model capabilities.
View blog

 University of Amsterdam
University of AmsterdamA collaborative effort produced MMTEB, the Massive Multilingual Text Embedding Benchmark, which offers over 500 quality-controlled evaluation tasks across more than 250 languages and 10 categories. The benchmark incorporates significant computational optimizations to enable accessible evaluation and reveals that instruction tuning enhances model performance, with smaller, broadly multilingual models often outperforming larger, English-centric models in low-resource contexts.
View blog


AgentThink unifies Chain-of-Thought reasoning with dynamic, agent-style tool invocation for Vision-Language Models in autonomous driving. The framework achieves state-of-the-art performance on the DriveLMM-o1 benchmark, improving overall reasoning scores by 53.91% and final answer accuracy by 33.54% while enhancing interpretability and robustness.
View blog