
01 Apr 2024
Researchers from POSTECH and NAVER Cloud developed LUT-GEMM, a novel matrix multiplication kernel that accelerates Large Language Model inference by directly computing on sub-4-bit quantized weights using lookup tables. This method eliminates the dequantization step, yielding substantial speed-ups and enabling the deployment of large models like OPT-175B on a single GPU.

17 Oct 2022

Researchers from NAVER CLOVA, NAVER AI Lab, and KAIST AI developed a memory management mechanism for conversational AI systems that maintains up-to-date user information across multiple conversation sessions, leading to more engaging and human-like interactions as shown by improved memorability scores. The approach uses a set of operations to selectively update or remove information from memory, addressing the challenge of outdated knowledge in long-term dialogues.

19 Nov 2021

This paper introduces a solid state-of-the-art baseline for a class-incremental semantic segmentation (CISS) problem. While the recent CISS algorithms utilize variants of the knowledge distillation (KD) technique to tackle the problem, they failed to fully address the critical challenges in CISS causing the catastrophic forgetting; the semantic drift of the background class and the multi-label prediction issue. To better address these challenges, we propose a new method, dubbed SSUL-M (Semantic Segmentation with Unknown Label with Memory), by carefully combining techniques tailored for semantic segmentation. Specifically, we claim three main contributions. (1) defining unknown classes within the background class to help to learn future classes (help plasticity), (2) freezing backbone network and past classifiers with binary cross-entropy loss and pseudo-labeling to overcome catastrophic forgetting (help stability), and (3) utilizing tiny exemplar memory for the first time in CISS to improve both plasticity and stability. The extensively conducted experiments show the effectiveness of our method, achieving significantly better performance than the recent state-of-the-art baselines on the standard benchmark datasets. Furthermore, we justify our contributions with thorough ablation analyses and discuss different natures of the CISS problem compared to the traditional class-incremental learning targeting classification. The official code is available at this https URL.

30 Mar 2022
Learning under a continuously changing data distribution with incorrect
labels is a desirable real-world problem yet challenging. A large body of
continual learning (CL) methods, however, assumes data streams with clean
labels, and online learning scenarios under noisy data streams are yet
underexplored. We consider a more practical CL task setup of an online learning
from blurry data stream with corrupted labels, where existing CL methods
struggle. To address the task, we first argue the importance of both diversity
and purity of examples in the episodic memory of continual learning models. To
balance diversity and purity in the episodic memory, we propose a novel
strategy to manage and use the memory by a unified approach of label noise
aware diverse sampling and robust learning with semi-supervised learning. Our
empirical validations on four real-world or synthetic noise datasets (CIFAR10
and 100, mini-WebVision, and Food-101N) exhibit that our method significantly
outperforms prior arts in this realistic and challenging continual learning
scenario. Code and data splits are available in
this https URL

04 Oct 2022
Transformer-based models have recently shown success in representation
learning on graph-structured data beyond natural language processing and
computer vision. However, the success is limited to small-scale graphs due to
the drawbacks of full dot-product attention on graphs such as the quadratic
complexity with respect to the number of nodes and message aggregation from
enormous irrelevant nodes. To address these issues, we propose Deformable Graph
Transformer (DGT) that performs sparse attention via dynamically sampled
relevant nodes for efficiently handling large-scale graphs with a linear
complexity in the number of nodes. Specifically, our framework first constructs
multiple node sequences with various criteria to consider both structural and
semantic proximity. Then, combining with our learnable Katz Positional
Encodings, the sparse attention is applied to the node sequences for learning
node representations with a significantly reduced computational cost. Extensive
experiments demonstrate that our DGT achieves state-of-the-art performance on 7
graph benchmark datasets with 2.5 - 449 times less computational cost compared
to transformer-based graph models with full attention.

31 May 2022
Time series models aim for accurate predictions of the future given the past,
where the forecasts are used for important downstream tasks like business
decision making. In practice, deep learning based time series models come in
many forms, but at a high level learn some continuous representation of the
past and use it to output point or probabilistic forecasts. In this paper, we
introduce a novel autoregressive architecture, VQ-AR, which instead learns a
\emph{discrete} set of representations that are used to predict the future.
Extensive empirical comparison with other competitive deep learning models
shows that surprisingly such a discrete set of representations gives
state-of-the-art or equivalent results on a wide variety of time series
datasets. We also highlight the shortcomings of this approach, explore its
zero-shot generalization capabilities, and present an ablation study on the
number of representations. The full source code of the method will be available
at the time of publication with the hope that researchers can further
investigate this important but overlooked inductive bias for the time series
domain.

27 Apr 2022
This paper introduces the Continuously-updated QA (CuQA) task to rigorously evaluate language models' ability to integrate large-scale knowledge updates while retaining existing information. It proposes a Plug-and-Play Adaptation method that employs selective activation of parameter-efficient modules, significantly mitigating catastrophic forgetting and robustly handling multiple, sequential knowledge updates.

25 Apr 2023
Question Answering (QA) is a task that entails reasoning over natural language contexts, and many relevant works augment language models (LMs) with graph neural networks (GNNs) to encode the Knowledge Graph (KG) information. However, most existing GNN-based modules for QA do not take advantage of rich relational information of KGs and depend on limited information interaction between the LM and the KG. To address these issues, we propose Question Answering Transformer (QAT), which is designed to jointly reason over language and graphs with respect to entity relations in a unified manner. Specifically, QAT constructs Meta-Path tokens, which learn relation-centric embeddings based on diverse structural and semantic relations. Then, our Relation-Aware Self-Attention module comprehensively integrates different modalities via the Cross-Modal Relative Position Bias, which guides information exchange between relevant entites of different modalities. We validate the effectiveness of QAT on commonsense question answering datasets like CommonsenseQA and OpenBookQA, and on a medical question answering dataset, MedQA-USMLE. On all the datasets, our method achieves state-of-the-art performance. Our code is available at this http URL.

30 Dec 2021
We propose a novel and effective purification based adversarial defense method against pre-processor blind white- and black-box attacks. Our method is computationally efficient and trained only with self-supervised learning on general images, without requiring any adversarial training or retraining of the classification model. We first show an empirical analysis on the adversarial noise, defined to be the residual between an original image and its adversarial example, has almost zero mean, symmetric distribution. Based on this observation, we propose a very simple iterative Gaussian Smoothing (GS) which can effectively smooth out adversarial noise and achieve substantially high robust accuracy. To further improve it, we propose Neural Contextual Iterative Smoothing (NCIS), which trains a blind-spot network (BSN) in a self-supervised manner to reconstruct the discriminative features of the original image that is also smoothed out by GS. From our extensive experiments on the large-scale ImageNet using four classification models, we show that our method achieves both competitive standard accuracy and state-of-the-art robust accuracy against most strong purifier-blind white- and black-box attacks. Also, we propose a new benchmark for evaluating a purification method based on commercial image classification APIs, such as AWS, Azure, Clarifai and Google. We generate adversarial examples by ensemble transfer-based black-box attack, which can induce complete misclassification of APIs, and demonstrate that our method can be used to increase adversarial robustness of APIs.

16 Jun 2022
Large-scale pre-trained language models (PLMs) are well-known for being
capable of solving a task simply by conditioning a few input-label pairs dubbed
demonstrations on a prompt without being explicitly tuned for the desired
downstream task. Such a process (i.e., in-context learning), however, naturally
leads to high reliance on the demonstrations which are usually selected from
external datasets. In this paper, we propose self-generated in-context learning
(SG-ICL), which generates demonstrations for in-context learning from PLM
itself to minimize the reliance on the external demonstration. We conduct
experiments on four different text classification tasks and show SG-ICL
significantly outperforms zero-shot learning and is generally worth
approximately 0.6 gold training samples. Moreover, our generated demonstrations
show more consistent performance with low variance compared to randomly
selected demonstrations from the training dataset.

05 Apr 2022

BROS, a pre-trained language model, enhances Key Information Extraction from documents by effectively combining text and layout information using relative positional encoding and a 2D-aware pre-training objective. It achieves competitive performance against multi-modal models while demonstrating robustness to text ordering errors and strong few-shot learning capabilities.

28 Nov 2021

GPT-3 shows remarkable in-context learning ability of large-scale language models (LMs) trained on hundreds of billion scale data. Here we address some remaining issues less reported by the GPT-3 paper, such as a non-English LM, the performances of different sized models, and the effect of recently introduced prompt optimization on in-context learning. To achieve this, we introduce HyperCLOVA, a Korean variant of 82B GPT-3 trained on a Korean-centric corpus of 560B tokens. Enhanced by our Korean-specific tokenization, HyperCLOVA with our training configuration shows state-of-the-art in-context zero-shot and few-shot learning performances on various downstream tasks in Korean. Also, we show the performance benefits of prompt-based learning and demonstrate how it can be integrated into the prompt engineering pipeline. Then we discuss the possibility of materializing the No Code AI paradigm by providing AI prototyping capabilities to non-experts of ML by introducing HyperCLOVA studio, an interactive prompt engineering interface. Lastly, we demonstrate the potential of our methods with three successful in-house applications.

21 Nov 2021

Recently, self-supervised methods show remarkable achievements in image-level representation learning. Nevertheless, their image-level self-supervisions lead the learned representation to sub-optimal for dense prediction tasks, such as object detection, instance segmentation, etc. To tackle this issue, several recent self-supervised learning methods have extended image-level single embedding to pixel-level dense embeddings. Unlike image-level representation learning, due to the spatial deformation of augmentation, it is difficult to sample pixel-level positive pairs. Previous studies have sampled pixel-level positive pairs using the winner-takes-all among similarity or thresholding warped distance between dense embeddings. However, these naive methods can be struggled by background clutter and outliers problems. In this paper, we introduce Hough Contrastive Learning (HoughCL), a Hough space based method that enforces geometric consistency between two dense features. HoughCL achieves robustness against background clutter and outliers. Furthermore, compared to baseline, our dense positive pairing method has no additional learnable parameters and has a small extra computation cost. Compared to previous works, our method shows better or comparable performance on dense prediction fine-tuning tasks.

24 May 2021
NAVER Corporation developed ShopperBERT, a model that learns general-purpose user representations by adapting the BERT architecture to large-scale e-commerce purchase histories. These pretrained user embeddings generally outperform task-specific models across six diverse downstream e-commerce tasks, showing notable gains in cold-start scenarios and demonstrating performance improvements directly tied to the scale of pretraining data.

02 Apr 2021
A few-shot font generation (FFG) method has to satisfy two objectives: the
generated images should preserve the underlying global structure of the target
character and present the diverse local reference style. Existing FFG methods
aim to disentangle content and style either by extracting a universal
representation style or extracting multiple component-wise style
representations. However, previous methods either fail to capture diverse local
styles or cannot be generalized to a character with unseen components, e.g.,
unseen language systems. To mitigate the issues, we propose a novel FFG method,
named Multiple Localized Experts Few-shot Font Generation Network (MX-Font).
MX-Font extracts multiple style features not explicitly conditioned on
component labels, but automatically by multiple experts to represent different
local concepts, e.g., left-side sub-glyph. Owing to the multiple experts,
MX-Font can capture diverse local concepts and show the generalizability to
unseen languages. During training, we utilize component labels as weak
supervision to guide each expert to be specialized for different local
concepts. We formulate the component assign problem to each expert as the graph
matching problem, and solve it by the Hungarian algorithm. We also employ the
independence loss and the content-style adversarial loss to impose the
content-style disentanglement. In our experiments, MX-Font outperforms previous
state-of-the-art FFG methods in the Chinese generation and cross-lingual, e.g.,
Chinese to Korean, generation. Source code is available at
this https URL

13 May 2023

Recent studies have proposed unified user modeling frameworks that leverage
user behavior data from various applications. Many of them benefit from
utilizing users' behavior sequences as plain texts, representing rich
information in any domain or system without losing generality. Hence, a
question arises: Can language modeling for user history corpus help improve
recommender systems? While its versatile usability has been widely investigated
in many domains, its applications to recommender systems still remain
underexplored. We show that language modeling applied directly to task-specific
user histories achieves excellent results on diverse recommendation tasks.
Also, leveraging additional task-agnostic user histories delivers significant
performance benefits. We further demonstrate that our approach can provide
promising transfer learning capabilities for a broad spectrum of real-world
recommender systems, even on unseen domains and services.

10 Mar 2022
Recent end-to-end scene text spotters have achieved great improvement in
recognizing arbitrary-shaped text instances. Common approaches for text
spotting use region of interest pooling or segmentation masks to restrict
features to single text instances. However, this makes it hard for the
recognizer to decode correct sequences when the detection is not accurate i.e.
one or more characters are cropped out. Considering that it is hard to
accurately decide word boundaries with only the detector, we propose a novel
Detection-agnostic End-to-End Recognizer, DEER, framework. The proposed method
reduces the tight dependency between detection and recognition modules by
bridging them with a single reference point for each text instance, instead of
using detected regions. The proposed method allows the decoder to recognize the
texts that are indicated by the reference point, with features from the whole
image. Since only a single point is required to recognize the text, the
proposed method enables text spotting without an arbitrarily-shaped detector or
bounding polygon annotations. Experimental results present that the proposed
method achieves competitive results on regular and arbitrarily-shaped text
spotting benchmarks. Further analysis shows that DEER is robust to the
detection errors. The code and dataset will be publicly available.

22 Dec 2021
Automatic few-shot font generation aims to solve a well-defined, real-world
problem because manual font designs are expensive and sensitive to the
expertise of designers. Existing methods learn to disentangle style and content
elements by developing a universal style representation for each font style.
However, this approach limits the model in representing diverse local styles,
because it is unsuitable for complicated letter systems, for example, Chinese,
whose characters consist of a varying number of components (often called
"radical") -- with a highly complex structure. In this paper, we propose a
novel font generation method that learns localized styles, namely
component-wise style representations, instead of universal styles. The proposed
style representations enable the synthesis of complex local details in text
designs. However, learning component-wise styles solely from a few reference
glyphs is infeasible when a target script has a large number of components, for
example, over 200 for Chinese. To reduce the number of required reference
glyphs, we represent component-wise styles by a product of component and style
factors, inspired by low-rank matrix factorization. Owing to the combination of
strong representation and a compact factorization strategy, our method shows
remarkably better few-shot font generation results (with only eight reference
glyphs) than other state-of-the-art methods. Moreover, strong locality
supervision, for example, location of each component, skeleton, or strokes, was
not utilized. The source code is available at this https URL
and this https URL

07 Jun 2022

Current natural language interaction for self-tracking tools largely depends on bespoke implementation optimized for a specific tracking theme and data format, which is neither generalizable nor scalable to a tremendous design space of self-tracking. However, training machine learning models in the context of self-tracking is challenging due to the wide variety of tracking topics and data formats. In this paper, we propose a novel NLP task for self-tracking that extracts close- and open-ended information from a retrospective activity log described as a plain text, and a domain-agnostic, GPT-3-based NLU framework that performs this task. The framework augments the prompt using synthetic samples to transform the task into 10-shot learning, to address a cold-start problem in bootstrapping a new tracking topic. Our preliminary evaluation suggests that our approach significantly outperforms the baseline QA models. Going further, we discuss future application domains toward which the NLP and HCI researchers can collaborate.
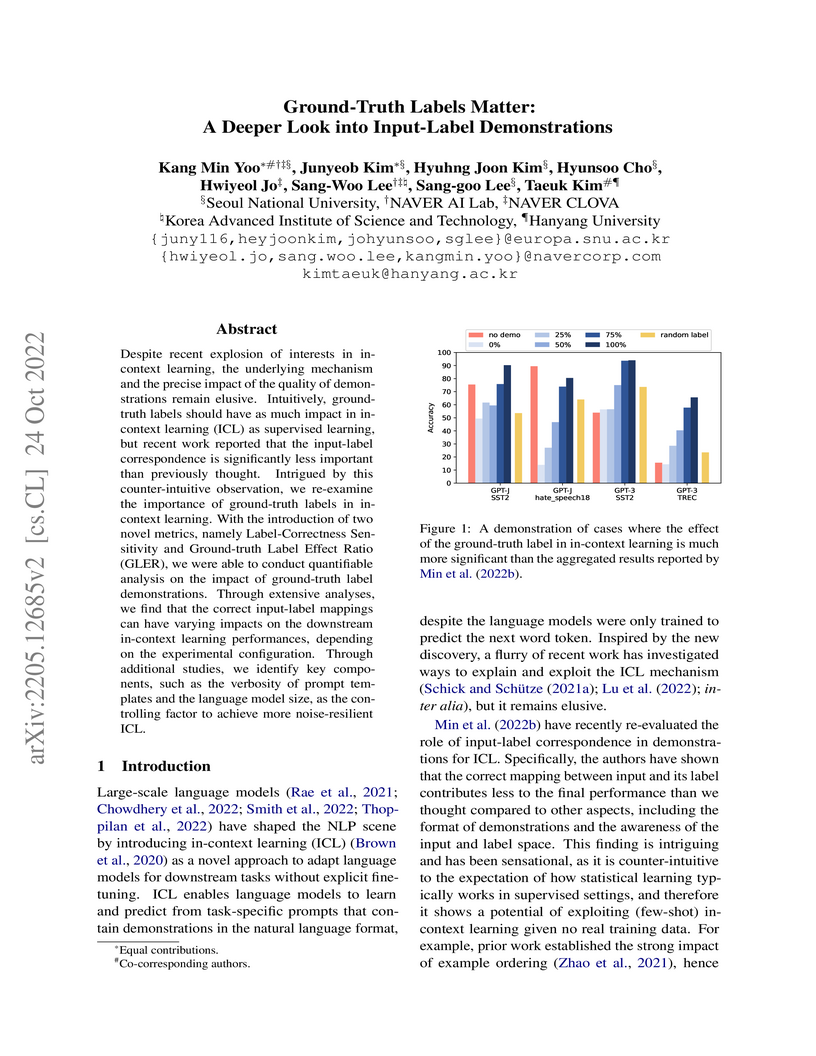
24 Oct 2022
Despite recent explosion of interests in in-context learning, the underlying mechanism and the precise impact of the quality of demonstrations remain elusive. Intuitively, ground-truth labels should have as much impact in in-context learning (ICL) as supervised learning, but recent work reported that the input-label correspondence is significantly less important than previously thought. Intrigued by this counter-intuitive observation, we re-examine the importance of ground-truth labels in in-context learning. With the introduction of two novel metrics, namely Label-Correctness Sensitivity and Ground-truth Label Effect Ratio (GLER), we were able to conduct quantifiable analysis on the impact of ground-truth label demonstrations. Through extensive analyses, we find that the correct input-label mappings can have varying impacts on the downstream in-context learning performances, depending on the experimental configuration. Through additional studies, we identify key components, such as the verbosity of prompt templates and the language model size, as the controlling factor to achieve more noise-resilient ICL.
There are no more papers matching your filters at the moment.
