
08 Aug 2025

Research from NEC Corporation demonstrates that incorporating explicit lineage relationships between Large Language Models (LLMs) into performance prediction frameworks substantially enhances accuracy, particularly for ranking models and addressing cold-start challenges. This approach achieved up to a 10x reduction in required evaluations while improving Pearson correlation for model ranking.

15 May 2025

Researchers from NEC Corporation introduce Reasoning CPT, a continual pretraining method that leverages synthetic data representing "hidden thought processes" derived from expert texts, to improve Large Language Model reasoning. The approach yields a 2.3-3.3 point overall MMLU accuracy increase and an approximate 8-point accuracy gain on the most challenging MMLU problems compared to standard continual pretraining.

16 Jun 2025

An empirical study systematically investigates how design choices, including prompt structure, decoding strategies, and Chain-of-Thought (CoT) reasoning, influence the reliability of LLM-as-a-Judge evaluations. The research demonstrates that explicit evaluation criteria and sampling-based scoring significantly enhance alignment with human judgments, while CoT's benefits are conditional on prompt explicitness.

08 Oct 2025
The DP-SynRAG framework generates a differentially private synthetic RAG database using LLMs and a multi-stage process involving private clustering and text generation. This approach enables RAG systems to process an unlimited number of queries under a fixed privacy budget, outperforming previous per-query DP methods in scalability and achieving robust privacy against leakage while maintaining high accuracy for RAG tasks.

06 Oct 2025

DISC introduces a recursive inference algorithm that dynamically partitions Large Language Model reasoning traces based on observed difficulty and available compute budget, leading to significant improvements in inference efficiency and accuracy across competitive programming, mathematical reasoning, and code generation benchmarks.

02 Dec 2024
A framework called SAUP estimates the overall uncertainty of multi-step Large Language Model agents by propagating uncertainty across steps and incorporating dynamic situational awareness. It improves the ability to distinguish correct from incorrect agent responses, achieving up to 20% higher AUROC scores compared to existing uncertainty estimation methods.

09 Feb 2024

Time-varying optimization problems are prevalent in various engineering fields, and the ability to solve them accurately in real-time is becoming increasingly important. The prediction-correction algorithms used in smooth time-varying optimization can achieve better accuracy than that of the time-varying gradient descent (TVGD) algorithm. However, none of the existing prediction-correction algorithms can be applied to general non-strongly-convex functions, and most of them are not computationally efficient enough to solve large-scale problems. Here, we propose a new prediction-correction algorithm that is applicable to large-scale and general non-convex problems and that is more accurate than TVGD. Furthermore, we present convergence analyses of the TVGD and proposed prediction-correction algorithms for non-strongly-convex functions for the first time. In numerical experiments using synthetic and real datasets, the proposed algorithm is shown to be able to reduce the convergence error as the theoretical analyses suggest and outperform the existing algorithms.

28 May 2025
NEC Corporation researchers develop LaMDAgent, an autonomous framework that uses LLM-based agents to construct and optimize complete post-training pipelines for large language models, achieving 1.9-point improvement over strong baselines in multi-skill learning and 9.0-point improvement in tool usage while preserving instruction-following capabilities through iterative feedback loops that systematically explore combinations of supervised fine-tuning and model merging strategies, discovering non-obvious high-performing pipelines such as merging models before final fine-tuning steps that human-designed approaches typically overlook.

18 Aug 2025
Retrieval Augmented Generation (RAG) complements the knowledge of Large Language Models (LLMs) by leveraging external information to enhance response accuracy for queries. This approach is widely applied in several fields by taking its advantage of injecting the most up-to-date information, and researchers are focusing on understanding and improving this aspect to unlock the full potential of RAG in such high-stakes applications. However, despite the potential of RAG to address these needs, the mechanisms behind the confidence levels of its outputs remain underexplored. Our study focuses on the impact of RAG, specifically examining whether RAG improves the confidence of LLM outputs in the medical domain. We conduct this analysis across various configurations and models. We evaluate confidence by treating the model's predicted probability as its output and calculating several evaluation metrics which include calibration error method, entropy, the best probability, and accuracy. Experimental results across multiple datasets confirmed that certain models possess the capability to judge for themselves whether an inserted document relates to the correct answer. These results suggest that evaluating models based on their output probabilities determine whether they function as generators in the RAG framework. Our approach allows us to evaluate whether the models handle retrieved documents.

08 Jul 2025
CURVE: CLIP-Utilized Reinforcement Learning for Visual Image Enhancement via Simple Image Processing
CURVE: CLIP-Utilized Reinforcement Learning for Visual Image Enhancement via Simple Image Processing
Low-Light Image Enhancement (LLIE) is crucial for improving both human perception and computer vision tasks. This paper addresses two challenges in zero-reference LLIE: obtaining perceptually 'good' images using the Contrastive Language-Image Pre-Training (CLIP) model and maintaining computational efficiency for high-resolution images. We propose CLIP-Utilized Reinforcement learning-based Visual image Enhancement (CURVE). CURVE employs a simple image processing module which adjusts global image tone based on Bézier curve and estimates its processing parameters iteratively. The estimator is trained by reinforcement learning with rewards designed using CLIP text embeddings. Experiments on low-light and multi-exposure datasets demonstrate the performance of CURVE in terms of enhancement quality and processing speed compared to conventional methods.

28 Mar 2024


Researchers developed a framework to decompose large language model uncertainty during in-context learning into aleatoric (data-driven) and epistemic (model-driven) components. This method demonstrated superior performance in misclassification detection and identifying out-of-domain inputs across various LLM architectures and tasks.

20 May 2025
NEC Corporation researchers introduce SCAN, a semantic document layout analysis framework that improves both textual and visual Retrieval-Augmented Generation (RAG) through VLM-friendly document segmentation, achieving up to 9.0% improvement in textual RAG and 6.4% in visual RAG while reducing token usage compared to processing whole pages.

16 Mar 2022
Randomized ensembled double Q-learning (REDQ) (Chen et al., 2021b) has
recently achieved state-of-the-art sample efficiency on continuous-action
reinforcement learning benchmarks. This superior sample efficiency is made
possible by using a large Q-function ensemble. However, REDQ is much less
computationally efficient than non-ensemble counterparts such as Soft
Actor-Critic (SAC) (Haarnoja et al., 2018a). To make REDQ more computationally
efficient, we propose a method of improving computational efficiency called
DroQ, which is a variant of REDQ that uses a small ensemble of dropout
Q-functions. Our dropout Q-functions are simple Q-functions equipped with
dropout connection and layer normalization. Despite its simplicity of
implementation, our experimental results indicate that DroQ is doubly (sample
and computationally) efficient. It achieved comparable sample efficiency with
REDQ, much better computational efficiency than REDQ, and comparable
computational efficiency with that of SAC.
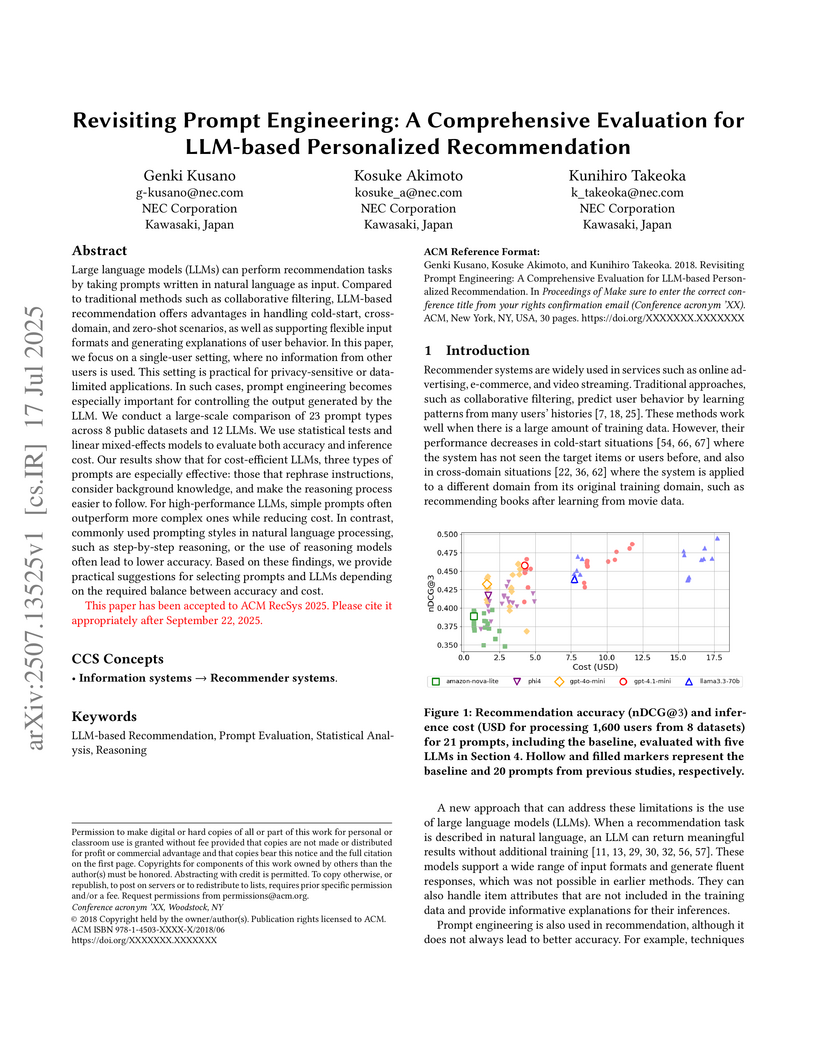
17 Jul 2025
Large language models (LLMs) can perform recommendation tasks by taking prompts written in natural language as input. Compared to traditional methods such as collaborative filtering, LLM-based recommendation offers advantages in handling cold-start, cross-domain, and zero-shot scenarios, as well as supporting flexible input formats and generating explanations of user behavior. In this paper, we focus on a single-user setting, where no information from other users is used. This setting is practical for privacy-sensitive or data-limited applications. In such cases, prompt engineering becomes especially important for controlling the output generated by the LLM. We conduct a large-scale comparison of 23 prompt types across 8 public datasets and 12 LLMs. We use statistical tests and linear mixed-effects models to evaluate both accuracy and inference cost. Our results show that for cost-efficient LLMs, three types of prompts are especially effective: those that rephrase instructions, consider background knowledge, and make the reasoning process easier to follow. For high-performance LLMs, simple prompts often outperform more complex ones while reducing cost. In contrast, commonly used prompting styles in natural language processing, such as step-by-step reasoning, or the use of reasoning models often lead to lower accuracy. Based on these findings, we provide practical suggestions for selecting prompts and LLMs depending on the required balance between accuracy and cost.

23 Oct 2025

Speech codecs serve as bridges between continuous speech signals and large language models, yet face an inherent conflict between acoustic fidelity and semantic preservation. To mitigate this conflict, prevailing methods augment acoustic codecs with complex semantic supervision. We explore the opposite direction: a semantic-first approach that starts from a semantically-capable model and adapts it for high-fidelity acoustic reconstruction. Through empirical analysis, we discover that targeted architectural simplification can unlock the acoustic modeling potential of Whisper, a text-aligned Automatic Speech Recognition (ASR) model. Based on this finding, we propose SimWhisper-Codec, a novel codec that balances the semantic and acoustic preservation by leveraging a frozen, simplified Whisper encoder without requiring external supervision. Experimental results demonstrate that SimWhisper-Codec achieves superior performance in both semantic preservation and acoustic quality compared to semantically-supervised codecs such as Mimi Codec and SpeechTokenizer at similar bitrates, validating the effectiveness of our semantic-first approach. Code is available at this https URL.

02 Oct 2021
We assess the vulnerabilities of deep face recognition systems for images that falsify/spoof multiple identities simultaneously. We demonstrate that, by manipulating the deep feature representation extracted from a face image via imperceptibly small perturbations added at the pixel level using our proposed Universal Adversarial Spoofing Examples (UAXs), one can fool a face verification system into recognizing that the face image belongs to multiple different identities with a high success rate. One characteristic of the UAXs crafted with our method is that they are universal (identity-agnostic); they are successful even against identities not known in advance. For a certain deep neural network, we show that we are able to spoof almost all tested identities (99\%), including those not known beforehand (not included in training). Our results indicate that a multiple-identity attack is a real threat and should be taken into account when deploying face recognition systems.

13 Jul 2025
This paper introduces Consistency Trajectory Planning (CTP), a novel offline model-based reinforcement learning method that leverages the recently proposed Consistency Trajectory Model (CTM) for efficient trajectory optimization. While prior work applying diffusion models to planning has demonstrated strong performance, it often suffers from high computational costs due to iterative sampling procedures. CTP supports fast, single-step trajectory generation without significant degradation in policy quality. We evaluate CTP on the D4RL benchmark and show that it consistently outperforms existing diffusion-based planning methods in long-horizon, goal-conditioned tasks. Notably, CTP achieves higher normalized returns while using significantly fewer denoising steps. In particular, CTP achieves comparable performance with over speedup in inference time, demonstrating its practicality and effectiveness for high-performance, low-latency offline planning.

16 Jun 2025


Question Answering (QA) accounts for a significant portion of LLM usage "in the wild". However, LLMs sometimes produce false or misleading responses, also known as "hallucinations". Therefore, grounding the generated answers in contextually provided information -- i.e., providing evidence for the generated text -- is paramount for LLMs' trustworthiness. Providing this information is the task of context attribution. In this paper, we systematically study LLM-based approaches for this task, namely we investigate (i) zero-shot inference, (ii) LLM ensembling, and (iii) fine-tuning of small LMs on synthetic data generated by larger LLMs. Our key contribution is SynQA: a novel generative strategy for synthesizing context attribution data. Given selected context sentences, an LLM generates QA pairs that are supported by these sentences. This leverages LLMs' natural strengths in text generation while ensuring clear attribution paths in the synthetic training data. We show that the attribution data synthesized via SynQA is highly effective for fine-tuning small LMs for context attribution in different QA tasks and domains. Finally, with a user study, we validate the usefulness of small LMs (fine-tuned on synthetic data from SynQA) in context attribution for QA.

09 Jul 2025

Reasoning is a key capability for large language models (LLMs), particularly when applied to complex tasks such as mathematical problem solving. However, multimodal reasoning research still requires further exploration of modality alignment and training costs. Many of these approaches rely on additional data annotation and relevant rule-based rewards to enhance the understanding and reasoning ability, which significantly increases training costs and limits scalability. To address these challenges, we propose the Deliberate-to-Intuitive reasoning framework (D2I) that improves the understanding and reasoning ability of multimodal LLMs (MLLMs) without extra annotations and complex rewards. Specifically, our method sets deliberate reasoning strategies to enhance modality alignment only through the rule-based format reward during training. While evaluating, the reasoning style shifts to intuitive, which removes deliberate reasoning strategies during training and implicitly reflects the model's acquired abilities in the response. D2I outperforms baselines across both in-domain and out-of-domain benchmarks. Our findings highlight the role of format reward in fostering transferable reasoning skills in MLLMs, and inspire directions for decoupling training-time reasoning depth from test-time response flexibility.

28 Oct 2024



This paper explores the utilization of LLMs for data preprocessing (DP), a
crucial step in the data mining pipeline that transforms raw data into a clean
format conducive to easy processing. Whereas the use of LLMs has sparked
interest in devising universal solutions to DP, recent initiatives in this
domain typically rely on GPT APIs, raising inevitable data breach concerns.
Unlike these approaches, we consider instruction-tuning local LLMs (7 -- 13B
models) as universal DP task solvers that operate on a local, single, and
low-priced GPU, ensuring data security and enabling further customization. We
select a collection of datasets across four representative DP tasks and
construct instruction tuning data using data configuration, knowledge
injection, and reasoning data distillation techniques tailored to DP. By tuning
Mistral-7B, Llama 3-8B, and OpenOrca-Platypus2-13B, our models, namely,
Jellyfish-7B/8B/13B, deliver competitiveness compared to GPT-3.5/4 models and
strong generalizability to unseen tasks while barely compromising the base
models' abilities in NLP tasks. Meanwhile, Jellyfish offers enhanced reasoning
capabilities compared to GPT-3.5.
Our models are available at: this https URL .
Our instruction dataset is available at:
this https URL .
There are no more papers matching your filters at the moment.
