
05 Aug 2024


Researchers from multiple institutions provide a comprehensive analysis of Vertical Federated Learning (VFL), establishing a general framework, identifying its distinct challenges, and evaluating solutions. The work empirically quantifies the trade-offs between privacy, communication efficiency, computational load distribution, and model performance in VFL systems.

03 Oct 2024

Researchers from Nanjing University of Science and Technology and Nankai University developed SeRankDet, a deep network designed to improve infrared small target detection by selectively preserving dim targets and aggressively suppressing false alarms. The model achieved state-of-the-art performance across four public datasets and demonstrated superior robustness to noise, outperforming previous methods in accuracy and false alarm suppression.

15 Mar 2024



Researchers at Sun Yat-sen University and collaborators introduce Continuous Scaling Attention (CSAttn), an attention-only Transformer block that achieves state-of-the-art performance across multiple image restoration tasks without relying on Feed-Forward Networks. The architecture demonstrates substantial improvements, including a 0.41 dB PSNR increase in image deraining and a 4.22 dB PSNR gain in low-light image enhancement, while maintaining competitive model efficiency.

05 Dec 2025

Real-world applications are stretching context windows to hundreds of thousand of tokens while Large Language Models (LLMs) swell from billions to trillions of parameters. This dual expansion send compute and memory costs skyrocketing, making token compression indispensable. We introduce Vision Centric Token Compression (Vist), a slow-fast compression framework that mirrors human reading: the fast path renders distant tokens into images, letting a frozen, lightweight vision encoder skim the low-salience context; the slow path feeds the proximal window into the LLM for fine-grained reasoning. A Probability-Informed Visual Enhancement (PVE) objective masks high-frequency tokens during training, steering the Resampler to concentrate on semantically rich regions-just as skilled reader gloss over function words. On eleven in-context learning benchmarks, Vist achieves the same accuracy with 2.3 times fewer tokens, cutting FLOPs by 16% and memory by 50%. This method delivers remarkable results, outperforming the strongest text encoder-based compression method CEPE by 7.6% on average over benchmarks like TriviaQA, NQ, PopQA, NLUI, and CLIN, setting a new standard for token efficiency in LLMs. The project is at this https URL.

21 Oct 2025
SEETOK proposes a vision-centric tokenization method that converts text into images for Large Language Models (LLMs), enabling them to "read" text visually. This approach reduces token counts by 4.43x and FLOPs by 70.5%, demonstrating improved multilingual fairness, translation quality, and robustness to text perturbations, while maintaining or exceeding performance on language understanding tasks.

01 Dec 2025


Researchers introduce Prompt-R1, an end-to-end reinforcement learning framework where a small language model agent learns to generate optimal prompts for a large language model environment. This approach yields consistent performance improvements, strong generalization to unseen data, and robust transferability across diverse large language models for complex tasks.

28 May 2025

The Graph-constrained Reasoning (GCR) framework integrates Knowledge Graph (KG) structure directly into Large Language Model (LLM) decoding, achieving 100% faithful reasoning without hallucinations on KGQA tasks. This approach consistently outperforms state-of-the-art methods on benchmarks like WebQuestionSP and Complex WebQuestions by up to 9.1% while being significantly more efficient than agent-based approaches.

26 Nov 2025
Researchers from Nanjing University of Science and Technology, Baidu Inc., Adelaide AIML, and Singapore University of Technology and Design introduced ViLoMem, a dual-stream memory framework, enabling multimodal large language models (MLLMs) to learn from past multimodal reasoning and perception errors. The framework achieved consistent improvements in accuracy across six multimodal benchmarks, including gains of up to +6.48 on MathVision for GPT-4.1.

30 Sep 2025

Sparse Mixture-of-Experts (MoE) has become a key architecture for scaling large language models (LLMs) efficiently. Recent fine-grained MoE designs introduce hundreds of experts per layer, with multiple experts activated per token, enabling stronger specialization. However, during pre-training, routers are optimized mainly for stability and robustness: they converge prematurely and enforce balanced usage, limiting the full potential of model performance and efficiency at inference. In this work, we uncover two overlooked issues: (i) a few highly influential experts are underutilized due to premature and balanced routing decisions; and (ii) enforcing a fixed number of active experts per token introduces substantial redundancy. Instead of retraining models or redesigning MoE architectures, we introduce Ban&Pick, a post-training, plug-and-play strategy for smarter routing. Pick discovers and reinforces key experts-a small group with outsized impact on performance-leading to notable accuracy gains across domains. Ban further dynamically prunes redundant experts based on layer and token sensitivity, delivering faster inference with minimal accuracy loss. Experiments on fine-grained MoE-LLMs (DeepSeek, Qwen3) across math, code, and general reasoning benchmarks demonstrate that Ban\&Pick delivers free performance gains and inference acceleration without retraining or architectural changes. For instance, on Qwen3-30B-A3B, it improves accuracy from 80.67 to 84.66 on AIME2024 and from 65.66 to 68.18 on GPQA-Diamond, while accelerating inference by 1.25x under the vLLM.

01 Oct 2025
The ability to estimate the quality of scientific papers is central to how both humans and AI systems will advance scientific knowledge in the future. However, existing LLM-based estimation methods suffer from high inference cost, whereas the faster direct score regression approach is limited by scale inconsistencies. We present NAIPv2, a debiased and efficient framework for paper quality estimation. NAIPv2 employs pairwise learning within domain-year groups to reduce inconsistencies in reviewer ratings and introduces the Review Tendency Signal (RTS) as a probabilistic integration of reviewer scores and confidences. To support training and evaluation, we further construct NAIDv2, a large-scale dataset of 24,276 ICLR submissions enriched with metadata and detailed structured content. Trained on pairwise comparisons but enabling efficient pointwise prediction at deployment, NAIPv2 achieves state-of-the-art performance (78.2% AUC, 0.432 Spearman), while maintaining scalable, linear-time efficiency at inference. Notably, on unseen NeurIPS submissions, it further demonstrates strong generalization, with predicted scores increasing consistently across decision categories from Rejected to Oral. These findings establish NAIPv2 as a debiased and scalable framework for automated paper quality estimation, marking a step toward future scientific intelligence systems. Code and dataset are released at this http URL.

17 Sep 2025
InstanceVG introduces an instance-aware framework that jointly trains for Generalized Referring Expression Comprehension (GREC) and Segmentation (GRES) within a unified query-guided architecture. It achieves state-of-the-art performance across ten mainstream datasets for both traditional and generalized visual grounding tasks, demonstrating significant improvements over prior methods, such as a +12.2% rIoU on R-RefCOCOg for GRES and +11.4% F1score on gRefCOCO for GREC.

14 Sep 2025

Class-Incremental Unsupervised Domain Adaptation (CI-UDA) aims to adapt a model from a labeled source domain to an unlabeled target domain, where the sets of potential target classes appearing at different time steps are disjoint and are subsets of the source classes. The key to solving this problem lies in avoiding catastrophic forgetting of knowledge about previous target classes during continuously mitigating the domain shift. Most previous works cumbersomely combine two technical components. On one hand, they need to store and utilize rehearsal target sample from previous time steps to avoid catastrophic forgetting; on the other hand, they perform alignment only between classes shared across domains at each time step. Consequently, the memory will continuously increase and the asymmetric alignment may inevitably result in knowledge forgetting. In this paper, we propose to mine and preserve domain-invariant and class-agnostic knowledge to facilitate the CI-UDA task. Specifically, via using CLIP, we extract the class-agnostic properties which we name as "attribute". In our framework, we learn a "key-value" pair to represent an attribute, where the key corresponds to the visual prototype and the value is the textual prompt. We maintain two attribute dictionaries, each corresponding to a different domain. Then we perform attribute alignment across domains to mitigate the domain shift, via encouraging visual attention consistency and prediction consistency. Through attribute modeling and cross-domain alignment, we effectively reduce catastrophic knowledge forgetting while mitigating the domain shift, in a rehearsal-free way. Experiments on three CI-UDA benchmarks demonstrate that our method outperforms previous state-of-the-art methods and effectively alleviates catastrophic forgetting. Code is available at this https URL.

15 Aug 2025
VISUAL-RAG is a new benchmark and dataset designed to evaluate multimodal large language models' (MLLMs) capacity for text-to-image retrieval augmented generation (RAG) on queries requiring explicit visual evidence from retrieved images. Experiments on this benchmark show that current MLLMs and visual retrievers struggle with identifying fine-grained visual clues amidst distractors, with proprietary models exhibiting more robustness in noisy contexts than most open-source counterparts.
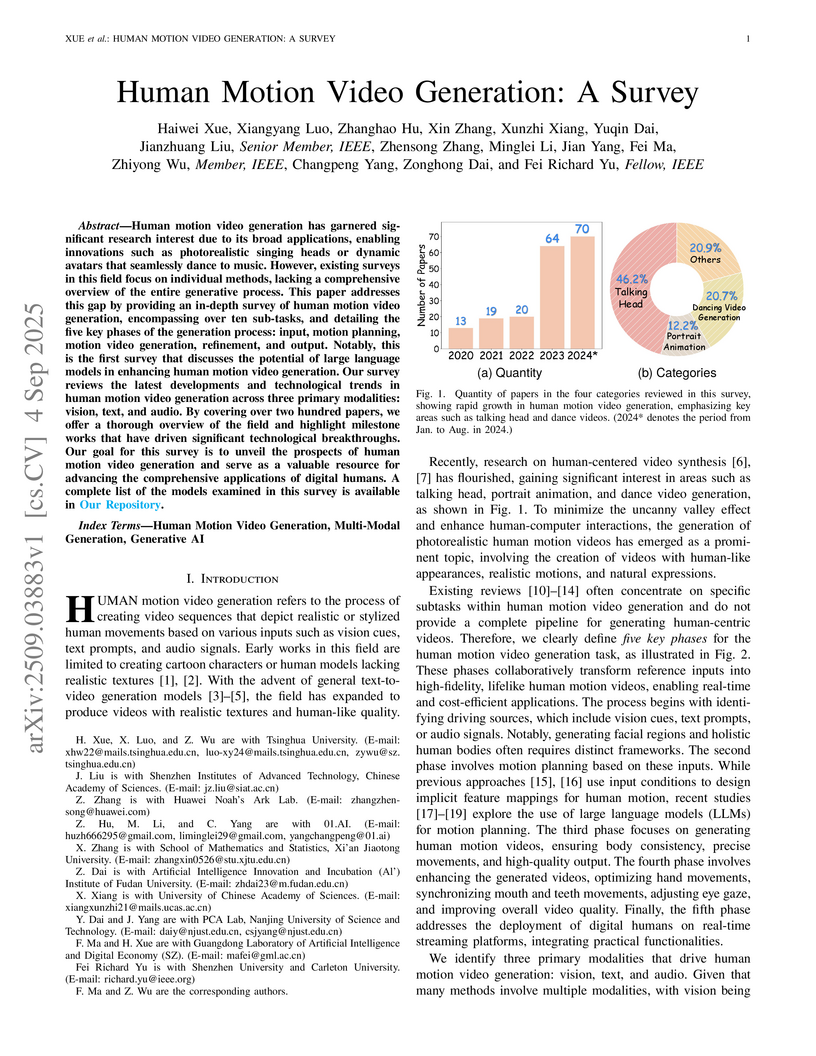
04 Sep 2025

This paper provides the first comprehensive, end-to-end survey of human motion video generation, introducing a novel five-phase pipeline and pioneering the discussion of Large Language Models (LLMs) for motion planning. It reviews over 200 papers, categorizes sub-tasks by input modality, and conducts a quantitative comparison of state-of-the-art methods.

06 Feb 2025
Diffusion models have achieved significant progress in image generation. The
pre-trained Stable Diffusion (SD) models are helpful for image deblurring by
providing clear image priors. However, directly using a blurry image or
pre-deblurred one as a conditional control for SD will either hinder accurate
structure extraction or make the results overly dependent on the deblurring
network. In this work, we propose a Latent Kernel Prediction Network (LKPN) to
achieve robust real-world image deblurring. Specifically, we co-train the LKPN
in latent space with conditional diffusion. The LKPN learns a spatially variant
kernel to guide the restoration of sharp images in the latent space. By
applying element-wise adaptive convolution (EAC), the learned kernel is
utilized to adaptively process the input feature, effectively preserving the
structural information of the input. This process thereby more effectively
guides the generative process of Stable Diffusion (SD), enhancing both the
deblurring efficacy and the quality of detail reconstruction. Moreover, the
results at each diffusion step are utilized to iteratively estimate the kernels
in LKPN to better restore the sharp latent by EAC. This iterative refinement
enhances the accuracy and robustness of the deblurring process. Extensive
experimental results demonstrate that the proposed method outperforms
state-of-the-art image deblurring methods on both benchmark and real-world
images.

20 Sep 2025
Structured information extraction from scientific literature is crucial for capturing core concepts and emerging trends in specialized fields. While existing datasets aid model development, most focus on specific publication sections due to domain complexity and the high cost of annotating scientific texts. To address this limitation, we introduce SciNLP--a specialized benchmark for full-text entity and relation extraction in the Natural Language Processing (NLP) domain. The dataset comprises 60 manually annotated full-text NLP publications, covering 7,072 entities and 1,826 relations. Compared to existing research, SciNLP is the first dataset providing full-text annotations of entities and their relationships in the NLP domain. To validate the effectiveness of SciNLP, we conducted comparative experiments with similar datasets and evaluated the performance of state-of-the-art supervised models on this dataset. Results reveal varying extraction capabilities of existing models across academic texts of different lengths. Cross-comparisons with existing datasets show that SciNLP achieves significant performance improvements on certain baseline models. Using models trained on SciNLP, we implemented automatic construction of a fine-grained knowledge graph for the NLP domain. Our KG has an average node degree of 3.2 per entity, indicating rich semantic topological information that enhances downstream applications. The dataset is publicly available at: this https URL.

01 Oct 2025

In this paper, we present IMAGEdit, a training-free framework for any number of video subject editing that manipulates the appearances of multiple designated subjects while preserving non-target regions, without finetuning or retraining. We achieve this by providing robust multimodal conditioning and precise mask sequences through a prompt-guided multimodal alignment module and a prior-based mask retargeting module. We first leverage large models' understanding and generation capabilities to produce multimodal information and mask motion sequences for multiple subjects across various types. Then, the obtained prior mask sequences are fed into a pretrained mask-driven video generation model to synthesize the edited video. With strong generalization capability, IMAGEdit remedies insufficient prompt-side multimodal conditioning and overcomes mask boundary entanglement in videos with any number of subjects, thereby significantly expanding the applicability of video editing. More importantly, IMAGEdit is compatible with any mask-driven video generation model, significantly improving overall performance. Extensive experiments on our newly constructed multi-subject benchmark MSVBench verify that IMAGEdit consistently surpasses state-of-the-art methods. Code, models, and datasets are publicly available at this https URL.

21 Oct 2025

Although autoregressive models have dominated language modeling in recent years, there has been a growing interest in exploring alternative paradigms to the conventional next-token prediction framework. Diffusion-based language models have emerged as a compelling alternative due to their powerful parallel generation capabilities and inherent editability. However, these models are often constrained by fixed-length generation. A promising direction is to combine the strengths of both paradigms, segmenting sequences into blocks, modeling autoregressive dependencies across blocks while leveraging discrete diffusion to estimate the conditional distribution within each block given the preceding context. Nevertheless, their practical application is often hindered by two key limitations: rigid fixed-length outputs and a lack of flexible control mechanisms. In this work, we address the critical limitations of fixed granularity and weak controllability in current large diffusion language models. We propose CtrlDiff, a dynamic and controllable semi-autoregressive framework that adaptively determines the size of each generation block based on local semantics using reinforcement learning. Furthermore, we introduce a classifier-guided control mechanism tailored to discrete diffusion, which significantly reduces computational overhead while facilitating efficient post-hoc conditioning without retraining. Extensive experiments demonstrate that CtrlDiff sets a new standard among hybrid diffusion models, narrows the performance gap to state-of-the-art autoregressive approaches, and enables effective conditional text generation across diverse tasks.

16 Oct 2025

Current 3D gaze estimation methods struggle to generalize across diverse data domains, primarily due to i) the scarcity of annotated datasets, and ii) the insufficient diversity of labeled data. In this work, we present OmniGaze, a semi-supervised framework for 3D gaze estimation, which utilizes large-scale unlabeled data collected from diverse and unconstrained real-world environments to mitigate domain bias and generalize gaze estimation in the wild. First, we build a diverse collection of unlabeled facial images, varying in facial appearances, background environments, illumination conditions, head poses, and eye occlusions. In order to leverage unlabeled data spanning a broader distribution, OmniGaze adopts a standard pseudo-labeling strategy and devises a reward model to assess the reliability of pseudo labels. Beyond pseudo labels as 3D direction vectors, the reward model also incorporates visual embeddings extracted by an off-the-shelf visual encoder and semantic cues from gaze perspective generated by prompting a Multimodal Large Language Model to compute confidence scores. Then, these scores are utilized to select high-quality pseudo labels and weight them for loss computation. Extensive experiments demonstrate that OmniGaze achieves state-of-the-art performance on five datasets under both in-domain and cross-domain settings. Furthermore, we also evaluate the efficacy of OmniGaze as a scalable data engine for gaze estimation, which exhibits robust zero-shot generalization on four unseen datasets.

27 Nov 2024
FaithDiff introduces a method for faithful image super-resolution by adaptively fine-tuning a latent diffusion model alongside a novel alignment module and encoder, ensuring both high perceptual quality and precise structural consistency in reconstructed images. The approach achieves state-of-the-art perceptual quality on synthetic and real-world datasets and significantly improves OCR recognition accuracy on super-resolved text while demonstrating superior inference efficiency.
There are no more papers matching your filters at the moment.
