
05 Aug 2024


Researchers from multiple institutions provide a comprehensive analysis of Vertical Federated Learning (VFL), establishing a general framework, identifying its distinct challenges, and evaluating solutions. The work empirically quantifies the trade-offs between privacy, communication efficiency, computational load distribution, and model performance in VFL systems.

07 Aug 2024

Researchers at the Australian National University and Data61 CSIRO developed a neuro-symbolic architecture that integrates Large Language Models with Automated Theorem Provers to significantly enhance logical reasoning accuracy. Their approach, featuring a novel Semantic Error Detection and Correction (SEDAC) algorithm, achieved up to 99.5% accuracy on the PRONTOQA benchmark by systematically identifying and automatically correcting translation errors from natural language to formal logic.
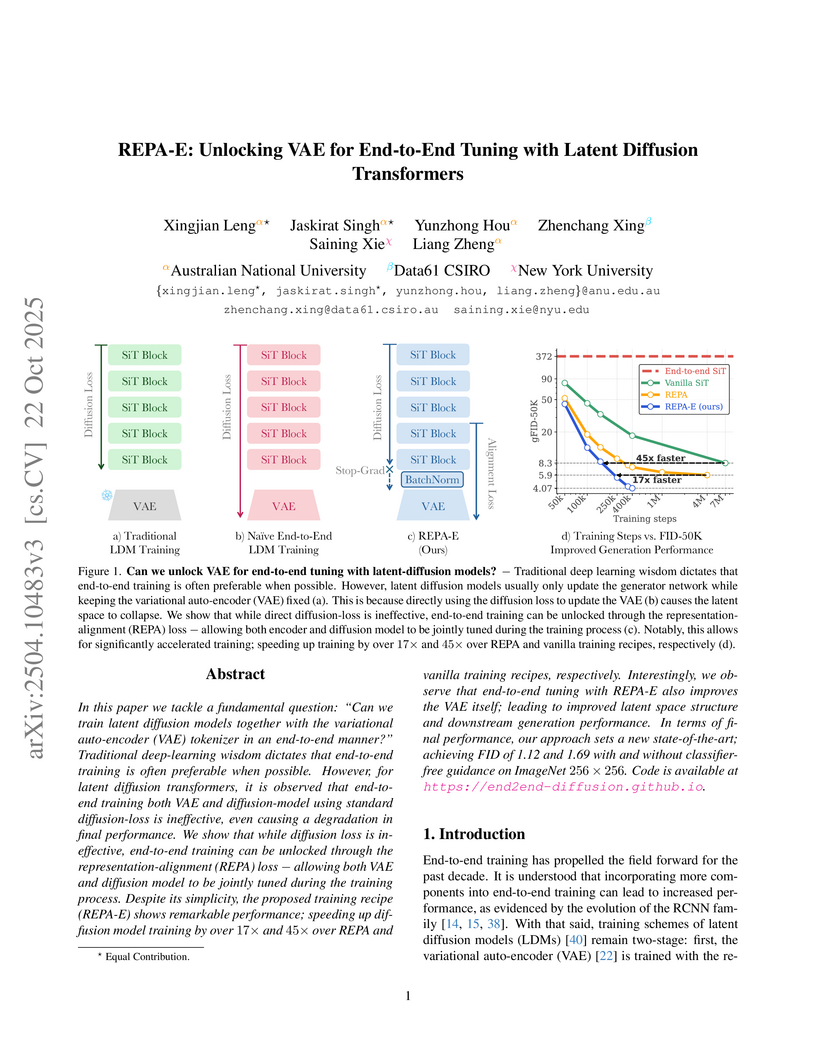
22 Oct 2025

The REPA-E framework enables stable end-to-end tuning of variational autoencoders (VAEs) and latent diffusion models (LDMs), leading to significantly faster training and state-of-the-art image generation quality on ImageNet 256x256 with an FID of 1.12.

06 Nov 2024
Data61, CSIRO researchers have compiled an AGENT DESIGN PATTERN CATALOGUE, presenting 18 architectural patterns to address challenges in designing Foundation Model-based agents. The catalogue, derived from systematic review and analysis of real-world implementations, offers reusable solutions for issues like reasoning uncertainty, underspecification, and explainability, aiming to provide systematic guidance for practitioners.

12 Mar 2025
The Paths-over-Graph (PoG) framework from UNSW and Data61, CSIRO enhances large language model reasoning by integrating faithful and interpretable knowledge graph paths. This approach achieves new state-of-the-art performance on KGQA benchmarks while significantly reducing LLM computational costs through dynamic path exploration, pruning, and summarization.

03 Oct 2025
StepChain GraphRAG, a framework developed by researchers from UTS, Data61/CSIRO, ECU, and UNSW, enhances multi-hop question answering by integrating iterative reasoning with dynamic knowledge graph construction. It achieved an average Exact Match of 57.67% and F1 score of 68.53% across three datasets, outperforming the previous state-of-the-art by an average of +2.57% EM and +2.13% F1.

30 Oct 2024
Researchers from Australian National University and Data61, CSIRO developed Semantic Embedding Uncertainty (SEU) and Amortised SEU (ASEU) to more accurately and efficiently quantify semantic uncertainty in Large Language Model outputs. SEU improves upon prior methods by using semantic embeddings and cosine similarity, while ASEU achieves single-pass uncertainty estimation by fine-tuning LLMs to predict semantic uncertainty from internal representations.

19 Sep 2025
Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating external knowledge. Current hybrid RAG system retrieves evidence from both knowledge graphs (KGs) and text documents to support LLM reasoning. However, it faces challenges like handling multi-hop reasoning, multi-entity questions, multi-source verification, and effective graph utilization. To address these limitations, we present HydraRAG, a training-free framework that unifies graph topology, document semantics, and source reliability to support deep, faithful reasoning in LLMs. HydraRAG handles multi-hop and multi-entity problems through agent-driven exploration that combines structured and unstructured retrieval, increasing both diversity and precision of evidence. To tackle multi-source verification, HydraRAG uses a tri-factor cross-source verification (source trustworthiness assessment, cross-source corroboration, and entity-path alignment), to balance topic relevance with cross-modal agreement. By leveraging graph structure, HydraRAG fuses heterogeneous sources, guides efficient exploration, and prunes noise early. Comprehensive experiments on seven benchmark datasets show that HydraRAG achieves overall state-of-the-art results on all benchmarks with GPT-3.5-Turbo, outperforming the strong hybrid baseline ToG-2 by an average of 20.3% and up to 30.1%. Furthermore, HydraRAG enables smaller models (e.g., Llama-3.1-8B) to achieve reasoning performance comparable to that of GPT-4-Turbo. The source code is available on this https URL.

18 Jun 2024

A method called LACR enhances causal graph discovery by combining Large Language Models with Retrieval-Augmented Generation, and revealed that common benchmark datasets for causal inference are outdated based on current scientific literature.

27 Sep 2025







Object detection has advanced significantly in the closed-set setting, but real-world deployment remains limited by two challenges: poor generalization to unseen categories and insufficient robustness under adverse conditions. Prior research has explored these issues separately: visible-infrared detection improves robustness but lacks generalization, while open-world detection leverages vision-language alignment strategy for category diversity but struggles under extreme environments. This trade-off leaves robustness and diversity difficult to achieve simultaneously. To mitigate these issues, we propose \textbf{C3-OWD}, a curriculum cross-modal contrastive learning framework that unifies both strengths. Stage~1 enhances robustness by pretraining with RGBT data, while Stage~2 improves generalization via vision-language alignment. To prevent catastrophic forgetting between two stages, we introduce an Exponential Moving Average (EMA) mechanism that theoretically guarantees preservation of pre-stage performance with bounded parameter lag and function consistency. Experiments on FLIR, OV-COCO, and OV-LVIS demonstrate the effectiveness of our approach: C3-OWD achieves AP on FLIR, AP on OV-COCO, and mAP on OV-LVIS, establishing competitive performance across both robustness and diversity evaluations. Code available at: this https URL.

18 Oct 2025
Quantum machine learning (QML) has emerged as a promising area of research for enhancing the performance of classical machine learning systems by leveraging quantum computational principles. However, practical deployment of QML remains limited due to current hardware constraints such as limited number of qubits and quantum noise. This chapter introduces a hybrid quantum-classical architecture that combines the advantages of quantum computing with transfer learning techniques to address high-resolution image classification. Specifically, we propose a Quantum Transfer Learning (QTL) model that integrates classical convolutional feature extraction with quantum variational circuits. Through extensive simulations on diverse datasets including Ants \& Bees, CIFAR-10, and Road Sign Detection, we demonstrate that QTL achieves superior classification performance compared to both conventional and quantum models trained without transfer learning. Additionally, we also investigate the model's vulnerability to adversarial attacks and demonstrate that incorporating adversarial training significantly boosts the robustness of QTL, enhancing its potential for deployment in security sensitive applications.

14 Oct 2025
Knowledge Hypergraphs (KHs) have recently emerged as a knowledge representation for retrieval-augmented generation (RAG), offering a paradigm to model multi-entity relations into a structured form. However, existing KH-based RAG methods suffer from three major limitations: static retrieval planning, non-adaptive retrieval execution, and superficial use of KH structure and semantics, which constrain their ability to perform effective multi-hop question answering. To overcome these limitations, we propose PRoH, a dynamic Planning and Reasoning over Knowledge Hypergraphs framework. PRoH incorporates three core innovations: (i) a context-aware planning module that sketches the local KH neighborhood to guide structurally grounded reasoning plan generation; (ii) a structured question decomposition process that organizes subquestions as a dynamically evolving Directed Acyclic Graph (DAG) to enable adaptive, multi-trajectory exploration; and (iii) an Entity-Weighted Overlap (EWO)-guided reasoning path retrieval algorithm that prioritizes semantically coherent hyperedge traversals. Experiments across multiple domains demonstrate that PRoH achieves state-of-the-art performance, surpassing the prior SOTA model HyperGraphRAG by an average of 19.73% in F1 and 8.41% in Generation Evaluation (G-E) score, while maintaining strong robustness in long-range multi-hop reasoning tasks.

02 Mar 2023
We propose the Factorized Fourier Neural Operator (F-FNO), a learning-based
approach for simulating partial differential equations (PDEs). Starting from a
recently proposed Fourier representation of flow fields, the F-FNO bridges the
performance gap between pure machine learning approaches to that of the best
numerical or hybrid solvers. This is achieved with new representations -
separable spectral layers and improved residual connections - and a combination
of training strategies such as the Markov assumption, Gaussian noise, and
cosine learning rate decay. On several challenging benchmark PDEs on regular
grids, structured meshes, and point clouds, the F-FNO can scale to deeper
networks and outperform both the FNO and the geo-FNO, reducing the error by 83%
on the Navier-Stokes problem, 31% on the elasticity problem, 57% on the airfoil
flow problem, and 60% on the plastic forging problem. Compared to the
state-of-the-art pseudo-spectral method, the F-FNO can take a step size that is
an order of magnitude larger in time and achieve an order of magnitude speedup
to produce the same solution quality.

24 Mar 2022

A self-supervised photometric stereo framework effectively recovers 3D object shape and spatially-varying surface materials, explicitly addressing non-Lambertian reflectance and self-shadows using neural implicit representations. It attains an average Mean Angular Error of 6.50 degrees on the DiLiGenT dataset, outperforming prior self-supervised methods and matching some supervised approaches, with significantly reduced inference time.

02 Jun 2025
RePaViT introduces a structural reparameterization method for the Feedforward Network (FFN) layers of Vision Transformers, utilizing a channel idle mechanism to create linear pathways that bypass non-linearity. This approach significantly reduces inference latency, achieving up to a 68.7% speed-up, and for larger models like ViT-Large and ViT-Huge, it concurrently improves top-1 accuracy by over 1%.

24 Jul 2023
The popularity of online social networks has enabled rapid dissemination of information. People now can share and consume information much more rapidly than ever before. However, low-quality and/or accidentally/deliberately fake information can also spread rapidly. This can lead to considerable and negative impacts on society. Identifying, labelling and debunking online misinformation as early as possible has become an increasingly urgent problem. Many methods have been proposed to detect fake news including many deep learning and graph-based approaches. In recent years, graph-based methods have yielded strong results, as they can closely model the social context and propagation process of online news. In this paper, we present a systematic review of fake news detection studies based on graph-based and deep learning-based techniques. We classify existing graph-based methods into knowledge-driven methods, propagation-based methods, and heterogeneous social context-based methods, depending on how a graph structure is constructed to model news related information flows. We further discuss the challenges and open problems in graph-based fake news detection and identify future research directions.

26 Jan 2024

The aspiration of the next generation's autonomous driving (AD) technology relies on the dedicated integration and interaction among intelligent perception, prediction, planning, and low-level control. There has been a huge bottleneck regarding the upper bound of autonomous driving algorithm performance, a consensus from academia and industry believes that the key to surmount the bottleneck lies in data-centric autonomous driving technology. Recent advancement in AD simulation, closed-loop model training, and AD big data engine have gained some valuable experience. However, there is a lack of systematic knowledge and deep understanding regarding how to build efficient data-centric AD technology for AD algorithm self-evolution and better AD big data accumulation. To fill in the identified research gaps, this article will closely focus on reviewing the state-of-the-art data-driven autonomous driving technologies, with an emphasis on the comprehensive taxonomy of autonomous driving datasets characterized by milestone generations, key features, data acquisition settings, etc. Furthermore, we provide a systematic review of the existing benchmark closed-loop AD big data pipelines from the industrial frontier, including the procedure of closed-loop frameworks, key technologies, and empirical studies. Finally, the future directions, potential applications, limitations and concerns are discussed to arouse efforts from both academia and industry for promoting the further development of autonomous driving. The project repository is available at: this https URL.

07 Oct 2025

ATOM introduces a pretrained transformer neural operator for multitask molecular dynamics, demonstrating zero-shot generalization to unseen molecules and timescales. The model achieves state-of-the-art performance on MD17 and MD22 benchmarks, outperforming existing baselines by up to 97.30% in S2S MSE on larger molecules and nearly halving the S2T MSE of EGNO in out-of-domain generalization on the new TG80 dataset.

15 Oct 2025
MemoTime, a memory-augmented framework developed by researchers from UNSW and Data61/CSIRO, enhances Large Language Models' temporal reasoning by integrating them with Temporal Knowledge Graphs. The framework achieved state-of-the-art Hits@1 accuracy on the MultiTQ dataset at 77.9% (a 24.0% improvement over TempAgent) and on the TimeQuestions dataset at 71.4% overall, demonstrating improved temporal faithfulness and adaptability across various LLM backbones.

14 Oct 2024
This paper resolves the expressivity-generalization paradox in Graph Neural Networks by proposing a theoretical framework that connects generalization to the variance in graph structures. It reveals that increased expressivity can improve or worsen generalization depending on whether it primarily enhances inter-class separation or increases intra-class variance.
There are no more papers matching your filters at the moment.
