
21 Nov 2025
Researchers developed the Latent Upscale Adapter (LUA), a lightweight, single-pass module that upscales latent representations from diffusion models, enabling high-resolution image generation up to 4K. LUA demonstrates superior speed and competitive image fidelity compared to existing pixel-space super-resolution and multi-stage latent re-diffusion methods, with robust generalization across various VAEs.

26 Oct 2023

Researchers from Yandex, MIPT, and HSE conducted a rigorous evaluation of deep learning architectures for tabular data, introducing a ResNet-like baseline and the FT-Transformer. Their work clarifies that while the FT-Transformer achieves state-of-the-art deep learning performance and excels on certain datasets, Gradient Boosted Decision Trees retain superiority on others, underscoring that no single model universally outperforms.

19 Sep 2019
The paper introduces Neural Oblivious Decision Ensembles (NODE), a deep learning architecture that integrates differentiable oblivious decision trees to achieve state-of-the-art performance on tabular datasets, consistently outperforming traditional Gradient Boosting Decision Trees (GBDTs). This framework from Yandex researchers aims to bridge the performance gap between deep learning and classical methods for tabular data.

28 Oct 2020



Generative models are becoming a tool of choice for exploring the molecular space. These models learn on a large training dataset and produce novel molecular structures with similar properties. Generated structures can be utilized for virtual screening or training semi-supervised predictive models in the downstream tasks. While there are plenty of generative models, it is unclear how to compare and rank them. In this work, we introduce a benchmarking platform called Molecular Sets (MOSES) to standardize training and comparison of molecular generative models. MOSES provides a training and testing datasets, and a set of metrics to evaluate the quality and diversity of generated structures. We have implemented and compared several molecular generation models and suggest to use our results as reference points for further advancements in generative chemistry research. The platform and source code are available at this https URL.

25 Sep 2025
In this paper, we establish novel concentration inequalities for additive functionals of geometrically ergodic Markov chains similar to Rosenthal inequalities for sums of independent random variables. We pay special attention to the dependence of our bounds on the mixing time of the corresponding chain. Precisely, we establish explicit bounds that are linked to the constants from the martingale version of the Rosenthal inequality, as well as the constants that characterize the mixing properties of the underlying Markov kernel. Finally, our proof technique is, up to our knowledge, new and is based on a recurrent application of the Poisson decomposition.

16 Mar 2022
Yandex Research developed a method leveraging Denoising Diffusion Probabilistic Models (DDPMs) to extract effective pixel-level representations for label-efficient semantic segmentation. The approach demonstrated superior performance over GAN-based and self-supervised learning baselines across various datasets, including LSUN and FFHQ.

31 Dec 2019

Researchers developed SWA-Gaussian (SWAG), a method extending Stochastic Weight Averaging to efficiently estimate a Gaussian approximate posterior over deep neural network weights by capturing the mean and variance of SGD iterates. This approach provides superior predictive uncertainty and calibration across image classification, language modeling, and regression tasks, often outperforming or matching complex baselines with minimal additional computational cost.

25 Jun 2023
The number of proposed recommender algorithms continues to grow. The authors propose new approaches and compare them with existing models, called baselines. Due to the large number of recommender models, it is difficult to estimate which algorithms to choose in the article. To solve this problem, we have collected and published a dataset containing information about the recommender models used in 903 papers, both as baselines and as proposed approaches. This dataset can be seen as a typical dataset with interactions between papers and previously proposed models. In addition, we provide a descriptive analysis of the dataset and highlight possible challenges to be investigated with the data. Furthermore, we have conducted extensive experiments using a well-established methodology to build a good recommender algorithm under the dataset. Our experiments show that the selection of the best baselines for proposing new recommender approaches can be considered and successfully solved by existing state-of-the-art collaborative filtering models. Finally, we discuss limitations and future work.

31 Oct 2022

In this paper, we present the first stepsize schedule for Newton method resulting in fast global and local convergence guarantees. In particular, a) we prove an global rate, which matches the state-of-the-art global rate of cubically regularized Newton method of Polyak and Nesterov (2006) and of regularized Newton method of Mishchenko (2021) and Doikov and Nesterov (2021), b) we prove a local quadratic rate, which matches the best-known local rate of second-order methods, and c) our stepsize formula is simple, explicit, and does not require solving any subproblem. Our convergence proofs hold under affine-invariance assumptions closely related to the notion of self-concordance. Finally, our method has competitive performance when compared to existing baselines, which share the same fast global convergence guarantees.

01 Nov 2024
The decoy-state method is a prominent approach to enhance the performance of quantum key distribution (QKD) systems that operate with weak coherent laser sources. Due to the limited transmissivity of single photons in optical fiber, current experimental decoy-state QKD setups increase their secret key rate by raising the repetition rate of the transmitter. However, this usually leads to correlations between subsequent optical pulses. This phenomenon leaks information about the encoding settings, including the intensities of the generated signals, which invalidates a basic premise of decoy-state QKD. Here we characterize intensity correlations between the emitted optical pulses in two industrial prototypes of decoy-state BB84 QKD systems and show that they significantly reduce the asymptotic key rate. In contrast to what has been conjectured, we experimentally confirm that the impact of higher-order correlations on the intensity of the generated signals can be much higher than that of nearest-neighbour correlations.

12 May 2019

In this paper, a new variant of accelerated gradient descent is proposed. The
pro-posed method does not require any information about the objective function,
usesexact line search for the practical accelerations of convergence, converges
accordingto the well-known lower bounds for both convex and non-convex
objective functions,possesses primal-dual properties and can be applied in the
non-euclidian set-up. Asfar as we know this is the rst such method possessing
all of the above properties atthe same time. We also present a universal
version of the method which is applicableto non-smooth problems. We demonstrate
how in practice one can efficiently use thecombination of line-search and
primal-duality by considering a convex optimizationproblem with a simple
structure (for example, linearly constrained).

01 Nov 2023


We propose a novel neural algorithm for the fundamental problem of computing the entropic optimal transport (EOT) plan between continuous probability distributions which are accessible by samples. Our algorithm is based on the saddle point reformulation of the dynamic version of EOT which is known as the Schrödinger Bridge problem. In contrast to the prior methods for large-scale EOT, our algorithm is end-to-end and consists of a single learning step, has fast inference procedure, and allows handling small values of the entropy regularization coefficient which is of particular importance in some applied problems. Empirically, we show the performance of the method on several large-scale EOT tasks. this https URL
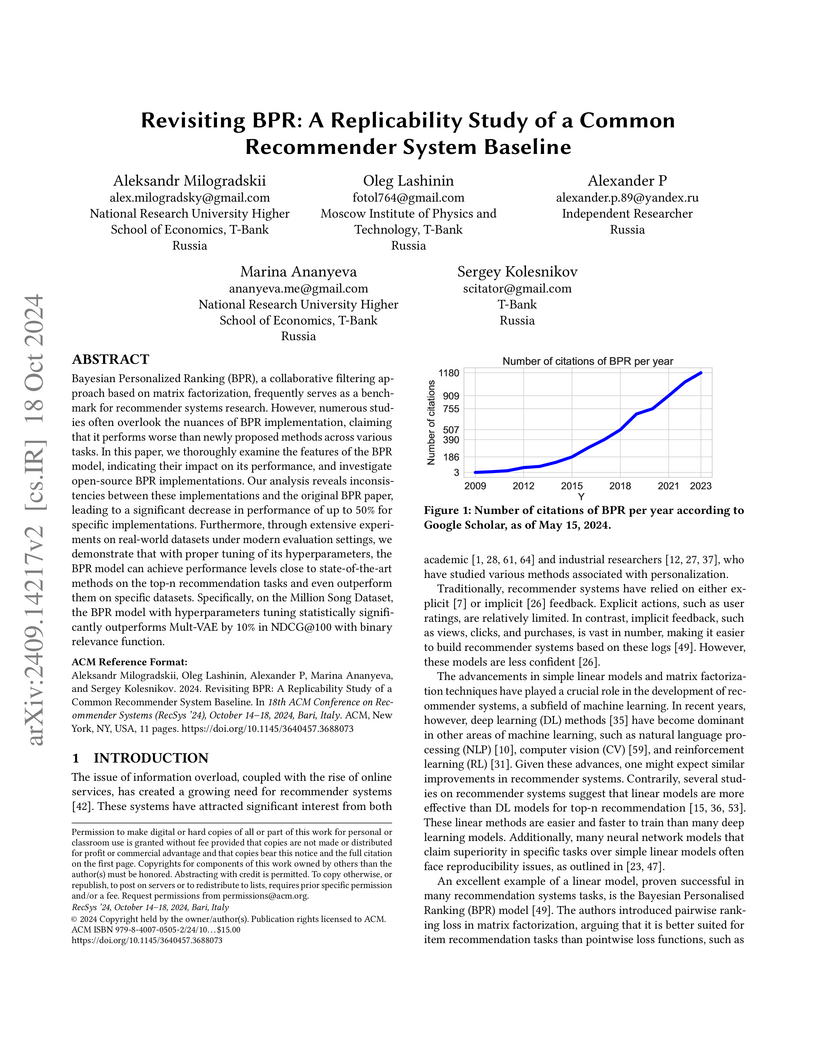
18 Oct 2024
Bayesian Personalized Ranking (BPR), a collaborative filtering approach based on matrix factorization, frequently serves as a benchmark for recommender systems research. However, numerous studies often overlook the nuances of BPR implementation, claiming that it performs worse than newly proposed methods across various tasks. In this paper, we thoroughly examine the features of the BPR model, indicating their impact on its performance, and investigate open-source BPR implementations. Our analysis reveals inconsistencies between these implementations and the original BPR paper, leading to a significant decrease in performance of up to 50% for specific implementations. Furthermore, through extensive experiments on real-world datasets under modern evaluation settings, we demonstrate that with proper tuning of its hyperparameters, the BPR model can achieve performance levels close to state-of-the-art methods on the top-n recommendation tasks and even outperform them on specific datasets. Specifically, on the Million Song Dataset, the BPR model with hyperparameters tuning statistically significantly outperforms Mult-VAE by 10% in NDCG@100 with binary relevance function.

05 Apr 2023
In social choice there often arises a conflict between the majority principle (the search for a candidate that is as good as possible for as many voters as possible), and the protection of minority rights (choosing a candidate that is not overly bad for particular individuals or groups). In a context where the latter is our main concern, veto-based rules -- giving individuals or groups the ability to strike off certain candidates from the list -- are a natural and effective way of ensuring that no minority is left with an outcome they find untenable. However, such rules often fail to be anonymous, or impose specific restrictions on the number of voters and candidates. These issues can be addressed by considering the proportional veto core -- the solution to a cooperative game where every coalition is given the power to veto a number of candidates proportional to its size. However, the naïve algorithm for the veto core is exponential, and the only known rule for selecting from the core, with an arbitrary number of voters, fails anonymity. In this paper we present a polynomial time algorithm for computing the core, study its expected size, and present an anonymous rule for selecting a candidate from it. We study the properties of core-consistent voting rules. Finally, we show that a pessimist can manipulate the core in polynomial time, while an optimist cannot manipulate it at all.

23 Jun 2025
Quantum key distribution systems offer cryptographic security, provided that all their components are thoroughly characterised. However, certain components might be vulnerable to a laser-damage attack, particularly when attacked at previously untested laser parameters. Here we show that exposing 1550-nm fiber-optic isolators to 17-mW average power, 1061-nm picosecond attacking pulses reduces their isolation below a safe threshold. Furthermore, the exposure to 1160-mW sub-nanosecond pulsed illumination permanently degrades isolation at 1550 nm while the isolators maintain forward transparency. These threats are not addressed by the currently-practiced security analysis.

21 Feb 2025
The human structural connectome has a complex internal community
organization, characterized by a high degree of overlap and related to
functional and cognitive phenomena. We explored connectivity properties in
connectome networks and showed that -clique percolation of an anomalously
high order is characteristic of the human structural connectome. The resulting
structural organization maintains a high local density of connectivity
distributed throughout the connectome while preserving the overall sparsity of
the network. To analyze these findings, we proposed a novel model for the
emergence of high-order clique percolation during network formation with a
phase transition dynamic under constraints on connection length. Investigating
the structural basis of functional brain subnetworks, we identified a direct
relationship between their interaction and the formation of clique clusters
within their structural connections. Based on these findings, we hypothesize
that the percolating clique cluster serves as a distributed boundary between
interacting functional subnetworks, showing the complex, complementary nature
of their structural connections. We also examined the difference between
individual-specific and common structural connections and found that the latter
plays a sustaining role in the connectivity of structural communities. At the
same time, the superiority of individual connections, in contrast to common
ones, creates variability in the interaction of functional brain subnetworks.

01 May 2020

Researchers from Yandex, MIPT, HSE, University of Edinburgh, and University of Amsterdam developed BPE-dropout, a straightforward subword regularization method that injects stochasticity into Byte Pair Encoding segmentation during NMT training. This approach consistently yields 0.5 to 2.3 BLEU point improvements on various translation tasks and notably enhances model robustness against misspelled input by 1.6 to 2.3 BLEU points, without affecting inference time.

15 Sep 2022
Safe navigation in uneven terrains is an important problem in robotic
research. In this paper we propose a 2.5D navigation system which consists of
elevation map building, path planning and local path following with obstacle
avoidance. For local path following we use Model Predictive Path Integral
(MPPI) control method. We propose novel cost-functions for MPPI in order to
adapt it to elevation maps and motion through unevenness. We evaluate our
system on multiple synthetic tests and in a simulated environment with
different types of obstacles and rough surfaces.

18 Jul 2021
Uncertainty estimation and ensembling methods go hand-in-hand. Uncertainty estimation is one of the main benchmarks for assessment of ensembling performance. At the same time, deep learning ensembles have provided state-of-the-art results in uncertainty estimation. In this work, we focus on in-domain uncertainty for image classification. We explore the standards for its quantification and point out pitfalls of existing metrics. Avoiding these pitfalls, we perform a broad study of different ensembling techniques. To provide more insight in this study, we introduce the deep ensemble equivalent score (DEE) and show that many sophisticated ensembling techniques are equivalent to an ensemble of only few independently trained networks in terms of test performance.

20 Dec 2024
Researchers from Moscow Institute of Physics and Technology, HSE, and T-Bank developed SAFERec, a self-attention and frequency-enriched model for Next Basket Recommendation. This model integrates item frequency information into a Transformer architecture, leading to improved recommendation accuracy, including up to an 8% increase in Recall@10, and an enhanced ability to recommend novel items for entire purchase baskets.
There are no more papers matching your filters at the moment.
