
30 Mar 2024


Researchers at Zhejiang University developed Tram, a token-level retrieval-augmented mechanism that guides the decoder's generation of source code summaries by incorporating external knowledge. This approach established new state-of-the-art BLEU scores on four public benchmarks, including a 1.39 point improvement on Java and 1.53 points on Python, while also enhancing the generation of low-frequency, domain-specific terms.

06 Aug 2025
Pinterest's PinRec, a generative retrieval system, integrates outcome-conditioned and multi-token generation into a causal transformer architecture, successfully boosting user engagement metrics by up to 4.01% in Homefeed grid clicks and improving corpus coverage by up to 17.3% across its web-scale platform.

20 Aug 2025
Pinterest researchers developed PinFM, a 20B+ parameter foundation model for understanding user activity sequences across various applications on its visual discovery platform. This model, optimized for efficiency, achieved online lifts in sitewide saves by +1.20% and surface saves by +2.60% for Home Feed ranking.

31 May 2023
Sequential models that encode user activity for next action prediction have become a popular design choice for building web-scale personalized recommendation systems. Traditional methods of sequential recommendation either utilize end-to-end learning on realtime user actions, or learn user representations separately in an offline batch-generated manner. This paper (1) presents Pinterest's ranking architecture for Homefeed, our personalized recommendation product and the largest engagement surface; (2) proposes TransAct, a sequential model that extracts users' short-term preferences from their realtime activities; (3) describes our hybrid approach to ranking, which combines end-to-end sequential modeling via TransAct with batch-generated user embeddings. The hybrid approach allows us to combine the advantages of responsiveness from learning directly on realtime user activity with the cost-effectiveness of batch user representations learned over a longer time period. We describe the results of ablation studies, the challenges we faced during productionization, and the outcome of an online A/B experiment, which validates the effectiveness of our hybrid ranking model. We further demonstrate the effectiveness of TransAct on other surfaces such as contextual recommendations and search. Our model has been deployed to production in Homefeed, Related Pins, Notifications, and Search at Pinterest.

09 May 2022

Pinterest and Stanford University researchers developed PinnerFormer, a Transformer-based model for user representation learning in large-scale recommender systems. It uses a novel dense all-action loss to capture multi-day user engagement patterns, enabling efficient batch computation of user embeddings for improved content personalization.

02 Jun 2025
Pinterest researchers develop TransAct V2, a transformer-based recommender system that effectively models lifelong user action sequences containing O(10^4) items (compared to typical O(10^2) limitations) by combining nearest neighbor search for sequence selection with a Next Action Loss auxiliary task, achieving +13.31% improvement in positive engagement prediction and -11.25% reduction in negative engagement on offline metrics, while online A/B tests show +6.35% increase in Homefeed Repin Volume and -12.80% reduction in Hide Volume through novel serving optimizations including Single Kernel Unified Transformer (SKUT) that reduces inference latency by up to 85% and request-level de-duplication that cuts CPU-to-GPU transfer time by over 80%, enabling practical deployment of truly long-term user behavior modeling in production environments serving billions of recommendations.

12 Jun 2025
Researchers at Pinterest developed OmniSage, a large-scale framework that unifies heterogeneous graph, user sequence, and content signals to learn universal entity representations. This approach led to an approximate 2.5% increase in sitewide repins across five Pinterest applications.

15 Jul 2024


Tabular data is one of the most commonly used types of data in machine
learning. Despite recent advances in neural nets (NNs) for tabular data, there
is still an active discussion on whether or not NNs generally outperform
gradient-boosted decision trees (GBDTs) on tabular data, with several recent
works arguing either that GBDTs consistently outperform NNs on tabular data, or
vice versa. In this work, we take a step back and question the importance of
this debate. To this end, we conduct the largest tabular data analysis to date,
comparing 19 algorithms across 176 datasets, and we find that the 'NN vs. GBDT'
debate is overemphasized: for a surprisingly high number of datasets, either
the performance difference between GBDTs and NNs is negligible, or light
hyperparameter tuning on a GBDT is more important than choosing between NNs and
GBDTs. A remarkable exception is the recently-proposed prior-data fitted
network, TabPFN: although it is effectively limited to training sets of size
3000, we find that it outperforms all other algorithms on average, even when
randomly sampling 3000 training datapoints. Next, we analyze dozens of
metafeatures to determine what properties of a dataset make NNs or GBDTs
better-suited to perform well. For example, we find that GBDTs are much better
than NNs at handling skewed or heavy-tailed feature distributions and other
forms of dataset irregularities. Our insights act as a guide for practitioners
to determine which techniques may work best on their dataset. Finally, with the
goal of accelerating tabular data research, we release the TabZilla Benchmark
Suite: a collection of the 36 'hardest' of the datasets we study. Our benchmark
suite, codebase, and all raw results are available at
this https URL

11 Nov 2025
Relevance evaluation plays a crucial role in personalized search systems to ensure that search results align with a user's queries and intent. While human annotation is the traditional method for relevance evaluation, its high cost and long turnaround time limit its scalability. In this work, we present our approach at Pinterest Search to automate relevance evaluation for online experiments using fine-tuned LLMs. We rigorously validate the alignment between LLM-generated judgments and human annotations, demonstrating that LLMs can provide reliable relevance measurement for experiments while greatly improving the evaluation efficiency. Leveraging LLM-based labeling further unlocks the opportunities to expand the query set, optimize sampling design, and efficiently assess a wider range of search experiences at scale. This approach leads to higher-quality relevance metrics and significantly reduces the Minimum Detectable Effect (MDE) in online experiment measurements.

25 Apr 2024
Pinterest's OmniSearchSage system unifies an embedding framework across user queries, pins, and products using a multi-task learning approach. This system led to over 8% improvement in search relevance, over 7% increase in user engagement, and over 5% improvement in ad click-through rates across Pinterest's search platform.

22 Oct 2024
Pinterest enhanced its search relevance by developing an LLM-based system that leverages knowledge distillation to train a smaller, production-ready model for real-time search. This approach, which also incorporates enriched Pin representations, resulted in improved search feed relevance and increased user engagement across its global platform.

29 Jun 2025
Synergizing Implicit and Explicit User Interests: A Multi-Embedding Retrieval Framework at Pinterest
Synergizing Implicit and Explicit User Interests: A Multi-Embedding Retrieval Framework at Pinterest
Industrial recommendation systems are typically composed of multiple stages, including retrieval, ranking, and blending. The retrieval stage plays a critical role in generating a high-recall set of candidate items that covers a wide range of diverse user interests. Effectively covering the diverse and long-tail user interests within this stage poses a significant challenge: traditional two-tower models struggle in this regard due to limited user-item feature interaction and often bias towards top use cases. To address these issues, we propose a novel multi-embedding retrieval framework designed to enhance user interest representation by generating multiple user embeddings conditioned on both implicit and explicit user interests. Implicit interests are captured from user history through a Differentiable Clustering Module (DCM), whereas explicit interests, such as topics that the user has followed, are modeled via Conditional Retrieval (CR). These methodologies represent a form of conditioned user representation learning that involves condition representation construction and associating the target item with the relevant conditions. Synergizing implicit and explicit user interests serves as a complementary approach to achieve more effective and comprehensive candidate retrieval as they benefit on different user segments and extract conditions from different but supplementary sources. Extensive experiments and A/B testing reveal significant improvements in user engagements and feed diversity metrics. Our proposed framework has been successfully deployed on Pinterest home feed.

29 Jan 2023


It has been observed in practice that applying pruning-at-initialization methods to neural networks and training the sparsified networks can not only retain the testing performance of the original dense models, but also sometimes even slightly boost the generalization performance. Theoretical understanding for such experimental observations are yet to be developed. This work makes the first attempt to study how different pruning fractions affect the model's gradient descent dynamics and generalization. Specifically, this work considers a classification task for overparameterized two-layer neural networks, where the network is randomly pruned according to different rates at the initialization. It is shown that as long as the pruning fraction is below a certain threshold, gradient descent can drive the training loss toward zero and the network exhibits good generalization performance. More surprisingly, the generalization bound gets better as the pruning fraction gets larger. To complement this positive result, this work further shows a negative result: there exists a large pruning fraction such that while gradient descent is still able to drive the training loss toward zero (by memorizing noise), the generalization performance is no better than random guessing. This further suggests that pruning can change the feature learning process, which leads to the performance drop of the pruned neural network.

24 May 2022
Pinterest developed ItemSage, a system that learns unified product embeddings by fusing multi-modal information through a transformer architecture. This approach, optimized via multi-task learning, increased gross merchandise value per user by up to 7% and click volume by 11% across various shopping surfaces.

17 Feb 2025



This paper presents AI Guide Dog (AIGD), a lightweight egocentric
(first-person) navigation system for visually impaired users, designed for
real-time deployment on smartphones. AIGD employs a vision-only multi-label
classification approach to predict directional commands, ensuring safe
navigation across diverse environments. We introduce a novel technique for
goal-based outdoor navigation by integrating GPS signals and high-level
directions, while also handling uncertain multi-path predictions for
destination-free indoor navigation. As the first navigation assistance system
to handle both goal-oriented and exploratory navigation across indoor and
outdoor settings, AIGD establishes a new benchmark in blind navigation. We
present methods, datasets, evaluations, and deployment insights to encourage
further innovations in assistive navigation systems.

11 Aug 2025
Large embedding tables are indispensable in modern recommendation systems, thanks to their ability to effectively capture and memorize intricate details of interactions among diverse entities. As we explore integrating large embedding tables into Pinterest's ads ranking models, we encountered not only common challenges such as sparsity and scalability, but also several obstacles unique to our context. Notably, our initial attempts to train large embedding tables from scratch resulted in neutral metrics. To tackle this, we introduced a novel multi-faceted pretraining scheme that incorporates multiple pretraining algorithms. This approach greatly enriched the embedding tables and resulted in significant performance improvements. As a result, the multi-faceted large embedding tables bring great performance gain on both the Click-Through Rate (CTR) and Conversion Rate (CVR) domains. Moreover, we designed a CPU-GPU hybrid serving infrastructure to overcome GPU memory limits and elevate the scalability. This framework has been deployed in the Pinterest Ads system and achieved 1.34% online CPC reduction and 2.60% CTR increase with neutral end-to-end latency change.
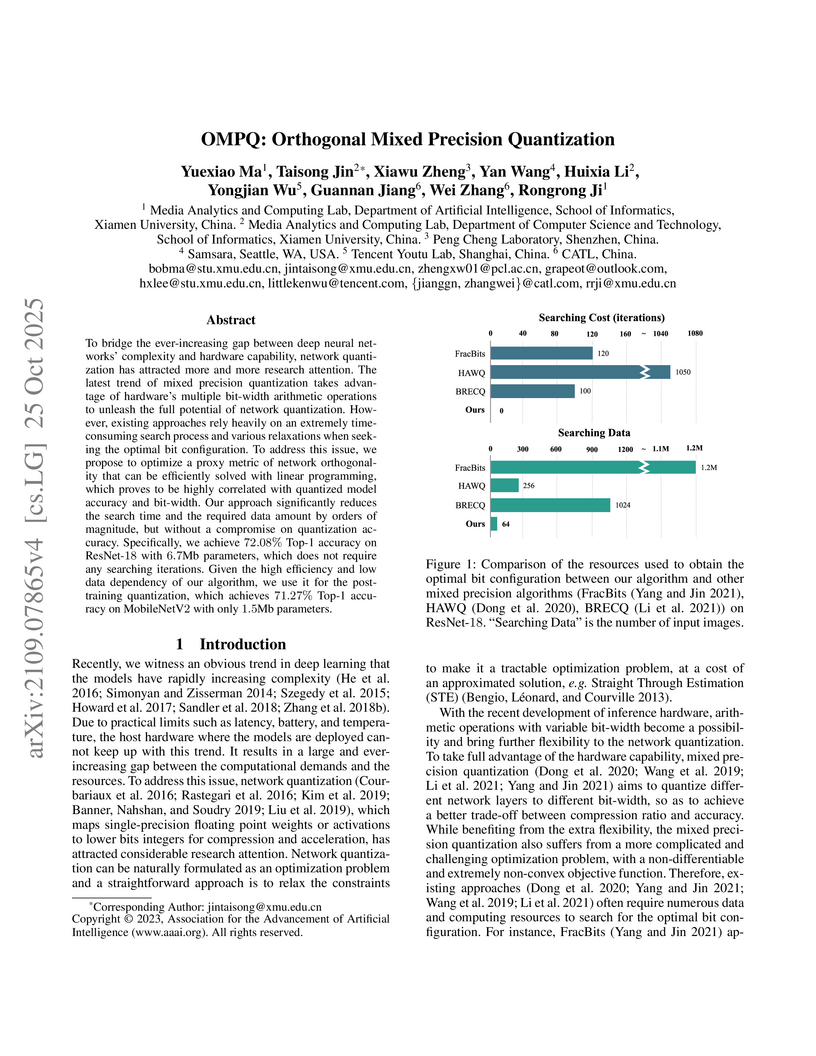
25 Oct 2025
To bridge the ever increasing gap between deep neural networks' complexity and hardware capability, network quantization has attracted more and more research attention. The latest trend of mixed precision quantization takes advantage of hardware's multiple bit-width arithmetic operations to unleash the full potential of network quantization. However, this also results in a difficult integer programming formulation, and forces most existing approaches to use an extremely time-consuming search process even with various relaxations. Instead of solving a problem of the original integer programming, we propose to optimize a proxy metric, the concept of network orthogonality, which is highly correlated with the loss of the integer programming but also easy to optimize with linear programming. This approach reduces the search time and required data amount by orders of magnitude, with little compromise on quantization accuracy. Specifically, we achieve 72.08% Top-1 accuracy on ResNet-18 with 6.7Mb, which does not require any searching iterations. Given the high efficiency and low data dependency of our algorithm, we used it for the post-training quantization, which achieve 71.27% Top-1 accuracy on MobileNetV2 with only 1.5Mb. Our code is available at this https URL.

09 Apr 2025
Pinterest researchers develop InteractRank, a two-tower pre-ranking model that incorporates cross-interaction features and real-time user engagement sequences to improve web-scale search relevance, demonstrating a 6.5% improvement in Search Intent Fulfillment Rate over BM25 baselines while maintaining low latency requirements for production deployment.

08 Mar 2017
We demonstrate that, with the availability of distributed computation platforms such as Amazon Web Services and open-source tools, it is possible for a small engineering team to build, launch and maintain a cost-effective, large-scale visual search system with widely available tools. We also demonstrate, through a comprehensive set of live experiments at Pinterest, that content recommendation powered by visual search improve user engagement. By sharing our implementation details and the experiences learned from launching a commercial visual search engines from scratch, we hope visual search are more widely incorporated into today's commercial applications.

10 Apr 2019

Recommender systems that can learn from cross-session data to dynamically predict the next item a user will choose are crucial for online platforms. However, existing approaches often use out-of-the-box sequence models which are limited by speed and memory consumption, are often infeasible for production environments, and usually do not incorporate cross-session information, which is crucial for effective recommendations. Here we propose Hierarchical Temporal Convolutional Networks (HierTCN), a hierarchical deep learning architecture that makes dynamic recommendations based on users' sequential multi-session interactions with items. HierTCN is designed for web-scale systems with billions of items and hundreds of millions of users. It consists of two levels of models: The high-level model uses Recurrent Neural Networks (RNN) to aggregate users' evolving long-term interests across different sessions, while the low-level model is implemented with Temporal Convolutional Networks (TCN), utilizing both the long-term interests and the short-term interactions within sessions to predict the next interaction. We conduct extensive experiments on a public XING dataset and a large-scale Pinterest dataset that contains 6 million users with 1.6 billion interactions. We show that HierTCN is 2.5x faster than RNN-based models and uses 90% less data memory compared to TCN-based models. We further develop an effective data caching scheme and a queue-based mini-batch generator, enabling our model to be trained within 24 hours on a single GPU. Our model consistently outperforms state-of-the-art dynamic recommendation methods, with up to 18% improvement in recall and 10% in mean reciprocal rank.
There are no more papers matching your filters at the moment.
