
05 Jun 2025
An LLM-based framework for video summarization, LLMVS, leverages Large Language Models to semantically interpret video frame captions and globally aggregate importance, achieving state-of-the-art performance on the SumMe and TVSum benchmarks.

22 Oct 2025

QHFLOW introduces a generative model leveraging flow matching and high-order SE(3)-equivariance to predict Kohn-Sham Hamiltonians from molecular geometries. This approach effectively models the distribution of Hamiltonians, reducing prediction error by up to 73% on the MD17 dataset and accelerating Density Functional Theory (DFT) calculations by 54% on the QH9-id benchmark.

14 Oct 2025
Retrieval-Augmented Generation (RAG) is an effective approach to enhance the factual accuracy of large language models (LLMs) by retrieving information from external databases, which are typically composed of diverse sources, to supplement the limited internal knowledge of LLMs. However, the standard RAG often risks retrieving incorrect information, as it relies solely on relevance between a query and a document, overlooking the heterogeneous reliability of these sources. To address this issue, we propose Reliability-Aware RAG (RA-RAG), a new multi-source RAG framework that estimates the reliability of sources and leverages this information to prioritize highly reliable and relevant documents, ensuring more robust and accurate response generation. Specifically, RA-RAG first estimates source reliability by cross-checking information across multiple sources. It then retrieves documents from the top- reliable and relevant sources and aggregates their information using weighted majority voting (WMV), where the selective retrieval ensures scalability while not compromising the performance. Comprehensive experiments show that RA-RAG consistently outperforms baselines in scenarios with heterogeneous source reliability while scaling efficiently as the number of sources increases. Furthermore, we demonstrate the ability of RA-RAG to estimate real-world sources' reliability, highlighting its practical applicability. \jy{Our code and data are available at \href{this https URL}{RA-RAG}.}

28 Sep 2025
Designing metal-organic frameworks (MOFs) with novel chemistries is a longstanding challenge due to their large combinatorial space and complex 3D arrangements of the building blocks. While recent deep generative models have enabled scalable MOF generation, they assume (1) a fixed set of building blocks and (2) known local 3D coordinates of building blocks. However, this limits their ability to (1) design novel MOFs and (2) generate the structure using novel building blocks. We propose a two-stage MOF generation framework that overcomes these limitations by modeling both chemical and geometric degrees of freedom. First, we train an SMILES-based autoregressive model to generate metal and organic building blocks, paired with a cheminformatics toolkit for 3D structure initialization. Second, we introduce a flow matching model that predicts translations, rotations, and torsional angles to assemble the blocks into valid 3D frameworks. Our experiments demonstrate improved reconstruction accuracy, the generation of valid, novel, and unique MOFs, and the ability to create novel building blocks. Our code is available at this https URL.

13 Jun 2025
POSTECH researchers develop Affogato, an automated data generation pipeline that leverages foundation models (Gemma3, Molmo, SAM) to create the largest open-vocabulary affordance grounding dataset containing 150K 3D objects with 750K query-heatmap pairs across 450+ object classes and 350+ affordance types, achieving 72.3% "good" ratings in human evaluation while enabling unified 2D and 3D affordance understanding through multi-view aggregation that projects 3D heatmaps to 2D image planes, with their minimalistic Espresso baseline models demonstrating superior cross-dataset generalization (14.3% aIoU drop vs 66.2% for competing methods) and zero-shot performance on AGD20K benchmark by training only lightweight decoders while keeping pretrained vision-language encoders frozen, addressing the critical data scarcity bottleneck that has limited affordance grounding to narrow object categories and predefined interaction vocabularies.

07 Apr 2024
Referring Image Segmentation (RIS) is a cross-modal task that aims to segment an instance described by a natural language expression. Recent methods leverage large-scale pretrained unimodal models as backbones along with fusion techniques for joint reasoning across modalities. However, the inherent cross-modal nature of RIS raises questions about the effectiveness of unimodal backbones. We propose RISCLIP, a novel framework that effectively leverages the cross-modal nature of CLIP for RIS. Observing CLIP's inherent alignment between image and text features, we capitalize on this starting point and introduce simple but strong modules that enhance unimodal feature extraction and leverage rich alignment knowledge in CLIP's image-text shared-embedding space. RISCLIP exhibits outstanding results on all three major RIS benchmarks and also outperforms previous CLIP-based methods, demonstrating the efficacy of our strategy in extending CLIP's image-text alignment to RIS.

13 Oct 2025
For reliable large-scale quantum computation, a quantum error correction (QEC) scheme must effectively resolve physical errors to protect logical information. Leveraging recent advances in deep learning, neural network-based decoders have emerged as a promising approach to enhance the reliability of QEC. We propose the Hierarchical Qubit-Merging Transformer (HQMT), a novel and general decoding framework that explicitly leverages the structural graph of stabilizer codes to learn error correlations across multiple scales. Our architecture first computes attention locally on structurally related groups of stabilizers and then systematically merges these qubit-centric representations to build a global view of the error syndrome. The proposed HQMT achieves substantially lower logical error rates for surface codes by integrating a dedicated qubit-merging layer within the transformer architecture. Across various code distances, HQMT significantly outperforms previous neural network-based QEC decoders as well as a powerful belief propagation with ordered statistics decoding (BP+OSD) baseline. This hierarchical approach provides a scalable and effective framework for surface code decoding, advancing the realization of reliable quantum computing.

23 Aug 2025
Self-correction has demonstrated potential in code generation by allowing language models to revise and improve their outputs through successive refinement. Recent studies have explored prompting-based strategies that incorporate verification or feedback loops using proprietary models, as well as training-based methods that leverage their strong reasoning capabilities. However, whether smaller models possess the capacity to effectively guide their outputs through self-reflection remains unexplored. Our findings reveal that smaller models struggle to exhibit reflective revision behavior across both self-correction paradigms. In response, we introduce CoCoS, an approach designed to enhance the ability of small language models for multi-turn code correction. Specifically, we propose an online reinforcement learning objective that trains the model to confidently maintain correct outputs while progressively correcting incorrect outputs as turns proceed. Our approach features an accumulated reward function that aggregates rewards across the entire trajectory and a fine-grained reward better suited to multi-turn correction scenarios. This facilitates the model in enhancing initial response quality while achieving substantial improvements through self-correction. With 1B-scale models, CoCoS achieves improvements of 35.8% on the MBPP and 27.7% on HumanEval compared to the baselines.

23 May 2025
Recently, large language models (LLMs) have shown significant progress,
approaching human perception levels. In this work, we demonstrate that despite
these advances, LLMs still struggle to reason using molecular structural
information. This gap is critical because many molecular properties, including
functional groups, depend heavily on such structural details. To address this
limitation, we propose an approach that sketches molecular structures for
reasoning. Specifically, we introduce Molecular Structural Reasoning (MSR)
framework to enhance the understanding of LLMs by explicitly incorporating the
key structural features. We present two frameworks for scenarios where the
target molecule is known or unknown. We verify that our MSR improves molecular
understanding through extensive experiments.
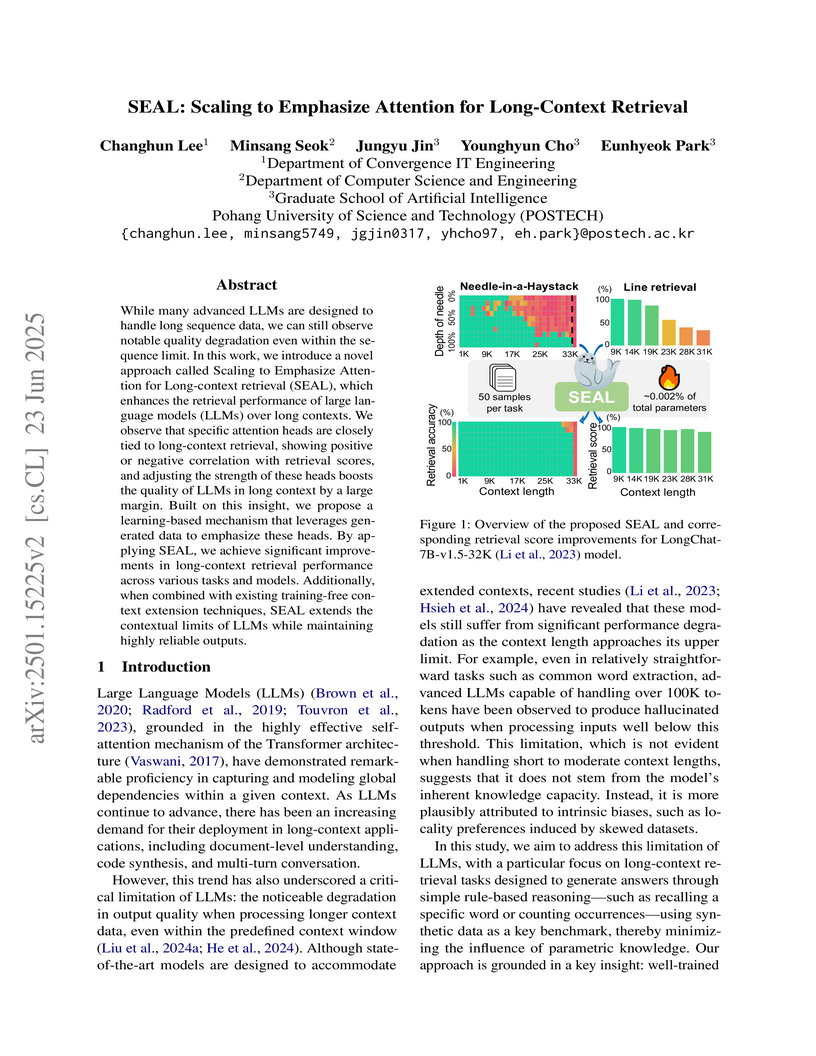
23 Jun 2025
While many advanced LLMs are designed to handle long sequence data, we can still observe notable quality degradation even within the sequence limit. In this work, we introduce a novel approach called Scaling to Emphasize Attention for Long-context retrieval (SEAL), which enhances the retrieval performance of large language models (LLMs) over long contexts. We observe that specific attention heads are closely tied to long-context retrieval, showing positive or negative correlation with retrieval scores, and adjusting the strength of these heads boosts the quality of LLMs in long context by a large margin. Built on this insight, we propose a learning-based mechanism that leverages generated data to emphasize these heads. By applying SEAL, we achieve significant improvements in long-context retrieval performance across various tasks and models. Additionally, when combined with existing training-free context extension techniques, SEAL extends the contextual limits of LLMs while maintaining highly reliable outputs.

29 Sep 2025
Establishing semantic correspondences between images is a fundamental yet challenging task in computer vision. Traditional feature-metric methods enhance visual features but may miss complex inter-correlation relationships, while recent correlation-metric approaches are hindered by high computational costs due to processing 4D correlation maps. We introduce MambaMatcher, a novel method that overcomes these limitations by efficiently modeling high-dimensional correlations using selective state-space models (SSMs). By implementing a similarity-aware selective scan mechanism adapted from Mamba's linear-complexity algorithm, MambaMatcher refines the 4D correlation map effectively without compromising feature map resolution or receptive field. Experiments on standard semantic correspondence benchmarks demonstrate that MambaMatcher achieves state-of-the-art performance.

13 Oct 2025
Researchers from POSTECH and Samsung Electronics developed Neural Weight Compression (NWC), an end-to-end learned compression framework for large language model weights, which achieves superior accuracy-compression tradeoffs, particularly at mid-to-high bitrates (4-6 bits), compared to existing handcrafted quantization techniques across various LLMs and vision models.

16 Oct 2022

Despite the extensive adoption of machine learning on the task of visual object tracking, recent learning-based approaches have largely overlooked the fact that visual tracking is a sequence-level task in its nature; they rely heavily on frame-level training, which inevitably induces inconsistency between training and testing in terms of both data distributions and task objectives. This work introduces a sequence-level training strategy for visual tracking based on reinforcement learning and discusses how a sequence-level design of data sampling, learning objectives, and data augmentation can improve the accuracy and robustness of tracking algorithms. Our experiments on standard benchmarks including LaSOT, TrackingNet, and GOT-10k demonstrate that four representative tracking models, SiamRPN++, SiamAttn, TransT, and TrDiMP, consistently improve by incorporating the proposed methods in training without modifying architectures.

02 Sep 2024
The substantial computational costs of diffusion models, especially due to the repeated denoising steps necessary for high-quality image generation, present a major obstacle to their widespread adoption. While several studies have attempted to address this issue by reducing the number of score function evaluations (NFE) using advanced ODE solvers without fine-tuning, the decreased number of denoising iterations misses the opportunity to update fine details, resulting in noticeable quality degradation. In our work, we introduce an advanced acceleration technique that leverages the temporal redundancy inherent in diffusion models. Reusing feature maps with high temporal similarity opens up a new opportunity to save computation resources without compromising output quality. To realize the practical benefits of this intuition, we conduct an extensive analysis and propose a novel method, FRDiff. FRDiff is designed to harness the advantages of both reduced NFE and feature reuse, achieving a Pareto frontier that balances fidelity and latency trade-offs in various generative tasks.

05 Dec 2024
Temporal action segmentation and long-term action anticipation are two popular vision tasks for the temporal analysis of actions in videos. Despite apparent relevance and potential complementarity, these two problems have been investigated as separate and distinct tasks. In this work, we tackle these two problems, action segmentation and action anticipation, jointly using a unified diffusion model dubbed ActFusion. The key idea to unification is to train the model to effectively handle both visible and invisible parts of the sequence in an integrated manner; the visible part is for temporal segmentation, and the invisible part is for future anticipation. To this end, we introduce a new anticipative masking strategy during training in which a late part of the video frames is masked as invisible, and learnable tokens replace these frames to learn to predict the invisible future. Experimental results demonstrate the bi-directional benefits between action segmentation and anticipation. ActFusion achieves the state-of-the-art performance across the standard benchmarks of 50 Salads, Breakfast, and GTEA, outperforming task-specific models in both of the two tasks with a single unified model through joint learning.

31 Mar 2022
The inherent challenge of detecting symmetries stems from arbitrary orientations of symmetry patterns; a reflection symmetry mirrors itself against an axis with a specific orientation while a rotation symmetry matches its rotated copy with a specific orientation. Discovering such symmetry patterns from an image thus benefits from an equivariant feature representation, which varies consistently with reflection and rotation of the image. In this work, we introduce a group-equivariant convolutional network for symmetry detection, dubbed EquiSym, which leverages equivariant feature maps with respect to a dihedral group of reflection and rotation. The proposed network is built end-to-end with dihedrally-equivariant layers and trained to output a spatial map for reflection axes or rotation centers. We also present a new dataset, DENse and DIverse symmetry (DENDI), which mitigates limitations of existing benchmarks for reflection and rotation symmetry detection. Experiments show that our method achieves the state of the arts in symmetry detection on LDRS and DENDI datasets.

29 May 2025
POSTECH researchers develop HDRQ (Hessian and Distance Regularizing Quantization), the first post-training quantization method designed specifically for model merging in multi-target domain adaptation scenarios, addressing how quantization noise disrupts weight alignment between domain-adapted models by introducing noise-based Hessian regularization to flatten loss surfaces and distance regularization to maintain proximity to source weights, achieving substantial improvements in merged model performance at lower bit-widths (4.21 mIoU gain over QDrop at W4A4 in semantic segmentation and 3.42% improvement in Office-Home classification) through theoretical analysis extending the error barrier concept to quantized model spaces.

15 Apr 2024
We address the problem of generalized category discovery (GCD) that aims to partition a partially labeled collection of images; only a small part of the collection is labeled and the total number of target classes is unknown. To address this generalized image clustering problem, we revisit the mean-shift algorithm, i.e., a classic, powerful technique for mode seeking, and incorporate it into a contrastive learning framework. The proposed method, dubbed Contrastive Mean-Shift (CMS) learning, trains an image encoder to produce representations with better clustering properties by an iterative process of mean shift and contrastive update. Experiments demonstrate that our method, both in settings with and without the total number of clusters being known, achieves state-of-the-art performance on six public GCD benchmarks without bells and whistles.

27 Aug 2025

We observe that zero-shot appearance transfer with large-scale image generation models faces a significant challenge: Attention Leakage. This challenge arises when the semantic mapping between two images is captured by the Query-Key alignment. To tackle this issue, we introduce Q-Align, utilizing Query-Query alignment to mitigate attention leakage and improve the semantic alignment in zero-shot appearance transfer. Q-Align incorporates three core contributions: (1) Query-Query alignment, facilitating the sophisticated spatial semantic mapping between two images; (2) Key-Value rearrangement, enhancing feature correspondence through realignment; and (3) Attention refinement using rearranged keys and values to maintain semantic consistency. We validate the effectiveness of Q-Align through extensive experiments and analysis, and Q-Align outperforms state-of-the-art methods in appearance fidelity while maintaining competitive structure preservation.

27 Jul 2022


Researchers at POSTECH developed FastMETRO, an encoder-decoder transformer that uses disentangled cross-attention and topology-aware masking for 3D human mesh recovery. This approach achieves state-of-the-art accuracy on datasets like 3DPW while drastically reducing model parameters (e.g., 9% of METRO's transformer parameters) and increasing inference speed by up to 2.58x compared to prior transformer-based methods.
There are no more papers matching your filters at the moment.
