
14 Jul 2024



A comprehensive survey categorizes self-supervised learning algorithms into context-based, contrastive, generative, and hybrid approaches, exploring their evolution, theoretical underpinnings, and applications in computer vision and natural language processing. It comparatively analyzes their performance characteristics and identifies key future research directions and open questions.

17 Dec 2023

Researchers from The Chinese University of Hong Kong and collaborators developed a multi-task prompting framework for Graph Neural Networks (GNNs), enabling pre-trained GNNs to adapt to diverse node, edge, and graph-level tasks in few-shot settings. The approach yields superior performance and efficiency, reducing tunable parameters by over 95% while maintaining or improving accuracy across various datasets.

16 Oct 2025
LOTA introduces a method for detecting AI-generated images by extracting intrinsic noise patterns from lower bit-planes, achieving an average accuracy of 98.9% on the GenImage dataset. It processes images at 1.52 milliseconds, demonstrating superior cross-generator generalization and robustness to image degradation compared to existing techniques.

18 Mar 2025

A comprehensive survey examines adversarial robustness in multimodal large language models (MLLMs) across image, video, audio and speech modalities, providing a structured taxonomy of attacks and defenses while highlighting key research gaps in cross-modal security and defense mechanisms.
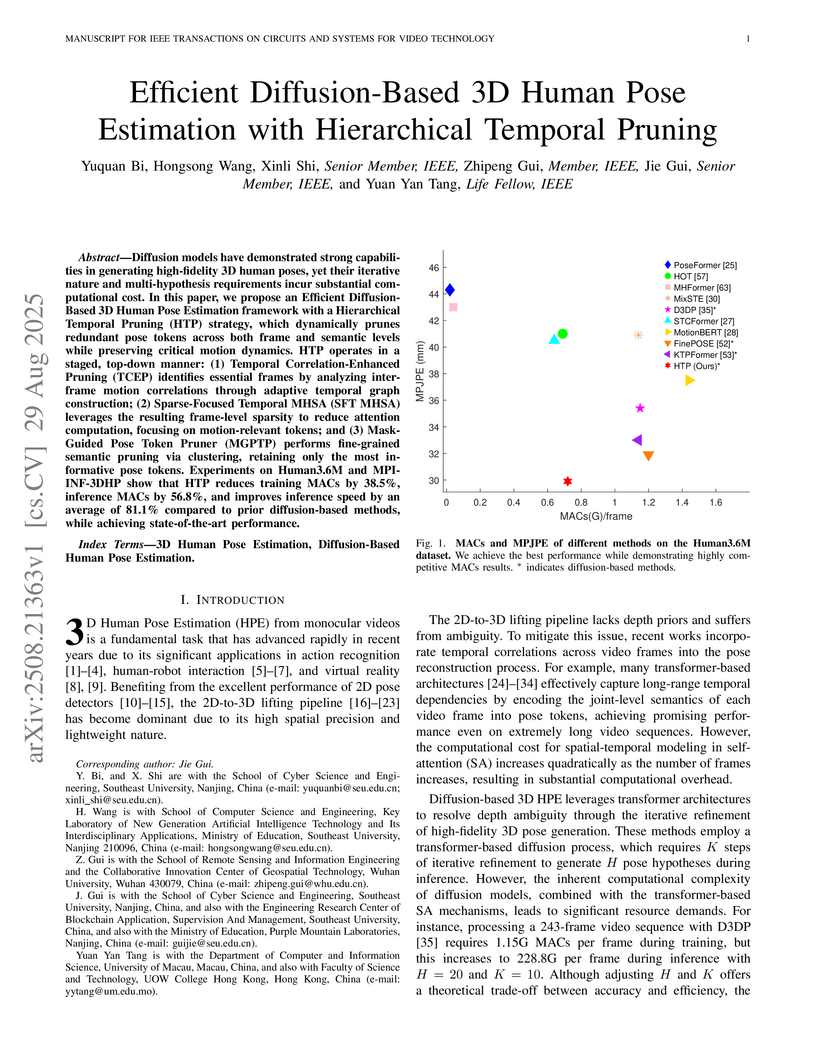
29 Aug 2025
Diffusion models have demonstrated strong capabilities in generating high-fidelity 3D human poses, yet their iterative nature and multi-hypothesis requirements incur substantial computational cost. In this paper, we propose an Efficient Diffusion-Based 3D Human Pose Estimation framework with a Hierarchical Temporal Pruning (HTP) strategy, which dynamically prunes redundant pose tokens across both frame and semantic levels while preserving critical motion dynamics. HTP operates in a staged, top-down manner: (1) Temporal Correlation-Enhanced Pruning (TCEP) identifies essential frames by analyzing inter-frame motion correlations through adaptive temporal graph construction; (2) Sparse-Focused Temporal MHSA (SFT MHSA) leverages the resulting frame-level sparsity to reduce attention computation, focusing on motion-relevant tokens; and (3) Mask-Guided Pose Token Pruner (MGPTP) performs fine-grained semantic pruning via clustering, retaining only the most informative pose tokens. Experiments on Human3.6M and MPI-INF-3DHP show that HTP reduces training MACs by 38.5\%, inference MACs by 56.8\%, and improves inference speed by an average of 81.1\% compared to prior diffusion-based methods, while achieving state-of-the-art performance.

04 Aug 2024
An approach to multimodal semantic communication (LAM-MSC) leverages large AI models for unifying diverse data types, personalizing semantic interpretation, and robustly estimating wireless channels. Simulations indicate the framework achieves high compression rates and maintains robust performance.

22 Aug 2025
Zero-shot action recognition, which addresses the issue of scalability and generalization in action recognition and allows the models to adapt to new and unseen actions dynamically, is an important research topic in computer vision communities. The key to zero-shot action recognition lies in aligning visual features with semantic vectors representing action categories. Most existing methods either directly project visual features onto the semantic space of text category or learn a shared embedding space between the two modalities. However, a direct projection cannot accurately align the two modalities, and learning robust and discriminative embedding space between visual and text representations is often difficult. To address these issues, we introduce Dual Visual-Text Alignment (DVTA) for skeleton-based zero-shot action recognition. The DVTA consists of two alignment modules--Direct Alignment (DA) and Augmented Alignment (AA)--along with a designed Semantic Description Enhancement (SDE). The DA module maps the skeleton features to the semantic space through a specially designed visual projector, followed by the SDE, which is based on cross-attention to enhance the connection between skeleton and text, thereby reducing the gap between modalities. The AA module further strengthens the learning of the embedding space by utilizing deep metric learning to learn the similarity between skeleton and text. Our approach achieves state-of-the-art performances on several popular zero-shot skeleton-based action recognition benchmarks. The code is available at: this https URL.

26 Jun 2024

Underwater image enhancement (UIE) presents a significant challenge within computer vision research. Despite the development of numerous UIE algorithms, a thorough and systematic review is still absent. To foster future advancements, we provide a detailed overview of the UIE task from several perspectives. Firstly, we introduce the physical models, data construction processes, evaluation metrics, and loss functions. Secondly, we categorize and discuss recent algorithms based on their contributions, considering six aspects: network architecture, learning strategy, learning stage, auxiliary tasks, domain perspective, and disentanglement fusion. Thirdly, due to the varying experimental setups in the existing literature, a comprehensive and unbiased comparison is currently unavailable. To address this, we perform both quantitative and qualitative evaluations of state-of-the-art algorithms across multiple benchmark datasets. Lastly, we identify key areas for future research in UIE. A collection of resources for UIE can be found at {this https URL}.

09 Jul 2025


With the growing complexity and dynamics of the mobile communication networks, accurately predicting key system parameters, such as channel state information (CSI), user location, and network traffic, has become essential for a wide range of physical (PHY)-layer and medium access control (MAC)-layer tasks. Although traditional deep learning (DL)-based methods have been widely applied to such prediction tasks, they often struggle to generalize across different scenarios and tasks. In response, we propose a unified foundation model for multi-task prediction in wireless networks that supports diverse prediction intervals. The proposed model enforces univariate decomposition to unify heterogeneous tasks, encodes granularity for interval awareness, and uses a causal Transformer backbone for accurate predictions. Additionally, we introduce a patch masking strategy during training to support arbitrary input lengths. After trained on large-scale datasets, the proposed foundation model demonstrates strong generalization to unseen scenarios and achieves zero-shot performance on new tasks that surpass traditional full-shot baselines.

10 Dec 2024
High-accuracy positioning has become a fundamental enabler for intelligent connected devices. Nevertheless, the present wireless networks still rely on model-driven approaches to achieve positioning functionality, which are susceptible to performance degradation in practical scenarios, primarily due to hardware impairments. Integrating artificial intelligence into the positioning framework presents a promising solution to revolutionize the accuracy and robustness of location-based services. In this study, we address this challenge by reformulating the problem of angle-of-arrival (AoA) estimation into image reconstruction of spatial spectrum. To this end, we design a model-driven deep neural network (MoD-DNN), which can automatically calibrate the angular-dependent phase error. The proposed MoD-DNN approach employs an iterative optimization scheme between a convolutional neural network and a sparse conjugate gradient algorithm. Simulation and experimental results are presented to demonstrate the effectiveness of the proposed method in enhancing spectrum calibration and AoA estimation.

13 Jun 2025
In this paper, we propose a unified framework based on equivariance for the design of artificial intelligence (AI)-assisted technologies in multi-user multiple-input-multiple-output (MU-MIMO) systems. We first provide definitions of multidimensional equivariance, high-order equivariance, and multidimensional invariance (referred to collectively as tensor equivariance). On this basis, by investigating the design of precoding and user scheduling, which are key techniques in MU-MIMO systems, we delve deeper into revealing tensor equivariance of the mappings from channel information to optimal precoding tensors, precoding auxiliary tensors, and scheduling indicators, respectively. To model mappings with tensor equivariance, we propose a series of plug-and-play tensor equivariant neural network (TENN) modules, where the computation involving intricate parameter sharing patterns is transformed into concise tensor operations. Building upon TENN modules, we propose the unified tensor equivariance framework that can be applicable to various communication tasks, based on which we easily accomplish the design of corresponding AI-assisted precoding and user scheduling schemes. Simulation results demonstrate that the constructed precoding and user scheduling methods achieve near-optimal performance while exhibiting significantly lower computational complexity and generalization to inputs with varying sizes across multiple dimensions. This validates the superiority of TENN modules and the unified framework.

03 Aug 2024
Semantic communication (SC) is an emerging intelligent paradigm, offering solutions for various future applications like metaverse, mixed reality, and the Internet of Everything. However, in current SC systems, the construction of the knowledge base (KB) faces several issues, including limited knowledge representation, frequent knowledge updates, and insecure knowledge sharing. Fortunately, the development of the large AI model (LAM) provides new solutions to overcome the above issues. Here, we propose a LAM-based SC framework (LAM-SC) specifically designed for image data, where we first apply the segment anything model (SAM)-based KB (SKB) that can split the original image into different semantic segments by universal semantic knowledge. Then, we present an attention-based semantic integration (ASI) to weigh the semantic segments generated by SKB without human participation and integrate them as the semantic aware image. Additionally, we propose an adaptive semantic compression (ASC) encoding to remove redundant information in semantic features, thereby reducing communication overhead. Finally, through simulations, we demonstrate the effectiveness of the LAM-SC framework and the possibility of applying the LAM-based KB in future SC paradigms.

01 Dec 2025
 Fudan UniversityPurple Mountain Laboratories
Fudan UniversityPurple Mountain Laboratories Shanghai Jiao Tong UniversityThe Hong Kong University of Science and Technology (Guangzhou)Swinburne University of TechnologyChina University of Petroleum (East China)James Cook UniversityShandong Key Laboratory of Intelligent Oil & Gas Industrial SoftwareXi
JiaoTong-Liverpool UniversityXi
as’an Jiaotong-Liverpool University
Shanghai Jiao Tong UniversityThe Hong Kong University of Science and Technology (Guangzhou)Swinburne University of TechnologyChina University of Petroleum (East China)James Cook UniversityShandong Key Laboratory of Intelligent Oil & Gas Industrial SoftwareXi
JiaoTong-Liverpool UniversityXi
as’an Jiaotong-Liverpool UniversityReferring Multi-Object Tracking (RMOT) aims to achieve precise object detection and tracking through natural language instructions, representing a fundamental capability for intelligent robotic systems. However, current RMOT research remains mostly confined to ground-level scenarios, which constrains their ability to capture broad-scale scene contexts and perform comprehensive tracking and path planning. In contrast, Unmanned Aerial Vehicles (UAVs) leverage their expansive aerial perspectives and superior maneuverability to enable wide-area surveillance. Moreover, UAVs have emerged as critical platforms for Embodied Intelligence, which has given rise to an unprecedented demand for intelligent aerial systems capable of natural language interaction. To this end, we introduce AerialMind, the first large-scale RMOT benchmark in UAV scenarios, which aims to bridge this research gap. To facilitate its construction, we develop an innovative semi-automated collaborative agent-based labeling assistant (COALA) framework that significantly reduces labor costs while maintaining annotation quality. Furthermore, we propose HawkEyeTrack (HETrack), a novel method that collaboratively enhances vision-language representation learning and improves the perception of UAV scenarios. Comprehensive experiments validated the challenging nature of our dataset and the effectiveness of our method.

20 Nov 2025

Cross-modal object tracking (CMOT) is an emerging task that maintains target consistency while the video stream switches between different modalities, with only one modality available in each frame, mostly focusing on RGB-Near Infrared (RGB-NIR) tracking. Existing methods typically connect parallel RGB and NIR branches to a shared backbone, which limits the comprehensive extraction of distinctive modality-specific features and fails to address the issue of object drift, especially in the presence of unreliable inputs. In this paper, we propose SwiTrack, a novel state-switching framework that redefines CMOT through the deployment of three specialized streams. Specifically, RGB frames are processed by the visual encoder, while NIR frames undergo refinement via a NIR gated adapter coupled with the visual encoder to progressively calibrate shared latent space features, thereby yielding more robust cross-modal representations. For invalid modalities, a consistency trajectory prediction module leverages spatio-temporal cues to estimate target movement, ensuring robust tracking and mitigating drift. Additionally, we incorporate dynamic template reconstruction to iteratively update template features and employ a similarity alignment loss to reinforce feature consistency. Experimental results on the latest benchmarks demonstrate that our tracker achieves state-of-the-art performance, boosting precision rate and success rate gains by 7.2\% and 4.3\%, respectively, while maintaining real-time tracking at 65 frames per second. Code and models are available at this https URL.

03 Dec 2024
As large-scale diffusion models continue to advance, they excel at producing high-quality images but often generate unwanted content, such as sexually explicit or violent content. Existing methods for concept removal generally guide the image generation process but can unintentionally modify unrelated regions, leading to inconsistencies with the original model. We propose a novel approach for targeted concept replacing in diffusion models, enabling specific concepts to be removed without affecting non-target areas. Our method introduces a dedicated concept localizer for precisely identifying the target concept during the denoising process, trained with few-shot learning to require minimal labeled data. Within the identified region, we introduce a training-free Dual Prompts Cross-Attention (DPCA) module to substitute the target concept, ensuring minimal disruption to surrounding content. We evaluate our method on concept localization precision and replacement efficiency. Experimental results demonstrate that our method achieves superior precision in localizing target concepts and performs coherent concept replacement with minimal impact on non-target areas, outperforming existing approaches.

26 Aug 2025
Acquiring perfect channel state information (CSI) introduces substantial challenges in cell-free massive MIMO (CF-mMIMO) systems, primarily due to the large dimensionality of channel parameters, especially under ultra-reliable low-latency communication (uRLLC) constraints. Furthermore, the impact of imperfect CSI on the average achievable rate within the finite blocklength regime remains largely unexplored. Motivated by this gap, this paper proposes a novel analytical framework that provides a closed-form expression for the average achievable rate with imperfect CSI in the Laplace domain. We demonstrate analytically that both the channel dispersion and the expected channel capacity can be expressed explicitly in terms of the Laplace transform of the large-scale fading component. Numerical simulations confirm that the derived expressions match closely with Monte Carlo simulations, verifying their accuracy. Furthermore, we theoretically show that although imperfect CSI degrades performance in the finite blocklength regime, the inherent characteristics of CF-mMIMO architecture effectively mitigates this loss.

23 Jun 2025
The rapid advancement of text-to-image (T2I) models, such as Stable Diffusion, has enhanced their capability to synthesize images from textual prompts. However, this progress also raises significant risks of misuse, including the generation of harmful content (e.g., pornography, violence, discrimination), which contradicts the ethical goals of T2I technology and hinders its sustainable development. Inspired by "jailbreak" attacks in large language models, which bypass restrictions through subtle prompt modifications, this paper proposes NSFW-Classifier Guided Prompt Sanitization (PromptSan), a novel approach to detoxify harmful prompts without altering model architecture or degrading generation capability. PromptSan includes two variants: PromptSan-Modify, which iteratively identifies and replaces harmful tokens in input prompts using text NSFW classifiers during inference, and PromptSan-Suffix, which trains an optimized suffix token sequence to neutralize harmful intent while passing both text and image NSFW classifier checks. Extensive experiments demonstrate that PromptSan achieves state-of-the-art performance in reducing harmful content generation across multiple metrics, effectively balancing safety and usability.

19 Aug 2025
Self-supervised contrastive learning (CL) effectively learns transferable representations from unlabeled data containing images or image-text pairs but suffers vulnerability to data poisoning backdoor attacks (DPCLs). An adversary can inject poisoned images into pretraining datasets, causing compromised CL encoders to exhibit targeted misbehavior in downstream tasks. Existing DPCLs, however, achieve limited efficacy due to their dependence on fragile implicit co-occurrence between backdoor and target object and inadequate suppression of discriminative features in backdoored images. We propose Noisy Alignment (NA), a DPCL method that explicitly suppresses noise components in poisoned images. Inspired by powerful training-controllable CL attacks, we identify and extract the critical objective of noisy alignment, adapting it effectively into data-poisoning scenarios. Our method implements noisy alignment by strategically manipulating contrastive learning's random cropping mechanism, formulating this process as an image layout optimization problem with theoretically derived optimal parameters. The resulting method is simple yet effective, achieving state-of-the-art performance compared to existing DPCLs, while maintaining clean-data accuracy. Furthermore, Noisy Alignment demonstrates robustness against common backdoor defenses. Codes can be found at this https URL.

18 Jul 2020
This article proposes the concept of channel knowledge map (CKM) as an
enabler towards environment-aware wireless communications. CKM is a
site-specific database, tagged with the locations of the transmitters and/or
receivers, that contains whatever channel-related information useful to enhance
environmental-awareness and facilitate or even obviate sophisticated real-time
channel state information (CSI) acquisition. Therefore, CKM is expected to play
an important role for 6G networks targeting for super high capacity, extremely
low latency, and ultra-massive connectivity, by offering potential solutions to
practical challenges brought by the drastically increased channel dimensions
and training overhead. In this article, the motivations of
environmental-awareness enabled by CKM are firstly discussed, followed by the
key techniques to build and utilize CKM. In particular, it is highlighted that
CKM is especially appealing for four channel types: channels for yet-to-reach
locations, channels for non-cooperative nodes, channels with large dimensions,
and channels with severe hardware/processing limitations. Two case studies with
extensive numerical results are presented to demonstrate the great potential of
environment-aware communications enabled by CKM.

08 Oct 2024
Existing diffusion-based methods for inverse problems sample from the posterior using score functions and accept the generated random samples as solutions. In applications that posterior mean is preferred, we have to generate multiple samples from the posterior which is time-consuming. In this work, by analyzing the probability density evolution of the conditional reverse diffusion process, we prove that the posterior mean can be achieved by tracking the mean of each reverse diffusion step. Based on that, we establish a framework termed reverse mean propagation (RMP) that targets the posterior mean directly. We show that RMP can be implemented by solving a variational inference problem, which can be further decomposed as minimizing a reverse KL divergence at each reverse step. We further develop an algorithm that optimizes the reverse KL divergence with natural gradient descent using score functions and propagates the mean at each reverse step. Experiments demonstrate the validity of the theory of our framework and show that our algorithm outperforms state-of-the-art algorithms on reconstruction performance with lower computational complexity in various inverse problems.
There are no more papers matching your filters at the moment.
