
31 May 2025

This paper presents ICAT, an evaluation framework for measuring coverage of
diverse factual information in long-form text generation. ICAT breaks down a
long output text into a list of atomic claims and not only verifies each claim
through retrieval from a (reliable) knowledge source, but also computes the
alignment between the atomic factual claims and various aspects expected to be
presented in the output. We study three implementations of the ICAT framework,
each with a different assumption on the availability of aspects and alignment
method. By adopting data from the diversification task in the TREC Web Track
and the ClueWeb corpus, we evaluate the ICAT framework. We demonstrate strong
correlation with human judgments and provide comprehensive evaluation across
multiple state-of-the-art LLMs. Our framework further offers interpretable and
fine-grained analysis of diversity and coverage. Its modular design allows for
easy adaptation to different domains and datasets, making it a valuable tool
for evaluating the qualitative aspects of long-form responses produced by LLMs.

06 Dec 2023
Digital whole slides images contain an enormous amount of information providing a strong motivation for the development of automated image analysis tools. Particularly deep neural networks show high potential with respect to various tasks in the field of digital pathology. However, a limitation is given by the fact that typical deep learning algorithms require (manual) annotations in addition to the large amounts of image data, to enable effective training. Multiple instance learning exhibits a powerful tool for learning deep neural networks in a scenario without fully annotated data. These methods are particularly effective in this domain, due to the fact that labels for a complete whole slide image are often captured routinely, whereas labels for patches, regions or pixels are not. This potential already resulted in a considerable number of publications, with the majority published in the last three years. Besides the availability of data and a high motivation from the medical perspective, the availability of powerful graphics processing units exhibits an accelerator in this field. In this paper, we provide an overview of widely and effectively used concepts of used deep multiple instance learning approaches, recent advances and also critically discuss remaining challenges and future potential.

15 May 2025
Many multi-variate time series obtained in the natural sciences and
engineering possess a repetitive behavior, as for instance state-space
trajectories of industrial machines in discrete automation. Recovering the
times of recurrence from such a multi-variate time series is of a fundamental
importance for many monitoring and control tasks. For a periodic time series
this is equivalent to determining its period length. In this work we present a
persistent homology framework to estimate recurrence times in multi-variate
time series with different generalizations of cyclic behavior (periodic,
repetitive, and recurring). To this end, we provide three specialized methods
within our framework that are provably stable and validate them using
real-world data, including a new benchmark dataset from an injection molding
machine.

20 Jul 2024
Medical imaging is vital in computer assisted intervention. Particularly cone beam computed tomography (CBCT) with defacto real time and mobility capabilities plays an important role. However, CBCT images often suffer from artifacts, which pose challenges for accurate interpretation, motivating research in advanced algorithms for more effective use in clinical practice.
In this work we present CBCTLiTS, a synthetically generated, labelled CBCT dataset for segmentation with paired and aligned, high quality computed tomography data. The CBCT data is provided in 5 different levels of quality, reaching from a large number of projections with high visual quality and mild artifacts to a small number of projections with severe artifacts. This allows thorough investigations with the quality as a degree of freedom. We also provide baselines for several possible research scenarios like uni- and multimodal segmentation, multitask learning and style transfer followed by segmentation of relatively simple, liver to complex liver tumor segmentation. CBCTLiTS is accesssible via this https URL.

02 Jun 2023
This paper presents a comparison between two well-known deep Reinforcement Learning (RL) algorithms: Deep Q-Learning (DQN) and Proximal Policy Optimization (PPO) in a simulated production system. We utilize a Petri Net (PN)-based simulation environment, which was previously proposed in related work. The performance of the two algorithms is compared based on several evaluation metrics, including average percentage of correctly assembled and sorted products, average episode length, and percentage of successful episodes. The results show that PPO outperforms DQN in terms of all evaluation metrics. The study highlights the advantages of policy-based algorithms in problems with high-dimensional state and action spaces. The study contributes to the field of deep RL in context of production systems by providing insights into the effectiveness of different algorithms and their suitability for different tasks.

28 Oct 2024
Industrial Operational Technology (OT) systems are increasingly targeted by
cyber-attacks due to their integration with Information Technology (IT) systems
in the Industry 4.0 era. Besides intrusion detection systems, honeypots can
effectively detect these attacks. However, creating realistic honeypots for
brownfield systems is particularly challenging. This paper introduces a
generative model-based honeypot designed to mimic industrial OPC UA
communication. Utilizing a Long ShortTerm Memory (LSTM) network, the honeypot
learns the characteristics of a highly dynamic mechatronic system from recorded
state space trajectories. Our contributions are twofold: first, we present a
proof-of concept for a honeypot based on generative machine-learning models,
and second, we publish a dataset for a cyclic industrial process. The results
demonstrate that a generative model-based honeypot can feasibly replicate a
cyclic industrial process via OPC UA communication. In the short-term, the
generative model indicates a stable and plausible trajectory generation, while
deviations occur over extended periods. The proposed honeypot implementation
operates efficiently on constrained hardware, requiring low computational
resources. Future work will focus on improving model accuracy, interaction
capabilities, and extending the dataset for broader applications.

12 May 2025
Industrial automation increasingly demands energy-efficient control
strategies to balance performance with environmental and cost constraints. In
this work, we present a multi-objective reinforcement learning (MORL) framework
for energy-efficient control of the Quanser Aero 2 testbed in its
one-degree-of-freedom configuration. We design a composite reward function that
simultaneously penalizes tracking error and electrical power consumption.
Preliminary experiments explore the influence of varying the Energy penalty
weight, alpha, on the trade-off between pitch tracking and energy savings. Our
results reveal a marked performance shift for alpha values between 0.0 and
0.25, with non-Pareto optimal solutions emerging at lower alpha values, on both
the simulation and the real system. We hypothesize that these effects may be
attributed to artifacts introduced by the adaptive behavior of the Adam
optimizer, which could bias the learning process and favor bang-bang control
strategies. Future work will focus on automating alpha selection through
Gaussian Process-based Pareto front modeling and transitioning the approach
from simulation to real-world deployment.

14 May 2024
This paper proposes a framework for training Reinforcement Learning agents using Python in conjunction with Simulink models. Leveraging Python's superior customization options and popular libraries like Stable Baselines3, we aim to bridge the gap between the established Simulink environment and the flexibility of Python for training bleeding edge agents. Our approach is demonstrated on the Quanser Aero 2, a versatile dual-rotor helicopter. We show that policies trained on Simulink models can be seamlessly transferred to the real system, enabling efficient development and deployment of Reinforcement Learning agents for control tasks. Through systematic integration steps, including C-code generation from Simulink, DLL compilation, and Python interface development, we establish a robust framework for training agents on Simulink models. Experimental results demonstrate the effectiveness of our approach, surpassing previous efforts and highlighting the potential of combining Simulink with Python for Reinforcement Learning research and applications.

18 Apr 2025
The Hough transform is a popular and classical technique in computer vision
for the detection of lines (or more general objects). It maps a pixel into a
dual space -- the Hough space: each pixel is mapped to the set of lines through
this pixel, which forms a curve in Hough space. The detection of lines then
becomes a voting process to find those lines that received many votes by
pixels. However, this voting is done by thresholding, which is susceptible to
noise and other artifacts.
In this work, we present an alternative voting technique to detect peaks in
the Hough space based on persistent homology, which very naturally addresses
limitations of simple thresholding. Experiments on synthetic data show that our
method significantly outperforms the original method, while also demonstrating
enhanced robustness.
This work seeks to inspire future research in two key directions. First, we
highlight the untapped potential of Topological Data Analysis techniques and
advocate for their broader integration into existing methods, including
well-established ones. Secondly, we initiate a discussion on the mathematical
stability of the Hough transform, encouraging exploration of mathematically
grounded improvements to enhance its robustness.

09 Jan 2025
Document layout understanding is a field of study that analyzes the spatial arrangement of information in a document hoping to understand its structure and layout. Models such as LayoutLM (and its subsequent iterations) can understand semi-structured documents with SotA results; however, the lack of open semi-structured data is a limitation in itself. While semi-structured data is common in everyday life (balance sheets, purchase orders, receipts), there is a lack of public datasets for training machine learning models for this type of document. In this investigation we propose a method to generate new, synthetic, layout information that can help overcoming this data shortage. According to our results, the proposed method performs better than LayoutTransformer, another popular layout generation method. We also show that, in some scenarios, text classification can improve when supported by bounding box information.

02 Dec 2024
The increasing digitization of medical imaging enables machine learning based improvements in detecting, visualizing and segmenting lesions, easing the workload for medical experts. However, supervised machine learning requires reliable labelled data, which is is often difficult or impossible to collect or at least time consuming and thereby costly. Therefore methods requiring only partly labeled data (semi-supervised) or no labeling at all (unsupervised methods) have been applied more regularly. Anomaly detection is one possible methodology that is able to leverage semi-supervised and unsupervised methods to handle medical imaging tasks like classification and segmentation. This paper uses a semi-exhaustive literature review of relevant anomaly detection papers in medical imaging to cluster into applications, highlight important results, establish lessons learned and give further advice on how to approach anomaly detection in medical imaging. The qualitative analysis is based on google scholar and 4 different search terms, resulting in 120 different analysed papers. The main results showed that the current research is mostly motivated by reducing the need for labelled data. Also, the successful and substantial amount of research in the brain MRI domain shows the potential for applications in further domains like OCT and chest X-ray.
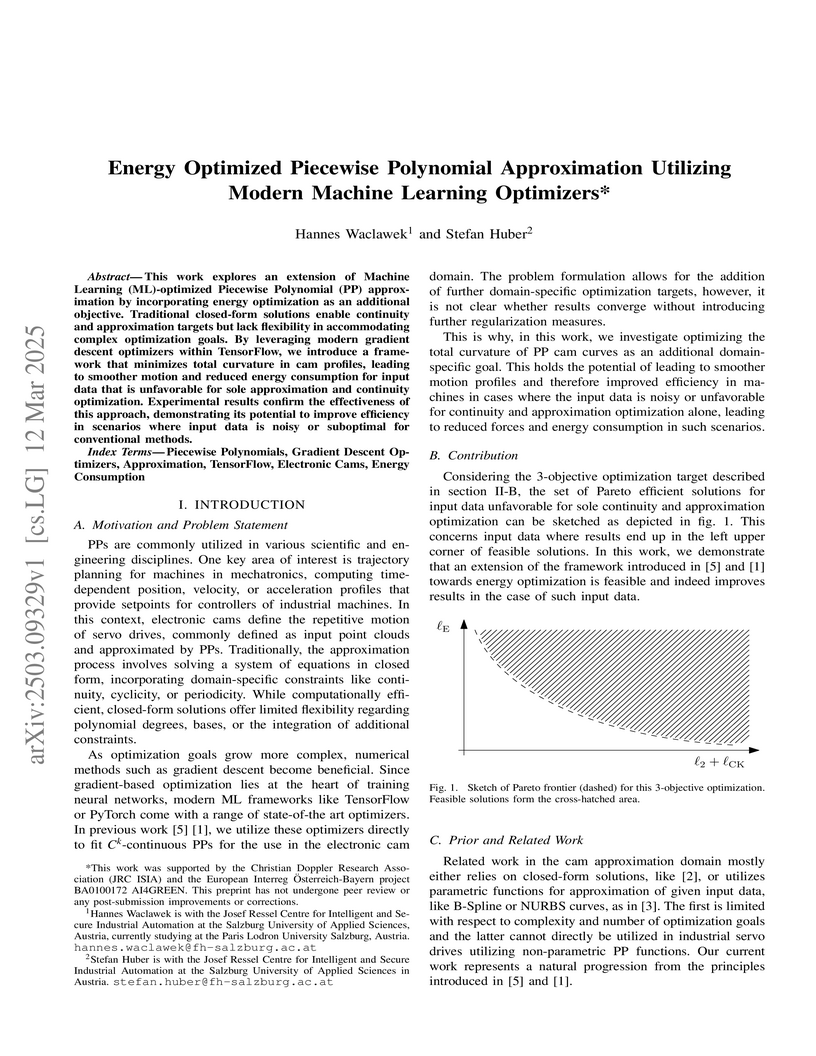
12 Mar 2025
This work explores an extension of ML-optimized piecewise polynomial
approximation by incorporating energy optimization as an additional objective.
Traditional closed-form solutions enable continuity and approximation targets
but lack flexibility in accommodating complex optimization goals. By leveraging
modern gradient descent optimizers within TensorFlow, we introduce a framework
that minimizes total curvature in cam profiles, leading to smoother motion and
reduced energy consumption for input data that is unfavorable for sole
approximation and continuity optimization. Experimental results confirm the
effectiveness of this approach, demonstrating its potential to improve
efficiency in scenarios where input data is noisy or suboptimal for
conventional methods.

26 Jul 2025
Automated breast cancer classification from mammography remains a significant challenge due to subtle distinctions between benign and malignant tissue. In this work, we present a hybrid framework combining deep convolutional features from a ResNet-50 backbone with handcrafted descriptors and transformer-based embeddings. Using the CBIS-DDSM dataset, we benchmark our ResNet-50 baseline (AUC: 78.1%) and demonstrate that fusing handcrafted features with deep ResNet-50 and DINOv2 features improves AUC to 79.6% (setup d1), with a peak recall of 80.5% (setup d1) and highest F1 score of 67.4% (setup d1). Our experiments show that handcrafted features not only complement deep representations but also enhance performance beyond transformer-based embeddings. This hybrid fusion approach achieves results comparable to state-of-the-art methods while maintaining architectural simplicity and computational efficiency, making it a practical and effective solution for clinical decision support.

03 Dec 2024
Computer-Assisted Interventions enable clinicians to perform precise,
minimally invasive procedures, often relying on advanced imaging methods.
Cone-beam computed tomography (CBCT) can be used to facilitate
computer-assisted interventions, despite often suffering from artifacts that
pose challenges for accurate interpretation. While the degraded image quality
can affect image analysis, the availability of high quality, preoperative scans
offers potential for improvements. Here we consider a setting where
preoperative CT and intraoperative CBCT scans are available, however, the
alignment (registration) between the scans is imperfect to simulate a real
world scenario. We propose a multimodal learning method that fuses roughly
aligned CBCT and CT scans and investigate the effect on segmentation
performance. For this experiment we use synthetically generated data containing
real CT and synthetic CBCT volumes with corresponding voxel annotations. We
show that this fusion setup improves segmentation performance in out of
investigated setups.

02 Dec 2024
Thyroid cancer is currently the fifth most common malignancy diagnosed in women. Since differentiation of cancer sub-types is important for treatment and current, manual methods are time consuming and subjective, automatic computer-aided differentiation of cancer types is crucial. Manual differentiation of thyroid cancer is based on tissue sections, analysed by pathologists using histological features. Due to the enormous size of gigapixel whole slide images, holistic classification using deep learning methods is not feasible. Patch based multiple instance learning approaches, combined with aggregations such as bag-of-words, is a common approach. This work's contribution is to extend a patch based state-of-the-art method by generating and combining feature vectors of three different patch resolutions and analysing three distinct ways of combining them. The results showed improvements in one of the three multi-scale approaches, while the others led to decreased scores. This provides motivation for analysis and discussion of the individual approaches.

26 Mar 2025
Reinforcement Learning (RL) offers promising solutions for control tasks in
industrial cyber-physical systems (ICPSs), yet its real-world adoption remains
limited. This paper demonstrates how seemingly small but well-designed
modifications to the RL problem formulation can substantially improve
performance, stability, and sample efficiency. We identify and investigate key
elements of RL problem formulation and show that these enhance both learning
speed and final policy quality. Our experiments use a one-degree-of-freedom
(1-DoF) helicopter testbed, the Quanser Aero~2, which features non-linear
dynamics representative of many industrial settings. In simulation, the
proposed problem design principles yield more reliable and efficient training,
and we further validate these results by training the agent directly on
physical hardware. The encouraging real-world outcomes highlight the potential
of RL for ICPS, especially when careful attention is paid to the design
principles of problem formulation. Overall, our study underscores the crucial
role of thoughtful problem formulation in bridging the gap between RL research
and the demands of real-world industrial systems.

10 Jun 2025
Cone-Beam Computed Tomography (CBCT) is widely used for real-time intraoperative imaging due to its low radiation dose and high acquisition speed. However, despite its high resolution, CBCT suffers from significant artifacts and thereby lower visual quality, compared to conventional Computed Tomography (CT). A recent approach to mitigate these artifacts is synthetic CT (sCT) generation, translating CBCT volumes into the CT domain. In this work, we enhance sCT generation through multimodal learning, integrating intraoperative CBCT with preoperative CT. Beyond validation on two real-world datasets, we use a versatile synthetic dataset, to analyze how CBCT-CT alignment and CBCT quality affect sCT quality. The results demonstrate that multimodal sCT consistently outperform unimodal baselines, with the most significant gains observed in well-aligned, low-quality CBCT-CT cases. Finally, we demonstrate that these findings are highly reproducible in real-world clinical datasets.

08 Jul 2025
Cone-Beam Computed Tomography (CBCT) is widely used for intraoperative imaging due to its rapid acquisition and low radiation dose. However, CBCT images typically suffer from artifacts and lower visual quality compared to conventional Computed Tomography (CT). A promising solution is synthetic CT (sCT) generation, where CBCT volumes are translated into the CT domain. In this work, we enhance sCT generation through multimodal learning by jointly leveraging intraoperative CBCT and preoperative CT data. To overcome the inherent misalignment between modalities, we introduce an end-to-end learnable registration module within the sCT pipeline. This model is evaluated on a controlled synthetic dataset, allowing precise manipulation of data quality and alignment parameters. Further, we validate its robustness and generalizability on two real-world clinical datasets. Experimental results demonstrate that integrating registration in multimodal sCT generation improves sCT quality, outperforming baseline multimodal methods in 79 out of 90 evaluation settings. Notably, the improvement is most significant in cases where CBCT quality is low and the preoperative CT is moderately misaligned.

02 Jun 2023
Industry 4.0 is driven by demands like shorter time-to-market, mass customization of products, and batch size one production. Reinforcement Learning (RL), a machine learning paradigm shown to possess a great potential in improving and surpassing human level performance in numerous complex tasks, allows coping with the mentioned demands. In this paper, we present an OPC UA based Operational Technology (OT)-aware RL architecture, which extends the standard RL setting, combining it with the setting of digital twins. Moreover, we define an OPC UA information model allowing for a generalized plug-and-play like approach for exchanging the RL agent used. In conclusion, we demonstrate and evaluate the architecture, by creating a proof of concept. By means of solving a toy example, we show that this architecture can be used to determine the optimal policy using a real control system.

15 Sep 2025
Image-based scene understanding allows Augmented Reality systems to provide contextual visual guidance in unprepared, real-world environments. While effective on video see-through (VST) head-mounted displays (HMDs), such methods suffer on optical see-through (OST) HMDs due to misregistration between the world-facing camera and the user's eye perspective. To approximate the user's true eye view, we implement and evaluate three software-based eye-perspective rendering (EPR) techniques on a commercially available, untethered OST HMD (Microsoft HoloLens 2): (1) Plane-Proxy EPR, projecting onto a fixed-distance plane; (2) Mesh-Proxy EPR, using SLAM-based reconstruction for projection; and (3) Gaze-Proxy EPR, a novel eye-tracking-based method that aligns the projection with the user's gaze depth. A user study on real-world tasks underscores the importance of accurate EPR and demonstrates gaze-proxy as a lightweight alternative to geometry-based methods. We release our EPR framework as open source.
There are no more papers matching your filters at the moment.
