Ask or search anything...
 University of Toronto
University of Toronto Chinese Academy of Sciences
Chinese Academy of Sciences
 Sun Yat-Sen University
Sun Yat-Sen UniversityResearchers from Nanyang Technological University, Sun Yat-Sen University, and South China University of Technology developed a general-purpose 3D Vision-Language Pre-training framework that leverages 3D scene graphs to achieve multi-level alignment between 3D scenes and natural language. The framework establishes state-of-the-art or competitive performance across 3D visual grounding, question answering, and dense captioning tasks.
View blog
Researchers from Sun Yat-sen University developed -optimal polynomial-time algorithms for entanglement purification scheduling and fidelity-constrained multi-flow routing in quantum networks. Their framework, incorporating dynamic programming and graph theory, achieves superior fidelity and lower path costs compared to existing methods, establishing theoretical conditions for optimal purification strategies.
View blog
 National University of Singapore
National University of SingaporeResearchers at Sun Yat-sen University and collaborators introduce Continuous Scaling Attention (CSAttn), an attention-only Transformer block that achieves state-of-the-art performance across multiple image restoration tasks without relying on Feed-Forward Networks. The architecture demonstrates substantial improvements, including a 0.41 dB PSNR increase in image deraining and a 4.22 dB PSNR gain in low-light image enhancement, while maintaining competitive model efficiency.
View blog

 Google DeepMind
Google DeepMindResearchers from The Hong Kong Polytechnic University, Dartmouth College, Max Planck Institute, Google DeepMind, and others developed Prophet, a training-free adaptive decoding paradigm for Diffusion Language Models (DLMs) that leverages early answer convergence. The method achieves up to 3.4 times faster inference by dynamically committing to answers when model confidence is high, often improving output quality compared to full-step decoding.
View blog

MemoryBank introduces a novel long-term memory mechanism for Large Language Models, enabling them to retain and recall information across extended interactions by simulating human-like forgetting and reinforcement. The system, demonstrated through the SiliconFriend chatbot, significantly enhances contextual understanding, personalizes user interactions through dynamic user portraits, and provides empathetic responses, showing strong performance across various LLMs in both qualitative and quantitative evaluations.
View blog
The MemAct framework enables Large Language Model agents to autonomously manage their working memory by treating context curation as learnable actions, addressing a critical bottleneck in long-horizon tasks. This approach achieves 59.1% accuracy on multi-objective QA while reducing average context tokens to 3,447, outperforming larger baselines and improving training efficiency by up to 40%.
View blog
 Northeastern University
Northeastern UniversityRoboTwin 2.0 introduces a scalable simulation framework and benchmark designed to generate high-quality, domain-randomized data for robust bimanual robotic manipulation, addressing limitations in existing synthetic datasets. Policies trained with RoboTwin 2.0 data achieved a 24.4% improvement in real-world success rates for few-shot learning and 21.0% for zero-shot generalization on unseen backgrounds.
View blog

 Alibaba Group
Alibaba GroupSearch Self-play (SSP) is a novel self-supervised framework enabling Large Language Model agents to autonomously generate, verify, and solve complex deep search tasks. The method consistently improves agent performance across seven question-answering benchmarks, yielding an average of 26.4 points improvement for base models and achieving state-of-the-art results on five benchmarks for larger models like Qwen2.5-32B-Instruct.
View blog
OmniVGGT, a 3D foundation model developed by researchers including those from HKUST and NTU, integrates an arbitrary number of geometric modalities like depth maps and camera parameters, resulting in superior performance across 3D perception tasks and improved spatial reasoning for robotic manipulation.
View blog
The WORLD-ENV framework enables effective post-training for Vision-Language-Action (VLA) models by utilizing a world model as a virtual environment and a VLM-guided 'instant reflector' for reward and dynamic task completion. This approach achieves an average task success rate of 79.6% on the LIBERO benchmark with only 5 expert demonstrations per task, exceeding supervised fine-tuning baselines.
View blog
Researchers from Nanyang Technological University and collaborators provide a comprehensive survey defining Agentic Multimodal Large Language Models (MLLMs), distinguishing them from earlier MLLM agents by their dynamic workflows and proactive behaviors. The survey establishes a three-dimensional framework covering internal intelligence, external tool invocation, and environment interaction, while also compiling open-source resources for the field.
View blog

An updated benchmark, VBench-2.0, provides a comprehensive and automatic suite for evaluating video generative models based on their intrinsic faithfulness, assessing adherence to real-world principles like physics, commonsense, and human anatomy. This framework, which leverages a hybrid approach of generalist and specialist AI models, demonstrates strong alignment with human preferences in evaluating generated video quality.
View blog

 University of Illinois at Urbana-Champaign
University of Illinois at Urbana-ChampaignThis research introduces Optimal Tool Call-controlled Policy Optimization (OTC-PO), an RL framework that enables Large Language Models (LLMs) to use external tools efficiently while maintaining answer correctness. The method reduces tool calls by up to 68.3% and boosts tool productivity by over 200% on search and code reasoning tasks across various benchmarks, effectively mitigating cognitive offloading in LLMs.
View blog

 Fudan University
Fudan UniversityResearchers from Soochow University, Microsoft, and other institutions developed OPENTHINKIMG, an open-source framework, and V-TOOLRL, a reinforcement learning method, enabling Large Vision-Language Models to adaptively use visual tools for complex reasoning tasks. This approach improved accuracy on chart reasoning by 29.83 points over baseline models and outperformed GPT-4.1, teaching agents to efficiently invoke tools with visual feedback.
View blog
LLMDet, from Sun Yat-sen University and Alibaba Group, leverages Large Language Models to provide rich, detailed image-level and region-level captions, improving open-vocabulary object detection performance, particularly for rare categories. The approach also demonstrates mutual benefits, enhancing large multi-modal models when integrated as a vision foundation.
View blog

 ETH Zurich
ETH ZurichTREERPO enhances Large Language Model reasoning by employing a novel tree sampling mechanism to generate fine-grained, step-level reward signals without requiring a separate process reward model. This method improves Pass@1 accuracy by up to 16.5% for Qwen2.5-Math-1.5B and reduces average response length by 18.1% compared to GRPO.
View blog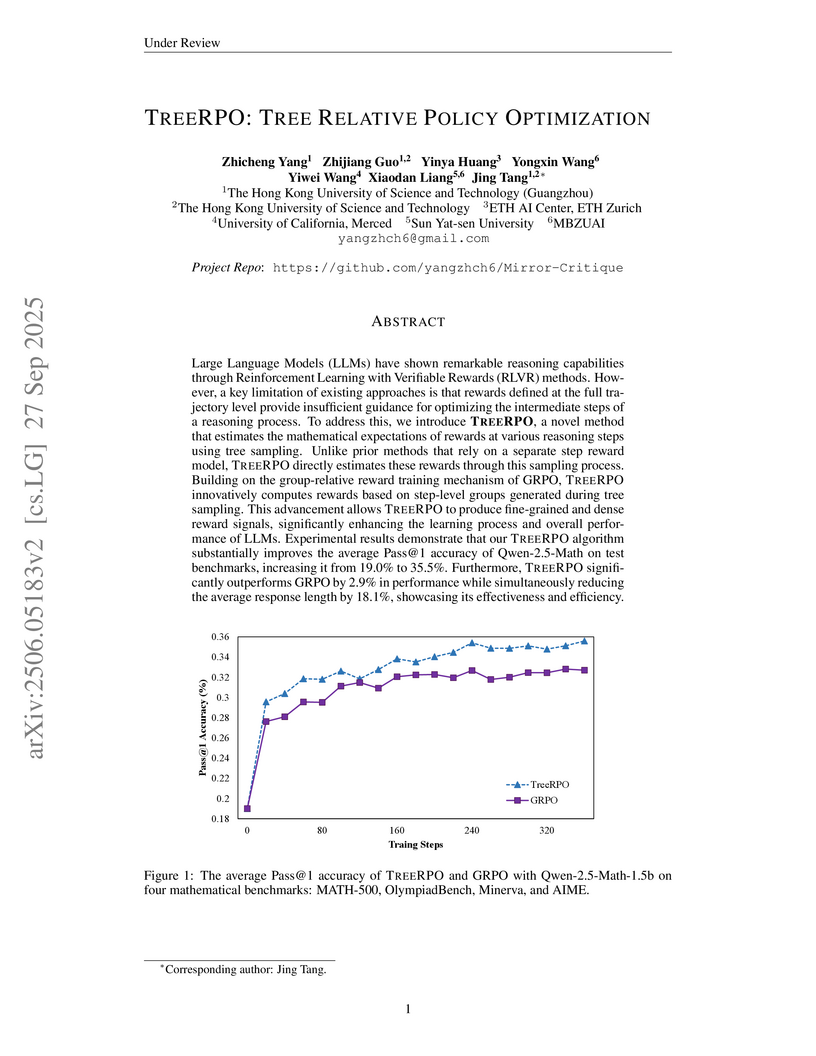
This survey paper meticulously reviews the current state and future trajectories of Embodied Artificial Intelligence, specifically focusing on the integration of Multi-modal Large Models and World Models. It systematically categorizes advancements across robots, simulators, perception, interaction, agent architectures, and sim-to-real adaptation, while introducing the ARIO (All Robots In One) dataset standard to foster the development of general-purpose embodied agents.
View blog
Researchers from The University of Hong Kong and collaborators introduced MMOral, the first large-scale multimodal instruction dataset and benchmark specifically for panoramic X-ray interpretation. Their fine-tuned OralGPT model demonstrated a 24.73% performance improvement on the MMOral-Bench, highlighting the need for domain-specific AI in dentistry as even leading general LVLMs like GPT-4o achieved only 41.45% accuracy.
View blog