
27 Nov 2024


Researchers from Nanyang Technological University, Sun Yat-Sen University, and South China University of Technology developed a general-purpose 3D Vision-Language Pre-training framework that leverages 3D scene graphs to achieve multi-level alignment between 3D scenes and natural language. The framework establishes state-of-the-art or competitive performance across 3D visual grounding, question answering, and dense captioning tasks.

02 Dec 2024


Researchers propose a 6DMA-aided cell-free massive MIMO system that optimizes antenna rotation angles to maximize the average achievable sum-rate by adapting to long-term user spatial distributions. The system demonstrates superior performance over fixed-antenna setups and provides distinct optimal 6DMA orientations for different receiver combining strategies.

18 Oct 2025
South China University of Technology California Institute of Technology
California Institute of Technology University of Cambridge
University of Cambridge Monash UniversityShanghai Artificial Intelligence Laboratory
Monash UniversityShanghai Artificial Intelligence Laboratory Chinese Academy of Sciences
Chinese Academy of Sciences University College London
University College London Fudan University
Fudan University Shanghai Jiao Tong University
Shanghai Jiao Tong University Nanjing University
Nanjing University Stanford University
Stanford University The Chinese University of Hong Kong
The Chinese University of Hong Kong The Hong Kong Polytechnic UniversityThe Chinese University of Hong Kong, Shenzhen
The Hong Kong Polytechnic UniversityThe Chinese University of Hong Kong, Shenzhen The University of Hong KongMBZUAI
The University of Hong KongMBZUAI Purdue University
Purdue University Virginia Tech
Virginia Tech HKUSTUniversity College DublinUNC-Chapel HillFuzhou UniversityNorth University of ChinaChina Pharmaceutical UniversityBeijing Institute of Heart, Lung and Blood Vessel Diseases
HKUSTUniversity College DublinUNC-Chapel HillFuzhou UniversityNorth University of ChinaChina Pharmaceutical UniversityBeijing Institute of Heart, Lung and Blood Vessel Diseases
California Institute of TechnologyUniversity of CambridgeMonash UniversityShanghai Artificial Intelligence LaboratoryChinese Academy of SciencesUniversity College LondonFudan UniversityShanghai Jiao Tong UniversityNanjing UniversityStanford UniversityThe Chinese University of Hong KongThe Hong Kong Polytechnic UniversityThe Chinese University of Hong Kong, ShenzhenThe University of Hong KongMBZUAIPurdue UniversityVirginia TechHKUSTUniversity College DublinUNC-Chapel HillFuzhou UniversityNorth University of ChinaChina Pharmaceutical UniversityBeijing Institute of Heart, Lung and Blood Vessel Diseases
A comprehensive survey by researchers from Shanghai AI Lab and various global institutions outlines the intricate relationship between scientific large language models (Sci-LLMs) and their data foundations, tracing their evolution towards autonomous agents for scientific discovery. The paper establishes a taxonomy for scientific data and knowledge, meticulously reviews over 270 datasets and 190 benchmarks, and identifies critical data challenges alongside future paradigms.

25 Jun 2025



This survey provides a comprehensive analysis of 'reasoning Large Language Models,' detailing their transition from intuitive 'System 1' to deliberate 'System 2' thinking. It maps the foundational technologies, core construction methods, and evaluation benchmarks, highlighting their enhanced performance in complex tasks like mathematics and coding while also identifying current limitations and future research directions.

02 Oct 2025
Patch-as-Decodable Token (PaDT) unifies multimodal Large Language Models by enabling direct generation of both textual and diverse visual outputs, such as bounding boxes and segmentation masks. This approach achieves state-of-the-art performance across fine-grained vision tasks, with smaller PaDT models surpassing much larger existing MLLMs.
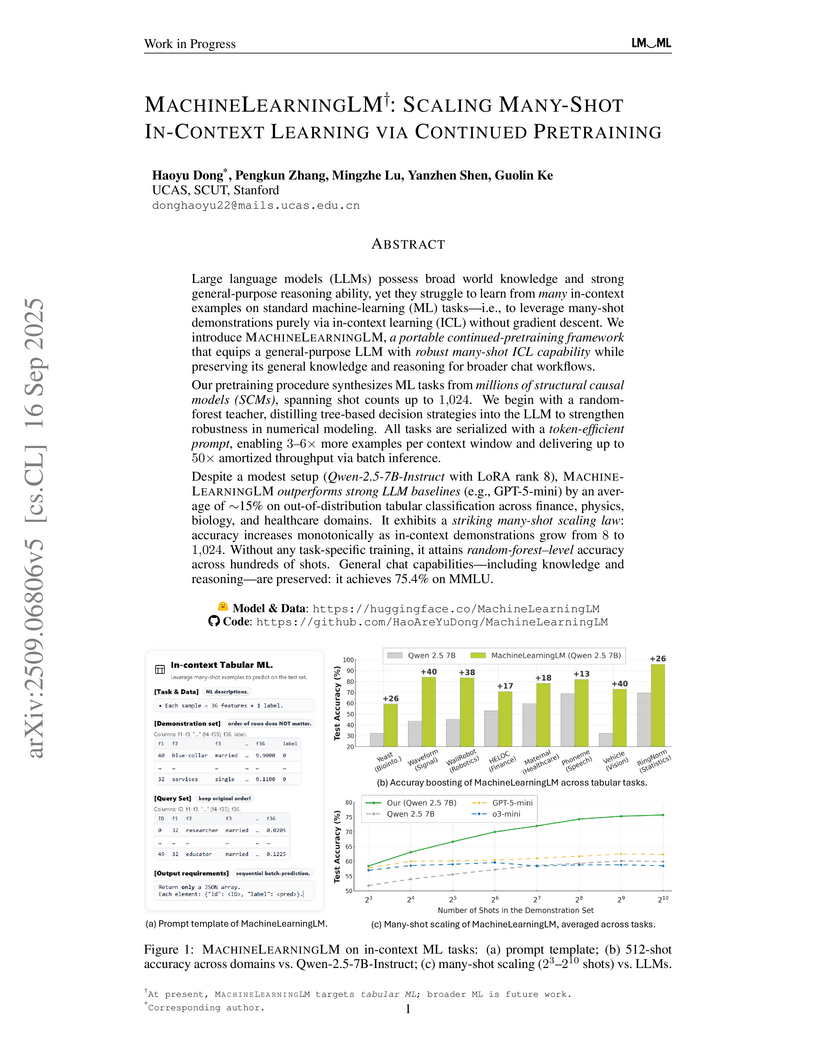
16 Sep 2025

Large language models (LLMs) possess broad world knowledge and strong general-purpose reasoning ability, yet they struggle to learn from many in-context examples on standard machine learning (ML) tasks, that is, to leverage many-shot demonstrations purely via in-context learning (ICL) without gradient descent. We introduce MachineLearningLM, a portable continued-pretraining framework that equips a general-purpose LLM with robust in-context ML capability while preserving its general knowledge and reasoning for broader chat workflows.
Our pretraining procedure synthesizes ML tasks from millions of structural causal models (SCMs), spanning shot counts up to 1,024. We begin with a random-forest teacher, distilling tree-based decision strategies into the LLM to strengthen robustness in numerical modeling. All tasks are serialized with a token-efficient prompt, enabling 3x to 6x more examples per context window and delivering up to 50x amortized throughput via batch inference.
Despite a modest setup (Qwen-2.5-7B-Instruct with LoRA rank 8), MachineLearningLM outperforms strong LLM baselines (e.g., GPT-5-mini) by an average of about 15% on out-of-distribution tabular classification across finance, physics, biology, and healthcare domains. It exhibits a striking many-shot scaling law: accuracy increases monotonically as in-context demonstrations grow from 8 to 1,024. Without any task-specific training, it attains random-forest-level accuracy across hundreds of shots. General chat capabilities, including knowledge and reasoning, are preserved: it achieves 75.4% on MMLU.

21 Aug 2025
South China University of TechnologyChinese Academy of Sciences University of Science and Technology of ChinaShanghai AI LabShenzhen UniversityHarbin Institute of Technology (Shenzhen)Shanghai University of Electric Power
University of Science and Technology of ChinaShanghai AI LabShenzhen UniversityHarbin Institute of Technology (Shenzhen)Shanghai University of Electric Power Southern University of Science and TechnologyShenzhen MSU-BIT UniversityShenzhen University of Advanced TechnologyShenzhen Key Laboratory for High Performance Data Mining, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences
Southern University of Science and TechnologyShenzhen MSU-BIT UniversityShenzhen University of Advanced TechnologyShenzhen Key Laboratory for High Performance Data Mining, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences
Chinese Academy of SciencesUniversity of Science and Technology of ChinaShanghai AI LabShenzhen UniversityHarbin Institute of Technology (Shenzhen)Shanghai University of Electric PowerSouthern University of Science and TechnologyShenzhen MSU-BIT UniversityShenzhen University of Advanced TechnologyShenzhen Key Laboratory for High Performance Data Mining, Shenzhen Institutes of Advanced Technology, Chinese Academy of SciencesResearchers from a consortium of Chinese institutions systematically surveyed 283 Large Language Model benchmarks, categorizing them into a three-tiered taxonomy. The work identifies critical issues like data contamination and cultural bias, while proposing a design paradigm for more robust and fair future evaluations.

14 Mar 2024



3D-VLA introduces a generative world model that integrates 3D scene understanding with language and action generation, enabling embodied AI systems to predict future states and plan actions in 3D environments. It leverages a new 3D embodied instruction dataset and demonstrates improved performance in 3D reasoning, goal generation, and action planning compared to 2D vision-language models.

02 Nov 2025
This work provides a comprehensive survey and taxonomy of multimodal spatial reasoning within large language models, addressing the scarcity of systematic reviews and standardized benchmarks. It analyzes diverse approaches for enhancing spatial intelligence in MLLMs and introduces open benchmarks to facilitate rigorous evaluation and comparison across various tasks and modalities.

05 Jun 2025




OCRBench v2 offers an improved benchmark for evaluating Large Multimodal Models (LMMs) on visual text localization and reasoning. It presents 23 tasks across 31 diverse scenarios with 10,000 human-validated instruction-response pairs and a private test set, revealing that current LMMs perform poorly on fine-grained spatial perception, complex layout understanding, and structured element parsing tasks, despite advances in basic text recognition.

18 Nov 2025
The Mixture-of-Memories (MoM) architecture replaces a single recurrent state with multiple, independent memory states and a routing mechanism, enhancing linear sequence models' ability to retain information over long sequences. This design enables performance on recall-intensive tasks comparable to Transformer models while maintaining linear time complexity during training and constant time inference.

13 Jan 2025

This paper provides a comprehensive survey of lifelong learning methods for LLM-based agents, focusing on how these agents can continuously learn and adapt through perception, memory, and action modules.

12 Apr 2025

Researchers from Peking University and South China University of Technology developed FakeShield, a framework that uses multi-modal large language models for explainable and generalized image forgery detection and localization. This system not only detects and precisely localizes image manipulations but also provides human-understandable explanations for its judgments, achieving superior performance across diverse tampering types.

24 Jul 2023

The 3D-LLM framework from a collaboration including MIT and UMass Amherst enables large language models to understand and reason about the 3D physical world. It achieves this by generating large-scale 3D-language data and deriving 3D features from multi-view 2D images, demonstrating improved performance across tasks like 3D question answering and object grounding compared to prior methods.

24 Apr 2025
Researchers from Peking University and collaborating institutions develop TimeChat-Online, a streaming video understanding framework that reduces visual token processing by 82.8% through differential token dropping while maintaining 98% performance on StreamingBench, enabling efficient real-time interaction with continuous video streams.

04 Apr 2025

3D-Mem introduces a scalable 3D scene memory framework for embodied agents, leveraging multi-view image "Memory Snapshots" for explored regions and "Frontier Snapshots" for unexplored areas. This enables efficient lifelong exploration and enhanced spatial reasoning, outperforming baselines in various embodied question answering and navigation tasks by effectively integrating with Vision-Language Models.

09 Oct 2025
Researchers at South China University of Technology and collaborators introduced NSG-VD, a physics-driven method utilizing a Normalized Spatiotemporal Gradient (NSG) and Maximum Mean Discrepancy, to detect AI-generated videos by identifying violations of physical continuity. The approach achieves superior detection performance on advanced generative models like Sora and demonstrates strong robustness in data-imbalanced settings.

27 May 2025

South China University of Technology and Pazhou Laboratory researchers develop TLM (Test-Time Learning for LLMs), a framework that adapts large language models to new domains during inference using only unlabeled test data through input perplexity minimization, achieving at least 20% performance improvements on domain knowledge adaptation tasks in their AdaptEval benchmark while employing LoRA-based parameter updates and a sample-efficient learning strategy that prioritizes high-perplexity examples to prevent catastrophic forgetting and reduce computational overhead compared to traditional fine-tuning approaches.

01 Aug 2025
CorrCLIP introduces a framework to enhance CLIP's performance for open-vocabulary semantic segmentation by reconstructing patch correlations, specifically addressing inter-class incoherence. The method achieved state-of-the-art performance among training-free approaches, improving averaged mIoU by up to 8.5% on various benchmarks and often surpassing weakly-supervised models.

30 May 2025
LifelongAgentBench introduces the first unified benchmark to evaluate large language model agents as lifelong learners across Database, Operating System, and Knowledge Graph environments. The benchmark demonstrates that experience replay consistently improves agent performance (e.g., 19% to 78% accuracy in DB tasks) but is limited by context length, leading to the development of group self-consistency which drastically reduces token usage (e.g., 56,409 to 11,002 tokens) while maintaining effectiveness.
There are no more papers matching your filters at the moment.
