
16 Sep 2025
Astronomical Institute of Slovak Academy of SciencesUniversity of Edinburgh University of Maryland, College ParkUniversidad Diego PortalesTechnische Universität BraunschweigMain Astronomical Observatory of the National Academy of Sciences of UkraineMax Planck Institute for Solar System ResearchTaras Shevchenko National University of Kyiv
University of Maryland, College ParkUniversidad Diego PortalesTechnische Universität BraunschweigMain Astronomical Observatory of the National Academy of Sciences of UkraineMax Planck Institute for Solar System ResearchTaras Shevchenko National University of Kyiv
University of Maryland, College ParkUniversidad Diego PortalesTechnische Universität BraunschweigMain Astronomical Observatory of the National Academy of Sciences of UkraineMax Planck Institute for Solar System ResearchTaras Shevchenko National University of KyivWe present observations of comet 67P/Churyumov-Gerasimenko during its 2021/22 apparition, aiming to investigate its dust and gas environment and compare the results with those obtained in 2015/16 using the same telescope. Quasi-simultaneous photometric, spectroscopic, and polarimetric observations were carried out at the 6-m BTA SAO telescope. The comet was observed on 6 October 2021, 31 days before perihelion, with \textit{g}-SDSS and \textit{r}-SDSS filters, and on 6 February 2022, 96 days after perihelion, using narrowband cometary filters: BC (~Å), RC (~Å), and CN (~Å). These were complemented by images from the 2-m Liverpool Telescope (La Palma). On 6 October 2021, a sunward jet and long dust tail were detected. By 6 February 2022, the dust coma morphology had changed noticeably, revealing a bright sunward neckline structure superimposed on the projected dust tail, along with two jets at position angles of 133 and 193. Spectra showed strong CN emission, with relatively weak C, C and NH emissions. The dust production rate did not exceed 200~cm (uncorrected for phase angle) in both epochs. An unusual CN coma morphology was observed, with evidence of an additional CN source associated with dust jets. Geometric modeling of the jets' dynamics indicated an active area at latitude with a jet opening angle of on 6 October 2021, and two active areas at latitudes and , separated by longitude , producing the observed jets on 6 February 2022. The average particle velocity in the jets was about ~km~s.

19 Aug 2025





Researchers, including those from Shanghai Jiao Tong University and Carnegie Mellon University, demonstrated that carefully curated, smaller datasets for speech enhancement consistently outperform larger, uncurated ones, particularly in improving perceptual quality. The study, motivated by observations from the URGENT 2025 challenge, found that a 700-hour quality-filtered subset yielded better non-intrusive metric scores than a 2,500-hour uncurated dataset, and a 100-hour top-ranked subset even surpassed the full 2,500-hour set in some perceptual evaluations.

02 Jun 2025
There has been a growing effort to develop universal speech enhancement (SE)
to handle inputs with various speech distortions and recording conditions. The
URGENT Challenge series aims to foster such universal SE by embracing a broad
range of distortion types, increasing data diversity, and incorporating
extensive evaluation metrics. This work introduces the Interspeech 2025 URGENT
Challenge, the second edition of the series, to explore several aspects that
have received limited attention so far: language dependency, universality for
more distortion types, data scalability, and the effectiveness of using noisy
training data. We received 32 submissions, where the best system uses a
discriminative model, while most other competitive ones are hybrid methods.
Analysis reveals some key findings: (i) some generative or hybrid approaches
are preferred in subjective evaluations over the top discriminative model, and
(ii) purely generative SE models can exhibit language dependency.

22 Sep 2025

We examine the first three BepiColombo Mercury flybys Using data from the Miniature Ion Precipitation Analyzer (MIPA), an ion mass analyzer in the Search for Exospheric Refilling and Natural Abundances (SERENA) package on the Mercury Planetary Orbiter (MPO) designed to study magnetospheric dynamics. These flybys all passed from dusk to dawn through the nightside equatorial region but were noticeably different from each other. In the first flyby, we observe a low latitude boundary layer and 1 keV ions near closest approach. For flybys 2 and 3 we see ions up to 14 keV in the same location, including freshly injected precipitating ions inside the loss cone. High time resolution data from flyby 3 show variations consistent with bursty bulk flows 10s long and occurring over s periods, the first such observation in this region. MIPA data demonstrate that high-energy injection processes are an important source of precipitation ions at Mercury.

03 Feb 2025
Modeling plays a critical role in additive manufacturing (AM), enabling a deeper understanding of underlying processes. Parametric solutions for such models are of great importance, enabling the optimization of production processes and considerable cost reductions. However, the complexity of the problem and diversity of spatio-temporal scales involved in the process pose significant challenges for traditional numerical methods. Surrogate models offer a powerful alternative by accelerating simulations and facilitating real-time monitoring and control. The present study presents an operator learning approach that relies on the deep operator network (DeepONet) and physics-informed neural networks (PINN) to predict the three-dimensional temperature distribution during melting and consolidation in laser powder bed fusion (LPBF). Parametric solutions for both single-track and multi-track scenarios with respect to tool path are obtained. To address the challenges in obtaining parametric solutions for multi-track scenarios using DeepONet architecture, a sequential PINN approach is proposed to efficiently manage the increased training complexity inherent in those scenarios. The accuracy and consistency of the model are verified against finite-difference computations. The developed surrogate allows us to efficiently analyze the effect of scanning paths and laser parameters on the thermal history.

08 Nov 2024
Researchers developed DiffBatt, a denoising diffusion model designed for both predicting battery degradation and synthesizing degradation curves. The model achieved a mean RMSE of 196 cycles for Remaining Useful Life (RUL) prediction across diverse datasets, outperforming existing benchmarks, and generated high-quality synthetic data that enhanced the accuracy of downstream machine learning models.

30 Mar 2025
Transformer architectures prominently lead single-image super-resolution
(SISR) benchmarks, reconstructing high-resolution (HR) images from their
low-resolution (LR) counterparts. Their strong representative power, however,
comes with a higher demand for training data compared to convolutional neural
networks (CNNs). For many real-world SR applications, the availability of
high-quality HR training images is not given, sparking interest in LR-only
training methods. The LR-only SISR benchmark mimics this condition by allowing
only low-resolution (LR) images for model training. For a 4x super-resolution,
this effectively reduces the amount of available training data to 6.25% of the
HR image pixels, which puts the employment of a data-hungry transformer model
into question. In this work, we are the first to utilize a lightweight vision
transformer model with LR-only training methods addressing the unsupervised
SISR LR-only benchmark. We adopt and configure a recent LR-only training method
from microscopy image super-resolution to macroscopic real-world data,
resulting in our multi-scale training method for bicubic degradation (MSTbic).
Furthermore, we compare it with reference methods and prove its effectiveness
both for a transformer and a CNN model. We evaluate on the classic SR benchmark
datasets Set5, Set14, BSD100, Urban100, and Manga109, and show superior
performance over state-of-the-art (so far: CNN-based) LR-only SISR methods. The
code is available on GitHub:
this https URL
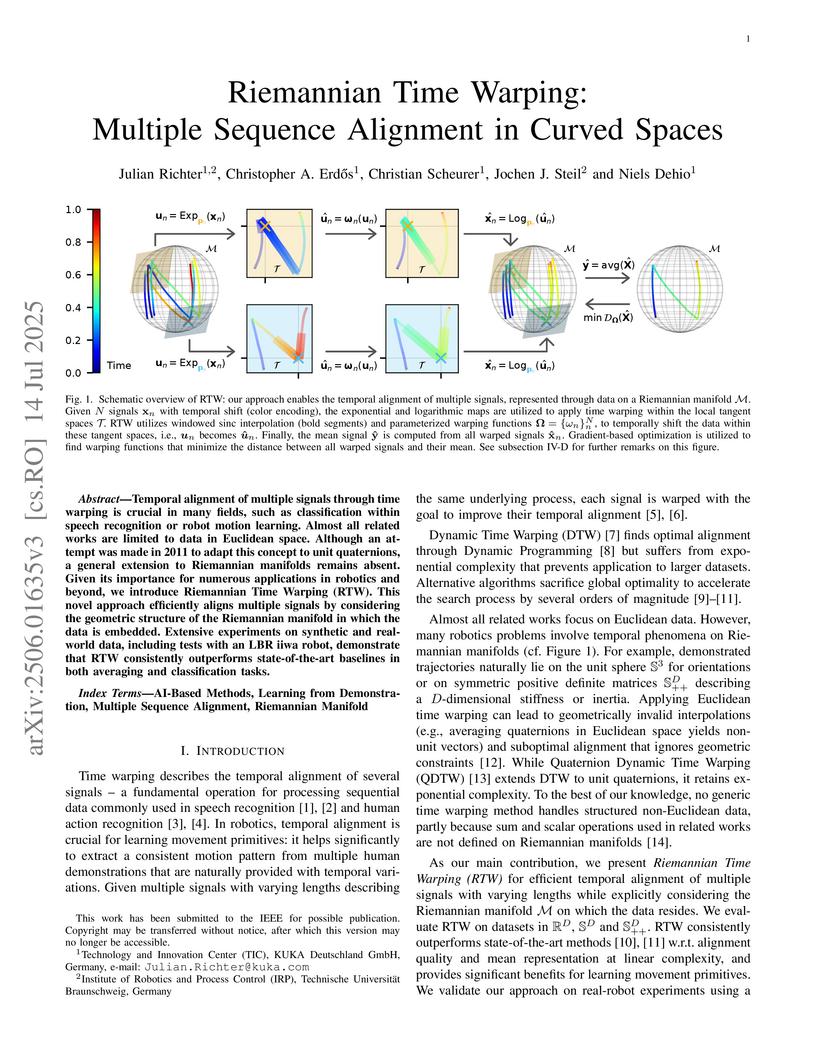
14 Jul 2025
Temporal alignment of multiple signals through time warping is crucial in many fields, such as classification within speech recognition or robot motion learning. Almost all related works are limited to data in Euclidean space. Although an attempt was made in 2011 to adapt this concept to unit quaternions, a general extension to Riemannian manifolds remains absent. Given its importance for numerous applications in robotics and beyond, we introduce Riemannian Time Warping (RTW). This novel approach efficiently aligns multiple signals by considering the geometric structure of the Riemannian manifold in which the data is embedded. Extensive experiments on synthetic and real-world data, including tests with an LBR iiwa robot, demonstrate that RTW consistently outperforms state-of-the-art baselines in both averaging and classification tasks.

30 Oct 2025
In this paper, we aim to study the information-theoretical limits of oblivious transfer. This work also investigates the problem of oblivious transfer over a noisy multiple access channel involving two non-colluding senders and a single receiver. The channel model is characterized by correlations among the parties, with the parties assumed to be either honest-but-curious or, in the receiver's case, potentially malicious. At first, we study the information-theoretical limits of oblivious transfer between two parties and extend it to the multiple access channel model. We propose a multiparty protocol for honest-but-curious parties where the general multiple access channel is reduced to a certain correlation. In scenarios where the receiver is malicious, the protocol achieves an achievable rate region.

20 Apr 2011
Higher-order recursion schemes are recursive equations defining new operations from given ones called "terminals". Every such recursion scheme is proved to have a least interpreted semantics in every Scott's model of \lambda-calculus in which the terminals are interpreted as continuous operations. For the uninterpreted semantics based on infinite \lambda-terms we follow the idea of Fiore, Plotkin and Turi and work in the category of sets in context, which are presheaves on the category of finite sets. Fiore et al showed how to capture the type of variable binding in \lambda-calculus by an endofunctor H\lambda and they explained simultaneous substitution of \lambda-terms by proving that the presheaf of \lambda-terms is an initial H\lambda-monoid. Here we work with the presheaf of rational infinite \lambda-terms and prove that this is an initial iterative H\lambda-monoid. We conclude that every guarded higher-order recursion scheme has a unique uninterpreted solution in this monoid.

02 Jun 2025
The URGENT 2024 Challenge aims to foster speech enhancement (SE) techniques
with great universality, robustness, and generalizability, featuring a broader
task definition, large-scale multi-domain data, and comprehensive evaluation
metrics. Nourished by the challenge outcomes, this paper presents an in-depth
analysis of two key, yet understudied, issues in SE system development: data
cleaning and evaluation metrics. We highlight several overlooked problems in
traditional SE pipelines: (1) mismatches between declared and effective audio
bandwidths, along with label noise even in various "high-quality" speech
corpora; (2) lack of both effective SE systems to conquer the hardest
conditions (e.g., speech overlap, strong noise / reverberation) and reliable
measure of speech sample difficulty; (3) importance of combining multifaceted
metrics for a comprehensive evaluation correlating well with human judgment. We
hope that this endeavor can inspire improved SE pipeline designs in the future.

26 Jul 2024
Training a linear classifier or lightweight model on top of pretrained vision
model outputs, so-called 'frozen features', leads to impressive performance on
a number of downstream few-shot tasks. Currently, frozen features are not
modified during training. On the other hand, when networks are trained directly
on images, data augmentation is a standard recipe that improves performance
with no substantial overhead. In this paper, we conduct an extensive pilot
study on few-shot image classification that explores applying data
augmentations in the frozen feature space, dubbed 'frozen feature augmentation
(FroFA)', covering twenty augmentations in total. Our study demonstrates that
adopting a deceptively simple pointwise FroFA, such as brightness, can improve
few-shot performance consistently across three network architectures, three
large pretraining datasets, and eight transfer datasets.

19 Nov 2024
Researchers at Leibniz Universität Hannover and Technische Universität Braunschweig introduced the Quantum Tree Generator (QTG) for the 0-1 Knapsack Problem, integrating it with an amplitude amplification method and a novel classical-quantum runtime estimation technique. This approach yielded substantial memory savings, scaling linearly with problem size, and achieved competitive to superior runtimes compared to classical state-of-the-art solvers for hard instances with up to 600 variables.

07 Sep 2022

Very often, in the course of uncertainty quantification tasks or data analysis, one has to deal with high-dimensional random variables (RVs). A high-dimensional RV can be described by its probability density (pdf) and/or by the corresponding probability characteristic functions (pcf), or by a polynomial chaos (PCE) or similar expansion. Here the interest is mainly to compute characterisations like the entropy, or relations between two distributions, like their Kullback-Leibler divergence. These are all computed from the pdf, which is often not available directly, and it is a computational challenge to even represent it in a numerically feasible fashion in case the dimension is even moderately large. In this regard, we propose to represent the density by a high order tensor product, and approximate this in a low-rank format. We show how to go from the pcf or functional representation to the pdf. This allows us to reduce the computational complexity and storage cost from an exponential to a linear. The characterisations such as entropy or the -divergences need the possibility to compute point-wise functions of the pdf. This normally rather trivial task becomes more difficult when the pdf is approximated in a low-rank tensor format, as the point values are not directly accessible any more. The data is considered as an element of a high order tensor space. The considered algorithms are independent of the representation of the data as a tensor. All that we require is that the data can be considered as an element of an associative, commutative algebra with an inner product. Such an algebra is isomorphic to a commutative sub-algebra of the usual matrix algebra, allowing the use of matrix algorithms to accomplish the mentioned tasks.

30 Jun 2025
Movable-antenna (MA) arrays are envisioned as a promising technique for enhancing secrecy performance in wireless communications by leveraging additional spatial degrees of freedom. However, when the eavesdropper is located in the same direction as the legitimate user, particularly in mmWave/THz bands where line-of-sight (LOS) propagation dominates, the secrecy performance of MA arrays becomes significantly limited, thus directionally insecure. To address this challenge, we employ a joint design that combines an MA array with a frequency-diverse array (FDA) at the transmitter to secure the transmission across both range and direction. Specifically, we derive closed-form expressions for the optimal antenna positions and frequency shifts, assuming small perturbations in both parameters from a linear frequency-diverse MA configuration. Furthermore, we compare the worst-case secrecy rate under this minor perturbation assumption with that obtained under a general constraint, where simulated annealing is employed to numerically determine the optimal parameters. Simulation results confirm that the proposed optimized frequency diverse MA approach significantly enhances secrecy performance in the presence of an eavesdropper aligned with the direction of the legitimate receiver.

07 Jun 2024
The last decade has witnessed significant advancements in deep learning-based speech enhancement (SE). However, most existing SE research has limitations on the coverage of SE sub-tasks, data diversity and amount, and evaluation metrics. To fill this gap and promote research toward universal SE, we establish a new SE challenge, named URGENT, to focus on the universality, robustness, and generalizability of SE. We aim to extend the SE definition to cover different sub-tasks to explore the limits of SE models, starting from denoising, dereverberation, bandwidth extension, and declipping. A novel framework is proposed to unify all these sub-tasks in a single model, allowing the use of all existing SE approaches. We collected public speech and noise data from different domains to construct diverse evaluation data. Finally, we discuss the insights gained from our preliminary baseline experiments based on both generative and discriminative SE methods with 12 curated metrics.

04 Feb 2025
Following initial work by JaJa, Ahlswede and Cai, and inspired by a recent renewed surge in interest in deterministic identification (DI) via noisy channels, we consider the problem in its generality for memoryless channels with finite output, but arbitrary input alphabets. Such a channel is essentially given by its output distributions as a subset in the probability simplex. Our main findings are that the maximum length of messages thus identifiable scales superlinearly as with the block length , and that the optimal rate is bounded in terms of the covering (aka Minkowski, or Kolmogorov, or entropy) dimension of a certain algebraic transformation of the output set: . Remarkably, both the lower and upper Minkowski dimensions play a role in this result. Along the way, we present a "Hypothesis Testing Lemma" showing that it is sufficient to ensure pairwise reliable distinguishability of the output distributions to construct a DI code. Although we do not know the exact capacity formula, we can conclude that the DI capacity exhibits superactivation: there exist channels whose capacities individually are zero, but whose product has positive capacity. We also generalise these results to classical-quantum channels with finite-dimensional output quantum system, in particular to quantum channels on finite-dimensional quantum systems under the constraint that the identification code can only use tensor product inputs.

05 Mar 2024

We show that from the point of view of the generalized pairing Hamiltonian, the atomic nucleus is a system with small entanglement and can thus be described efficiently using a 1D tensor network (matrix-product state) despite the presence of long-range interactions. The ground state can be obtained using the density-matrix renormalization group (DMRG) algorithm, which is accurate up to machine precision even for large nuclei, is numerically as cheap as the widely used BCS (Bardeen-Cooper-Schrieffer) approach, and does not suffer from any mean-field artifacts. We apply this framework to compute the even-odd mass differences of all known lead isotopes from Pb to Pb in a very large configuration space of 13 shells between the neutron magic numbers 82 and 184 (i.e., two major shells) and find good agreement with the experiment. We also treat pairing with non-zero angular momentum and determine the lowest excited states in the full configuration space of one major shell, which we demonstrate for the , isotones. To demonstrate the capabilities of the method beyond low-lying excitations, we calculate the first 100 excited states of Pb with singlet pairing and the two-neutron removal spectral function of Pb, which relates to a two-neutron pickup experiment.

23 Jan 2025
Researchers systematically evaluated various neural Kalman filter architectures for acoustic echo cancellation, integrating deep neural networks into the Frequency-Domain Adaptive Kalman Filter framework. These hybrid approaches demonstrated improved echo cancellation and faster adaptation compared to the classical FDKF, with some methods also preserving near-end speech quality effectively.

21 Sep 2024
In this work, we study amodal video instance segmentation for automated driving. Previous works perform amodal video instance segmentation relying on methods trained on entirely labeled video data with techniques borrowed from standard video instance segmentation. Such amodally labeled video data is difficult and expensive to obtain and the resulting methods suffer from a trade-off between instance segmentation and tracking performance. To largely solve this issue, we propose to study the application of foundation models for this task. More precisely, we exploit the extensive knowledge of the Segment Anything Model (SAM), while fine-tuning it to the amodal instance segmentation task. Given an initial video instance segmentation, we sample points from the visible masks to prompt our amodal SAM. We use a point memory to store those points. If a previously observed instance is not predicted in a following frame, we retrieve its most recent points from the point memory and use a point tracking method to follow those points to the current frame, together with the corresponding last amodal instance mask. This way, while basing our method on an amodal instance segmentation, we nevertheless obtain video-level amodal instance segmentation results. Our resulting S-AModal method achieves state-of-the-art results in amodal video instance segmentation while resolving the need for amodal video-based labels. Code for S-AModal is available at this https URL.
There are no more papers matching your filters at the moment.
