
30 Jun 2023

DreamDiffusion is a system that directly translates brain electroencephalogram (EEG) signals into high-quality images, circumventing the need for text-based intermediaries. It achieves this by combining masked signal modeling for robust EEG representation learning, fine-tuning a pre-trained Stable Diffusion model, and utilizing CLIP-based alignment to bridge the semantic gap between brain signals and image generation.

28 Mar 2025




SkillMimic presents a unified data-driven framework that enables physically simulated humanoids to learn diverse and precise human-object interaction skills, such as basketball maneuvers, directly from demonstrations. By introducing the Contact Graph and Contact Graph Reward, the framework effectively masters complex interactions and achieves continuous basketball scoring, outperforming prior methods.

18 Oct 2025


A research collaboration led by Tsinghua University presents a comprehensive survey of self-play methods in non-cooperative Multi-Agent Reinforcement Learning. It introduces a unified framework that integrates diverse algorithms, notably including regret-minimization approaches, and categorizes existing solutions while analyzing their applications and future challenges.

20 May 2025

Researchers from Tsinghua University, National University of Singapore, Fudan University, and Griffith University introduce TimeFilter, a framework for multivariate time series forecasting that employs patch-specific spatial-temporal graph filtration. The method dynamically identifies and filters out irrelevant dependencies for individual time series segments, achieving state-of-the-art performance with an average 4.48% MSE reduction over leading baselines in long-term forecasting.
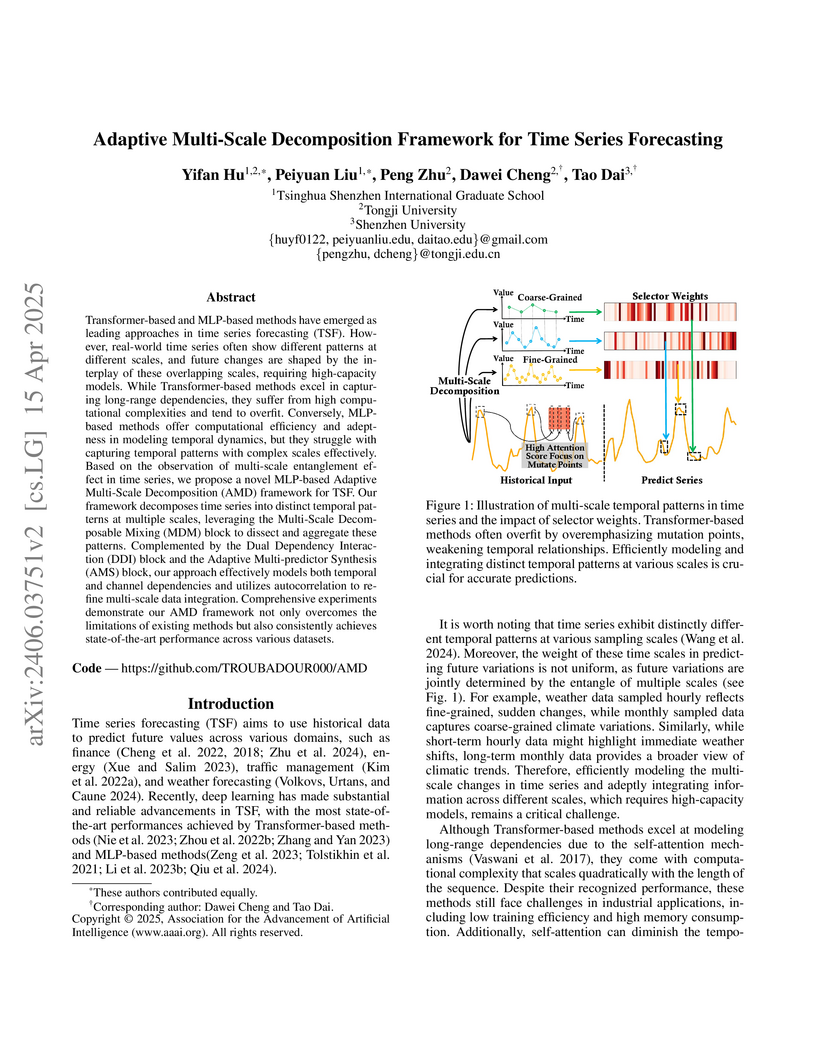
15 Apr 2025
An adaptive multi-scale decomposition (AMD) framework, built on an MLP architecture, was developed for time series forecasting, consistently achieving state-of-the-art performance across diverse datasets by dynamically disentangling and integrating multi-scale temporal patterns with improved computational efficiency.
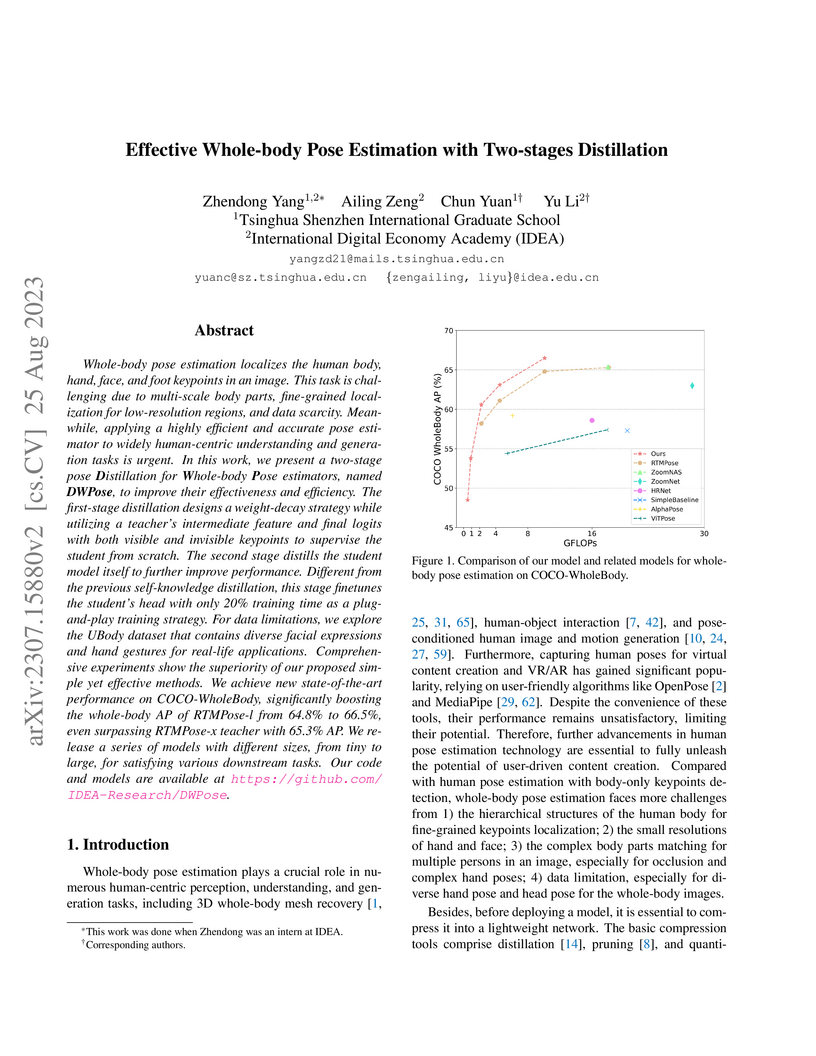
25 Aug 2023


Whole-body pose estimation localizes the human body, hand, face, and foot
keypoints in an image. This task is challenging due to multi-scale body parts,
fine-grained localization for low-resolution regions, and data scarcity.
Meanwhile, applying a highly efficient and accurate pose estimator to widely
human-centric understanding and generation tasks is urgent. In this work, we
present a two-stage pose \textbf{D}istillation for \textbf{W}hole-body
\textbf{P}ose estimators, named \textbf{DWPose}, to improve their effectiveness
and efficiency. The first-stage distillation designs a weight-decay strategy
while utilizing a teacher's intermediate feature and final logits with both
visible and invisible keypoints to supervise the student from scratch. The
second stage distills the student model itself to further improve performance.
Different from the previous self-knowledge distillation, this stage finetunes
the student's head with only 20% training time as a plug-and-play training
strategy. For data limitations, we explore the UBody dataset that contains
diverse facial expressions and hand gestures for real-life applications.
Comprehensive experiments show the superiority of our proposed simple yet
effective methods. We achieve new state-of-the-art performance on
COCO-WholeBody, significantly boosting the whole-body AP of RTMPose-l from
64.8% to 66.5%, even surpassing RTMPose-x teacher with 65.3% AP. We release a
series of models with different sizes, from tiny to large, for satisfying
various downstream tasks. Our codes and models are available at
this https URL

19 Jun 2025

Research shows large language model safety alignments are susceptible to latent perturbations, revealing a 'shallow' alignment where models refuse unsafe queries at the surface level. A new Activation Steering Attack (ASA) effectively uncovers these vulnerabilities, while a proposed Layer-wise Adversarial Patch Training (LAPT) defense significantly reduces attack success rates across models without compromising general capabilities.
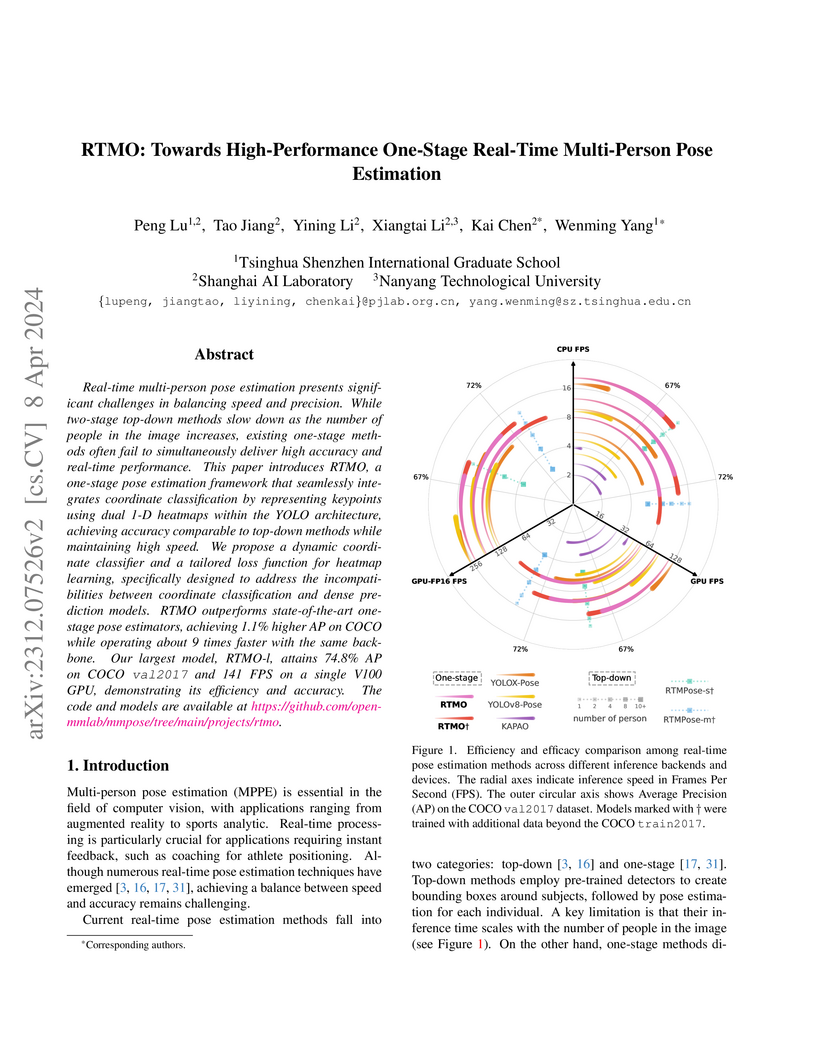
08 Apr 2024


RTMO introduces a one-stage real-time multi-person pose estimation framework that achieves high accuracy and consistent inference speeds, even in crowded scenes. The model sets a new state-of-the-art for one-stage methods, reaching 71.6% AP on COCO test-dev and 73.2% AP on CrowdPose, while maintaining high FPS (e.g., 141 FPS for RTMO-l on a V100 GPU).

23 Oct 2025
Large Vision-Language Models (LVLMs) have shown impressive performance across multi-modal tasks by encoding images into thousands of tokens. However, the large number of image tokens results in significant computational overhead, and the use of dynamic high-resolution inputs further increases this burden. Previous approaches have attempted to reduce the number of image tokens through token pruning, typically by selecting tokens based on attention scores or image token diversity. Through empirical studies, we observe that existing methods often overlook the joint impact of pruning on both the current layer's output (local) and the outputs of subsequent layers (global), leading to suboptimal pruning decisions. To address this challenge, we propose Balanced Token Pruning (BTP), a plug-and-play method for pruning vision tokens. Specifically, our method utilizes a small calibration set to divide the pruning process into multiple stages. In the early stages, our method emphasizes the impact of pruning on subsequent layers, whereas in the deeper stages, the focus shifts toward preserving the consistency of local outputs. Extensive experiments across various LVLMs demonstrate the broad effectiveness of our approach on multiple benchmarks. Our method achieves a 78% compression rate while preserving 96.7% of the original models' performance on average. Our code is available at this https URL.

24 Oct 2025
FINERS introduces a multi-modal large language model framework designed for instruction-guided reasoning and pixel-level segmentation of ultra-small objects within high-resolution images. The model achieves state-of-the-art gIoU/cIoU scores of 55.1/46.5 on the new UAV-captured 4K dataset, FINERS-4k, and generalizes robustly to other high-resolution visual question answering benchmarks.

11 Jun 2025
TransGI introduces an object-centric neural transfer model combined with an efficient probe-based lighting system to achieve real-time global illumination for dynamic scenes with complex materials. The system renders frames in approximately 6.7ms on an RTX 5000 GPU, enabling high-fidelity rendering with support for glossy materials and object-level dynamics.

26 Sep 2025
The increasing demand for 3D assets across various industries necessitates efficient and automated methods for 3D content creation. Leveraging 3D Gaussian Splatting, recent large reconstruction models (LRMs) have demonstrated the ability to efficiently achieve high-quality 3D rendering by integrating multiview diffusion for generation and scalable transformers for reconstruction. However, existing models fail to produce the material properties of assets, which is crucial for realistic rendering in diverse lighting environments. In this paper, we introduce the Large Material Gaussian Model (MGM), a novel framework designed to generate high-quality 3D content with Physically Based Rendering (PBR) materials, ie, albedo, roughness, and metallic properties, rather than merely producing RGB textures with uncontrolled light baking. Specifically, we first fine-tune a new multiview material diffusion model conditioned on input depth and normal maps. Utilizing the generated multiview PBR images, we explore a Gaussian material representation that not only aligns with 2D Gaussian Splatting but also models each channel of the PBR materials. The reconstructed point clouds can then be rendered to acquire PBR attributes, enabling dynamic relighting by applying various ambient light maps. Extensive experiments demonstrate that the materials produced by our method not only exhibit greater visual appeal compared to baseline methods but also enhance material modeling, thereby enabling practical downstream rendering applications.

09 Jan 2025
Model merging has recently gained attention as an economical and scalable
approach to incorporate task-specific weights from various tasks into a unified
multi-task model. For example, in Task Arithmetic (TA), adding the fine-tuned
weights of different tasks can enhance the model's performance on those tasks,
while subtracting them leads to task forgetting. Although TA is highly
effective, interference among task still hampers the performance of the merged
model. Existing methods for handling conflicts between task generally rely on
empirical selection, resulting in suboptimal performance. In this paper, we
introduce an Adaptive Weight Disentanglement method. We begin by theoretically
proving that task vectors employed in model merging should be orthogonal to
minimize interference among tasks. Guided by this insight, we initialize
redundant vectors such that, when subtracted from the original task vectors,
the resulting vectors exhibit increased orthogonality. Additionally, we impose
an norm constraint on the redundant vectors to preserve the performance of the
task-specific models. Experimental results demonstrate the effectiveness of our
proposed technique: it successfully extracts redundant vectors, and after their
subtraction, the task vectors not only retain robust performance but also
achieve superior fusion outcomes. Our code is available at
\href{https://github.com/FarisXiong/AWD.git}{this https URL}.

06 Oct 2025

ViP-CLIP presents a new framework for zero-shot anomaly detection, leveraging adaptive visual-perception prompting and unified text-patch alignment. This approach improves performance in identifying and localizing anomalies across diverse industrial and medical benchmarks, surpassing prior methods and showing resilience to variations in class names.

04 Aug 2025
Given the limitations of satellite orbits and imaging conditions, multi-modal remote sensing (RS) data is crucial in enabling long-term earth observation. However, maritime surveillance remains challenging due to the complexity of multi-scale targets and the dynamic environments. To bridge this critical gap, we propose a Synchronized Multi-modal Aligned Remote sensing Targets dataset for berthed ships analysis (SMART-Ship), containing spatiotemporal registered images with fine-grained annotation for maritime targets from five modalities: visible-light, synthetic aperture radar (SAR), panchromatic, multi-spectral, and near-infrared. Specifically, our dataset consists of 1092 multi-modal image sets, covering 38,838 ships. Each image set is acquired within one week and registered to ensure spatiotemporal consistency. Ship instances in each set are annotated with polygonal location information, fine-grained categories, instance-level identifiers, and change region masks, organized hierarchically to support diverse multi-modal RS tasks. Furthermore, we define standardized benchmarks on five fundamental tasks and comprehensively compare representative methods across the dataset. Thorough experiment evaluations validate that the proposed SMART-Ship dataset could support various multi-modal RS interpretation tasks and reveal the promising directions for further exploration.

02 Sep 2025

Accurate 24-hour solar irradiance forecasting is essential for the safe and economic operation of solar photovoltaic systems. Traditional numerical weather prediction (NWP) models represent the state-of-the-art in forecasting performance but rely on computationally costly data assimilation and solving complicated partial differential equations (PDEs) that simulate atmospheric physics. Here, we introduce SolarSeer, an end-to-end large artificial intelligence (AI) model for solar irradiance forecasting across the Contiguous United States (CONUS). SolarSeer is designed to directly map the historical satellite observations to future forecasts, eliminating the computational overhead of data assimilation and PDEs solving. This efficiency allows SolarSeer to operate over 1,500 times faster than traditional NWP, generating 24-hour cloud cover and solar irradiance forecasts for the CONUS at 5-kilometer resolution in under 3 seconds. Compared with the state-of-the-art NWP in the CONUS, i.e., High-Resolution Rapid Refresh (HRRR), SolarSeer significantly reduces the root mean squared error of solar irradiance forecasting by 27.28% in reanalysis data and 15.35% across 1,800 stations. SolarSeer also effectively captures solar irradiance fluctuations and significantly enhances the first-order irradiance difference forecasting accuracy. SolarSeer's ultrafast, accurate 24-hour solar irradiance forecasts provide strong support for the transition to sustainable, net-zero energy systems.

21 May 2025

A comprehensive survey categorizes and reviews existing multi-robot systems designed for cooperative exploration in unknown and challenging environments, proposing a modular research framework across localization and mapping, cooperative planning, and communication. It analyzes the evolution of these systems and their integration in real-world applications, such as the DARPA Subterranean Challenge.

14 Jun 2025



Incompletely-Supervised Concealed Object Segmentation (ISCOS) involves segmenting objects that seamlessly blend into their surrounding environments, utilizing incompletely annotated data, such as weak and semi-annotations, for model training. This task remains highly challenging due to (1) the limited supervision provided by the incompletely annotated training data, and (2) the difficulty of distinguishing concealed objects from the background, which arises from the intrinsic similarities in concealed scenarios. In this paper, we introduce the first unified method for ISCOS to address these challenges. To tackle the issue of incomplete supervision, we propose a unified mean-teacher framework, SEE, that leverages the vision foundation model, ``\emph{Segment Anything Model (SAM)}'', to generate pseudo-labels using coarse masks produced by the teacher model as prompts. To mitigate the effect of low-quality segmentation masks, we introduce a series of strategies for pseudo-label generation, storage, and supervision. These strategies aim to produce informative pseudo-labels, store the best pseudo-labels generated, and select the most reliable components to guide the student model, thereby ensuring robust network training. Additionally, to tackle the issue of intrinsic similarity, we design a hybrid-granularity feature grouping module that groups features at different granularities and aggregates these results. By clustering similar features, this module promotes segmentation coherence, facilitating more complete segmentation for both single-object and multiple-object images. We validate the effectiveness of our approach across multiple ISCOS tasks, and experimental results demonstrate that our method achieves state-of-the-art performance. Furthermore, SEE can serve as a plug-and-play solution, enhancing the performance of existing models.

02 Jan 2025
Video data and algorithms have been driving advances in multi-object tracking
(MOT). While existing MOT datasets focus on occlusion and appearance
similarity, complex motion patterns are widespread yet overlooked. To address
this issue, we introduce a new dataset called BEE24 to highlight complex
motions. Identity association algorithms have long been the focus of MOT
research. Existing trackers can be categorized into two association paradigms:
single-feature paradigm (based on either motion or appearance feature) and
serial paradigm (one feature serves as secondary while the other is primary).
However, these paradigms are incapable of fully utilizing different features.
In this paper, we propose a parallel paradigm and present the Two rOund
Parallel matchIng meChanism (TOPIC) to implement it. The TOPIC leverages both
motion and appearance features and can adaptively select the preferable one as
the assignment metric based on motion level. Moreover, we provide an
Attention-based Appearance Reconstruction Module (AARM) to reconstruct
appearance feature embeddings, thus enhancing the representation of appearance
features. Comprehensive experiments show that our approach achieves
state-of-the-art performance on four public datasets and BEE24. Moreover, BEE24
challenges existing trackers to track multiple similar-appearing small objects
with complex motions over long periods, which is critical in real-world
applications such as beekeeping and drone swarm surveillance. Notably, our
proposed parallel paradigm surpasses the performance of existing association
paradigms by a large margin, e.g., reducing false negatives by 6% to 81%
compared to the single-feature association paradigm. The introduced dataset and
association paradigm in this work offer a fresh perspective for advancing the
MOT field. The source code and dataset are available at
this https URL
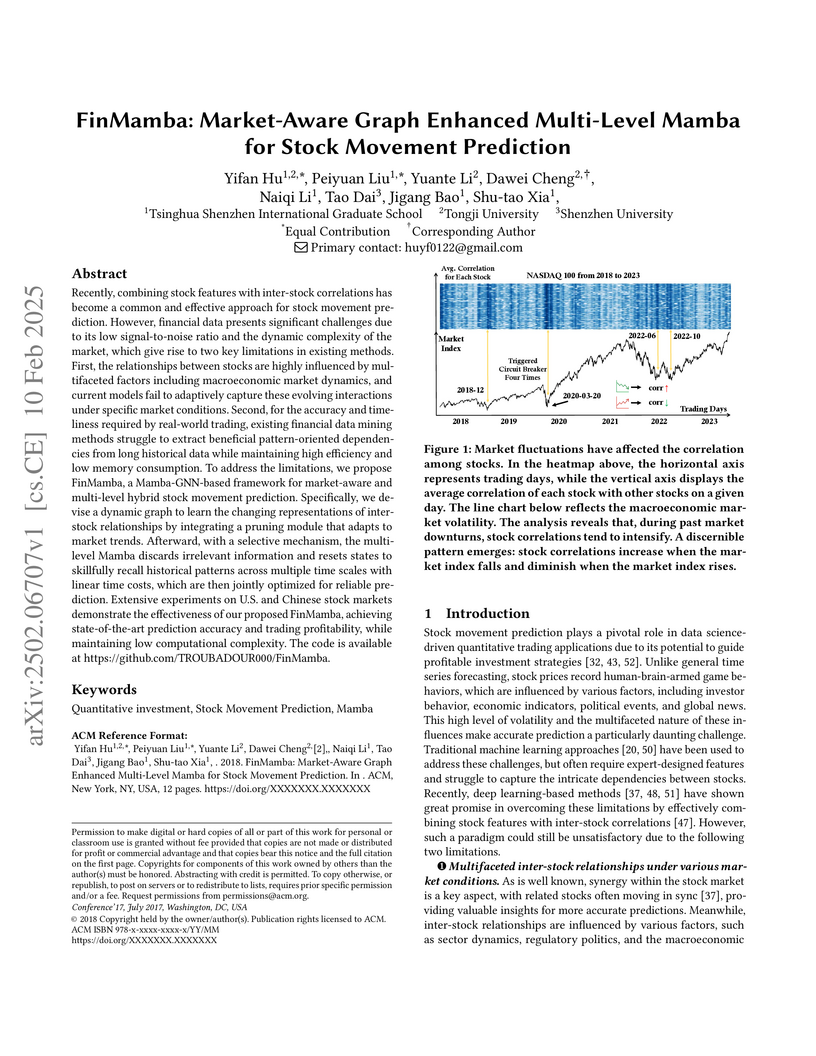
10 Feb 2025
FinMamba presents a framework for stock movement prediction that combines a market-aware graph to dynamically capture inter-stock relationships with a multi-level Mamba architecture for efficient temporal dependency extraction. The model consistently outperforms existing methods across various stock market datasets while maintaining computational efficiency for real-time applications.
There are no more papers matching your filters at the moment.
