
06 Aug 2019


We study proof techniques for bisimilarity based on unique solution of equations. We draw inspiration from a result by Roscoe in the denotational setting of CSP and for failure semantics, essentially stating that an equation (or a system of equations) whose infinite unfolding never produces a divergence has the unique-solution property. We transport this result onto the operational setting of CCS and for bisimilarity. We then exploit the operational approach to: refine the theorem, distinguishing between different forms of divergence; derive an abstract formulation of the theorems, on generic LTSs; adapt the theorems to other equivalences such as trace equivalence, and to preorders such as trace inclusion. We compare the resulting techniques to enhancements of the bisimulation proof method (the `up-to techniques'). Finally, we study the theorems in name-passing calculi such as the asynchronous -calculus, and use them to revisit the completeness part of the proof of full abstraction of Milner's encoding of the -calculus into the -calculus for Lévy-Longo Trees.
09 Mar 2023

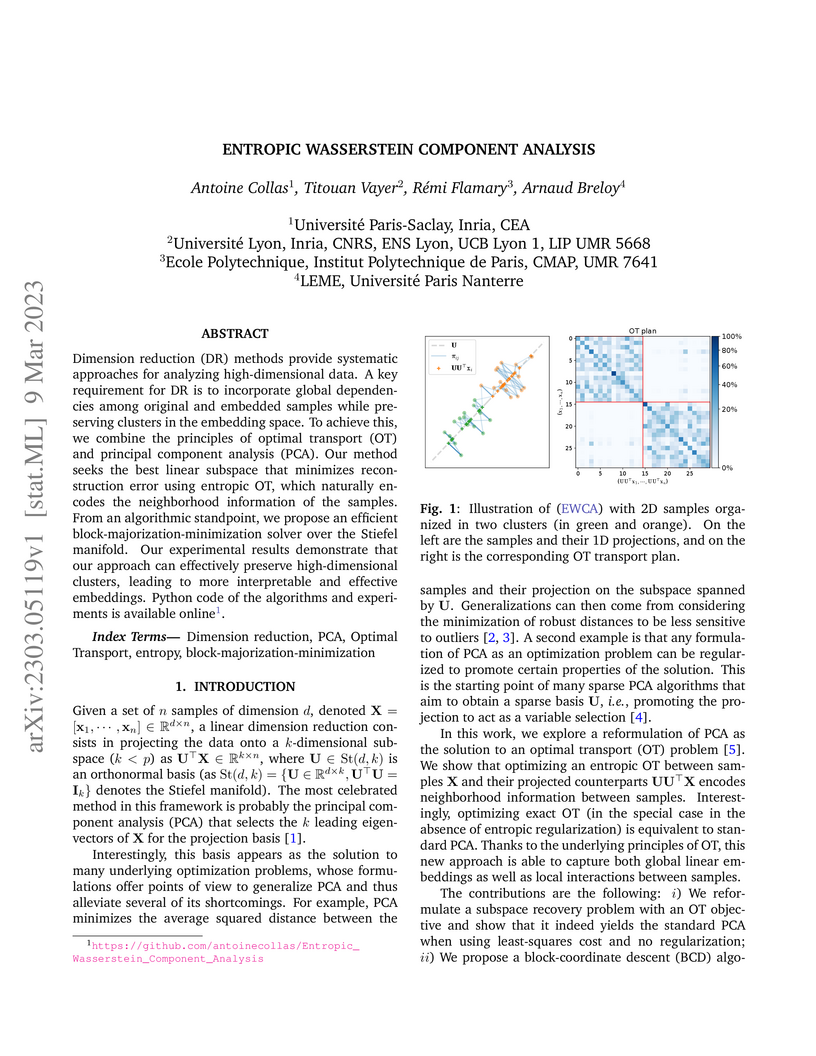
Dimension reduction (DR) methods provide systematic approaches for analyzing high-dimensional data. A key requirement for DR is to incorporate global dependencies among original and embedded samples while preserving clusters in the embedding space. To achieve this, we combine the principles of optimal transport (OT) and principal component analysis (PCA). Our method seeks the best linear subspace that minimizes reconstruction error using entropic OT, which naturally encodes the neighborhood information of the samples. From an algorithmic standpoint, we propose an efficient block-majorization-minimization solver over the Stiefel manifold. Our experimental results demonstrate that our approach can effectively preserve high-dimensional clusters, leading to more interpretable and effective embeddings. Python code of the algorithms and experiments is available online.

01 Mar 2022
Comparing structured objects such as graphs is a fundamental operation involved in many learning tasks. To this end, the Gromov-Wasserstein (GW) distance, based on Optimal Transport (OT), has proven to be successful in handling the specific nature of the associated objects. More specifically, through the nodes connectivity relations, GW operates on graphs, seen as probability measures over specific spaces. At the core of OT is the idea of conservation of mass, which imposes a coupling between all the nodes from the two considered graphs. We argue in this paper that this property can be detrimental for tasks such as graph dictionary or partition learning, and we relax it by proposing a new semi-relaxed Gromov-Wasserstein divergence. Aside from immediate computational benefits, we discuss its properties, and show that it can lead to an efficient graph dictionary learning algorithm. We empirically demonstrate its relevance for complex tasks on graphs such as partitioning, clustering and completion.
30 Nov 2020
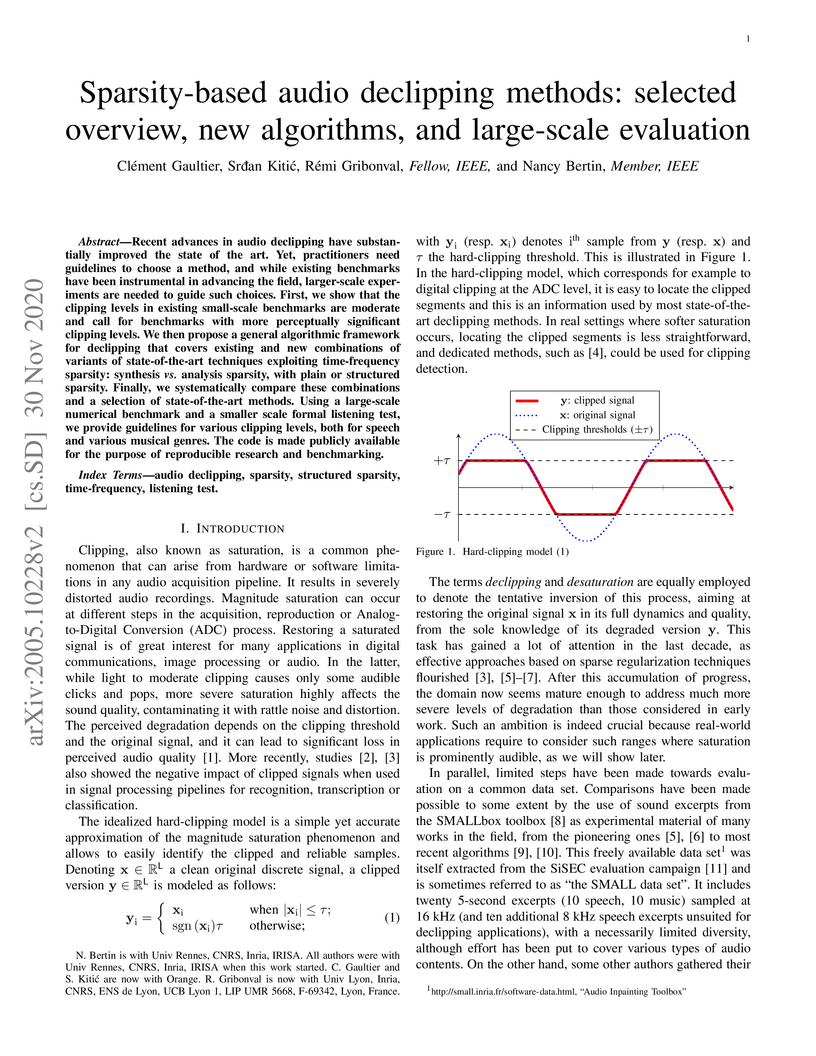
Recent advances in audio declipping have substantially improved the state of
the art.% in certain saturation regimes. Yet, practitioners need guidelines to
choose a method, and while existing benchmarks have been instrumental in
advancing the field, larger-scale experiments are needed to guide such choices.
First, we show that the clipping levels in existing small-scale benchmarks are
moderate and call for benchmarks with more perceptually significant clipping
levels. We then propose a general algorithmic framework for declipping that
covers existing and new combinations of variants of state-of-the-art techniques
exploiting time-frequency sparsity: synthesis vs. analysis sparsity, with plain
or structured sparsity. Finally, we systematically compare these combinations
and a selection of state-of-the-art methods. Using a large-scale numerical
benchmark and a smaller scale formal listening test, we provide guidelines for
various clipping levels, both for speech and various musical genres. The code
is made publicly available for the purpose of reproducible research and
benchmarking.

24 Jun 2021

This article considers "compressive learning," an approach to large-scale
machine learning where datasets are massively compressed before learning (e.g.,
clustering, classification, or regression) is performed. In particular, a
"sketch" is first constructed by computing carefully chosen nonlinear random
features (e.g., random Fourier features) and averaging them over the whole
dataset. Parameters are then learned from the sketch, without access to the
original dataset. This article surveys the current state-of-the-art in
compressive learning, including the main concepts and algorithms, their
connections with established signal-processing methods, existing theoretical
guarantees -- on both information preservation and privacy preservation, and
important open problems.
09 Mar 2023
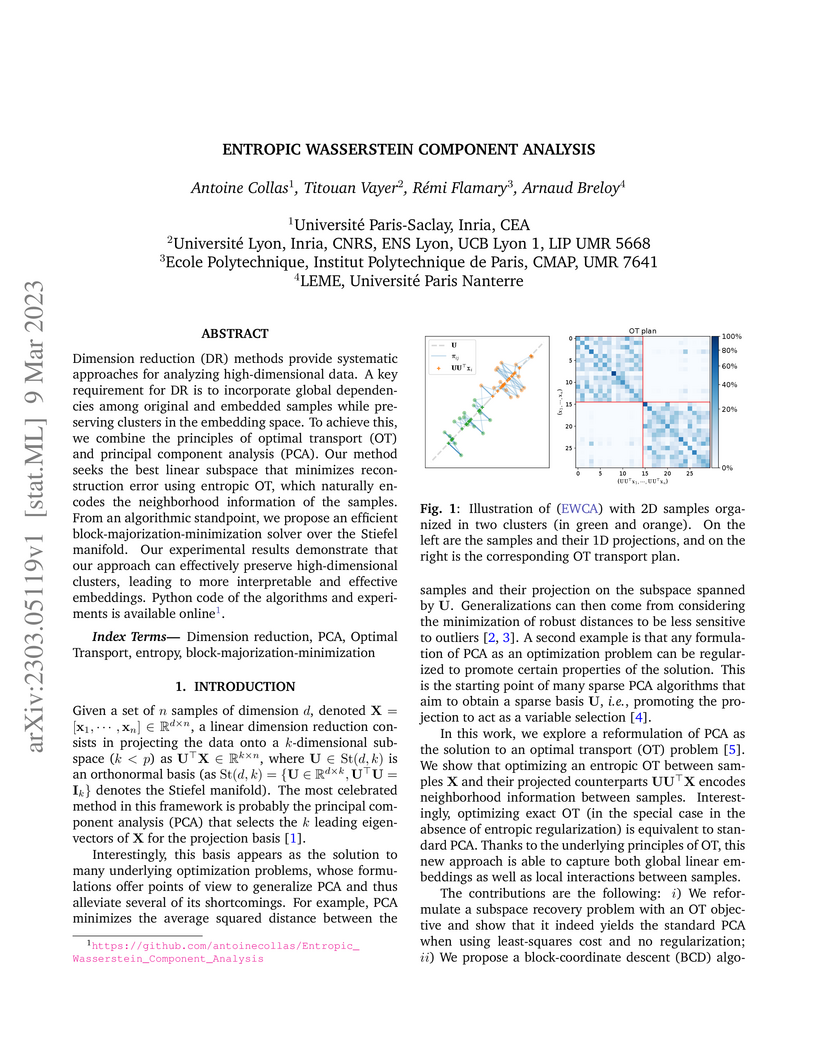
Dimension reduction (DR) methods provide systematic approaches for analyzing high-dimensional data. A key requirement for DR is to incorporate global dependencies among original and embedded samples while preserving clusters in the embedding space. To achieve this, we combine the principles of optimal transport (OT) and principal component analysis (PCA). Our method seeks the best linear subspace that minimizes reconstruction error using entropic OT, which naturally encodes the neighborhood information of the samples. From an algorithmic standpoint, we propose an efficient block-majorization-minimization solver over the Stiefel manifold. Our experimental results demonstrate that our approach can effectively preserve high-dimensional clusters, leading to more interpretable and effective embeddings. Python code of the algorithms and experiments is available online.

03 Jun 2022
We present a variant of the theory of compatible functions on relations, due to Sangiorgi and Pous. We show that the up-to context proof technique for bisimulation is compatible in this setting for two subsets of the pi-calculus: the asynchronous pi-calculus and a pi-calculus with immediately available names.

13 Oct 2021
Optimal transport distances are powerful tools to compare probability distributions and have found many applications in machine learning. Yet their algorithmic complexity prevents their direct use on large scale datasets. To overcome this challenge, practitioners compute these distances on minibatches {\em i.e.} they average the outcome of several smaller optimal transport problems. We propose in this paper an analysis of this practice, which effects are not well understood so far. We notably argue that it is equivalent to an implicit regularization of the original problem, with appealing properties such as unbiased estimators, gradients and a concentration bound around the expectation, but also with defects such as loss of distance property. Along with this theoretical analysis, we also conduct empirical experiments on gradient flows, GANs or color transfer that highlight the practical interest of this strategy.

21 Dec 2017
We analyze a coupled anonymized dataset collecting the mobile phone communication and bank transactions history of a large number of individuals. After mapping the social structure and introducing indicators of socioeconomic status, demographic features, and purchasing habits of individuals we show that typical consumption patterns are strongly correlated with identified socioeconomic classes leading to patterns of stratification in the social structure. In addition we measure correlations between merchant categories and introduce a correlation network, which emerges with a meaningful community structure. We detect multivariate relations between merchant categories and show correlations in purchasing habits of individuals. Our work provides novel and detailed insight into the relations between social and consuming behaviour with potential applications in recommendation system design.

19 May 2021
Surveys of galaxy distances and radial peculiar velocities can be used to reconstruct the large scale structure. Other than systematic errors in the zero-point calibration of the galaxy distances the main source of uncertainties of such data are errors on the distance moduli, assumed here to be Gaussian and thus turn into lognormal errors on distances and velocities. Naively treated, it leads to spurious nearby outflow and strong infall at larger distances. The lognormal bias is corrected here and tested against mock data extracted from a CDM simulation, designed to statistically follow the grouped Cosmicflows-3 (CF3) data. Considering a subsample of data points, all of which have the same true distances or same redshifts, the lognormal bias arises because the means of the distributions of observed distances and velocities are skewed off the means of the true distances and velocities. Yet, the medians are invariant under the lognormal transformation. That invariance allows the Gaussianization of the distances and velocities and the removal of the lognormal bias. This Bias Gaussianization correction (BGc) algorithm is tested against mock CF3 catalogs. The test consists of a comparison of the BGC estimated with the simulated distances and velocities and of an examination of the Wiener filter reconstruction from the BGc data. Indeed, the BGc eliminates the lognormal bias. The estimation of Hubble's () constant is also tested. The residual of the BGc estimated from the simulated values is and is dominated by the cosmic variance. The BGc correction of the actual CF3 data yields .

16 Jun 2022
This paper studies trace-based equivalences for systems combining
nondeterministic and probabilistic choices. We show how trace semantics for
such processes can be recovered by instantiating a coalgebraic construction
known as the generalised powerset construction. We characterise and compare the
resulting semantics to known definitions of trace equivalences appearing in the
literature. Most of our results are based on the exciting interplay between
monads and their presentations via algebraic theories.

13 Apr 2022
Reverse search is a convenient method for enumerating structured objects,
that can be used both to address theoretical issues and to solve data mining
problems. This method has already been successfully developed to handle
unordered trees. If the literature proposes solutions to enumerate singletons
of trees, we study in this article a more general problem, the enumeration of
sets of trees -- forests. Specifically, we mainly study irredundant forests,
i.e., where no tree is a subtree of another. By compressing each such forest
into a Directed Acyclic Graph (DAG), we develop a reverse search like method to
enumerate DAGs compressing irredundant forests. Remarkably, we prove that these
DAGs are in bijection with the row-Fishburn matrices, a well-studied class of
combinatorial objects. In a second step, we derive our irredundant forest
enumeration to provide algorithms for tackling related problems: (i)
enumeration of forests in their classical sense (where redundancy is allowed);
(ii) the enumeration of "subforests" of a forest, and (iii) the frequent
"subforest" mining problem. All the methods presented in this article enumerate
each item uniquely, up to isomorphism.

31 May 2023
Comparing probability distributions is at the crux of many machine learning algorithms. Maximum Mean Discrepancies (MMD) and Wasserstein distances are two classes of distances between probability distributions that have attracted abundant attention in past years. This paper establishes some conditions under which the Wasserstein distance can be controlled by MMD norms. Our work is motivated by the compressive statistical learning (CSL) theory, a general framework for resource-efficient large scale learning in which the training data is summarized in a single vector (called sketch) that captures the information relevant to the considered learning task. Inspired by existing results in CSL, we introduce the Hölder Lower Restricted Isometric Property and show that this property comes with interesting guarantees for compressive statistical learning. Based on the relations between the MMD and the Wasserstein distances, we provide guarantees for compressive statistical learning by introducing and studying the concept of Wasserstein regularity of the learning task, that is when some task-specific metric between probability distributions can be bounded by a Wasserstein distance.

28 Sep 2016


The graph translation operator has been defined with good spectral properties
in mind, and in particular with the end goal of being an isometric operator.
Unfortunately, the resulting definitions do not provide good intuitions on a
vertex-domain interpretation. In this paper, we show that this operator does
have a vertex-domain interpretation as a diffusion operator using a polynomial
approximation. We show that its impulse response exhibit an exponential decay
of the energy way from the impulse, demonstrating localization preservation.
Additionally, we formalize several techniques that can be used to study other
graph signal operators.

02 Dec 2020
Description of temporal networks and detection of dynamic communities have been hot topics of research for the last decade. However, no consensual answers to these challenges have been found due to the complexity of the task. Static communities are not well defined objects, and adding a temporal dimension renders the description even more difficult. In this article, we propose a coherent temporal clustering method: the Best Combination of Local Communities (BCLC). Our method aims at finding a good balance between two conflicting objectives : closely following the short time evolution by finding optimal partitions at each time step and temporal smoothness, which privileges historical continuity.

05 Dec 2023
Given a training set, a loss function, and a neural network architecture, it is often taken for granted that optimal network parameters exist, and a common practice is to apply available optimization algorithms to search for them. In this work, we show that the existence of an optimal solution is not always guaranteed, especially in the context of {\em sparse} ReLU neural networks. In particular, we first show that optimization problems involving deep networks with certain sparsity patterns do not always have optimal parameters, and that optimization algorithms may then diverge. Via a new topological relation between sparse ReLU neural networks and their linear counterparts, we derive -- using existing tools from real algebraic geometry -- an algorithm to verify that a given sparsity pattern suffers from this issue. Then, the existence of a global optimum is proved for every concrete optimization problem involving a shallow sparse ReLU neural network of output dimension one. Overall, the analysis is based on the investigation of two topological properties of the space of functions implementable as sparse ReLU neural networks: a best approximation property, and a closedness property, both in the uniform norm. This is studied both for (finite) domains corresponding to practical training on finite training sets, and for more general domains such as the unit cube. This allows us to provide conditions for the guaranteed existence of an optimum given a sparsity pattern. The results apply not only to several sparsity patterns proposed in recent works on network pruning/sparsification, but also to classical dense neural networks, including architectures not covered by existing results.

18 Jul 2017
Network analysis techniques remain rarely used for understanding
international management strategies. Our paper highlights their value as
research tool in this field of social science using a large set of micro-data
(20,000) to investigate the presence of networks of subsidiaries overseas. The
research question is the following: to what extent did/do global Japanese
business networks mirror organizational models existing in Japan? In
particular, we would like to assess how much the links building such business
networks are shaped by the structure of big-size industrial conglomerates of
firms headquartered in Japan, also described as HK. The major part of the
academic community in the fields of management and industrial organization
considers that formal links can be identified among firms belonging to HK. Miwa
and Ramseyer (Miwa and Ramseyer 2002; Ramseyer 2006) challenge this claim and
argue that the evidence supporting the existence of HK is weak. So far,
quantitative empirical investigation has been conducted exclusively using data
for firms incorporated in Japan. Our study tests the Miwa-Ramseyer hypothesis
(MRH) at the global level using information on the network of Japanese
subsidiaries overseas. The results obtained lead us to reject the MRH for the
global dataset, as well as for subsets restricted to the two main
regions/countries of destination of Japanese foreign investment. The results
are robust to the weighting of the links, with different specifications, and
are observed in most industrial sectors. The global Japanese network became
increasingly complex during the late 20th century as a consequence of increase
in the number of Japanese subsidiaries overseas but the key features of the
structure remained rather stable. We draw implications of these findings for
academic research in international business and for professionals involved in
corporate strategy.

17 Aug 2020
We propose a novel algorithm for unsupervised graph representation learning
with attributed graphs. It combines three advantages addressing some current
limitations of the literature: i) The model is inductive: it can embed new
graphs without re-training in the presence of new data; ii) The method takes
into account both micro-structures and macro-structures by looking at the
attributed graphs at different scales; iii) The model is end-to-end
differentiable: it is a building block that can be plugged into deep learning
pipelines and allows for back-propagation. We show that combining a coarsening
method having strong theoretical guarantees with mutual information
maximization suffices to produce high quality embeddings. We evaluate them on
classification tasks with common benchmarks of the literature. We show that our
algorithm is competitive with state of the art among unsupervised graph
representation learning methods.

21 Aug 2023
The simple random walk on shows two drastically different behaviours depending on the value of : it is recurrent when while it escapes (with a rate increasing with ) as soon as . This classical example illustrates that the asymptotic properties of a random walk provides some information on the structure of its state space. This paper aims to explore analogous questions on space made up of combinatorial objects with no algebraic structure. We take as a model for this problem the space of unordered unlabeled rooted trees endowed with Zhang edit distance. To this end, it defines the canonical unbiased random walk on the space of trees and provides an efficient algorithm to evaluate its escape rate. Compared to Zhang algorithm, it is incremental and computes the edit distance along the random walk approximately 100 times faster on trees of size on average. The escape rate of the random walk on trees is precisely estimated using intensive numerical simulations, out of reasonable reach without the incremental algorithm.

14 Jan 2002
The nonequilibrium dynamics of a binary Lennard-Jones mixture in a simple
shear flow is investigated by means of molecular dynamics simulations. The
range of temperature investigated covers both the liquid, supercooled and
glassy states, while the shear rate covers both the linear and nonlinear
regimes of rheology. The results can be interpreted in the context of a
nonequilibrium, schematic mode-coupling theory developed recently, which makes
the theory applicable to a wide range of soft glassy materials. The behavior of
the viscosity is first investigated. In the nonlinear regime, strong
shear-thinning is obtained. Scaling properties of the intermediate scattering
functions are studied. Standard `mode-coupling properties' of factorization and
time-superposition hold in this nonequilibrium situation. The
fluctuation-dissipation relation is violated in the shear flow in a way very
similar to that predicted theoretically, allowing for the definition of an
effective temperature Teff for the slow modes of the fluid. Temperature and
shear rate dependencies of Teff are studied using density fluctuations as an
observable. The observable dependence of Teff is also investigated. Many
different observables are found to lead to the same value of Teff, suggesting
several experimental procedures to access Teff. It is proposed that tracer
particle of large mass may play the role of an `effective thermometer'. When
the Einstein frequency of the tracers becomes smaller than the inverse
relaxation time of the fluid, a nonequilibrium equipartition theorem holds.
This last result gives strong support to the thermodynamic interpretation of
Teff and makes it experimentally accessible in a very direct way.
There are no more papers matching your filters at the moment.
