
03 Feb 2024
Among various interactions between humans, such as eye contact and gestures,
physical interactions by contact can act as an essential moment in
understanding human behaviors. Inspired by this fact, given a 3D partner human
with the desired interaction label, we introduce a new task of 3D human
generation in terms of physical contact. Unlike previous works of interacting
with static objects or scenes, a given partner human can have diverse poses and
different contact regions according to the type of interaction. To handle this
challenge, we propose a novel method of generating interactive 3D humans for a
given partner human based on a guided diffusion framework. Specifically, we
newly present a contact prediction module that adaptively estimates potential
contact regions between two input humans according to the interaction label.
Using the estimated potential contact regions as complementary guidances, we
dynamically enforce ContactGen to generate interactive 3D humans for a given
partner human within a guided diffusion model. We demonstrate ContactGen on the
CHI3D dataset, where our method generates physically plausible and diverse
poses compared to comparison methods.

03 Sep 2025

In the fast-paced financial domain, accurate and up-to-date information is critical to addressing ever-evolving market conditions. Retrieving this information correctly is essential in financial Question-Answering (QA), since many language models struggle with factual accuracy in this domain. We present FinDER, an expert-generated dataset tailored for Retrieval-Augmented Generation (RAG) in finance. Unlike existing QA datasets that provide predefined contexts and rely on relatively clear and straightforward queries, FinDER focuses on annotating search-relevant evidence by domain experts, offering 5,703 query-evidence-answer triplets derived from real-world financial inquiries. These queries frequently include abbreviations, acronyms, and concise expressions, capturing the brevity and ambiguity common in the realistic search behavior of professionals. By challenging models to retrieve relevant information from large corpora rather than relying on readily determined contexts, FinDER offers a more realistic benchmark for evaluating RAG systems. We further present a comprehensive evaluation of multiple state-of-the-art retrieval models and Large Language Models, showcasing challenges derived from a realistic benchmark to drive future research on truthful and precise RAG in the financial domain.

03 Oct 2025
FinAgentBench introduces the first large-scale benchmark for evaluating agentic retrieval capabilities of large language models in financial question answering. It assesses LLMs in a two-stage process for identifying relevant document types and specific content chunks, demonstrating that fine-tuning significantly improves performance across both stages.
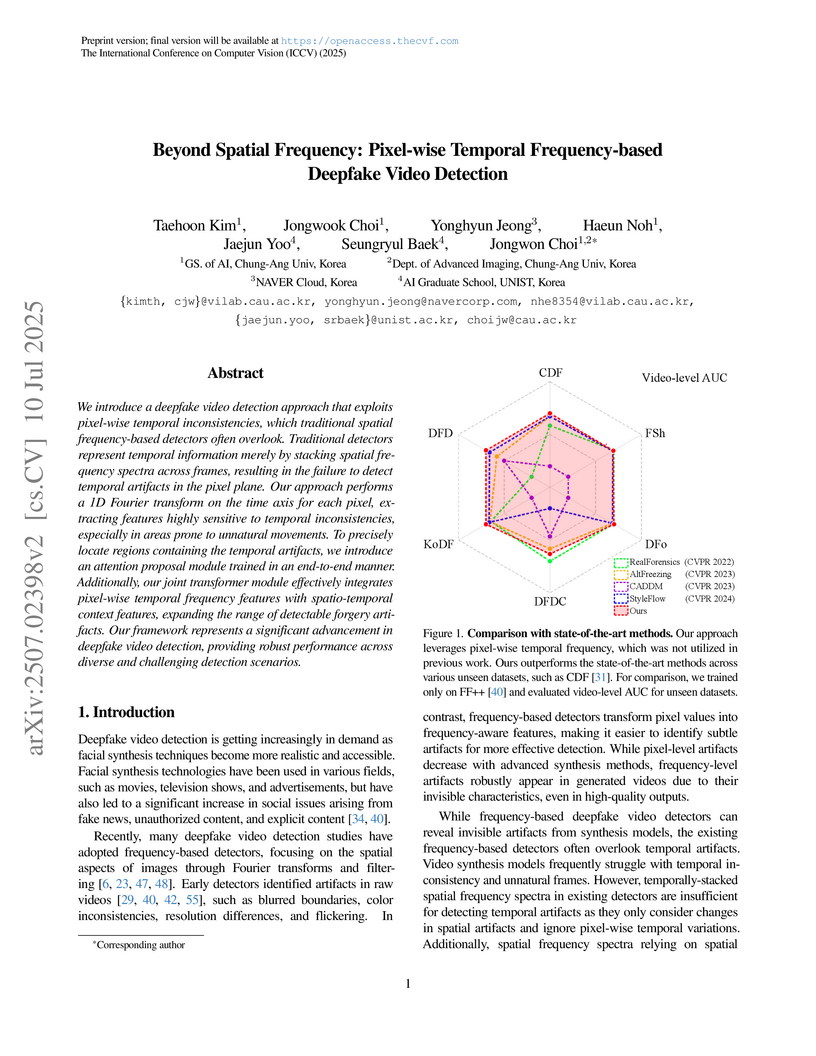
10 Jul 2025
We introduce a deepfake video detection approach that exploits pixel-wise temporal inconsistencies, which traditional spatial frequency-based detectors often overlook. Traditional detectors represent temporal information merely by stacking spatial frequency spectra across frames, resulting in the failure to detect temporal artifacts in the pixel plane. Our approach performs a 1D Fourier transform on the time axis for each pixel, extracting features highly sensitive to temporal inconsistencies, especially in areas prone to unnatural movements. To precisely locate regions containing the temporal artifacts, we introduce an attention proposal module trained in an end-to-end manner. Additionally, our joint transformer module effectively integrates pixel-wise temporal frequency features with spatio-temporal context features, expanding the range of detectable forgery artifacts. Our framework represents a significant advancement in deepfake video detection, providing robust performance across diverse and challenging detection scenarios.

16 Oct 2025

Researchers from UNIST, LG AI Research, LinqAlpha, and the University of Florida systematically uncover and quantify intrinsic biases in Large Language Models for financial analysis, demonstrating their strong preferences for specific sectors, company sizes, and investment styles. This work reveals how these latent biases manifest as confirmation bias, leading to decisions that persist even when confronted with volumetrically or qualitatively stronger counter-evidence.

22 Oct 2025
Machine unlearning (MU) aims to remove the influence of specific data from a trained model. However, approximate unlearning methods, often formulated as a single-objective optimization (SOO) problem, face a critical trade-off between unlearning efficacy and model fidelity. This leads to three primary challenges: the risk of over-forgetting, a lack of fine-grained control over the unlearning process, and the absence of metrics to holistically evaluate the trade-off. To address these issues, we reframe MU as a multi-objective optimization (MOO) problem. We then introduce a novel algorithm, Controllable Unlearning by Pivoting Gradient (CUP), which features a unique pivoting mechanism. Unlike traditional MOO methods that converge to a single solution, CUP's mechanism is designed to controllably navigate the entire Pareto frontier. This navigation is governed by a single intuitive hyperparameter, the `unlearning intensity', which allows for precise selection of a desired trade-off. To evaluate this capability, we adopt the hypervolume indicator, a metric that captures both the quality and diversity of the entire set of solutions an algorithm can generate. Our experimental results demonstrate that CUP produces a superior set of Pareto-optimal solutions, consistently outperforming existing methods across various vision tasks.

02 Apr 2024

This paper introduces Text2HOI, a framework that generates realistic 3D hand-object interaction motions from a text prompt and an object mesh, eliminating the need for object trajectories or initial hand poses. The method surpasses existing baselines in physical realism, achieving a score of 0.8839 on the GRAB dataset compared to 0.7382 for the next best method, and demonstrates strong generalization to unseen objects.
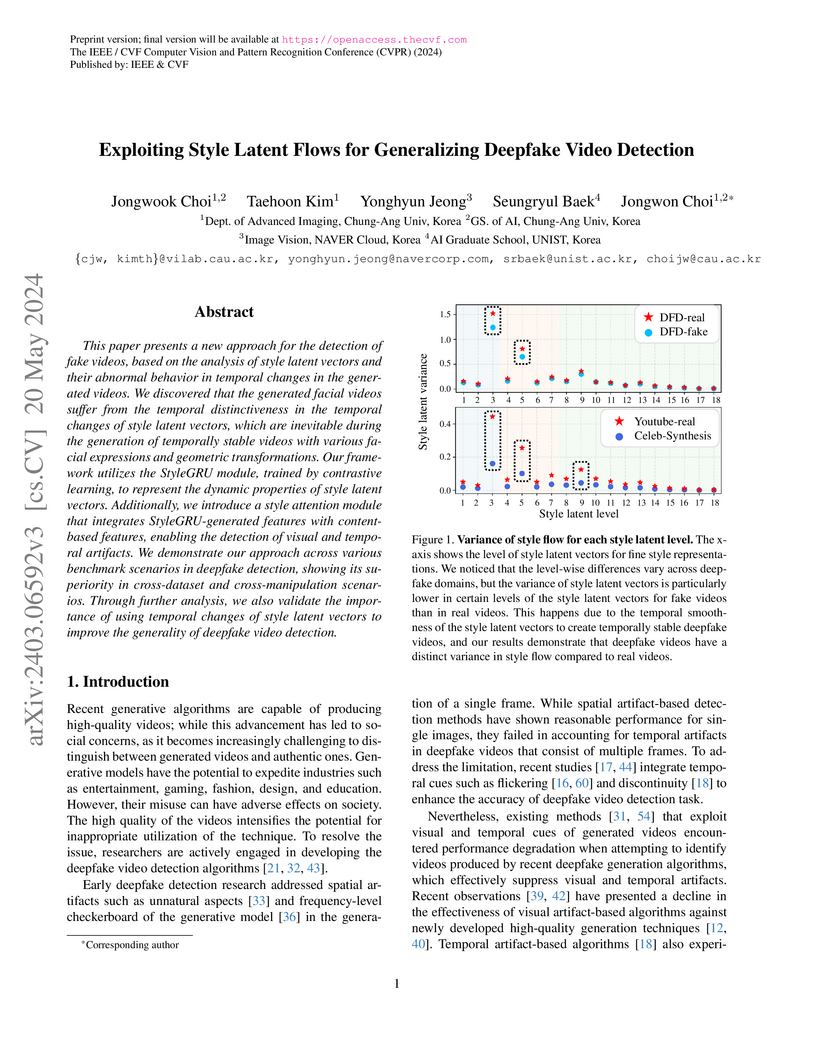
20 May 2024

This paper presents a new approach for the detection of fake videos, based on
the analysis of style latent vectors and their abnormal behavior in temporal
changes in the generated videos. We discovered that the generated facial videos
suffer from the temporal distinctiveness in the temporal changes of style
latent vectors, which are inevitable during the generation of temporally stable
videos with various facial expressions and geometric transformations. Our
framework utilizes the StyleGRU module, trained by contrastive learning, to
represent the dynamic properties of style latent vectors. Additionally, we
introduce a style attention module that integrates StyleGRU-generated features
with content-based features, enabling the detection of visual and temporal
artifacts. We demonstrate our approach across various benchmark scenarios in
deepfake detection, showing its superiority in cross-dataset and
cross-manipulation scenarios. Through further analysis, we also validate the
importance of using temporal changes of style latent vectors to improve the
generality of deepfake video detection.
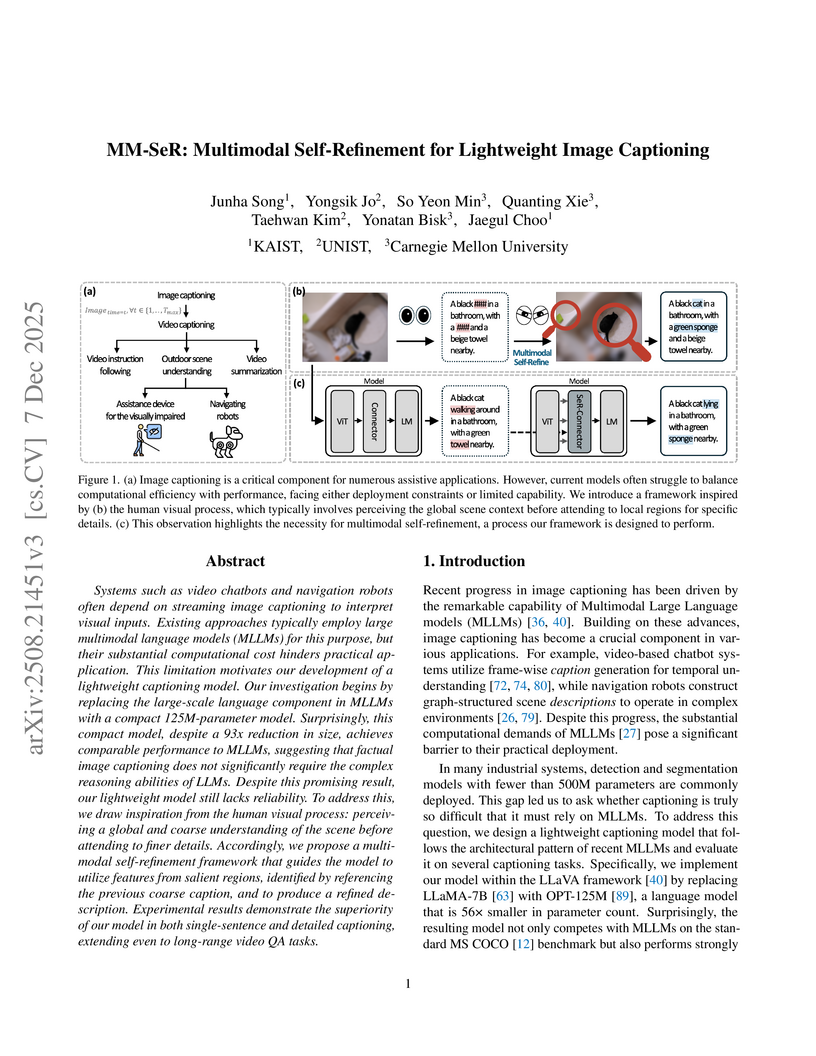
07 Dec 2025


Systems such as video chatbots and navigation robots often depend on streaming image captioning to interpret visual inputs. Existing approaches typically employ large multimodal language models (MLLMs) for this purpose, but their substantial computational cost hinders practical application. This limitation motivates our development of a lightweight captioning model. Our investigation begins by replacing the large-scale language component in MLLMs with a compact 125M-parameter model. Surprisingly, this compact model, despite a 93x reduction in size, achieves comparable performance to MLLMs, suggesting that factual image captioning does not significantly require the complex reasoning abilities of LLMs. Despite this promising result, our lightweight model still lacks reliability. To address this, we draw inspiration from the human visual process: perceiving a global and coarse understanding of the scene before attending to finer details. Accordingly, we propose a multimodal self-refinement framework that guides the model to utilize features from salient regions, identified by referencing the previous coarse caption, and to produce a refined description. Experimental results demonstrate the superiority of our model in both single-sentence and detailed captioning, extending even to long-range video QA tasks.

31 Aug 2025

Understanding and reasoning over text within visual contexts poses a significant challenge for Vision-Language Models (VLMs), given the complexity and diversity of real-world scenarios. To address this challenge, text-rich Visual Question Answering (VQA) datasets and benchmarks have emerged for high-resource languages like English. However, a critical gap persists for low-resource languages such as Korean, where the lack of comprehensive benchmarks hinders robust model evaluation and comparison. To bridge this gap, we introduce KRETA, a benchmark for Korean Reading and rEasoning in Text-rich VQA Attuned to diverse visual contexts. KRETA facilitates an in-depth evaluation of both visual text understanding and reasoning capabilities, while also supporting a multifaceted assessment across 15 domains and 26 image types. Additionally, we introduce a semi-automated VQA generation pipeline specifically optimized for text-rich settings, leveraging refined stepwise image decomposition and a rigorous seven-metric evaluation protocol to ensure data quality. While KRETA is tailored for Korean, we hope our adaptable and extensible pipeline will facilitate the development of similar benchmarks in other languages, thereby accelerating multilingual VLM research. The code and dataset for KRETA are available at this https URL.

30 Jun 2025
Domain generalization (DG) aims to learn models that perform well on unseen target domains by training on multiple source domains. Sharpness-Aware Minimization (SAM), known for finding flat minima that improve generalization, has therefore been widely adopted in DG. However, our analysis reveals that SAM in DG may converge to \textit{fake flat minima}, where the total loss surface appears flat in terms of global sharpness but remains sharp with respect to individual source domains. To understand this phenomenon more precisely, we formalize the average worst-case domain risk as the maximum loss under domain distribution shifts within a bounded divergence, and derive a generalization bound that reveals the limitations of global sharpness-aware minimization. In contrast, we show that individual sharpness provides a valid upper bound on this risk, making it a more suitable proxy for robust domain generalization. Motivated by these insights, we shift the DG paradigm toward minimizing individual sharpness across source domains. We propose \textit{Decreased-overhead Gradual SAM (DGSAM)}, which applies gradual domain-wise perturbations in a computationally efficient manner to consistently reduce individual sharpness. Extensive experiments demonstrate that DGSAM not only improves average accuracy but also reduces performance variance across domains, while incurring less computational overhead than SAM.

07 May 2024
In the field of class incremental learning (CIL), generative replay has
become increasingly prominent as a method to mitigate the catastrophic
forgetting, alongside the continuous improvements in generative models.
However, its application in class incremental object detection (CIOD) has been
significantly limited, primarily due to the complexities of scenes involving
multiple labels. In this paper, we propose a novel approach called stable
diffusion deep generative replay (SDDGR) for CIOD. Our method utilizes a
diffusion-based generative model with pre-trained text-to-diffusion networks to
generate realistic and diverse synthetic images. SDDGR incorporates an
iterative refinement strategy to produce high-quality images encompassing old
classes. Additionally, we adopt an L2 knowledge distillation technique to
improve the retention of prior knowledge in synthetic images. Furthermore, our
approach includes pseudo-labeling for old objects within new task images,
preventing misclassification as background elements. Extensive experiments on
the COCO 2017 dataset demonstrate that SDDGR significantly outperforms existing
algorithms, achieving a new state-of-the-art in various CIOD scenarios. The
source code will be made available to the public.

19 Sep 2025
LiteRSan: Lightweight Memory Safety Via Rust-specific Program Analysis and Selective Instrumentation
LiteRSan: Lightweight Memory Safety Via Rust-specific Program Analysis and Selective Instrumentation

Rust is a memory-safe language, and its strong safety guarantees combined with high performance have been attracting widespread adoption in systems programming and security-critical applications. However, Rust permits the use of unsafe code, which bypasses compiler-enforced safety checks and can introduce memory vulnerabilities. A widely adopted approach for detecting memory safety bugs in Rust is Address Sanitizer (ASan). Optimized versions, such as ERASan and RustSan, have been proposed to selectively apply security checks in order to reduce performance overhead. However, these tools still incur significant performance and memory overhead and fail to detect many classes of memory safety vulnerabilities due to the inherent limitations of ASan. In this paper, we present LiteRSan, a novel memory safety sanitizer that addresses the limitations of prior approaches. By leveraging Rust's unique ownership model, LiteRSan performs Rust-specific static analysis that is aware of pointer lifetimes to identify risky pointers. It then selectively instruments risky pointers to enforce only the necessary spatial or temporal memory safety checks. Consequently, LiteRSan introduces significantly lower runtime overhead (18.84% versus 152.05% and 183.50%) and negligible memory overhead (0.81% versus 739.27% and 861.98%) compared with existing ASan-based sanitizers while being capable of detecting memory safety bugs that prior techniques miss.

09 May 2024
VLM-PL introduces an approach for Class Incremental Object Detection that leverages Vision-Language Models (VLMs) to verify and refine pseudo-labels, addressing the issue of degrading pseudo-label quality in multi-incremental learning scenarios. The method achieves state-of-the-art performance on Pascal VOC and MS COCO, notably improving AP50 by 6.78% over prior methods in challenging 4-task scenarios on Pascal VOC.

03 Oct 2024
Recently introduced dialogue systems have demonstrated high usability. However, they still fall short of reflecting real-world conversation scenarios. Current dialogue systems exhibit an inability to replicate the dynamic, continuous, long-term interactions involving multiple partners. This shortfall arises because there have been limited efforts to account for both aspects of real-world dialogues: deeply layered interactions over the long-term dialogue and widely expanded conversation networks involving multiple participants. As the effort to incorporate these aspects combined, we introduce Mixed-Session Conversation, a dialogue system designed to construct conversations with various partners in a multi-session dialogue setup. We propose a new dataset called MiSC to implement this system. The dialogue episodes of MiSC consist of 6 consecutive sessions, with four speakers (one main speaker and three partners) appearing in each episode. Also, we propose a new dialogue model with a novel memory management mechanism, called Egocentric Memory Enhanced Mixed-Session Conversation Agent (EMMA). EMMA collects and retains memories from the main speaker's perspective during conversations with partners, enabling seamless continuity in subsequent interactions. Extensive human evaluations validate that the dialogues in MiSC demonstrate a seamless conversational flow, even when conversation partners change in each session. EMMA trained with MiSC is also evaluated to maintain high memorability without contradiction throughout the entire conversation.

09 Oct 2025
Meta-reinforcement learning (Meta-RL) facilitates rapid adaptation to unseen tasks but faces challenges in long-horizon environments. Skill-based approaches tackle this by decomposing state-action sequences into reusable skills and employing hierarchical decision-making. However, these methods are highly susceptible to noisy offline demonstrations, leading to unstable skill learning and degraded performance. To address this, we propose Self-Improving Skill Learning (SISL), which performs self-guided skill refinement using decoupled high-level and skill improvement policies, while applying skill prioritization via maximum return relabeling to focus updates on task-relevant trajectories, resulting in robust and stable adaptation even under noisy and suboptimal data. By mitigating the effect of noise, SISL achieves reliable skill learning and consistently outperforms other skill-based meta-RL methods on diverse long-horizon tasks.

23 Jan 2025

In modern large language models (LLMs), increasing the context length is
crucial for improving comprehension and coherence in long-context, multi-modal,
and retrieval-augmented language generation. While many recent transformer
models attempt to extend their context length over a million tokens, they
remain impractical due to the quadratic time and space complexities. Although
recent works on linear and sparse attention mechanisms can achieve this goal,
their real-world applicability is often limited by the need to re-train from
scratch and significantly worse performance. In response, we propose a novel
approach, Hierarchically Pruned Attention (HiP), which reduces the time
complexity of the attention mechanism to and the space complexity
to , where is the sequence length. We notice a pattern in the
attention scores of pretrained LLMs where tokens close together tend to have
similar scores, which we call ``attention locality''. Based on this
observation, we utilize a novel tree-search-like algorithm that estimates the
top- key tokens for a given query on the fly, which is mathematically
guaranteed to have better performance than random attention pruning. In
addition to improving the time complexity of the attention mechanism, we
further optimize GPU memory usage by implementing KV cache offloading, which
stores only tokens on the GPU while maintaining similar decoding
throughput. Experiments on benchmarks show that HiP, with its training-free
nature, significantly reduces both prefill and decoding latencies, as well as
memory usage, while maintaining high-quality generation with minimal
degradation. HiP enables pretrained LLMs to scale up to millions of tokens on
commodity GPUs, potentially unlocking long-context LLM applications previously
deemed infeasible.

12 Apr 2025

BIGS reconstructs animatable 3D representations of bimanual hand-object interactions with unknown objects from monocular video by leveraging 3D Gaussian Splatting and Score Distillation Sampling for occluded region completion. It outperforms the prior state-of-the-art method HOLD on the ARCTIC dataset, achieving an F-score of 83.93 for object reconstruction compared to 63.92 and significantly improving contact accuracy.

17 Jul 2025
The reasoning-based pose estimation (RPE) benchmark has emerged as a widely adopted evaluation standard for pose-aware multimodal large language models (MLLMs). Despite its significance, we identified critical reproducibility and benchmark-quality issues that hinder fair and consistent quantitative evaluations. Most notably, the benchmark utilizes different image indices from those of the original 3DPW dataset, forcing researchers into tedious and error-prone manual matching processes to obtain accurate ground-truth (GT) annotations for quantitative metrics (\eg, MPJPE, PA-MPJPE). Furthermore, our analysis reveals several inherent benchmark-quality limitations, including significant image redundancy, scenario imbalance, overly simplistic poses, and ambiguous textual descriptions, collectively undermining reliable evaluations across diverse scenarios. To alleviate manual effort and enhance reproducibility, we carefully refined the GT annotations through meticulous visual matching and publicly release these refined annotations as an open-source resource, thereby promoting consistent quantitative evaluations and facilitating future advancements in human pose-aware multimodal reasoning.

08 Apr 2024
The synthesis of human motion has traditionally been addressed through
task-dependent models that focus on specific challenges, such as predicting
future motions or filling in intermediate poses conditioned on known key-poses.
In this paper, we present a novel task-independent model called UNIMASK-M,
which can effectively address these challenges using a unified architecture.
Our model obtains comparable or better performance than the state-of-the-art in
each field. Inspired by Vision Transformers (ViTs), our UNIMASK-M model
decomposes a human pose into body parts to leverage the spatio-temporal
relationships existing in human motion. Moreover, we reformulate various
pose-conditioned motion synthesis tasks as a reconstruction problem with
different masking patterns given as input. By explicitly informing our model
about the masked joints, our UNIMASK-M becomes more robust to occlusions.
Experimental results show that our model successfully forecasts human motion on
the Human3.6M dataset. Moreover, it achieves state-of-the-art results in motion
inbetweening on the LaFAN1 dataset, particularly in long transition periods.
More information can be found on the project website
https://evm7.github.io/UNIMASKM-page/
There are no more papers matching your filters at the moment.
