
19 Sep 2025
In this work, we investigate multimodal foundation models (MFMs) for EmoFake detection (EFD) and hypothesize that they will outperform audio foundation models (AFMs). MFMs due to their cross-modal pre-training, learns emotional patterns from multiple modalities, while AFMs rely only on audio. As such, MFMs can better recognize unnatural emotional shifts and inconsistencies in manipulated audio, making them more effective at distinguishing real from fake emotional expressions. To validate our hypothesis, we conduct a comprehensive comparative analysis of state-of-the-art (SOTA) MFMs (e.g. LanguageBind) alongside AFMs (e.g. WavLM). Our experiments confirm that MFMs surpass AFMs for EFD. Beyond individual foundation models (FMs) performance, we explore FMs fusion, motivated by findings in related research areas such synthetic speech detection and speech emotion recognition. To this end, we propose SCAR, a novel framework for effective fusion. SCAR introduces a nested cross-attention mechanism, where representations from FMs interact at two stages sequentially to refine information exchange. Additionally, a self-attention refinement module further enhances feature representations by reinforcing important cross-FM cues while suppressing noise. Through SCAR with synergistic fusion of MFMs, we achieve SOTA performance, surpassing both standalone FMs and conventional fusion approaches and previous works on EFD.

07 Oct 2025
We formalize the structure of a class of mathematical models of growing-dividing autocatalytic systems demonstrating that self-reproduction emerges only if the system's 'growth dynamics' and 'division strategy' are mutually compatible. Using various models in this class (the linear Hinshelwood cycle and nonlinear coarse-grained models of protocells and bacteria), we show that depending on the chosen division mechanism, the same chemical system can exhibit either (i) balanced exponential growth, (ii) balanced nonexponential growth, or (iii) system death (where the system either explodes to infinity or collapses to zero in successive generations). We identify the class of division processes that lead to these three outcomes, offering strategies to stabilize or destabilize growing-dividing systems. Our work provides a geometric framework to further explore growing-dividing systems and will aid in the design of self-reproducing synthetic cells.

23 Jul 2024
Autism Spectrum Disorder (ASD) is a complex neuro-developmental challenge, presenting a spectrum of difficulties in social interaction, communication, and the expression of repetitive behaviors in different situations. This increasing prevalence underscores the importance of ASD as a major public health concern and the need for comprehensive research initiatives to advance our understanding of the disorder and its early detection methods. This study introduces a novel hierarchical feature fusion method aimed at enhancing the early detection of ASD in children through the analysis of code-switched speech (English and Hindi). Employing advanced audio processing techniques, the research integrates acoustic, paralinguistic, and linguistic information using Transformer Encoders. This innovative fusion strategy is designed to improve classification robustness and accuracy, crucial for early and precise ASD identification. The methodology involves collecting a code-switched speech corpus, CoSAm, from children diagnosed with ASD and a matched control group. The dataset comprises 61 voice recordings from 30 children diagnosed with ASD and 31 from neurotypical children, aged between 3 and 13 years, resulting in a total of 159.75 minutes of voice recordings. The feature analysis focuses on MFCCs and extensive statistical attributes to capture speech pattern variability and complexity. The best model performance is achieved using a hierarchical fusion technique with an accuracy of 98.75% using a combination of acoustic and linguistic features first, followed by paralinguistic features in a hierarchical manner.

21 Sep 2024
In this study, we investigate multimodal foundation models (MFMs) for emotion
recognition from non-verbal sounds. We hypothesize that MFMs, with their joint
pre-training across multiple modalities, will be more effective in non-verbal
sounds emotion recognition (NVER) by better interpreting and differentiating
subtle emotional cues that may be ambiguous in audio-only foundation models
(AFMs). To validate our hypothesis, we extract representations from
state-of-the-art (SOTA) MFMs and AFMs and evaluated them on benchmark NVER
datasets. We also investigate the potential of combining selected foundation
model representations to enhance NVER further inspired by research in speech
recognition and audio deepfake detection. To achieve this, we propose a
framework called MATA (Intra-Modality Alignment through Transport Attention).
Through MATA coupled with the combination of MFMs: LanguageBind and ImageBind,
we report the topmost performance with accuracies of 76.47%, 77.40%, 75.12% and
F1-scores of 70.35%, 76.19%, 74.63% for ASVP-ESD, JNV, and VIVAE datasets
against individual FMs and baseline fusion techniques and report SOTA on the
benchmark datasets.

03 Jun 2025
As video-sharing platforms have grown over the past decade, child viewership
has surged, increasing the need for precise detection of harmful content like
violence or explicit scenes. Malicious users exploit moderation systems by
embedding unsafe content in minimal frames to evade detection. While prior
research has focused on visual cues and advanced such fine-grained detection,
audio features remain underexplored. In this study, we embed audio cues with
visual for fine-grained child harmful content detection and introduce SNIFR, a
novel framework for effective alignment. SNIFR employs a transformer encoder
for intra-modality interaction, followed by a cascaded cross-transformer for
inter-modality alignment. Our approach achieves superior performance over
unimodal and baseline fusion methods, setting a new state-of-the-art.

02 Jun 2025
Akhtar et al. demonstrates that Mamba-based Audio Foundation Models consistently outperform Attention-based Audio Foundation Models for Non-Verbal Vocal Sounds Emotion Recognition, and introduces RENO, a fusion framework that achieves state-of-the-art performance by aligning representations from diverse models.

03 Jun 2025
In this work, we introduce the task of singing voice deepfake source
attribution (SVDSA). We hypothesize that multimodal foundation models (MMFMs)
such as ImageBind, LanguageBind will be most effective for SVDSA as they are
better equipped for capturing subtle source-specific characteristics-such as
unique timbre, pitch manipulation, or synthesis artifacts of each singing voice
deepfake source due to their cross-modality pre-training. Our experiments with
MMFMs, speech foundation models and music foundation models verify the
hypothesis that MMFMs are the most effective for SVDSA. Furthermore, inspired
from related research, we also explore fusion of foundation models (FMs) for
improved SVDSA. To this end, we propose a novel framework, COFFE which employs
Chernoff Distance as novel loss function for effective fusion of FMs. Through
COFFE with the symphony of MMFMs, we attain the topmost performance in
comparison to all the individual FMs and baseline fusion methods.

16 Oct 2024
Despite being trained exclusively on speech data, speech foundation models (SFMs) like Whisper have shown impressive performance in non-speech tasks such as audio classification. This is partly because speech shares some common traits with audio, enabling SFMs to transfer effectively. In this study, we push the boundaries by evaluating SFMs on a more challenging out-of-domain (OOD) task: classifying physiological time-series signals. We test two key hypotheses: first, that SFMs can generalize to physiological signals by capturing shared temporal patterns; second, that multilingual SFMs will outperform others due to their exposure to greater variability during pre-training, leading to more robust, generalized representations. Our experiments, conducted for stress recognition using ECG (Electrocardiogram), EMG (Electromyography), and EDA (Electrodermal Activity) signals, reveal that models trained on SFM-derived representations outperform those trained on raw physiological signals. Among all models, multilingual SFMs achieve the highest accuracy, supporting our hypothesis and demonstrating their OOD capabilities. This work positions SFMs as promising tools for new uncharted domains beyond speech.

03 Jun 2025
Compression-based representations (CBRs) from neural audio codecs such as
EnCodec capture intricate acoustic features like pitch and timbre, while
representation-learning-based representations (RLRs) from pre-trained models
trained for speech representation learning such as WavLM encode high-level
semantic and prosodic information. Previous research on Speech Emotion
Recognition (SER) has explored both, however, fusion of CBRs and RLRs haven't
been explored yet. In this study, we solve this gap and investigate the fusion
of RLRs and CBRs and hypothesize they will be more effective by providing
complementary information. To this end, we propose, HYFuse, a novel framework
that fuses the representations by transforming them to hyperbolic space. With
HYFuse, through fusion of x-vector (RLR) and Soundstream (CBR), we achieve the
top performance in comparison to individual representations as well as the
homogeneous fusion of RLRs and CBRs and report SOTA.

02 Jun 2025
In this study, we focus on Singing Voice Mean Opinion Score (SingMOS)
prediction. Previous research have shown the performance benefit with the use
of state-of-the-art (SOTA) pre-trained models (PTMs). However, they haven't
explored speaker recognition speech PTMs (SPTMs) such as x-vector, ECAPA and we
hypothesize that it will be the most effective for SingMOS prediction. We
believe that due to their speaker recognition pre-training, it equips them to
capture fine-grained vocal features (e.g., pitch, tone, intensity) from
synthesized singing voices in a much more better way than other PTMs. Our
experiments with SOTA PTMs including SPTMs and music PTMs validates the
hypothesis. Additionally, we introduce a novel fusion framework, BATCH that
uses Bhattacharya Distance for fusion of PTMs. Through BATCH with the fusion of
speaker recognition SPTMs, we report the topmost performance comparison to all
the individual PTMs and baseline fusion techniques as well as setting SOTA.

14 Jun 2025
A new class of audio deepfakes-codecfakes (CFs)-has recently caught
attention, synthesized by Audio Language Models that leverage neural audio
codecs (NACs) in the backend. In response, the community has introduced
dedicated benchmarks and tailored detection strategies. As the field advances,
efforts have moved beyond binary detection toward source attribution, including
open-set attribution, which aims to identify the NAC responsible for generation
and flag novel, unseen ones during inference. This shift toward source
attribution improves forensic interpretability and accountability. However,
open-set attribution remains fundamentally limited: while it can detect that a
NAC is unfamiliar, it cannot characterize or identify individual unseen codecs.
It treats such inputs as generic ``unknowns'', lacking insight into their
internal configuration. This leads to major shortcomings: limited
generalization to new NACs and inability to resolve fine-grained variations
within NAC families. To address these gaps, we propose Neural Audio Codec
Source Parsing (NACSP) - a paradigm shift that reframes source attribution for
CFs as structured regression over generative NAC parameters such as quantizers,
bandwidth, and sampling rate. We formulate NACSP as a multi-task regression
task for predicting these NAC parameters and establish the first comprehensive
benchmark using various state-of-the-art speech pre-trained models (PTMs). To
this end, we propose HYDRA, a novel framework that leverages hyperbolic
geometry to disentangle complex latent properties from PTM representations. By
employing task-specific attention over multiple curvature-aware hyperbolic
subspaces, HYDRA enables superior multi-task generalization. Our extensive
experiments show HYDRA achieves top results on benchmark CFs datasets compared
to baselines operating in Euclidean space.

01 Jun 2025
The emergence of Mamba as an alternative to attention-based architectures has
led to the development of Mamba-based self-supervised learning (SSL)
pre-trained models (PTMs) for speech and audio processing. Recent studies
suggest that these models achieve comparable or superior performance to
state-of-the-art (SOTA) attention-based PTMs for speech emotion recognition
(SER). Motivated by prior work demonstrating the benefits of PTM fusion across
different speech processing tasks, we hypothesize that leveraging the
complementary strengths of Mamba-based and attention-based PTMs will enhance
SER performance beyond the fusion of homogenous attention-based PTMs. To this
end, we introduce a novel framework, PARROT that integrates parallel branch
fusion with Optimal Transport and Hadamard Product. Our approach achieves SOTA
results against individual PTMs, homogeneous PTMs fusion, and baseline fusion
techniques, thus, highlighting the potential of heterogeneous PTM fusion for
SER.

02 Jun 2025
This research introduces machine unlearning techniques to paralinguistic speech processing, proposing SISA++ which employs weight averaging of sub-models for efficient and effective data removal. The method shows improved performance retention after unlearning operations and identifies optimal feature-architecture combinations for robust unlearning in speech-based tasks.

01 Jun 2025
In this work, we focus on source tracing of synthetic speech generation
systems (STSGS). Each source embeds distinctive paralinguistic features--such
as pitch, tone, rhythm, and intonation--into their synthesized speech,
reflecting the underlying design of the generation model. While previous
research has explored representations from speech pre-trained models (SPTMs),
the use of representations from SPTM pre-trained for paralinguistic speech
processing, which excel in paralinguistic tasks like synthetic speech
detection, speech emotion recognition has not been investigated for STSGS. We
hypothesize that representations from paralinguistic SPTM will be more
effective due to its ability to capture source-specific paralinguistic cues
attributing to its paralinguistic pre-training. Our comparative study of
representations from various SOTA SPTMs, including paralinguistic, monolingual,
multilingual, and speaker recognition, validates this hypothesis. Furthermore,
we explore fusion of representations and propose TRIO, a novel framework that
fuses SPTMs using a gated mechanism for adaptive weighting, followed by
canonical correlation loss for inter-representation alignment and
self-attention for feature refinement. By fusing TRILLsson (Paralinguistic
SPTM) and x-vector (Speaker recognition SPTM), TRIO outperforms individual
SPTMs, baseline fusion methods, and sets new SOTA for STSGS in comparison to
previous works.
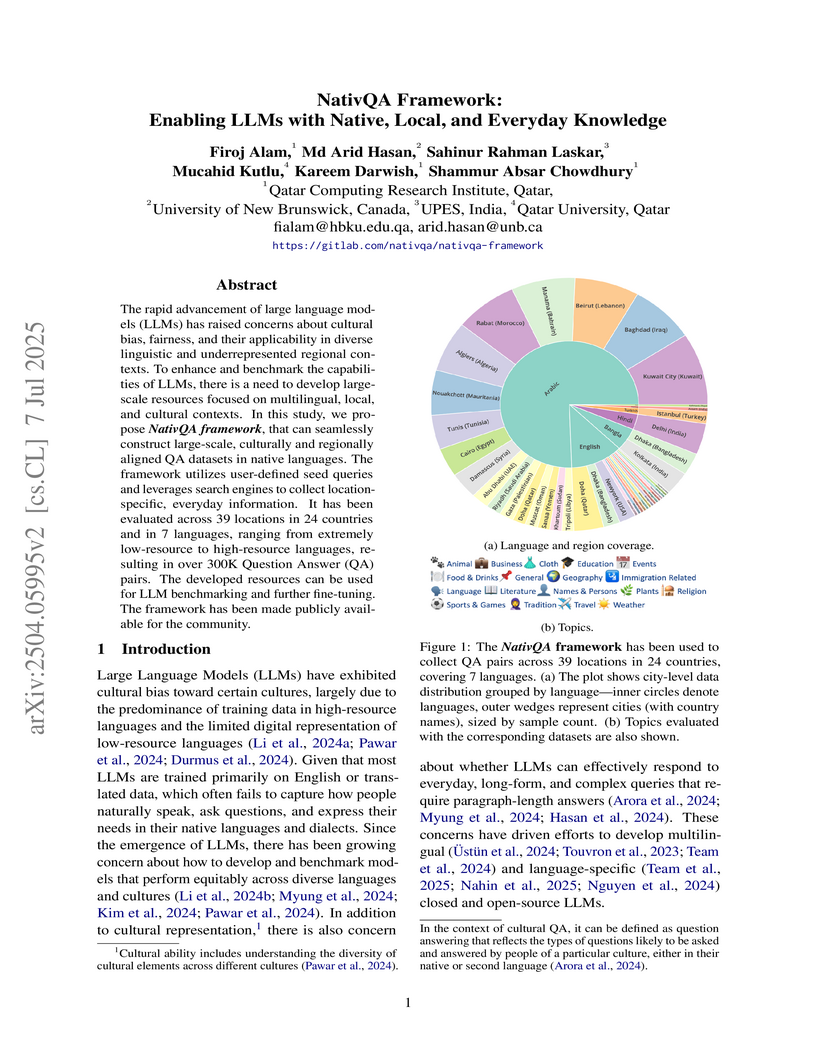
07 Jul 2025
The rapid advancement of large language models (LLMs) has raised concerns about cultural bias, fairness, and their applicability in diverse linguistic and underrepresented regional contexts. To enhance and benchmark the capabilities of LLMs, there is a need to develop large-scale resources focused on multilingual, local, and cultural contexts. In this study, we propose the NativQA framework, which can seamlessly construct large-scale, culturally and regionally aligned QA datasets in native languages. The framework utilizes user-defined seed queries and leverages search engines to collect location-specific, everyday information. It has been evaluated across 39 locations in 24 countries and in 7 languages -- ranging from extremely low-resource to high-resource languages -- resulting in over 300K Question-Answer (QA) pairs. The developed resources can be used for LLM benchmarking and further fine-tuning. The framework has been made publicly available for the community (this https URL).

08 Oct 2025
In this paper, we give the enumeration of z-classes in finite Coxeter groups.

19 Sep 2025
This paper investigates the polyglot (multilingual) speech foundation models (SFMs) for Crowd Emotion Recognition (CER). We hypothesize that polyglot SFMs, pre-trained on diverse languages, accents, and speech patterns, are particularly adept at navigating the noisy and complex acoustic environments characteristic of crowd settings, thereby offering a significant advantage for CER. To substantiate this, we perform a comprehensive analysis, comparing polyglot, monolingual, and speaker recognition SFMs through extensive experiments on a benchmark CER dataset across varying audio durations (1 sec, 500 ms, and 250 ms). The results consistently demonstrate the superiority of polyglot SFMs, outperforming their counterparts across all audio lengths and excelling even with extremely short-duration inputs. These findings pave the way for adaptation of SFMs in setting up new benchmarks for CER.

01 Jun 2025
The emergence of Mamba as an alternative to attention-based architectures has led to the development of Mamba-based self-supervised learning (SSL) pre-trained models (PTMs) for speech and audio processing. Recent studies suggest that these models achieve comparable or superior performance to state-of-the-art (SOTA) attention-based PTMs for speech emotion recognition (SER). Motivated by prior work demonstrating the benefits of PTM fusion across different speech processing tasks, we hypothesize that leveraging the complementary strengths of Mamba-based and attention-based PTMs will enhance SER performance beyond the fusion of homogenous attention-based PTMs. To this end, we introduce a novel framework, PARROT that integrates parallel branch fusion with Optimal Transport and Hadamard Product. Our approach achieves SOTA results against individual PTMs, homogeneous PTMs fusion, and baseline fusion techniques, thus, highlighting the potential of heterogeneous PTM fusion for SER.

05 Jun 2024
Code-switching is a common communication phenomenon where individuals alternate between two or more languages or linguistic styles within a single conversation. Autism Spectrum Disorder (ASD) is a developmental disorder posing challenges in social interaction, communication, and repetitive behaviors. Detecting ASD in individuals with code-switch scenario presents unique challenges. In this paper, we address this problem by building an application NeuRO which aims to detect potential signs of autism in code-switched conversations, facilitating early intervention and support for individuals with ASD.

12 Sep 2024
In this article, we study the black hole evaporation process and shadow property of the Tangherlini-Reissner-Nordström (TRN) black holes. The TRN black holes are the higher-dimensional extension of the Reissner-Nordström (RN) black holes and are characterized by their mass , charge , and spacetime dimensions . In higher-dimensional spacetime, the black hole evaporation occurs rapidly, causing the black hole's horizon to shrink. We derive the rate of mass loss for the higher-dimensional charged black hole and investigate the effect of higher-dimensional spacetime on charged black hole shadow. We derive the complete geodesic equations of motion with the effect of spacetime dimensions . We determine impact parameters by maximizing the black hole's effective potential and estimate the critical radius of photon orbits. The photon orbits around the black hole shrink with the effect of the increasing number of spacetime dimensions. To visualize the shadows of the black hole, we derive the celestial coordinates in terms of the black hole parameters. We use the observed results of M87 and Sgr A black hole from the Event Horizon Telescope and estimate the angular diameter of the charge black hole shadow in the higher-dimensional spacetime. We also estimate the energy emission rate of the black hole. Our finding shows that the angular diameter of the black hole shadow decreases with the increasing number of spacetime dimensions .
There are no more papers matching your filters at the moment.
